
基于深度自学习的图像哈希检索方法*
2016-01-26 06:22欧新宇,伍嘉,朱恒等
计算机工程与科学 2015年12期
基于深度自学习的图像哈希检索方法*
通信地址:650223 云南省昆明市云南开放大学云南省干部在线学习学院Address:Yunnan Province Cadres Online Learning College,Yunnan Open University,Kunming 650223,Yunnan,P.R.China
欧新宇1,2,伍嘉3,朱恒4,李佶5
(1.云南开放大学云南省干部在线学习学院,云南 昆明 650223;
2.华中科技大学计算机科学与技术学院,湖北 武汉 430074;3.云南开放大学经济与管理学院,云南 昆明 650223;
4.云南大学信息学院,云南 昆明 650091;5.昆明长水国际机场信息部,云南 昆明 650000)
摘要:基于监督学习的卷积神经网络被证明在图像识别的任务中具有强大的特征学习能力。然而,利用监督的深度学习方法进行图像检索,需要大量已标注的数据,否则很容易出现过拟合的问题。为了解决这个问题,提出了一种新颖的基于深度自学习的图像哈希检索方法。首先,通过无监督的自编码网络学习到一个具有判别性的特征表达函数,这种方法降低了学习的复杂性,让训练样本不需要依赖于有语义标注的图像,算法被迫在大量未标注的数据上学习更强健的特征。其次,为了加快检索速度,抛弃了传统利用欧氏距离计算相似性的方法,而使用感知哈希算法来进行相似性衡量。这两种技术的结合确保了在获得更好的特征表达的同时,获得了更快的检索速度。实验结果表明,提出的方法优于一些先进的图像检索方法。
关键词:自学习;感知哈希算法;栈式自编码算法;无监督学习;图像检索
1引言
基于内容的图像检索[1~4]的核心思想是通过比较图像的语义相似性,从图像数据库中找出与查询图像最相近的图片集合,并根据相似度进行排序。在大规模的图像检索任务中,相似性的度量通常是采用一种有效的索引结构来对整幅图像进行全局描述。例如,倒排文档[5]、哈希算法[6]和基于颜色空间的直方图[2]。然而,由于查询目标的多样性,简单的全局相似性衡量并不是总能得到较满意的结果。例如,方向梯度直方图(HoG)特征[4]比较适合描述结构复杂的图像,而具有颜色显著性的图像又适合于使用基于颜色、纹理特征的检索[3]。因此,如何用同样的算法高效地完成不同分布图像的检索成了基于内容的图像检索的关键。要实现这一目标,需要解决以下两个方面的问题:
(1)对图像提取更深层次、更普遍的特征,例如高层的语义信息,并将特征转换成可表达的形式。
(2)对于提出的特征,寻找一种更加快速的方法进行检索,以保证检索算法的实时性。
对于第(1)个问题,本文将深度学习引入到特征学习中。深度学习[7~9]展现了其在这方面的强大性,利用深层次的网络,算法可以实现图像信息的语义化学习,将原始的像素表达变成一种可识别的信息。与此同时,深度网络可以轻松地输出特征表达,用于分类或检索。
对于第(2)个问题,本文采用了一种快速的相似性对比技术——哈希编码,相对于传统的欧氏距离的衡量方法,哈希算法[6,10],特别是感知哈希算法,具有更优秀的性能。
2相关工作
通常如果有一个足够强大的机器学习算法,为了获得更好的性能,最有效的方法之一是给这个算法提供更多的数据。人们总是可以尝试获取更多的已标注的数据,例如,使用手工标注,或采用类似亚马逊土耳其机器人AMT(Amazon Mechanical Turk)[11]的自动标注工具,然而这种方法成本很高,并且难以完成,特别是在大数据下并不现实。如果算法能够从未标注的数据中学习特征,那么我们可以轻易获得大量无标注的数据,并从中学习到有用的特征。尽管一个已标注的样本蕴含的信息远比未标注的样本信息多,但如果能让算法有效地利用大量无标注的数据,将比大规模的手工构建特征和标注数据,获得更好的性能。自学习可以利用大量未标注的数据,学习出较好的特征描述。在解决一个具体的分类或检索问题时,可以基于这些学习出的特征和任意的已标注的数据(可能是少量的),使用有监督学习方法完成微调,并进一步提高分类和检索的性能。
无监督特征学习和深度学习作为机器学习的方法被用来从无标注的数据中进行特征提取。近来有很多基于无监督学习框架成功的案例文献,例如RBMs[12]、autoencoders[13,14]、sparse coding[15]、K-means[16]。本文利用无监督学习和感知哈希技术相结合,扩展到图像检索领域,获得了较好的效果。
3基于自学习的特征提取
3.1 无监督特征学习
无监督特征学习,通常有两种方式,一种是带限制性条件的半监督学习,它要求未标注的样本xu和已标注的样本xl具有相同的分布,可以想象的是,在实践中常常无法满足这种要求。自学习(Self-Taught Learning)[17]是一种更为一般、更强大的学习方式,它不要求未标注的样本xu和已标注的样本xl来自同样的分布。图1显示了本文提出的基于深度自学习哈希的图像检索方法的通用框架,包含两个明显的步骤:离线阶段和在线阶段。离线阶段通过未标注的数据训练一个稀疏自编码网络,从中得到有用的特征。然后利用该训练好的神经网络去训练待查询数据,并将其生成的特征通过哈希算法生成哈希编码。在线阶段,同样将查询数据输入到训练好的神经网络中生成特征,之后将该特征利用训练阶段相同的哈希算法生成哈希编码,再计算该编码与已生成的训练数据哈希编码的汉明距离,从而获得检索结果。

