
基于LDA主题模型的用户兴趣发现方法
2016-02-13 05:58储涛涛
软件 2016年12期
储涛涛
(北京邮电大学计算机学院,北京 100876)
基于LDA主题模型的用户兴趣发现方法
储涛涛
(北京邮电大学计算机学院,北京 100876)
用户兴趣是对微博用户研究的重要内容,本文使用聚类方法提取用户兴趣。由于微博短文本的特征稀疏和上下文依赖性,传统方法不能取得良好的效果。本文对微博短文本进行基于LDA主题模型的特征拓展处理。LDA主题模型引入隐含主题,通过主题相似性,在一定程度上拓展文本特征,弥补原文本特征稀疏的缺点。并且,在处理多义词时,主题相似性能明显区分不同词义,以解决上下文依赖问题。在此基础上,通过文本聚类方法提取用户兴趣。通过实验表明,在引入LDA模型下,聚类效果和用户兴趣抽取的到明显提升,有效解决的微博用户兴趣发现中文博短文本特征稀疏和上下文依赖问题。
用户兴趣;短文本;LDA;特征拓展;K-means
本文著录格式:储涛涛. 基于LDA主题模型的用户兴趣发现方法[J]. 软件,2016,37(12):38-42
0 引言
用户兴趣是对微博用户研究的重要内容,本研究中使用文本聚类方法发掘用户兴趣,文本聚类技术一直是文本挖掘领域的重要内容。而微博短文本由于具有短小、新词多、不规范等特点,如果直接使用传统的方法往往不能取得很好的效果。对微博文本的研究,具有十分重要的理论研究和实际应用意义。
从理论上来说,本研究充分考虑互联网微博用户的短文本特性,针对短文本内容丰富、特征稀疏、上下文依赖性强的特点,设计合适的文本挖掘方法,通过LDA模型对微博短文本进行特征的扩展。从而准确全面地描述用户兴趣,为用户兴趣发现扩展了方法和范围。从应用上来说,通过对微博文本的分析,可以帮助用户从海量的微博数据中区分出不同话题的微博,提高用户的浏览效率。由于微博内容可以涉及政治、军事、娱乐等等诸多方面的内容,文本分析技术在话题跟踪与发现、舆情预警、情感分析等领域都有广泛的应用背景。
1 相关研究
针对微博的分析一直是今年的研究热点,针对微博用户的分析,yang[1]等通过研究用户发布微博的情况用户发布含有链接的微博用户网络结构3个方面提出了一个新模式来预测信息扩散的速度规模和范围。JIANG[2]等同样也提出了一个新的模型来预测信息传播情况。BOYD[3]等以Twitter为研究对象针对一系列研究数据分析了用户在转发动机与评论作者出处和真实性之间的关系。针对微博内容的分析也是研究的热点。杨亮[4]等根据热点事件发生时用户情感词数量增多提出了一个情感分布模型,并通过该模型分析相邻时间段情感分布的语言差异从而实现对热点事件的发现LEE[5]开发了一套对关键字动态加权的方案以实现对所发生事件的实时监测。READ[22]通过API获得大量表情符号并利用这些表情符号建立语料库从而判断微博的情感极性[6]。
针对微博文本的短文本特征,研究人员已经提出了多种方法,来克服短文本稀疏性的问题,更好的表示文本特征,提高短文本聚类和聚类的效果。这些方法大致可以分为两类:一种是基于额外信息如搜索引擎,开源知识库等的特征扩展方法,还有就是通过挖掘短文本本身的特性,通过选择更好的特征来表示文本。
