
基于跨语言语料的汉泰词分布表示*
2016-01-26 06:48张金鹏,周兰江,线岩团等
计算机工程与科学 2015年12期
基于跨语言语料的汉泰词分布表示*
通信地址:650500 云南省昆明市昆明理工大学信息工程与自动化学院Address:School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,Yunnan,P.R.China
张金鹏1,2,周兰江1,2,线岩团1,2,余正涛1,2,何思兰3
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;
2.昆明理工大学智能信息处理重点实验室,云南 昆明 650500;3.昆明理工大学理学院,云南 昆明 650500)
摘要:词汇的表示问题是自然语言处理的基础研究内容。目前单语词汇分布表示已经在一些自然语言处理问题上取得很好的应用效果,然而在跨语言词汇的分布表示上国内外研究很少,针对这个问题,利用两种语言名词、动词分布的相似性,通过弱监督学习扩展等方式在中文语料中嵌入泰语的互译词、同类词、上义词等,学习出泰语词在汉泰跨语言环境下的分布。实验基于学习到的跨语言词汇分布表示应用于双语文本相似度计算和汉泰混合语料集文本分类,均取得较好效果。
关键词:弱监督学习扩展;跨语言语料;跨语言词汇分布表示;神经概率语言模型
1引言
词汇表征问题是自然语言处理的重要内容,是信息检索、数据挖掘、知识图谱构建等研究方向的重要技术支持。基于统计机器学习的词汇表征方法的目标是从自然语言文本中学习出词序列的概率表示函数,其面临的一个困难在于词向量的维度灾难与数据稀疏问题[1],在训练的过程中每一个词序列与其它训练语料中的词序列在离散空间表示时有很大的不同。在单语词汇的空间表示过程中,一个传统但有效的方法是n元语法模型,它通过学习目标词汇一个短的窗口信息来预测目标词汇出现的概率。它的缺点在于不能反映窗口以外的词对序列生成概率的影响及相似词序列的分布概率的相似性[2]。BengioY等人[2]在2001年提出的神经概率语言模型在单语环境中较好地解决了这个问题。神经概率语言模型通过从自然语言文本中获取句法语义信息学习出词语的分布表示特征,对相似的词序列有相似词分布,CollobertR等[3]验证了词分布能很好地应用于词性标注、命名实体识别、语义角色标注等自然语言问题。虽然单语词汇分布表示上取得了不错的效果,但在跨语言自然语言处理领域的国内外研究稀少,目前主要有两种方法:第一种是迁移学习[4~7],该方法将标记学习信息从一种语言迁移到另一种语言,使得资源较少的语言获得较好的处理效果。ZemanD等[4]在跨语言句法树库建设上验证了该方法,但该方法有较大的局限性,其效果直接依赖于知识转移的过程,不同的跨语言自然语言处理任务有不同的迁移方法。第二种方法将两种语言转化为其中一种语言或第三方语言上,用一种语言表达跨语言信息[8~10]。SteinbergerR等[8]在跨语言文本相似度计算上应用了该方法。但这些方法无一例外依赖已有的双语翻译概念词典(如WordNet)的质量或统计语料共现信息来计算跨语言词之间的相似度,需要解决译词歧义问题,过程复杂,效果有限。
