
基于时间序列的Global Skyline并行算法
2016-01-21 07:27李媛媛曲雯毓栗志扬季长清吴俊峰
系统工程与电子技术 2016年1期
李媛媛, 曲雯毓, 栗志扬, 季长清,3, 吴俊峰,4
(1. 大连海事大学信息科学技术学院, 辽宁 大连 116026; 2. 大连交通大学软件学院,
辽宁 大连 116028; 3. 大连大学物理科学与技术学院, 辽宁 大连 116622;
4. 大连海洋大学信息工程学院, 辽宁 大连 116023)
基于时间序列的Global Skyline并行算法
李媛媛1,2, 曲雯毓1, 栗志扬1, 季长清1,3, 吴俊峰1,4
(1. 大连海事大学信息科学技术学院, 辽宁 大连 116026; 2. 大连交通大学软件学院,
辽宁 大连 116028; 3. 大连大学物理科学与技术学院, 辽宁 大连 116622;
4. 大连海洋大学信息工程学院, 辽宁 大连 116023)
摘要:Global Skyline 查询是Skyline查询的一种变种,它和动态Skyline查询、反Skyline查询关系密切,已被广泛应用于多目标决策、网络监控、数据挖掘等方面。随着数据的积累,传统集中式的Skyline查询已经不能满足大数据的处理要求。为了高效解决大规模的基于时间序列的数据处理难题,提出了基于MapReduce框架并行的Global Skyline Cell查询算法。首先,通过对实际应用需求进行分析,本文提出了基于时间序列数据Skyline查询的时间倒排索引模型;并提出了Global Skyline格概念,利用格间的支配关系进行粗粒度高效剪枝,避免了大部分的无效运算;其次查询点将数据空间分割成不同象限,基于各象限进行轮询,实现了Global Skyline 格的查询,在此候选结果中得到Global Skyline点,为下一步实现动态Skyline和反Skyline查询奠定基础。最后,我们在Hadoop集群环境中实现了该算法。实验结果表明,该算法能有效解决基于时间序列的大规模数据Skyline查询的时间和空间矛盾,能够满足实际应用需求。
关键词:Global Skyline查询;MapReduce;大数据;时间序列
0引言
Skyline查询问题又叫Pareto最优或极大向量问题[1],是从数据集中查找感兴趣的点,这些点不被其他点所支配。Skyline查询将返回数据集的一个子集,该子集中的点都不能被数据集中的任意一个其他点所支配,满足这种条件的点称为Skyline点(Skyline point,SP)。
Skyline查询被广泛应用于多目标决策、商业计划、网络监控、无线传感器网络、数据挖掘等方面。近年来,Skyline研究受到了广泛关注,Skyline算法在集中式数据处理[1-4]和分布式数据处理[5-14]领域均得到了广泛深入的研究。随着传感器网络,移动互联网及物联网的不断发展,数据流处理也成为Skyline计算的一个研究热点,并有了一些相关的研究[15-18]。
本文研究了随时间不断变化的大规模时序数据的Skyline查询问题,这些数据表现为数值的形式并且在每个时间点上均存在一个值,这个时间点指特定的时间粒度[16]。如网络监控中检测到的各种安全事件按小时来记录,零售业中各种商品按月销售量来记录。一个典型的例子是网络监控中对网络节点信息的监控,每个被监控的节点实时向服务器发送被监控的数据,这样就产生了海量的持续的数据及历史数据记录。以网络安全为目的的监控是为了发现异常和攻击,而不是为了实时记录网络状态,同时还可以关注很多内容,例如统计一段时间内系统漏洞多且受攻击频率高的服务器,以采取针对性措施。Skyline计算会返回符合多标准最优化选择的关注对象。
随着监控网络数据流速度的提高,使得短时间内积累大量历史数据成为可能,同时网络安全监控的长期性和准确性需求也要求扩大数据规模。面对大规模历史数据的处理,传统的单机集中式处理模式受限于内存容量、计算能力等因素而难以胜任。单机处理模式以牺牲服务质量来保证大数据的处理,如概要数据、准入控制、QoS降阶[17-19]等方法。因此,如何针对大规模时间序列历史数据进行Skyline处理成为物联网和云计算领域的新挑战。文献[20]提出了区间Skyline查询,是从多个时序数据中发现所有在指定时间区间内没有被其他任何数据在量值上支配的时序数据,但算法中需要计算并且保存某段时间序列中的最大值和最小值,当数据量非常大时,该方法计算费用过高。与上述工作不同,本文考虑的是基于时序数据的Global Skyline查询[5],提出了针对海量数据的查询。
本文针对数据流上的数据的特点及Skyline查询所面临的问题进行了研究。数据流处理的数据规模大,一般都是海量的,比如中国电信主干网络每秒能产生几十GB的数据;同时这些海量数据都是连续的,针对查询结果的数据增量维护困难;应用在网络监控及环境监控的Skyline查询,关注的是异常情况的发现,比如基于阈值网络攻击检测,Skyline查询能够提供近似结果查询的要求。