Yih和Christopher[7]通过使用特征词的内权重内积代替TF-IDF,扩展了Web-kernel相似性计算公式。他们还引入了机器学习的方法来提高相似性度量的准确性。Banerjee[8]将结合信息检索技术和维基百科的数据。他们基于维基百科的数据建立了一个搜索引擎,待聚类的短文本作为关键词进行查询,通过查询返回的结果来进行特征扩展。在[9]的研究中,使用了不同的外部数据来进行特征扩展。若短文本有多个特征词,这则使用维基百科进行特征扩展。若短文本只有一个特征词,则使用WorldNet来进行特征扩展。除了直接使用额外资源的直接结果外,一些方法也使用的概念挖掘来扩展短文本的特征。Phan[10]等人使用LDA模型挖掘维基百科数据中的隐含主题,并且使用隐含主题来扩展短文本的特征。Chen[15]等人进一步改进了[10]中的LDA方法,提出了多粒度主题。
Sriram[11]等人分析了推特中推文的特征,选择了另外的8个特征(缩略词和俚语,时间-时间短语,观点词等)来代替传统的词袋(bag of words)特征。Sun[12]的研究尝试模拟人类投票的行为来进行短文本聚类。他们将训练集建立索引,然后在这个索引中搜索关键词,用返回的结果投票,结果中最多的类别就是当前待聚类短文本的类别。Yuan[13]等人尝试优化聚类算法来提高在稀疏数据上的准确性。他们使用四种平滑方法和朴素贝叶斯在Yahoo!问答系统数据集上做了一些实验。他们发现,一些合适的平滑方法能够极大的提高贝叶斯方法在短文本聚类上的准确性。Wang[14]改进了原有的TF-IDF大的特征选择和权重计算方法,提出了DFICF的概念和基于互信息的方法进行特征选择,解决短文本特征稀疏性的问题。在这些研究中,还没有哪种方法具有十分明显的优势。其他一些关于短文本的研究,比如关键词提取[15]和相似性计算[16]-[20],对于聚类算法的研究也具有比较大的帮助。
2 相关理论
2.1 向量空间
VSM由Salton等提出,已经成为信息检索领域常用的文本表示模型,将文本看作“词袋”。给出一些符号定义:词表N为词的总数;文本集M为文本总数;一篇文di∈D的向量表示为为词v∈V在d中的权重,通常采用TF-kiIDF权重评价函数:

其中:tfki表示vk在di中出现的次数,dfk表示D中含有vk的文本总数。通常采用余弦距离计算两篇文本之间的相似度:
2.2 隐含狄利克雷分布
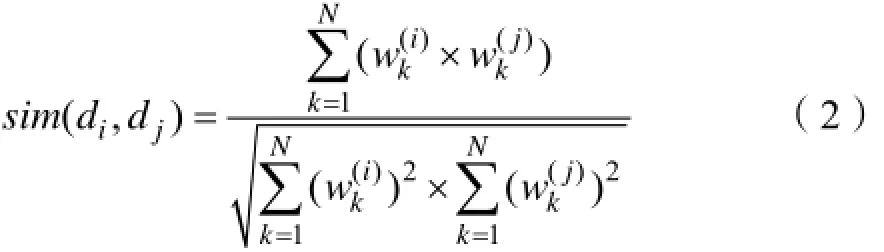
LDA主题模型有Blei等提出,是一个“文本-主题-词”的三层贝叶斯生成模式,每篇文本表示为主题的混合分布,而每个主题则是在词上的概率分布,最初的模型只对文本-主题概率分布引入一个超参数使其服从Dirichlet分布,随后Griffiths等对主题-词概率分布也引入一个超参数使其服从Dirichlet分布。该模型用图1表示,各个符号含义如表1所示。
两个超参数一般设置为α=50/T,β=0.01。LDA模型的参数个数只与主题数和词数相关,参数估计是计算出文本-主题概率分布以及主题-词概率分布,即θ和φ。通过对变量进行Gibbs采样间接估算θ和φ:

图1 LDA的图表示

表1 LDA模型中各符号的含义
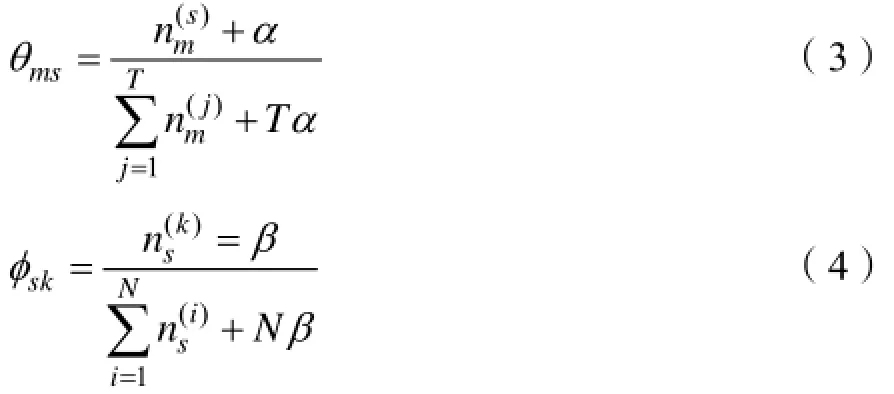
2.3 基于主题的相似性
Quan等提出了基于主题的相似性(Topic-Based Similarity,TBS)度量方法来解决短文本的特征稀疏性问题,基本思想是通过第三方主题来比较两篇短文本。
假设文本集D中存在两篇短文本d1和d2,使用分词为特征项,那么他们的向量表示为和V在D上运行LDA模型后得到T隐含主题以及主题-词概率分布φ,记φsk为词vk属于主题的概率分布。