以上方法在处理跨语言自然处理问题上都取得了一定的效果,但都存在可移植性不强、算法过程复杂、准确性存在提升空间的缺点。目前,主流的文本层面分析方法只考察名词、动词的分布特征,借鉴这一思想,本文针对以上存在的问题分析汉语、泰语名词、动词的分布相似性,将泰语名词、动词看做汉语名词、动词,将泰语词嵌入到汉语语料中,生成汉泰跨语言词汇序列语料,通过神经概率语言模型学习泰语名词、动词在跨语言空间中的分布。通过这种方式将在跨语言语料中学习得到的汉泰跨语言词向量分布表示,直接应用到泰语文本,解决泰语学习语料资源缺少和跨语言文本分析问题。本文基于汉语、泰语跨语言文本分类和文本相似度实验,验证了汉语、泰语跨语言词汇分布表示的效果。
本文第2节介绍了神经概率语言模型,第 3节介绍了汉语泰语跨语言语料生成方法,第4节对本文的方法进行了测试与评价。
2神经概率语言模型
神经概率语言模型[2]由BengioY等人于2003年第一次提出,基于人工神经网络来学习一种语言的词汇序列的联合概率函数,目前已经在自然语言处理各个领域得到了广泛应用,并取得不错的效果。该模型同时学习每个词的分布和表示词序列的概率函数。模型可以得到泛化是因为一个从未出现的词序列,如果它是由与它相似的词(在其附近的一个代表性的意义上)组成过已经出现的句子的话,那么它获得较高的概率。它有效地解决了词典向量语言空间的维度灾难与数据稀疏问题,同时解决了n元语法模型不能解决的分布相似问题,从而相比词典向量及n元语法模型可更好地表示词汇的分布。
神经概率语言模型的描述如下:
通过给定的词序列w1,…,wt,其中wt∈V,V代表目标语言所有的词汇集,V虽然很大但有限,神经语言模型的目标是要学到一个好的函数来估计词汇的条件概率:
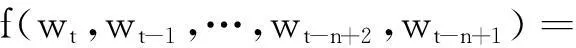
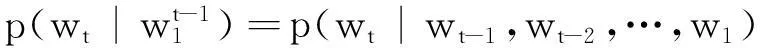
(1)

公式(1)包括两个过程:
(1)首先构建映射C将词汇集V中的任意元素映射到词的特征向量C(i) ∈Rd,它代表关联词表中词的分布特征向量,d代表特征向量的维度。实验中被表示为|V|*d的自由参数矩阵。
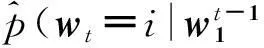

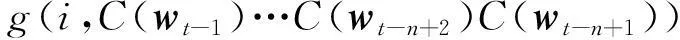
(2)
f由以上映射C与g组合而成,这两个映射都关联一些参数。映射C的参数就是特征向量本身,被表示成一个|V|*d的矩阵C,C的第i行是词i的特征向量。函数g可由前馈神经网络或卷积神经网络实现。式(2)表明函数f通过上下文词来预测词表中第i个词最终转化为函数g通过上下文词的分布特征向量来预测第i个词的分布。
3汉泰跨语言词分布表示
3.1 汉语与泰语的词序列分布特点
