
基于C4.5算法的入侵检测规则生成与应用
2016-02-07 02:37刁海军
网络安全技术与应用 2016年11期
◆刁海军
(九州职业技术学院 江苏 221116)
基于C4.5算法的入侵检测规则生成与应用
◆刁海军
(九州职业技术学院 江苏 221116)
为有效防范计算机系统安全威胁,提高入侵检测的准确率。可以利用数据挖掘技术,在应用程序的系统调用数据集上进行分类挖掘,从而生成计算机免疫系统中的入侵检测规则,对未知操作进行入侵检测。本文受计算机免疫原理启发,将系统调用序列作为数据源,在对系统调用进行采集的基础上,利用C4.5算法提取规则,比较样本数据集与未知数据集来检验入侵行为,并验证了这种异常入侵检测方法的有效性和可行性。
C4.5分类算法;异常检测;计算机免疫;数据挖掘
0 引言
在计算机系统安全问题日益突出的当下,作为一种主动的安全防御技术,异常检测技术已成为网络安全技术的一个重要研究方向倍受关注。Forrest[1]提出用免疫系统来解决计算机系统的安全问题。即通过监测系统调用的数据流或控制流来发现入侵行为,通过监测系统调用序列构建序列的各种模型来反映程序的控制执行流。该方法借鉴了生物免疫系统的原理,通过“自我”和“非我”来区分计算机系统内部和外来的信息流,并在此基础上完成外来的“非我”信息流的分类鉴别和删除。
硬件设备是执行所有应用程序的基础,没有一种系统调用是可以绕开硬件设备而运行的[2],所以一般入侵者的攻击行为很难避开系统调用。在应用程序执行过程中,其调用系统执行的访问顺序是一个完整的序列,具有很好的稳定性。这样的序列可作为计算机安全系统中的审计数据源。一般而言,系统调用序列之间还存在着一定程度的关联性。因此,本文提出在对多个系统调用序列关系进行分析的基础上发现异常,完成入侵检测。
1 C4.5算法与入侵检测
1.1 C4.5算法
C4.5算法是数据挖掘中一种较为常见的分类算法,这种算法可以帮助我们提取检测规则,属于一种分类决策树算法。[3]该算法具有规则生成容易,计算量小,同时可以清晰地显示哪些字段比较重要。
1.2 入侵检测
入侵检测是对入侵行为的发觉,主要通过对计算机网络或计算机系统中关键信息进行分析,看是否存在违反安全策略的行为[4],以此来发现网络或系统中是否有被攻击的迹象。受计算机免疫原理的启发,将系统调用作为数据源,利用C4.5算法提取规则,比较样本数据集与未知数据集来完成对入侵行为的检验。
2 检测规则的生成
作为入侵检测系统中发现入侵行为的主要依据,检测规则选择是否得当将直接影响系统监测的准确性。检测规则是根据入侵特征提出的,对于基于系统调用的异常检测系统来说,检测规则是通过对系统调用短序列集进行分析后得出的。
2.1 训练样本集的创建
训练样本集生成检测规则的基础,创建一个适当的训练样本集对于建立一个正确的检测规则,以及进行入侵检测都有重要影响。[5]我们从一个正常运行的服务进程中截取了一小段系统调用序列片段来进行检验,截取的片段如图1所示。

图1 正常进程产生的系统调用序列片段
实验结果表明:当我们以6~14这个区间作为滑动窗口时,该模型在准确性方面并没有表现出太大差异。考虑到计算的成本问题,我们采用长度为7的时间窗口,步长为1对上述系统调用序列进行分割处理,得到如下系统调用短序列集,如图2所示。
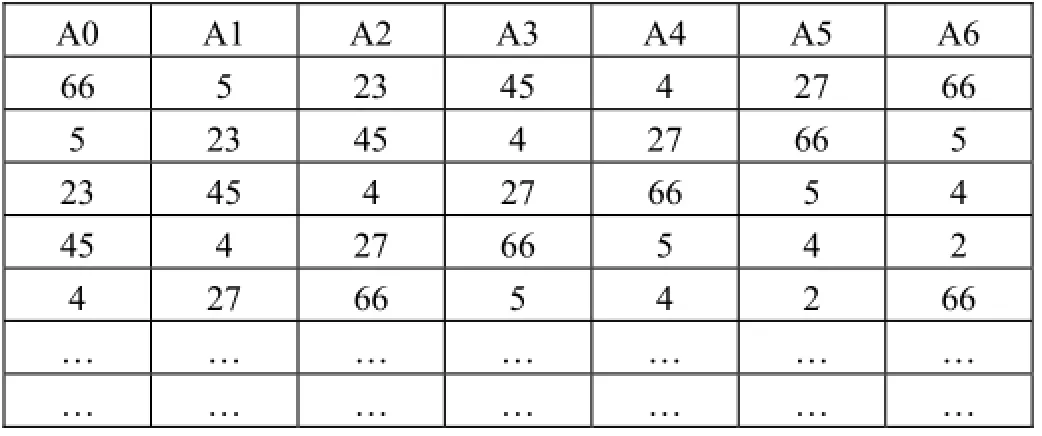
图2 划分后正常进程产生的系统调用序列集
对于正常系统调用短序列集,将其记入N(Normal)库。同样,也需要对异常情况下的系统调用序列进行分割处理,图3中是异常情况下的系统调用片段。