Figure 1 Workflow of self-taught learning hashing for image retrieval图1 基于自学习的图像哈希检索方法工作流程图
3.2 数据预处理
(1)简单缩放:将原始数据的每一个维度的值进行重新调节(对于彩色图像分别对每个通道独立操作),使得数据最终落在[0,1]的区间内。具体如公式(1)所示:
xi=xi/255
(1)
(2)逐样本均值消减:对图像的每个数据点移除该样本的均值,实现移除直流分量,即移除图像平均亮度,因为通常我们对图像的亮度并不感兴趣。如果x(i)∈Rn代表图像I的每一个像素的亮度(灰度值)值,则可用以下算法进行零均值化:
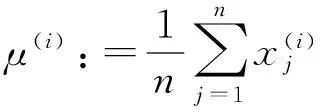
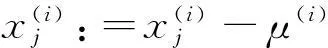
(3)白化:该步骤的主要目的是去除相邻像素之间的相关性,降低输入的冗余性,简单地说,通过白化操作,可以使学习算法的输入具有:特征间相关性较低、所有特征具有相同方差的性质。同时,白化也类似于一个低通滤波器,它可以将高频部分过滤掉,这有助于抑制噪声。常见的方法包括PCA白化和ZCA白化。考虑到本文的算法不需要事先对数据进行降维,因此ZCA方法进行白化处理更合理。假设有R是任意正交矩阵(或旋转或反射矩阵),即满足RRT=RTR=I,令R等于特征矩阵U,即R=U,可以定义ZCA白化的结果为:

3.3 自编码神经网络
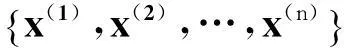


(2)
其中,第一项J(W,b)是均方差项,第二项是规则化项(也叫权重衰减项),主要用于降低权重的幅度,防止过拟合,其中λ是权值衰减参数,本文实验中λ=0.003。
梯度下降每一次迭代都按照如下公式对W和b进行更新:

(3)
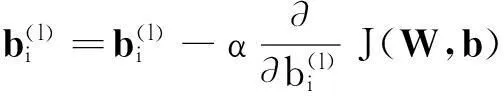
(4)

(1)进行前向传导计算,利用式(3)的前向传导公式,得到L2,L3,…,Lnl层的激活值。
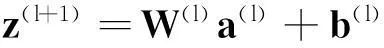