基于上述原因,本文提出了一种基于时段度量的时序数据Global Skyline算法,此算法采用一种粗粒度的剪枝方法,目的在于快速排除大量不相关的数据,减少参与运算的数据,同时也可以为动态Skyline和反Skyline计算提供更小的运算集合。为了更有效地管理数据,本文提出了基于时间序列数据Skyline查询的时间倒排索引模型,并在此基础上提出了Global Skyline格概念,利用格间的支配关系进行粗粒度的剪枝,减少了大部分的无效数据。本文还讨论了如何在MapReduce并行环境下实现此算法的问题,并利用集群强大处理能力快速生成时间倒排索引的方法。针对数据流数据的连续性,提出了基于时间片的Skyline查询,能够支持数据的增量维护。
第1节对问题进行形式化描述,基于已有相关工作提出了基于时段度量的时序数据Global Skyline算法;第2节给出了系统处理模型和时间倒排索引模型,阐述了其详细查询过程及具体数据结构。第3节通过实验验证上述方法的有效性和高效性;第4节对全文进行总结和展望。
1问题描述
1.1点支配
d维空间上的对象集合S={p1,…,pn}中的任意对象pi,pj∈S,若满足以下两个条件,称pi支配pj,即pippj:①pi任意一维属性取值都不比pj差;②至少有一维属性取值优于pj。
1.2静态Skyline
给定对象集合S,S的Skyline是所有不被其他对象支配的对象集合SP(S)={pi|∃pj∈S,pjppi}。
1.3动态Skyline
给定查询点q,对于任意两个对象pi,pj∈S,pi动态支配pj即pipqpj,满足条件:
(1) ∀t∈{1,2,…,d},|pi(t)-q(t)|≤|pj(t)-q(t)|;
(2) ∃k∈{1,2,…,d},|pi(k)-q(k)|<|pj(k)-q(k)|。
例如在网络安全监控应用中,可以监控主机安全漏洞数、入侵频率、流量信息等指标。一台对外提供服务的网络主机安全漏洞数量越多,其可能遭受攻击的类型就越多,入侵频率就越高。不同攻击又导致不同的流量变化。若已知某台主机遭受某种攻击,该主机的监控数据作为查询点,我们可以针对网络监控数据进行动态Skyline计算得到其他疑似被攻击的主机。
图1以网络监控为例说明了静态Skyline和动态Skyline的不同。图中的数据点为网络中的主机,x, y坐标分别表示该主机被监控的相关指标。图1(a)为静态Skyline查询的例子,返回安全隐患最大的主机(p7, p6, p8)。图1(b)则为动态Skyline查询,q为遭受攻击的主机,动态Skyline计算返回疑似遭受攻击的主机候选集(p7, p3, p6)。
1.4Global Skyline
给定查询点q,d维空间上的对象集合S中任意两个对象pi,pj∈S,对象pi关于查询点q全局支配pj满足下面条件:

图1 网络监控示例
(1) ∀t∈{1,2,…,d},(pi(t)-q(t))(pj(t)-q(t))>0;
(2) ∀t∈{1,2,…,d},|pi(t)-q(t)|≤|pj(t)-q(t)|;
(3) ∃k∈{1,2,…,d},|pi(k)-q(k)|<|pj(k)-q(k)|。
GlobalSkyline是Skyline查询的一种变种,考虑的是在有查询点情况下的Skyline计算,比静态Skyline计算复杂。同时与动态Skyline和反Skyline计算关系密切。它返回所有不被其他对象全局支配的对象集合。给定一个查询点,查询点把d维数据空间分割成2d个子象限。GlobalSkyline需要查询得到所有子象限(2d个子象限)的全局Skyline点。本文分析的是基于时间序列的历史数据,关于时间片的定义如下。
1.5时间片
定义了一个时间范围[i,j](i≤j),t[i:j]=t[i],t[i+1],…,t[j](i≤j)表示时间片。如果k∈[i:j]即i≤k≤j。对于两个时间片[i1:j1]和[i2:j2],当i1≥i2且j1≤j2,[i1:j1]⊆[i2:j2]。
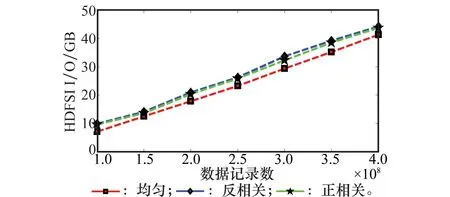
有了时间片定义,可以推导出时间片上的支配关系:给定一个时间片[i:j]和对象集合S,满足条件,若∀k∈[i:j],pi[k]≤pj[k];并且∃l∈[i:j],pi[l] 于是,给定一个对象集合S和一个时间片[i:j],该时间片上的Skyline如下: (1) 2基于时间倒排索引的GlobalSkyline并行算法 本文针对大规模历史数据提出的Global Skyline并行算法流程,如图2所示,系统主要由时间划分模块、生成索引模块、查询模块组成。所有模块都运行在Hadoop云平台上,利用分布式集群的强大计算能力能很好地解决大数据的处理要求。 首先,数据由成千上万个监控节点产生,这些节点可以是环境监控中的传感器,也可以是网络节点中的主机,它们都有一个共同的特点,以一定时间间隔通过网络向服务器发送收集到的数据。随着时间推移,服务器的磁盘阵列中形成了大规模的历史数据可用于分析计算。 时间划分模块就是利用MapReduce框架并行读取这些历史数据,并按一定的时间间隔将大数据集分而治之,形成以小时、天、月或年为间隔的小数据集。这样方便后续的计算和针对实际不同应用需要的各种时段统计,MapReduce也正适合这种大规模数据的处理。 