这两篇短文本的可区分词集定义为:
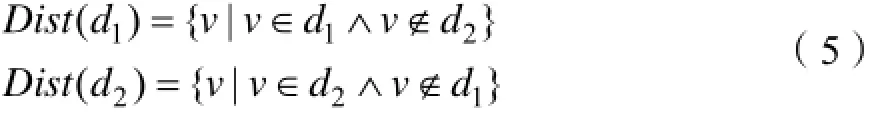

3 基于LDA的微博短文本聚类
3.1 问题描述
微博文本中,存在着大量的用户短微博数据,这些文本数据大多不足140字,且语法语义多样。文本中特征稀疏性和上下文依赖性给文本处理工作带来了很大挑战。
针对微博文本的特征稀疏性,通过引入可区分词集和基于主题的相似性能够很大程度丰富微博文本的分词特征项。如下例子:
微博a:“今天 雾霾 很大”
微博b:“空气 污染 严重”
“雾霾”和“空气”是不同的词,如果TBS引入的隐含主题,能够将两者很强地关联起来,认为两者具有主题相似性。
另一个例子体现了短文本的上下文依赖性强的问题,如下:
微博a:“电脑旁边的苹果很大”→ 电脑 苹果 大微博b:“苹果电脑很轻”→ 电脑 苹果 轻微博a和微博b经过分词和去停用词处理后相似度很大,但是“苹果”一次在两个句子中表达的意思完全不一致,这使得对“苹果”的词义理解依赖上下文。
这个例子中的微博文本经过分词去停用词后得到右边的词集。VSM计算结果会体现出这两篇微博具有很大的相似性。在此,我们引入一种新的基于LDA的文本聚类算法。
3.2 相似性度量
通常,如果出现在两个不同语境中的同一个词,表达出不同的主题。那么这个词很可能就体现出多义词性质,这在计算相似性是会误认为两篇文本相似程度搞。为了解决这个问题,这里讨论共有词集,以处理上下文依赖问题。
共有词集定义如下:
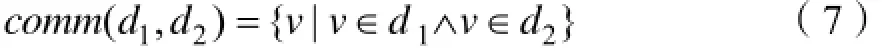
对于两篇微博文本,共有词集中同时满足条件C1和C2的词降低权重,来削弱同义词影响。
条件C1:根据式(8),提取d1和d2各自的最大主题,两者不一致;
条件C2:在各自最大主题下,该词的主题-词概率值排名前40%。
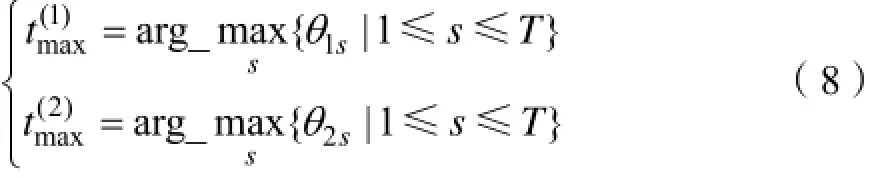
与式(6)相似思路,采用式(9)降低满足条件的共有词vc的权重:
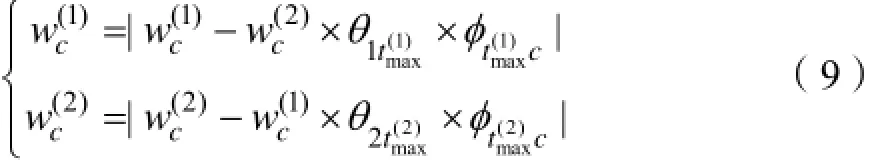
基于LDA的微博聚类方法的相似度度量算法描述如下
算法1 相似性度量:
输入 微博文本d1和d2,和概率分布φ和θ;
第1步 获取共有词集;
第2步 由式(8)提取两篇文本各自的最大主题t1max和tm2ax。若或者则跳转至第4步;
第3步 对于共有词集中的每个词vc,如果还满足条件C2,则根据式(9)更新权重;
第6步 根据式(2)计算d1和d2的相似度
3.3 聚类方法
聚类算法采用K-means,将一条微博中各个分词的TF-IDF平均值μ作为选择种子起点的指标,八个类别中的种子起点分别为各自μ值最大的微博文本。在计算相似使用4.2中的相似性计算方法,迭代计算。
4 实验
4.1 实验环境

表2 实验环境
4.2 实验数据
实验使用从新浪微博平台爬取下来的用户微博文本数据,数据通过主题聚类爬取。通过筛选,可用文本共有8个类别共计5798篇。
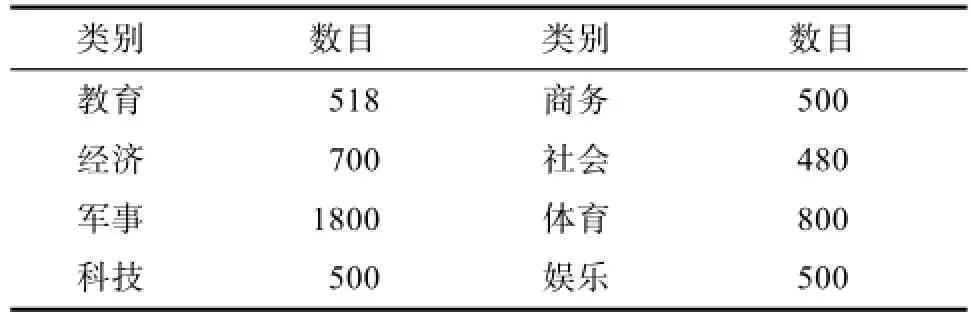
表3 实验数据
4.3 实验设置
预处理 对抓取的原始文本进行预处理,包括分词去停用词和长度筛选,分词采用了ICTCLAS分词系统