(2)对输出层,计算残差:

(3)对各隐层,计算残差:

(4)计算偏导值:
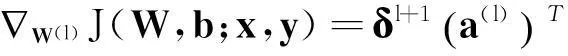
(5)

(6)
在获得了关于W(l)和b(l)的偏导值之后,将式(5)和式(6)分别代入式(3)和式(4)中,通过批量梯度下降算法的迭代步骤来最小化代价函数J(W,b)的值,进而求解神经网络。
3.4 稀疏性





其中J(W,b)如式(2)所定义,而β是控制系数性惩罚因子的权重,本文中β=3。
类似地,隐层的残差也修正为:
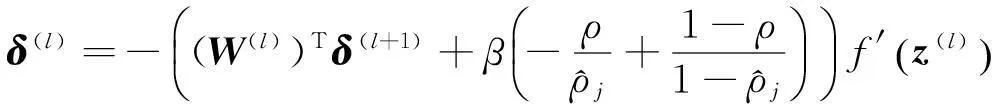
3.5 栈式自编码算法与自学习网络
深度学习相比传统神经网络的一大优点是逐层贪婪算法,通过将自编码器“栈化”到逐层贪婪训练法中,可以预训练整个深度神经网络。栈式自编码神经网络是一个由多层稀疏自编码器组成的神经网络,其前一层自编码器的输出作为后一层自编码器的输入。逐层贪婪算法首先利用原始输入来训练网络的第一层,得到其参数W1、b1;然后网络的第一层将原始输入解码成为由隐藏单元激活值组成的向量A,接着把A作为第二层的输入,接着训练第二层的参数W2、b2;以此类推,采用同样的方法得到第n层Wn、bn,即输出层的参数。在训练每一层参数的时候,固定其他各层参数保持不变。为了得到更好的结果,在预训练完成之后,可以通过反向传播算法同时调整所有层的参数以改善结果,这个称为微调(Fine-Tuning)。图2是一个包含三个隐层神经元的基于栈式自编码的自学习网络。可以看到,特征层一直接使用x作为输入,然后将生成的结果作为特征层二的输入;相似地,特征层三也使用特征层二的输出作为输入;最后特征层三的输出被直接当作样本的特征表达,进行后续处理。

Figure 2 Self-taught learning network based on stacked autoencoders图2 基于栈式自编码网络的自学习网络
4基于感知哈希的检索
得到了图像的特征表达之后,通过感知哈希算法可以获得最终的检索结果,算法的主要步骤如下:
(1) 利用哈希激活函数将特征码转换成[0,1]的表达。
Y=sigmoid(X)
其中,X为输入图像矩阵,Y为经过sigmoid函数所生成的像素值规范到[0,1]的变换矩阵。
(2) 分别计算每个图像所有特征值的平均值。
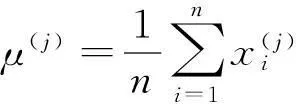

(3) 二值化。
比较特征值与均值的大小,并进行二值化,大于均值的记为1,小于或等于均值的记为0。
(4) 计算哈希值。
将上述的比较结果组合起来构成一个n位的二值整数,这就是一幅图片的指纹。这个组合的顺序并不重要,只需要保证所有采样图片都采用同样的次序。
(5) 哈希检索。
在得到指纹后,将图片库的图片与待检索图片进行按位比对,并根据相同位数的个数进行升序排列,获得有序的检索结果。这一步相当于计算两个指纹的汉明距离:

5实验及结果分析
本文在MNIST数据集上评估了自学习哈希(STLH)算法在不同条件下的性能,并且对比了目前四种比较优秀的二进制哈希算法:LSH(Locality Sensitive Hashing)[18]、SH(Spectral Hashing)[6]、SSH(Semi-Suppervised Hashing)[17]和RBMs(Restricte Boltzmann Machines)[19]。所有实验均基于Windows 8.1 x64操作系统,1.8 GHz CPU和8 GB RAM内存。
MNIST默认包含70 000个手写数字样本,其中训练样本60 000个,测试样本10 000个,每个样本大小为28*28像素,每个采样数据都被分配了0~9中的一个标签。为了验证无监督学习的有效性,我们仅使用了原始的60 000个训练样本,将其中共计29 404个5~9的数字作为无标签数据用于训练学习算法,并对剩余的0~4的数进行训练,学习特征。0~4的数字平均分成两部分,其中15 298个数字作为训练集去学习哈希函数和结构化哈希查询表,剩下的15 298个0~4的数字作为测试算法效率的测试数据。图像的灰度值直接作为768维特征向量被使用。对于LSH算法,随机选择零均值和单位协方差的高斯分布去构造哈希表。对于RBMs,直接使用Torralba A等[20]提出的神经网络结构和参数。
本文使用汉明排序来量化评估检索性能。汉明距离使用每一个测试样本在训练样本中的查询结果进行计算和排序。查询结果根据返回图像的距离进行排序,并依据其对应的语义标签来计算其准确性。图3a展示了8位、16位、32位、48位、64位、96位、128位、256位共计8组不同的编码长度下,整个样本的平均正确率曲线。可以看到相比其他学习方法,STLH方法始终具有2倍的图像检索正确率。此外,图3b显示了48位编码下的平均正确率-召回率曲线,可以看出STLH算法在汉明空间中具有较大的性能优势。图3c是不同算法的训练时间,RBMs算法具有最昂贵的训练代价,大约是其他算法的3个数量级,而STLH也有2个数量级的训练代价。由于算法的训练是离线完成的,并不直接影响查询的效率,因此该代价是可以接受的。与此同时,对于查询时间来说,RBMs需要10倍的时间通过训练好的神经网络去计算二进制代码;SH算法生成编码的时间略多于其他三种算法;STLH算法虽然使用的是神经网络,但由于它具有较简单的结构,因此其特征码生成时间几乎和LSH和SSH算法相当。总体来看,特征码生成时间可以排序为:RBMs≫SH>TLSH≈SSH≈LSH。
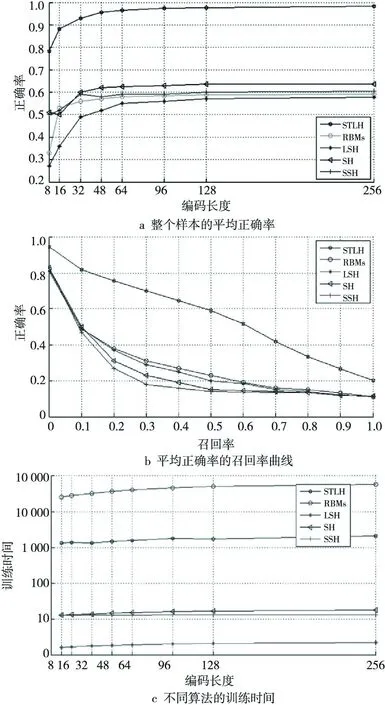
Figure 3 Petrieval performance comparison of the five methods on MNIST dataset图3 MNIST数据集上五种方法的检索性能对比图
为了可视化最近邻的查询质量,本文在图4中展示了一个样本分别使用五种不同算法的查询结果。其中最左边的第一个框内的数字是待查询样本,由上至下分别是使用了48位编码的LSH、SS、RBMs、SSH、STLH算法的检索结果。可以看出STLH算法和SSH算法在前49个查询结果中都获得了100%的正确率,算法效果都很理想。
为了比较不同的输出编码长度对检索效果的影响,我们使用了正确率-召回率曲线来衡量算法的性能。其中:

在图5中可以看到,随着编码长度的增加,图像检索的性能也随着增加。这主要是因为在自我学习网络中,较多的隐层神经元可以学习到更多丰富的细节特征,从而提高图像的识别能力,而最后一个隐层神经元的数量即图像最终的编码长度,因此编码长度直接影响了图像最终的检索性能。在MNIST数据集上,当输出的隐层神经元增加到64个时,算法的性能基本上趋于稳定。这主要是因为MNIST数据集的样本属于灰度图像,且前景和背景颜色具有较高的对比度,因此不需要太多的神经元就可以学习到较好的特征。