图2 系统模型 生成索引模块是为了加快查找速度,减少大量无效运算而生成的倒排索引。将各个时间段内数据分别生成时间倒排索引以备后续计算。这个预处理过程虽然耗时,但一旦索引事先生成,基于时间倒排索引的后续计算可以大大加快查询的速度。 查询模块接受管理节点的查询请求,一旦查询点q到来,查询模块将q映射到时间倒排索引中,使用Skyline格进行粗粒度的减枝,减少了大部分无效数据。利用各象限进行轮询,得到Global Skyline结果集,针对这一结果集作进一步的动态Skyline或反Skyline查询,并将结果返回给管理节点。至此,查询计算完成。 接下来本文将重点介绍此流程中的关键处理技术及重要数据结构。 2.1时间划分模块 在很多应用中需要分析大量的时序数据,比如网络监控、股票行情等。以二维属性为例,加上时间就是三维空间,每个数据点p的当前状态可以表示为 图3 时间划分模型 给定一个对象集合S,每个数据点p的时间属性值(t)在一个有界的区间[Tmin,Tmax],构造一个均匀的划分{t0,…,tB},ti的定义如下: (2) 由公式(2)形成一个含有B个时间片元素的集合{b0,…,bB-1},其中,每个时间片bi=[ti,ti+1),固定长度为l。每个数据点的时间属性为t映射到时间片bs(t)∈B,其中s(t)的定义如式(3)所示,其中不同粒度的区间l的值要根据实际应用情况而定。 (3) 2.2索引数据结构及流程 本文设计了一种基于时间序列的倒排索引数据结构,如图4所示,以二维空间为例,每个点的数据可表示为 图4 基于时间序列的倒排索引结构 (4) 以二维数据为例,带时间维的数据点都可表示为P 图5 网格倒排索引生成过程 以上时间划分和生成索引两过程利用MapReduce处理可以合并,用一个MapReduce流程完成,整个过程如图6所示。 图6 MapReduce生成索引流程 时间片个数B设置为n,网格宽度δ1=δ2=15,同时启动多个Map对历史大数据进行读取,每个Map读取不同的HDFS数据片生成 2.3GlobalSkyline格的计算 Skyline查询的开销和数据集大小有直接关系,尤其是对于海量数据它们的支配关系判断也是一笔很大的开销。为了解决这一问题,我们提出了Skyline格概念,如图7所示。查询点q被映射到相应的Skyline网格C6当中,整个网格区域就被分成了影响区域和被支配区域。非空的格C1,C2,C3,C5,C7,C9,C10,C11都为其影响区域,被支配区域是指被受影响区域支配的区域,如在第二象限中的C4格。 图7 Global Skyline查询与减枝 2.3.1单元格支配 给定查询点q,d维空间上单元格集合C中任意两个单元格ci,cj,用单元格的左下角点ei,ej坐标表示单元格,若满足条件:∀k∈{1,2,…,d},|ei(k)-q(k)|<|ej(k)-q(k)|则格ci关于q支配格cj即cipqcj。 由单元格支配定义,我们可以类推出全局格支配公式,给定查询点q,d维空间上单元格集合C中任意两个单元格ci,cj,ei,ej坐标表示单元格。若满足条件: ①∀k∈{1,2,…,d},(ei(k)-q(k))(ej(k)-q(k))>0; ②∀k∈{1,2,…,d},|ei(k)-q(k)|<|ej(k)-q(k)|。 则格ci关于q全局支配cj,即ci◁qcj。 2.3.2GlobalSkyline格 给定格集合C,C的全局Skyline是所有不被其他格全局支配的格集合GSC(C)={ci|┐∃cj∈C,cj◁qci}。 算法1 GlobalSkyline格算法输入:n维的数据集S,查询点q,中间结果集C输出:查询结果集R1:初始化原数据集S=⌀,C=⌀2:初始化结果集R=⌀3:FOR(everypointpi∈S)DO4: 按时间属性,分割数据点pi为时间序列5: 由公式gdx=pi.xd/δd,映射pi到相应的网格6: 插入pi到集合C中7:ENDFOR8:生成数据对 命题 1如果一个点p不在GlobalSkyline格中,那么它一定不是GlobalSkyline点。 证明如果点p∈S且p∉GSC(q),则p点一定落入被支配区域。则存在某个非空网格ci支配该点所在区域。ci中一定存在点关于q支配点p,则点p一定不是GlobalSkyline点。 证毕 推论 1任意一个GlobalSkyline点,它一定在某个GlobalSkyline格里。 综上所述,数据空间被划分为影响区域和支配区域。全局Skyline格所在的区域为影响区域,如图7所示的圆形区域,在生成全局Skyline格过程中,被支配的区域如图7所示的正方形阴影部分。我们利用过滤掉被支配的单元格方法进行粗略剪枝。 对于影响区域的查找,我们采用的是2n个象限轮询法(n为数据集维数),通过逐步扩展的方法,无需遍历全部数据便能获得影响区域及格中的数据点。相对于原始数据的全遍历,数量甚微的Skyline格的遍历大大减少了计算开销。实验结果也表明,通过此方法海量历史数据的Skyline查找效率大大提高。算法流程如算法1所示。 由推论1可知,上述算法返回GlobalSkyline格中的数据点一定在GlobalSkyline结果集中,也就是GlobalSkyline格是GlobalSkyline的侯选集,接着扫描算法1得到的结果侯选集,进行支配关系比较,最终得到GlobalSkyline结果。 