图3 异常进程产生的系统调用序列片段
采用长度为7的时间窗口,步长为1对上述系统调用序列进行分割处理后,就可以得到系统调用短序列集。对于异常系统调用短序列集,将其记入A(Abnormal)库。这样,最终的训练样本集就包括了“正常”与“异常”两个集合,我们需要将两个库进行标识,将N库短序列标识为1,同时将A库标识为0。
由于入侵行为一般是突发的,这样可以认为A库中的短序列大部分是正常的,所以为了提高入侵检测的效率,我们还需要进行数据清洗工作,即如果A库中的短序列与N库中某个短序列完全匹配,则在训练样本集中将A库中的那条短序列删除。进行数据清理后的训练样本集,如图4所示。

图4 训练样本集
2.2 检测规则库的生成
检测规则就是数据挖掘所需要提取的知识,采用C4.5算法进行分类挖掘,检测规则的建立依赖于训练样本集的完备性。按照前面的训练样本集来看,我们将每一条短序列的7个位置作为属性,分别记作A0,A1,A2,A3,A4,A5,A6,同时以0,1作为归属类别,用C4.5分类算法提取规则如下:

(1)中是归属类别为1的规则Rule1/1中A1=105;A7=85说明当A1位置为105并且A7位置为85时,系统调用短序列为“正常”,置信度为0.973;Rule1/2同理。(2)中是归属类别为0的规则Rule1/52中A4=3;A7=128说明当A4位置为3并且A7位置为128时,系统调用短序列为“异常”,置信度为0.996;Rule1/53同理。当然,我们这里只关心class1的规则,即“自我”规则。
通过对“正常”规则的提取,就可以对计算机正常与异常状态进行异常检测。为了提高检测结果的准确性,在选用“自我”规则时,我们一般要求选用置信度在0.800以上的“自我”规则。2.3 基于C4.5算法的检测规则提取
将采集来的训练集进一步划分成为系统调用短序列,再将其按照长度为k,步长为1的滑动窗口划分,得到系统调用短序列,并且在每个短序列后标注上“正常”或“异常”(一般用1表示正常,0表示异常)。将划分好的系统调用短序列集复制到.data文件中。将.data文件输入See5软件中,按照上述提取规则得到提取结果如表1所示。

表1 规则提取结果
3 使用检测规则进行入侵检测
由于一般入侵行为的发生具有突发性和聚集性,入侵行为中的“非我”序列在系统调用序列上会表现出明显的聚集特征。考虑到这一因素,我们选择采用局部统计方法进行入侵检测。
3.1 检测方法
按照数据采集的序列,将整个序列集划分为n个段序列小组,一个序列集作为一个区域。在实际检测过程中,如果某一区域中“非我”调用短序列出现的概率超过设定的阈值r,则可以判定为“非我”进程并结束执行过程。如果,在全部区域都执行完毕且没有出现“非我”调用短序列超过限定阈值,则可以判断其为正常进程。
将已经得到的匹配结果按照宽度为l,步长为h的滑动窗口进行划分,然后在每一个划分后的序列(0,1序列)中统计0的出现概率,最后将得出的所有结果同确定为入侵的临界值进行比较,如果0的出现概率大于预期值则表示该位置发生入侵。
3.2 检测过程及检测结果
我们选取异常程序产生的系统调用短序列集sm-314进行验证性检测,sm-314的短序列具体如下:

我们使用上述方法进行入侵检测,发现0的出现概率为26.11%,通过对检测后形成的输出结果(n2ontimerule4out.txt中的0,1序列)的观察可以发现,前面70%左右的短序列是正常的,异常序列大多集中在最后的30%的短序列中,这是因为在程序运行过程中,前期的系统调用大多是在为程序运行做准备,具体的程序运行主要集中在后半段的系统调用过程中。
我们使用长度为10,步长为1的滑动窗口对输出结果进行局部统计,结果如表2所示。从检测的结果来看,这种方法可以更好地发现突发性入侵,在一定程度上避免了漏判。

表2 局部检测结果
4 结论
C4.5算法相对以前决策树算法的主要改进是:采用了规则后修剪的方法,比以往更加灵活。同时,它可以区分不同的上下文并存在于多条规则中,可以保留更多有效的决策信息。基于C4.5算法的提取规则还可以将未知样本集转化为简单、直观的规则,提高信息的可读性。
考虑到入侵行为的发生具有突发性和聚集性,入侵行为中的“非我”序列在系统调用序列上会表现出明显的聚集特征,需要采用局部统计方法进行入侵检测。受生物免疫启发的入侵检测技术改进可以更好地分辨计算机中的“自我”和“非我”,较好地入侵检测性能,在某种程度上,该方法可以有效提高入侵检测效率和正确性。
[1]Forrest S,Hofmeyr S A,Somayaji A,et al.A sense of self for unix processes[C].In:Proceedings of the 1996 IEEE Symposium on Security and Privacy,Los Alamitos,1996.
[2]Hofmeyr S A,Forrest S,Somayaji A.Intrusion detection using sequences of system calls[J].Journal of Computer Security,1998.
[3]Wang Juan,Yang Qiren,Ren Dasen.An intrusion detection algorithm based on decision tree technology.Asia-Pacific Conference on Information Processing,2009.
[4]张新有,曾华燊,贾磊.入侵检测数据集KDD CUP99研究[J].计算机工程与设计,2010.
[5]向直扬.基于数据挖掘的网络入侵检测研究[D].陕西:西北农林科技大学,2013.
九州职业技术学院中青年骨干教师培养对象资助项目(九州[2016]60号)。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
中国惯性技术学报(2020年2期)2020-07-24
科技创新与应用(2020年6期)2020-02-29
商品与质量(2019年34期)2019-11-29
成都信息工程大学学报(2019年2期)2019-08-28
信息安全研究(2016年4期)2016-12-01
北京理工大学学报(2016年6期)2016-11-22
系统工程与电子技术(2016年7期)2016-08-21
北京航空航天大学学报(2016年12期)2016-02-27
中国信息化·学术版(2013年1期)2013-05-28