汉语与泰语有较大程度的相似性,它们在语法上有很多共同点。例如针对同一句话:汉语的句法结构为(+定语)主语+(+状语)谓语+(+定语)宾语(+补语);而泰语的句法结构为主语(+定语)+谓语+宾语(+定语)(+状语或补语),两种句子的主干:主谓宾序列关系完全一致,主要差异体现在泰语的定语、状语必须放在中心词之后,而汉语的定语、状语必须放在中心词之前。从句子的组成来讲,主干反映句子的主要内容,定状补是枝叶成分可有可无,两种语言主干主谓宾成分是完全一致的,主谓宾对应词性中的名词、动词,两者句子主干结构一致。两种语言名词、动词的词序列的分布也应该是有相似性的。
正是由于汉语与泰语在以上句子词序列上的主干相似性决定在同一分布空间下用相同维度向量表征名词、动词的分布成为可能,在自然语言处理中,文本分析只考察名词、动词,解决了名词、动词的跨语言词分布问题也就解决了跨语言文本分析问题。
我们的目标旨在忽略中泰两种语言的差异,将泰语名词、动词看做汉语名词、动词,在汉语的语言环境下学习它们的分布,从而使较为成熟的汉语的文本分析方法可以直接应用在泰语文本上。
3.2 平行语料预处理
我们选取从中国广播电台获取并人工校正得到平行句对10 216对。尽管原始文本包含所有的文本信息,但是目前的自然语言处理技术无法完全处理这些文本信息,因此,需要对文本进行预处理。传统的文本预处理主要是去除停用词,如“的”“地”等。由于本文的方法需要对词的序列分布进行学习,所以我们没有去除停用词,但我们将一些与汉泰文本内容无关的符号(“#、*”等)、无意义数字去除,并将一些人名等转化为统一的符号,避免因为人名的变化造成对词序列分布学习的影响,减少噪声干扰。
3.3 平行语料词对齐
我们将以上处理后的平行语料输入GIZA++[11]中,实现汉泰双语词对齐。GIZA++是包含IBM1-5训练模型及隐马尔可夫模型的统计机器学习工具包。GIZA++有几种词对齐启发式算法,我们主要使用交叉启发式算法,通过运行从汉语映射到泰语及从泰语映射到汉语两个方向来获取对齐词对。我们只考虑在两个方向都有的对齐词对。通过词对齐我们可以获取一个词语在平行语料中相应的跨语言翻译词。
例句:
(1)今天/0 下午/1 我们/2 要/3 打/4 篮球/5
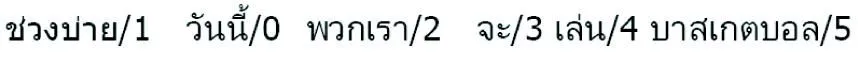

3.4 泰语词与汉语词相似关系替换

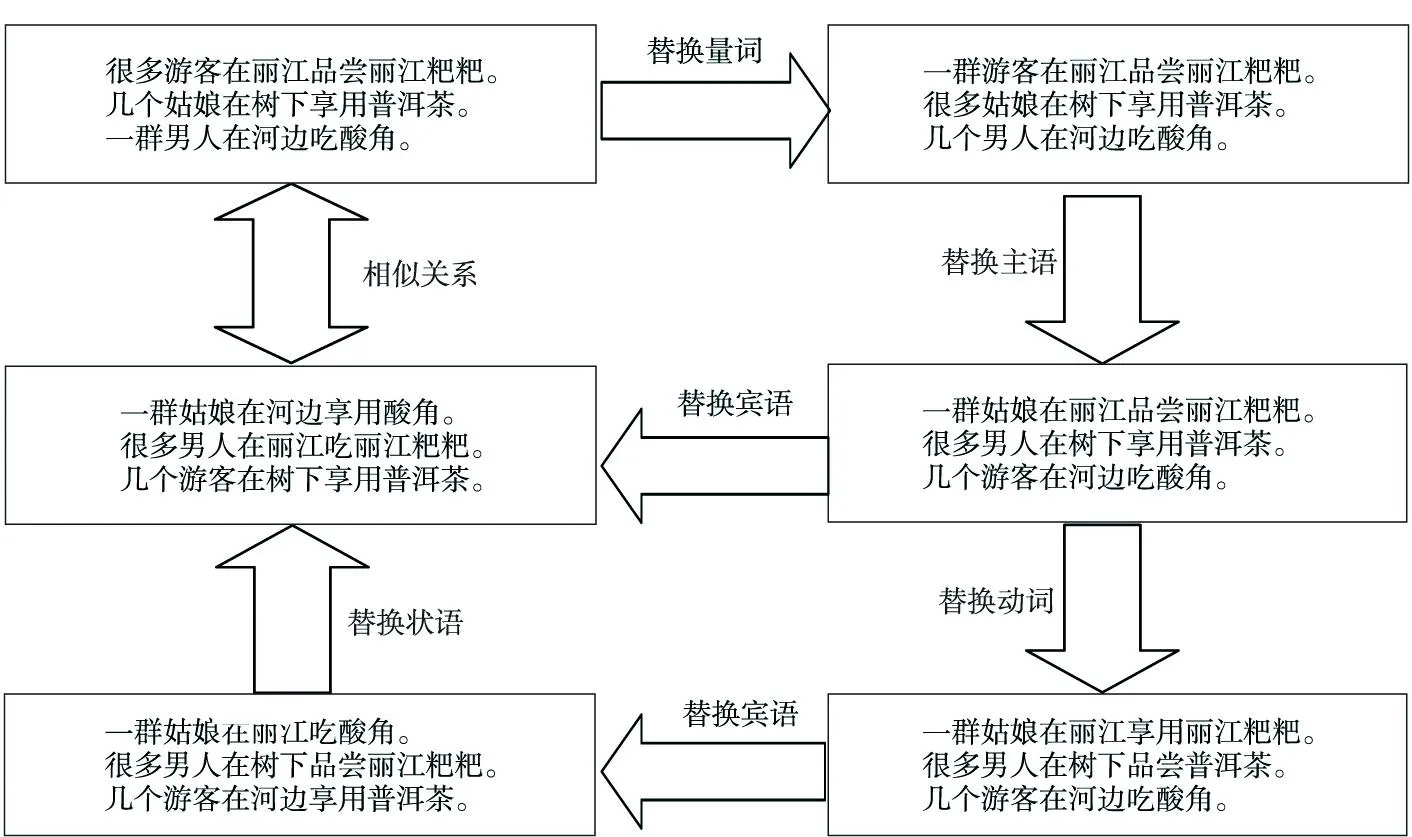
Figure 1 Word distribution example with word sequence similarity图1 词序列相似词分布示例
虽然通过WordNet可以考察汉语词与泰语词之间的语义关系对齐,但我们将语义词对齐泛化为更一般的情况,在自然语言词的序列分布中,只要是相似的语法语义角色就会有相似的词序列分布,即词相似则词在自然语言文本的词序列中的分布也相似。例如有以下实例集:(1)很多游客在丽江品尝丽江粑粑。(2)几个姑娘在树下享用普洱茶。(3)一群男人在河边吃酸角。对以上三个实例可以进行如图1所示的转化。