3实验评测 在本节中,我们介绍了实验集群环境及测试数据情况,本文中所提到的方法采用Java语言编写,均在Hadoop平台下实现。 3.1实验配置 所有实验均在Hadoop集群中实现运行,该集群由 12台节点所组成。每个节点硬件配置相同:DualcoreAMDOpteron2212 2.00GHzCPU,80GBSCSI硬盘, 2GB内存,Intel82551 10/100Mbps以太网网卡。每个节点操作系统均为Ubuntu10.10server64位操作系统,安装的Hadoop版本号为Hadoop0.20.2。所有节点以100M局域网相连接,一台运行有JobTracker和NameNode的节点作为master节点,剩下其他节点均为slave节点。HDFS文件系统的chunksize设置为64MB。 所有实验均基于以下两类数据集合进行: (1) 真实数据集:利用sniffer工具对某数据中心进行一段时间的监控抓包统计,得到197 895条网络监控数据。这些数据流包含正常流量和非正常的受攻击流量,不同时段内的数据量及流速度都具有随机性。它真实地反映了网络监控数据流的特征,但数据量难以达到海量特征。 (2) 模拟数据集:生成3种分布的海量数据如图7所示。第1种是均匀分布的数据如图8(a)所示,数据集里的对象各维属性相互独立;第2种是正相关数据如图8(b)所示,数据集里的对象各维属性值成正比例增长;第3种是反相关数据如图8(c)所示,数据集里的对象各维属性值成反比例增长。3种数据均产生40 000万条历史数据记录,以100 000/s持续到达模拟数据流场景。 图8 模拟数据的3种数据分布 3.2实验结果 图9展示了剪枝策略的效果,实验中采用真实数据集,数据记录总条数n=197 895时,剪枝后剩下数据记录条数随网格大小的变化情况。当网格大小设为5,剪枝后的记录数为38 303,仅为原来数据量的1/5。如图9所示网格设置越小,剪枝效果越明显。因真实的网络监控数据分布比较密集,而且数据规模较小且分布集中,网格大小对剪枝效果并不十分明显。 图9 剪枝与网格大小关系 图10展示了模拟数据集3种不同数据分布下网格索引的生成时间。实验采用模拟数据集,数据集大小为40 000万条数据。生成网格的时间随着网格大小的增大而增长。网格大小设置一样的情况下,均匀分布数据生成网格索引时间最短,因为数据散状分布在各个网格中;正相关分布的数据次之,反相关数据耗时最长,这和数据过于集中在部分网格,并且I/O开销大有关。这一点在后面的HDFSI/O开销实验中也有体现。 图10 网格生成时间与网格大小关系 表1总结了不同数据量情况下算法的运行时间。实验采用均匀分布模拟数据集,数据记录条数最小10 000万条(1.28GB),最大40 000(5.12GB)万条。网格大小设置为1,时间定义公式中B的值设置为2,分为{b0,b1}两个时间片。算法运行时间由3部分组成:生成倒排网格索引时间(timeofbuildinggridindex,TBGI);Global格剪枝时间(timeofpruningusingglobalskylinecell,TPG);GlobalSkyline查询时间(timeofglobalskylinequery,TGSQ)。随着数据量的增加,总的运行时间大幅度增加。在每个数据集内前两个阶段即网格索引生成时间与剪枝时间及查询时间比所占比例较大,这恰好说明,对于大数据量Skyline算法处理建立索引的必要性。生成倒排网格索引属于预处理阶段,预先生成以提供后续查询,并不占用真正查询时间,Hadoop正适合此类数据的处理。通过这一阶段的预处理,能大大提高查询效率。 表1 在模拟数据集下的运行时间 s 图11是实验采用模拟数据集3种不同数据分布,数据集记录数从10 000~40 000万条数据变化,网格大小为1,B的值仍设置为2情况下,算法中执行时间即表1中后两项和的对比。随着数据量的增长,查询时间也随着增长。相同数据量的情况下,反相关分布的数据执行时间最长,正相关分布次之,均匀分布查询时间最短。这是因为均匀分布的数据剪枝的效果最好,并且I/O开销也小。 图11 不同数据分布下算法的运行时间 图12展示了算法运行时间。当实验数据记录条数固定为40 000万条时,网格大小设置为1,B的值最小为2,最大为10变换。随着B的值增大,时间片间隔变小,数据分组越多,每组当中的数据越少,算法的运行时间相应的变少。 图12 算法的运行时间和B值关系 图13展示了不同数据量情况下两种算法的运行时间对比,其中本文基于MapReduce框架并行的带Global Skyline格(GSC-MR)算法的运行时间包含了表1中的3部分时间和(包含了网格索引的建立时间);对比算法为同等实验平台下的传统不带Global Skyline格计算过程的查询即直接计算Global Skyline点。实验采用均匀分布模拟数据集,数据记录条数最小10 000万条,最大40 000万条。网格大小设置为1,时间定义公式中B的值设置为2。