Figure 4 Retrieval results of the five methods on MNIST dataset图4 五种算法在MNIST数据集上距离最近的49个查询结果图

Figure 5 PR-curve of different code length图5 不同编码大小的正确率-召回率曲线
图6展示了不同深度(STLH-1~4分别代表包含1~4个隐层的自学习网络)的自学习网络对检索性能的影响,可以看到由于MNIST数据的特殊性,更深层次的网络并没有对性能有所提升,相反随着神经网络深度的增加,梯度逐渐产生了衰减,反而影响了整体的平均性能。但是,可以预测的是,当使用较复杂的彩色图像进行训练,更深的神经网络可以比浅层的神经网络获得更好的性能,因为它可以学到更丰富的细节特征。

Figure 6 PR-curves of different depths图6 不同深度的网络下的正确率-召回率曲线
6结束语
本文提出了一种利用自学习神经网络去高效地学习图像的哈希表达的方法,并进一步进行检索排序。该方法通过无标注的数据去训练自学习网络,这有效地回避了获取大量已标注数据的困难,同时,利用自学习网络的深度神经网络的优点,学习到了比其他算法更好的特征表达。同时利用感知哈希算法,进行特征检索,大大地提高了检索的性能。实验表明,本文提出的算法不仅是有效的,而且还获得了较好的效果。
参考文献:附中文
[1]Jegou H,Douze M,Schmid C.Product quantization for nearest neighbor search [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(1):117-128.
[2]Wang Jian-feng,Xiao Guo-qiang,Jiang Jian-min.An image retrieval algorithm based on the HSI color space accumulative histogram [J].Computer Engineering & Science,2007,29(4):55-58.(in Chinese)
[3]Wu Yong-ying,Ma Xiao-fei.Implementation of the CBIR system based on colour,space and texture features [J].Computer Engineering & Science,2005,27(6):40-42.(in Chinese)
[4]Cai Li-jun.Research on content-based image retrieval with relevance feedback[D].Kaifeng:Henan University,2013.(in Chinese)
[5]Liu Jin-ling.Chinese junk SMS retrieval based on query words expansion[J].Computer Engineering,2011,37(8):52-54.(in Chinese)
[6]Weiss Y,Torralba A,Fergus R.Spectral hashing[J].Proc NIPS, 2008,282(3):1753-1760.
[7]Krizhevsky A,Sutskever I,Hinton G E.Image netclassification with deep convolutional neural networks[C]∥Advances in Neural Information Processing System,2012:1.
[8]Oquab M,Bottou L E O,Laptev I,et al.Learning and transferring mid-level image representations using convolutional neural networks[C]∥Proc of IEEE Conference on Computer Vision and Pattern Recognition,2014:1.
[9]Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[J].arXiv preprint arXiv:1311.2524.2013.
[10]Lu Min, Huang Ya-lou, Xie Mao-qiang, et al. Rank hash similarity for fast similarity search [J].Information Processing & Management,2013,49(1):158-168.
[11]Ipeirotis P G. Analyzing the Amazon mechanical turk marketplace[J].XRDS:Crossroads,The ACM Magazine for Students,2010,17(2):16-21.
[12]Hinton G E,Osindero S,Teh Y.A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18(7):1527-1554.
[13]Hinton G E.Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.
[14]Bengio Y, Lamblin P, Popovici D, et al.Greedy layer-wise training of deep networks[C]∥Advances in Neural Information Processing Systems,2007:153.
[15]Lee H,Battle A,Raina R,et al.Efficient sparse coding algorithms[C]∥Advances in Neural Information Processing Systems,2007:801.
[16]Coates A,Ng A Y,Lee H.An analysis of single-layer networks in unsupervised feature learning[J].Journal of Machine Learning Research,2011,15:215-223.
[17]Wang J, Kumar S, Chang S.Semi-supervised hashing for scalable image retrieval[C]∥Proc of CVPR’10,2010:1.
[18]Gionis A,Indyk P,Motwani R,et al.Similarity search in high dimensions via hashing[C]∥Proc of International Conference on Very Large Data Bases,2000:518-529.
[19]Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.
[20]Torralba A,Fergus R,Weiss Y.Small codes and large image databases for recognition[C]∥Proc of IEEE Conference on Computer Vision & Pattern Recongnition,2008:1-8.
[2]王剑峰,肖国强,江健民.基于HSI色彩空间累加直方图的图像检索算法[J].计算机工程与科学,2007,29(4):55-58.
[3]吴永英,马笑飞.基于颜色、空间和纹理特征的CBIR系统实现[J].计算机工程与科学,2005,27(6):40-42.
[4]蔡利君.基于内容的交互式图像检索技术的若干问题研究[D].开封:河南大学,2013.
[5]刘金岭.基于查询词扩展的中文垃圾短信检索[J].计算机工程,2011,37(8):52-54.