从图1的三个实例句的成分可以看出,量词“很多、一群、几个”在句子集中可以相互替换位置,替换后它们各个句子的词序列联合概率分布仍是相似的。反映在神经概率语言模型中条件概率表达为:
P(很多|游客,在,丽江,品尝,丽江粑粑)≈P(几个|姑娘,在,树下,享用,普洱茶)≈P(一群|男人,在,河边,吃,酸角)
同理,主语“姑娘、男人、游客”,状语“丽江、树下、河边”,动词“吃、品尝、享用”,宾语“酸角、丽江粑粑、普洱茶”都可以相互替换。替换过之后的句子词序列联合概率分布仍与原句子序列联合概率分布相似,即两个句子在神经概率语言模型空间上的分布表示向量夹角余弦值接近于1或者欧氏距离较小。表达为如下公式:
V(很多|游客,在,丽江,品尝,丽江粑粑)≈V(一群|姑娘,在,河边,享用,酸角)
由于在平行句对中,与每句泰语平行对齐的汉语句子是其译句,如果泰语句子中的泰语词汇“thwordi”对应的汉语译句中的汉语词“chwordi”,而汉语词“chwordi”与其他汉语词“chwordj”存在上例所说的相似对齐,我们认为泰语词“thwordi”与汉语词“chwordj”相似分布对齐。我们将“thwordi”与“chwordj”的这种对齐方式在本文中定义为原理1。
在神经概率语言模型中,相近的词序列会有相近的分布概率表示,由于模型的平滑性,分布的微小改变会造成词的预测概率的微小改变,同时训练语料中任何一个实例句子的词的出现不仅会影响这个词所在句子的联合概率分布,也会影响到所有相似(邻近)实例句子的联合概率分布[12]。例如,有以下三个实例句:
(1)很多游客在丽江喜欢品尝丽江粑粑。
(2)游客在丽江喜欢品尝丽江粑粑。
(3)很多游客在丽江品尝丽江粑粑。
“游客”这个词在实例句(1)中的分布概率改变会影响到游客在实例(2)、(3)中的分布概率表示。即“游客”这个词在实例(1)~(3)中也是词序列中分布概率表示相似的。实例(1)~(3)中的任何一个在训练语料中的词序列变化都会影响到其余两个实例最后的概率分布表示。我们认为实例(1)中的“游客”跟实例(2)、(3)中的“游客”是相似的。因此,如果泰语句子对应的汉语译句为实例(1),泰语词“thwordi”对应实例(1)中的游客,则“thwordi”与实例(2)、(3)中的“游客”一词也为相似分布对齐。我们在本文中定义这个原理为原理2。
基于神经概率语言模型的原理1与原理2,我们通过3.3节的工作可以获得泰语句子中的每个泰语词“thowrdi”对应的汉语译句对应的汉语词“chwordi”。我们将已经通过神经概率语言模型对平行句对中的汉语句子语料集进行训练得到每个词在汉语语料中的分布表示。如果泰语实例句中的泰语词“thwordi”对应的汉语词“chwordi”的分布表示与其他汉语词“chwordj”的分布表示相近,我们就认为“thwordi”与“chwordj”在神经概率语言模型中相似分布对齐(即它们扮演相似的语法语义角色)。我们把“chwordj”与“thowrdi”的这种相似传播过程称为相似传递。