如图13所示,当数据量较小的情况下,GSC-MR算法优势并不明显,这是因为预处理时间比例较大。随着数据量的增长GSC-MR算法的优势就越明显。 图13 算法比较 图14展示了模拟数据在不同数据分布下HDFS的I/O开销,这里的I/O开销是所有过程I/O的总和,包括建立索引阶段。实验的数据记录条数,最小10 000万条,最大40 000万条。网格大小设置为1,B的值为1。如图14所示,相同数据记录的条件下,均匀分布的HDFS I/O开销最小,正相关次之,反相关数据开销最大。正相关数据和反相关数据I/O开销差距不大,但都比均匀分布大很多。这是因为均匀分布剪枝阶段的I/O开销相对小的多。 图14 不同数据分布的HDFS I/O 图15总结了不同并行机器数下算法的运行时间的加速比。实验中并行的节点数由2增至12台,采用均匀分布模拟数据集,数据记录条数分别为20 000万条(2.56 GB)和40 000万条(5.12 GB)。网格大小设置为1,时间定义公式中B的值设置为2。算法运行时间为总运行时间,包括生成倒排网格索引时间,Global格剪枝时间和Global Skyline查询时间总和。随着并行机器数的增加,算法的运行时间的加速比也增长,并且数据规模越大,算法的加速趋势越明显。 图15 不同机器数下的加速比 4结论 本文研究了基于时序数据离线Global Skyline 查询,将连续的时间分割成时间片,针对每个时间片,利用MapReduce进行并行Skyline查询。该查询算法针对海量数据,进行网格索引,利用格支配关系进行剪枝。本文针对的是大规模历史数据的处理,数据的实时计算将成为新的挑战。现有批处理方式的编程框架MapReduce难以满足实时要求,文献[20]提出了了实时性研究方法,下一步工作希望改进MapReduce框架以提高大规模数据流处理的实时效率。 参考文献: [1] Börzsönyi S, Kossmann D, Stocker K. The Skyline operator[C]∥Proc.ofthe17thInternationalConferenceonDataEngineering, 2001: 421-430. [2] Chomicki J, Godfrey P, Gryz J. Skyline with presorting[C]∥Proc.oftheInternationalConferenceonDataEngineering, 2003: 717-816. [3] Huang Y K, Chang C H, Lee C. Continuous distance-based Skyline queries in road networks[J].InformationSystems, 2012, 37(7): 611-633. [4] Lin X, Zhang Y, Zhang W, et al. Stochastic Skyline operator[C]∥Proc.ofthe27thInternationalConferenceonDataEngineering, 2011: 721-732. [5] Dellis E, Seeger B. Efficient Computation of reverse Skyline queries[C]∥Proc.ofthe33rdInternationalConferenceonVeryLargeDataBases, 2007: 291-302. [6] Hose K, Vlachou A. A survey of Skyline processing in highly distributed environments[J].TheInternationalJournalonVeryLargeDataBases, 2012, 21(3): 359-384. [7] Afrati F N, Koutris P, Suciu D, et al. Parallel Skyline queries[C]∥Proc.ofthe15thInternationalConferenceonDatabaseTheory,ACM, 2012: 274-284. [8] Vlachou A, Doulkeridis C, Nørvåg K. Distributed top-kquery processing by exploiting Skyline summaries[J].DistributedandParallelDatabases, 2012, 30(3/4): 239-271. [9] Köhler H, Yang J, Zhou X. Efficient parallel Skyline processing using hyperplane projections[C]∥Proc.oftheACMSIGMODInternationalConferenceonManagementofdata, 2011: 85-96. [10] Zhang B L, Zhou S G,Guan J H. Adapting Skyline computation to the mapreduce