主题数 聚类学习是非监督学习,本文通过抽样方法评估聚类结果,利用困惑度Perplexity指标确定主题数。该指标表示预测数据时的不确定度,取值越小表示性能越好。
TBS阈值 TBS调整可区分词的权重时需要判断主题-词概率是否超过阈值λ。利用最大主题-词概率值自动确定阈值,将所有主题下最大主题-词概率值累加求平均,并以40%的分界作为λ的取值:

聚类算法 采用K-means方法。将一条微博中各个分词的TF-IDF平均值μ作为选择种子起点的指标,八个类别中的种子起点分别为各自μ值最大的那条微博。
4.4 实验结果
在主题数为50时,Perplexity值接近极限值,且此时的计算效率任然较高,在此之后虽然主题数不断增加,但是Perplexity减小并不明显。因此,选择主题数为50。
实验结果如下:

表4 实验结果
综合比较:将8个类别上的查全率和准确率求平均值得到F1,两种方法对比结果如图2。

图2 实验结果对比
显然,在聚类结果的性能上,改进的新方法明显优于VSM。新方法在三个指标Re、Pr、F1上分别提高百分之1.2、2.5、1.9。新方法相对于VSM,在不牺牲时间代价的前提下提高了聚类结果的精度。
5 结论
微博短文本处理时面临两个问题: 特征稀疏性和上下文依赖性。利用 LDA 模型生成主题,TBS方法解决了特征稀疏性问题。同时,用另一种方法进一步解决上下文依赖性问题。新方法不仅给出短文本相似性的完备度量,而且能够自动确定TBS阈值。新方法通过对微博文本的聚类分析,进行兴趣发现和提取,结果表明新方法的聚类性能优于VSM,并通过同义词和多义词分布能够解释其原因。社交媒体由于表述的口语化和不规范化,给短文本处理带来新的挑战。
[1] Predicting the Speed, Scale, and Range of Information Diffusion in. Twitter. Jiang Yang. School of Information. University of Michigan. 1075 Beal Ave.2013; 355-358.
[2] Evolutionary Dynamics of Information Diffusion Over Social NetworksC Jiang, Y Chen, KJR Liu-Signal Processing, IEEE …, 2015.
[3] Tweet, tweet, retweet: Conversational aspects of retweeting on twitter D Boyd, S Golder, G Lotan-System Sciences (HICSS), 2014.
[4] Micro-Blog Hot Events Detection Based on Emotion Distribution [J] L YANG, Y LIN, H LIN-Journal of Chinese Information Processing, 2012 - en.cnki.com.cn.
[5] Mining spatio-temporal information on microblogging streams using a density-based online clustering methodCH Lee- Expert Systems with Applications, 2013-Elsevier.