遍历语料中所有汉语句子,本文通过相似传递统计出每个泰语词“thwordi”与其它汉语词“chwordj”(“chwordj”不为“thwordi”的互译词)的相似对齐实例。我们通过泰语词“thwordi”与满足相似对齐的其它汉语词“chwordj”,在汉语实例中相应位置的“chwordj”替换为泰语词“thwordi”生成新的实例,对语料中的每个泰语名词、动词重复以上过程,直到所有泰语名词、动词都嵌入它们在汉语实例中应有的位置,这个过程中我们不考虑已经在3.3节中计算过的互译对齐词。如果泰语词与汉语词之间的替换衍生实例越多,则说明它们之间的相似程度越高,最后通过神经概率语言模型学习到的词分布越接近。
我们将衍生实例与汉语实例一同作为学习语料进行学习,因为通过衍生实例我们可以学习到泰语名词、动词在汉语语言环境下应有的词分布。通过这个过程使汉语名词、动词与泰语相似的名词、动词有相近的分布,实现汉泰跨语言词汇在同一模型空间下的分布表示。
3.5 大规模汉泰混合语料弱监督学习扩展过程
基于以上分析,我们在第一次跨语言混合语料集中学习得到每个泰语词相似度高于一定阈值的汉语词,并对这些汉语泰语词通过synset_id转化为英文,在英语WordNet中进行查询,如果汉语词与泰语词属于同类关系或者直接上义词,我们都将泰语词替换汉语词相应的位置,生成新的衍生实例。这个阈值如果选取过高,将很难学习到新的汉语相似词,如果阈值选取过低,则学习得到新的汉语词相似度太低,很多情况下不能替换,我们把阈值设为0.5。
我们对包含泰语词的语料进行如下过程的弱监督学习扩展:

Figure 2 Learning flow chart of Chinese and Thai cross-lingual word distribution图2 汉泰跨语言词汇分布学习流程图
(1)将泰语词与汉语词的相似度进行比较,如果相似度高于阈值,我们把汉语词放入候选替换词集中。
(2)对泰语词与候选替换词集中的词通过synset_id转化为英语,在英文Wordnet的is_a层级树中查询他们之间的语义关系,如果它们之间是同类词或者直接上义词则可以直接替换,生成新的候选衍生实例。

(4)将筛选出的衍生实例加入语料集中,通过神经概率语言模型学习新的汉泰词汇跨语言分布,并跳转到过程(1)。
(5)重复过程(1)~(4),直到学习不出新的汉语替换词为止。
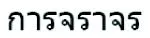
我们将整个汉泰跨语言词汇分布学习过程总结如流程图2所示。
我们把汉语神经概率语言模型扩展到汉泰跨语言词汇分布表示上,由于在学习语料中合适的位置嵌入了泰语名词、动词,所以我们的神经概率语言模型经过学习,可以得到汉泰跨语言词汇较为准确的分布表示。
3.6 模型学习
神经概率语言模型中用反向传播算法[13]学习模型参数。目前针对反向传播算法的参数改进学习算法有很多,我们选用ZeilerMD等人[14]改进的ADADELTA梯度下降算法来最优化模型的参数集。该方法可以动态地适应一阶信息,并对梯度下降有最小的计算开销。训练一次实例就更新一次参数。首先从神经网络的输出层开始,每一层的每个参数的梯度通过后一层的梯度来获得,经过网络的每一层最后到达输入层的词的分布特征向量,不断迭代直至误差符合预期完成整个过程。