framework: algorithms and experiments[C]∥Proc.oftheDatabaseSystemsforAdvancedApplications,2011:403-414. [11] Vlachou A, Doulkeridis C, Kotidis Y. Angle based space partitioning for efficient parallel Skyline computation[C]∥Proc.oftheACMSIGMODInternationalConference, 2008: 227-238. [12] Chen L, Hwang K, Wu J. Mapreduce Skyline query processing with a new angular partitioning approach[C]∥Proc.oftheIEEEInternationalSymposiumonParallelandDistributedProcessing,WorkshopsandPhdForum, 2012:2262-2270. [13] Ding L, Wang G, Xin J, et al. ComMapReduce: an improvement of mapreduce with lightweight communication mechanisms[J].LectureNotesinComputerScience, 2012, 88(1): 224-247 [14] Park Y, Min J K, Shim K. Parallel computation of Skyline and reverse Skyline queries using mapreduce[C]∥Proc.oftheInternationalConferenceonVeryLargeDataBases, 2013:2002-2013. [15] Zhang W, Lin X, Zhang Y, et al. Probabilistic Skyline operator over sliding windows[J].InformationSystems, 2013, 38(8): 1212-1233. [16] Jin C, Yi K, Chen L, et al. Sliding-window top-k queries on uncertain streams[J].TheVLDBJournal, 2010, 19(3): 411-435. [17] Zhang L, Zou P, Jia Y,et.al. Continuous dynamic Skyline queries over data stream[J].JournalofComputerResearchandDevelopment, 2011,48(1):77-85.(张丽,邹鹏,贾焰,等.数据流上连续动态Skyline查询研究[J].计算机研究与发展,2011,48(1):77-85.) [18] Tian L, Wang L, Li A P, et al. Resource sharing in continuous extreme values monitoring on sliding windows[J].JournalofComputerResearchandDevelopment, 2008,45(3):548-556.(田李,王乐,李爱平,等. 滑动窗口数据流上多极值查询资源共享策略研究[J]. 计算机研究与发展, 2008,45(3):548-556.) [19] Li Z, Peng Z, Yan J, et al. Continuous dynamic Skyline queries over data stream[J].JournalofComputerResearchandDevelopment, 2011, 48(1): 77-85. [20] Jiang B, Pei J. Online interval Skyline queries on time series[C]∥Proc.oftheInternationalConferenceonDataEngineering, 2009: 1036-1047. 李媛媛(1980-),女,讲师,博士研究生,主要研究方向为云计算、大数据信息检索。 E-mail:lyy1135@dlmu.edu.cn 曲雯毓(1972-),女,教授,博士,主要研究方向为云计算、计算机网络、信息检索。 E-mail:wenyu@dlmu.edu.cn 栗志扬(1982-),男,副教授,博士,主要研究方向为图像检索、计算几何。 E-mail:lizy@dlmu.edu.cn 季长清(1980-),男,副教授,博士研究生,主要研究方向为云计算、空间数据检索。 E-mail:jcqgood@gmail.com 吴俊峰(1983-),男,讲师,博士研究生,主要研究方向为图像检索。 