欧新宇(1982-),男,云南昆明人,博士,副教授,CCF会员(E200038862G),研究方向为深度学习、机器学习、图像检索和计算机视觉。E-mail:ouxinyu@hust.edu.cn
OU Xin-yu,born in 1982,PhD,associate professor,CCF member(E200038862G),his research interests include deep learning,machine learning,image retrieval, and computer vision.

伍嘉(1976-),女,云南昆明人,副教授,研究方向为计算机科学与教育、多媒体技术和电子商务。E-mail:252586696@qq.com
WU Jia,born in 1976,associate professor,her research interests include computer science and education,multimedia technology, and e-Commerce.

朱恒(1981-),男,云南昆明人,硕士,助理研究员,研究方向为软件工程和信息检索。E-mail:39208790@qq.com
ZHU Heng,born in 1981,MS,assistant researcher,his research interests include software engineering, and information retrieval.

李佶(1989-),男,云南昆明人,助理工程师,研究方向为计算机软件工程、数据库和集群计算。E-mail:mrli2002@hotmail.com
LI Ji,born in 1989,assistant engineer,his research interests include software engineering,database, and cluster computing.
Image hashing retrieval method based on deep self-learning
OU Xin-yu1,2,WU Jia3,ZHU Heng4,LI Ji5
(1.Yunnan Province Cadres Online Learning College,Yunnan Open University,Kunming 650223;
2.School of Computer Science & Technology,Huazhong University of Science and Technology,Wuhan 430074;
3.School of Economics and Management,Yunnan Open University,Kunming 650223;
4.School of Information Science and Engineering,Yunnan University,Kunming 650223;
5.Department of Information,Kunming Changshui International Airport,Kunming 650000,China)
Abstract:Convolutional neural networks are an established powerful self-learning ability in image recognition tasks. However, supervised deep learning methods are prone to over-fitting when the labeled data are small or noisy. To solve these problems, we propose a novel deep self-learning image hashing retrieval method, an unsupervised learning. First, we can obtain a function with discriminative features via unsupervised auto-encoding networks, which reduces learning complexity, thus enabling training images not to rely on their semantic labels. The algorithm is, therefore, forced to learn more robust features from the massive unlabeled data. In order to speed up the query, a perceptual hash algorithm is employed. The combination of these two techniques guarantee a better feature description and a faster query speed without depending on labeled data. Experimental results demonstrate that the proposed approach is superior to some of state-of-the-art methods.
Key words:self-learning;perceptual hash algorithm;stacked auto-encoding algorithm;unsupervised learning;image retrieval
作者简介:
doi:10.3969/j.issn.1007-130X.2015.12.029
中图分类号:TP391.7
文献标志码:A
基金项目:云南省教育厅应用基础研究计划资助项目(2012Y503);云南省科技厅应用基础研究计划项目青年资助项目(2012FD064);云南开放大学科学研究基金资助项目(2014-05);国家自然科学基金资助项目(61274092)
收稿日期:修回日期:2015-03-13
文章编号:1007-130X(2015)12-2386-07