4实验及分析
4.1 文本相似度计算方法
我们首先用神经概率语言对上述跨语言语料进行学习,得到汉泰词汇的跨语言分布表示,基于经验,我们设定每个词的向量维度为200,神经概率语言模型隐藏层的神经单元个数为64,允许误差0.001,训练窗口为5。在语料集学习的过程中只考虑出现频数大于或等于3次的汉泰词汇。我们把学习得到的汉泰词汇跨语言分布作为文本相似度计算的基础。
我们通过tf-idf算法筛选出每篇文档特征权重占前5位的特征词,文本t的特征词组为(vt1,vt2,…,vt5),权重为(wt1,wt2,…, wt5),同理文本k的特征词组为(vk1,vk2,…,vk5),特征词对应tf-idf权重为(wk1, wk2,…,wk5)。两篇文本间的相似度通过文本t中的每个特征词与文本k中的每个特征词的词向量余弦相似度及各自特征权重的乘积累加求和除以总共相加次数25。词vk1与vt1的词向量余弦相似度表示为vk1&vt1。文本相似度计算公式为:
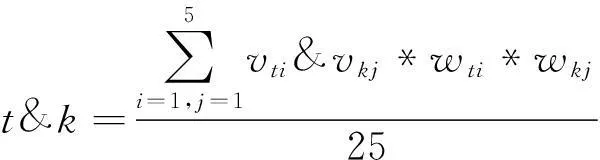
(3)
4.2 实验结果与分析
我们选用维基百科上的汉泰篇章对齐文本作为实验文本集,选取经济、政治、文化、科技、体育五类汉泰平行文本各100篇。实验由两部分组成:第一部分:汉泰平行文本相似度计算;第二部分:汉泰混合文本集中的文本随机打乱顺序后判断它们在五大类中的分类。汉泰文本的相似性说明两者之间的同义词的跨语言词分布相似性,只有两篇文本中的同义词在一致的向量空间分布表示上的相似才能使文本相似度高。
维基百科上篇章平行文本都是针对同一词条的描述,但它们在描述上有差异,很多情况下一种语言的描述很详细而另外一种语言描述较简单,我们人工筛选汉泰平行文本描述一致、篇幅相当的文章,经语言学家判定相似程度高于95%的平行文章。由于我们不追求单语言环境下的文本相似度效果,只追求在同种计算方式下的双语平行文本相似性,因此采用上节描述的文本相似度计算方法计算相似性。实验结果如表1所示。
文本相似度实验表明,通过跨语言词汇分布表示来表征汉泰文本相似度方面有一定的效果,针对平行文本均取得了69.84%以上的相似度。
汉泰文本混合文本集的文本分类准确性说明汉泰词在跨语言模型中的词汇分布表征准确性,如果词汇的跨语言词汇分布表示不准确会导致文本分类准确率下降。我们的目的是检验跨语言词汇表示的准确性,故我们采用KNN文本分类算法,它是较理想的文本分类算法。待分类文本与训练文本相似度计算时采用上节的文本相似度计算方法。我们选取的汉泰文本都是单种分类标记的文本,不考虑多分类标记文本,并将我们的方法同跨语言文本分类效果较好的模型翻译[15](通过期望最大算法把源语言分类标记文本翻译为目标语言分类标记文本学习分类知识后分类)、结合半监督适应的模型翻译[15](模型翻译同时结合半监督学习更新目标语言的分类特征词分布)及机器翻译(两种方法:(1)源语言分类标记文本翻译为目标语言,目标语言待分类文本学习分类知识后分类;(2)目标语言翻译为源语言学习分类知识后分类)的方法作对比。结果如表2所示。