[6] Using emoticons to reduce dependency in machine learning techniques for sentiment classificationJ Read-Proceedings of the ACL student research workshop, 2005-dl.acm.org;
[7] S. Banerjee, K. Ramanathan and A. Gupta, "Clustering short texts using wikipedia," Proc. ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 07), ACM Press, July 2010, pp. 787-788, doi: 10.1145/ 1277741.1277909.
[8] X. Hu, N. Sun, C. Zhang, and T. S. Chua, "Exploiting internal and external semantics for the clustering of short texts using world knowledge," Proc. ACM International Conference on Information and Knowledge Management (CIKM 09), ACM Press, Nov. 2012.
[9] X. H. Phan, L. M. Nguyen and S. Horiguchi, "Learning to classify short and sparse text & web with hidden topics from large-scale data collections," Proc. International Conference on World Wide Web (WWW 08), ACM Press, Apr. 2014.
[10] M. Chen, X. Jin and D. Shen, "Short text classification improved by learning multi-granularity topics," Proc. International Joint Conference on Artificial Intelligence (IJCAI 11), AAAI Press, July 2013.
[11] B. Sriram, D. Fuhry, E. Demir, H. Ferhatosmanoglu, and M. Demirbas, "Short text classification in twitter to improve information filtering," Proc. ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 10), ACM Press, July 2010.
[12] A. Sun, "Short text classification using very few words," Proc. ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 12), ACM Press, Aug. 2013.
[13] Q. Yuan, G. Cong and N. M. Thalmann, "Enhancing Naive Bayes with various smoothing methods for short text classification," Proc. International Conference on World Wide Web (WWW 12), ACM Press, April 2014.
[14] Meng Wang, Lanfen Lin, Feng Wang, Improving Short Text Classification through Better Feature Space Selection[C] // Ninth International Conference on Computational Intelligence and Security, 2016.
[15] Liu Z, Chen X, Sun M. Mining the interests of Chinese microbloggers via keyword extraction[J]. Frontiers of Computer Science, 2014, 6(1): 76-87.
[16] Bollegala D, Matsuo Y, Ishizuka M. Measuring semantic similarity between words using web search engines[J]. www, 2010, 7: 757-766.
[17] Yih W T, Meek C. Improving similarity measures for short segments of text[C]//AAAI. 2010, 7: 1489-1494.
[18] Sahami M, Heilman T D. A web-based kernel function for measuring the similarity of short text snippets[C]//Proceedings of the 15th international conference on World Wide Web. ACM, 2010: 377-386.
[19] 翟延冬, 王康平, 张东娜, 等. 一种基于WordNet的短文本语义相似性算法[J]. 电子学报, 2014, 40(3): 617-620.
[20] Quan X, Liu G, Lu Z, et al. Short text similarity based on probabilistic topics[J]. Knowledge and information systems, 2013, 25(3): 473-491.
[21] 基于频繁项集的海量短文本聚类与主题抽取.彭敏,黄佳佳,朱佳晖, 黄济民, 刘纪平-计算机研究与发展, 2016-crad.ict.ac.cn.
[22] Moodlens: an emoticon-based sentiment analysis system for chinese tweets J Zhao, L Dong, J Wu, K Xu - Proceedings of the 18th ACM SIGKDD …, 2015 - dl.acm.org.
Discoverying User Interest Using Latent Dirchlet Allocation
CHU Tao-tao
(Computer Science School, Beijing University of Post and Telecommunications, Beijing 100876)
User interest is an important part of the study of micro-blog users,clustering method was used to extract user interest.Due to very sparse features and strong context dependency of the micro-blog's short text, the traditional method can not achieve good results.In this paper,LDA topic model was used on micro-blog's short text to expand features. LDA topic model introducing the implicit theme, through the topic based similarity, to a certain extent, expanded the text features and maked up for the shortcomings of the original feature.When dealing with the ambiguous word,the TBS performance clearly distinguish words of different meanings,solving the problem of context dependency.On this basis, using the text clustering method to extract user interest.The experiments show that,the proposed method effectively solves the problem of sparse features and context dependency.
User interest; Short text; Feature expanding; LDA; K-means
TP391
A
10.3969/j.issn.1003-6970.2016.12.009
国家重点基础研究发展计划(973)(2013CB329606)。
储涛涛(1992-),男,硕士,通信软件技术。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
作文大王·低年级(2022年3期)2022-03-19
河北画报(2020年8期)2020-10-27
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
小学生作文·小学低年级适用(2018年12期)2018-04-11
浙江大学学报(工学版)(2016年2期)2016-06-05
校园英语·下旬(2016年2期)2016-03-18
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