E-mail:wujunfeng0411@gmail.com 网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20150706.1606.009.html Parallel algorithm of Global Skyline on time series LI Yuan-yuan1,2, QU Wen-yu1, LI Zhi-yang1, JI Chang-qing1,3, WU Jun-feng1,4 (1.CollegeofInformationScienceandTechnology,DalianMaritimeUniversity,Dalian116026,China; 2.CollegeofSoftwaretechnology,DailianJiaotongUniversity,Dalian116028,China; 3.Collegeof PhysicalScienceandTechnology,DalianUniversity,Dalian116622,China; 4.Collegeof InformationEngineering,DalianOceanUniversity,Dalian116023,China) Abstract:Global Skyline query is a variant of the Skyline query which has been used for multiple objective decision making, business planning, network monitoring and data mining etc. The result set of Global Skyline query is close to the ones of dynamic Skyline query and reverse Skyline query. With the number of historical data increases, Skyline query on centralized system is not competent for big data and Skyline query for large-scale data on time series is a challenge. A parallel algorithm of Global Skyline on time series is proposed. Firstly, we present a inverted index based on data on time series. Secondly, we provide the concept of Global Skyline cell which can eliminate the dominated cells according to the cell dominance relationship. The coarse grained pruning strategy can help to avoid a lot of meaningless computation. The query point divides the data space into the four quadrants, Global Skyline query can be executed in eachquadrant circularly. Lastly through extensive experiments with both real-world and synthetic datasets, we show that our algorithm is much more efficient for big data on time series. Keywords:Global Skyline query; MapReduce; big data; time series 作者简介: 中图分类号:TP 311 文献标志码:A DOI:10.3969/j.issn.1001-506X.2016.01.33 基金项目:国家自然科学基金(61173165,61300187,61370198,61370199,U1433124);中央高校基本科研业务费专项资金(31322013044,31322013029,3132014325,3132013335);辽宁省教育厅科学研究一般项目(L2015092,L2014492,L2014283,L2014191);江苏省未来网络创新研究院未来网络前瞻性研究项目资助课题 收稿日期:2014-12-03;修回日期:2015-05-03;网络优先出版日期:2015-07-06。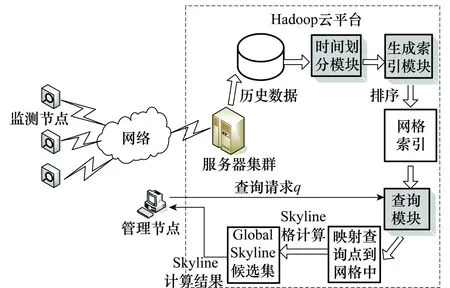
















猜你喜欢
商(2016年32期)2016-11-24
软件工程(2016年8期)2016-10-25
科技视界(2016年20期)2016-09-29
企业导报(2016年8期)2016-05-31