Table 1 Cross-lingual text similarity
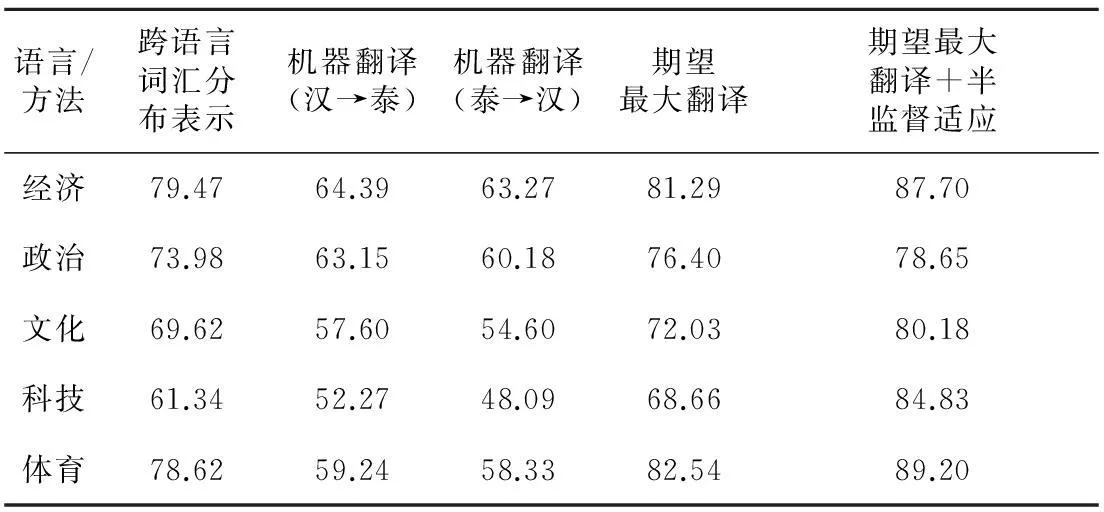
Table 2 Cross-lingual text classification accuracy
实验结果表明:相同语料规模情况下,跨语言词分布在跨语言文本分类方面较两种机器翻译方式效果较好,略差于基于期望最大算法翻译分类方式,与期望最大算法翻译+半监督适应方式相比有一定的差距。原因在于跨语言词汇分布可以反映跨语言词汇相似程度,相比机器翻译的翻译结果提高了准确性,但分类效果略差于期望最大翻译。因为期望最大算法考虑了在类别信息下源语言词翻译为目标语言词的最大翻译概率,相比跨语言词汇相似度是所有类别下的平均相似度,准确性更高,而结合半监督适应后可以更新目标语言文本分类的特征词,效果最好。实验说明汉泰跨语言词汇分布表示的准确性,即词汇意义的表达准确性。本文的方法在跨语言文本分类方面效果不是最佳但操作过程简单,没有复杂的翻译消歧过程,基于跨语言词分布将源语言的分类知识直接迁移到目标语言,有一定效果的同时速度最快。
5结束语
本文为解决汉泰词汇的跨语言分布表示问题,忽略两种语言的差异,将泰语名词、动词嵌入到汉语语料的合适位置生成跨语言语料,并通过弱监督学习扩展语料规模,最终通过神经概率语言模型学习得到汉泰词汇的跨语言分布表示,使在汉语上应用成熟的文本分析方法可以直接应用到泰语文本上,且在跨语言文本分析上的应用方法较为简单,没有很复杂的消歧过程。实验通过文本相似度和文本分类验证取得了一定效果。我们下一步期望对神经概率语言模型进行改进(如增加隐藏层的层数等)来提高跨语言词汇分布表示的准确性,并进一步探讨跨语言词汇的分布特征向量表示维数对跨语言词汇分布表示的影响。
参考文献:
[1]Bengio S,Bengio Y.Taking on the curse of dimensionality in joint distributions using neural networks[J].IEEE Transactions on Neural Networks,2000,11(3):550-557.
[2]Bengio Y,Ducharme R,Vincent P,et al.A neural probabilistic language model[J].Journal of Machine Learning Research,2003,4(3):1137-1155.
[3]Collobert R,Weston J,Bottou L,et al.Natural language processing (almost) from scratch[J].Journal of Machine Learning Research,2011,12(1):2493-2537.
[4]Zeman D,Resnik P.Cross-language parser adaptation between related languages[C]∥IJCNLP,2008:35-42.
[5]Søgaard A.Data point selection for cross-language adaptation of dependency parsers[C]∥Proc of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies:Short Papers-Volume 2,2011:682-686.
[6]Ando R K,Zhang T.A framework for learning predictive structures from multiple tasks and unlabeled data[J]. Journal of Machine Learning Research,2005,6(6):1817-1853.
[7]Prettenhofer P,Stein B.Cross-language text classification using structural correspondence learning[C]∥Proc of the 48th Annual Meeting of the Association for Computational Linguistics,2010:1118-1127.
[8]Steinberger R,Pouliquen B,Hagman J.Cross-lingual document similarity calculation using the multilingual thesaurus eurovoc[C]∥Proc of CICLing’02,2002:415-424.
[9]Wu L,Huang X,Guo Y,et al.FDU at TREC-9:CLIR,filtering and QA tasks[C]∥Proc of the 9th Text Retrieval Conference,2000:1.
[10]Gao J,Nie J,Xun E,et al.Improving query translation for cross-language information retrieval using statistical models[C]∥ACM SIGIR,2001:96-104.
[11]Och F J,Ney H.Improved statistical alignment models[C]∥Proc of the 3th Annual Meeting of the Association for Computational Linguistics,2000:440-447.
[12]Emami A,Jelinek F.A neural syntactic language model[J].Machine Learning,2005,60(1-3):195-227.
[13]Rumelhart D E,Hinton G E,Williams R J.Learning representations by back-propagating errors[J].Nature,1986,323(6088):533-536.
[14]Zeiler M D.ADADELTA:An adaptive learning rate method[J].arXiv Preprint arXiv:1212.5701,2012.
[15]Shi L,Mihalcea R,Tian M.Cross language text classification by model translation and semi-supervised learning[C]∥Proc of the 2010 Conference on Empirical Methods in Natural Language Processing,2010:1057-106.

张金鹏(1989-),男,河南新密人,硕士生,研究方向为自然语言处理。E-mail:939127870@qq.com
ZHANG Jin-peng,born in 1989,MS candidate,his research interest includes natural language processing.

周兰江(1964-),男,云南昆明人,副教授,研究方向为自然语言处理与嵌入式系统研究。E-mail:915090822@qq.com
ZHOU Lan-jiang,born in 1964,associate professor,his research interests include natural language processing, and embedded system.
DistributedrepresentationofChineseandThaiwordsbasedoncross-lingualcorpus
ZHANGJin-peng1,2,ZHOULan-jiang1,2,XIANYan-tuan1,2,YUZheng-tao1,2,HESi-lan3
(1.SchoolofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,Kunming650500;
2.TheKeyLaboratoryofIntelligentInformationProcessing,
KunmingUniversityofScienceandTechnology,Kunming650500;
3.SchoolofScience,KunmingUniversityofScienceandTechnology,Kunming650500,China)
Abstract:Word representation is the basic research content of natural language processing. At present, distributed representation of monolingual words has shown satisfactory application effect in some Neural Probabilistic Language (NPL) research, while as for distributed representation of cross-lingual words, there is little research both at home and abroad. Aiming at this problem, given distribution similarity of nouns and verbs in these two languages, we embed mutual translated words, synonyms, superordinates into Chinese corpus by the weakly supervised learning extension approach and other methods, thus Thai word distribution in cross-lingual environment of Chinese and Thai is learned. We applied the distributed representation of the cross-lingual words learned before to compute similarities of bilingual texts and classify the mixed text corpus of Chinese and Thai. Experimental results show that the proposal has a satisfactory effect on the two tasks.
Key words:weakly supervised learning extension;cross-lingual corpus;cross-lingual word distribution representations;neural probabilistic language model
作者简介:
doi:10.3969/j.issn.1007-130X.2015.12.025
中图分类号:TP391
文献标志码:A
基金项目:国家自然科学基金资助项目(61363044)
收稿日期:修回日期:2015-10-17
文章编号:1007-130X(2015)12-2358-08
