
北京大学课程推荐引擎的设计和实现
2016-01-15 07:37沈苗,来天平,王素美等
智能系统学报 2015年3期
网络出版地址:http://www.cnki.net/kcms/detail/23.1538.tp.20150610.1646.002.html
北京大学课程推荐引擎的设计和实现
沈苗,来天平,王素美,彭一明,高志同
(北京大学 计算中心,北京 100871)
摘要:为了在管理信息系统中向师生提供更个性化、人性化的服务,将推荐引擎应用到北京大学学生选课系统中,设计并实现北京大学课程推荐引擎。改进的推荐算法是一种以学生属性分类为前提的协同过滤算法,通过分析选课系统中课程推荐与商业推荐的不同点和学生属性、改进学生相似度的计算方法实现推荐。以北京大学学生选课系统为平台,2013—2014学年度第1学期的10 682名本科生为测试集,为其推荐课程,推荐结果的准确率为34.6%。该系统为学生选课提供了有效的指导,填补了选课系统智能化、个性化方面的空白。
关键词:北京大学;课程推荐;推荐引擎;协同过滤;选课系统;管理信息系统
DOI:10.3969/j.issn.1673-4785.201409045
中图分类号:TP319 文献标志码:A
收稿日期:2014-09-30. 网络出版日期:2015-06-10.
基金项目:北京大学教育发展研究中心2013北大研究课题 (Y+25).
作者简介:
中文引用格式:沈苗,来天平,王素美,等. 北京大学课程推荐引擎的设计和实现[J]. 智能系统学报, 2015, 10(3): 369-375.
英文引用格式:SHEN Miao, LAI Tianping, WANG Sumei, et al. Design and implementation of the course recommendation engine in Peking University[J]. CAAI Transactions on Intelligent Systems, 2015, 10(3): 369-375.
Design and implementation of the
course recommendation engine in Peking University
SHEN Miao, LAI Tianping, WANG Sumei, PENG Yiming, GAO Zhitong
(Computer Center, Peking University, Beijing 100871, China)
Abstract:In order to provide a more personalized and humanized service for students and teachers in the management information system, a recommendation engine is applied to the Peking University student course-selecting system. The Peking University course recommendation engine is designed and implemented. The improved recommendation algorithm is a collaborative filtering algorithm on the premises of student attribute classification. The recommendation is achieved through analyzing different points between course recommendation and commercial recommendation, analyzing student attribute and improving the calculation method of students' similarity. As the platform, course-selecting system in Peking University recommend courses to 10 682 undergraduate students in the first semester of the 2013-2014 school year. The precision of recommendation results is 34.6%. This system can provide the effective guidance for the students choosing courses, and fill the blank of the system's intelligent and personalized.
Keywords:Peking University; course recommendation; recommendation engine; collaborative filtering; elective system; management information systems

通信作者:沈苗. E-mail: shenm@pku.edu.cn.
随着互联网技术的高速发展,信息过载问题亟须解决。用户希望从海量信息中快速准确地获取所需信息,信息创造者则希望其信息能够在海量数据中被迅速发掘并应用。在此情况下,互联网的技术从最初的分类目录到搜索引擎再到推荐引擎,在电子商务中得到了快速发展,其中推荐引擎是近些年学术界和产业界研究的重点,推荐引擎实现了用户与信息间的主动交互,通过用户行为和属性“猜测”用户感兴趣的内容并进行推荐,是一种根据不同用户的特点进行推荐的个性化服务[1]。
管理信息系统的使用是高校信息化建设的关键手段,选课系统更是学生获取课程信息、选择自己培养方案的重要媒介。一个好的选课系统不但要简单易用、逻辑严密,还要承担平衡教学资源的责任。目前,推荐引擎在管理信息系统方面的应用主要集中在图书借阅系统和选课系统[2],而且主要是理论研究。针对以上情况,在现有的选课系统中增加课程推荐服务,针对学生的特点推荐个性化课程,是一个创新性的研究方向[3]。
1选课系统和课程推荐的特征
首先关注学生在常规选课系统中如何实现选课,以北京大学为例,学生根据学校的培养手册计算本学期所需学分,根据学分要求分类,针对不同的课程类别分别选择课程,例如本学期计划选择4学分的通选课,然后开始浏览,关注课程类型、授课教师、学分、学时、上课时间等课程因素,找到符合自己要求的课程进行选择,选择后选课系统会提示是否符合选课条件(如有某种先行课的要求或有专业限制要求等)、上课时间与本学期的必修课或已选课程是否冲突。如果选课失败,学生需要重新去浏览其他通选课程。这里提出的问题是学生在有一定限制(学分和课程类型限制)的情况下,面对信息过载(几千门可选课程)所采用的常规措施。在此过程中学生已经根据自身特点进行了一定的分类,但是这种简单的分类并没有明确学生的需求,有些学生面对众多课程甚至无法通过关键字来搜索自己可能感兴趣的方向,需要人或工具来帮助他做出筛选,给出建议供其选择,事实上大部分学生也确实这样做了—通过询问身边同学或学长选择一些课程以满足学分要求。这样做导致的主要弊端有:学生不能根据个人情况私人定制自己的学习计划(如爱好、实力、当前学业进展等);某些精品课程由于知选课人数较少最终停开,浪费教学资源。学生也不能时刻都去咨询“前辈”,因此,一个个性化的课程推荐系统显得尤为重要。
除常规选课系统出现的上述问题外,在选课过程中,学生从大量开设的课程中找到符合自己要求的课程也是一件非常困难的事情,因为学生大部分情况下没有特别明确的需求,无法通过关键字搜索进行查询,因此各种课程想要更加突出自己的特点让学生去关注,让学生更好地利用教学资源,也是一件非常困难的事情。推荐系统的基本任务就是解决这个矛盾,常规选课系统的课程推荐引擎一方面让学生更了解自身特点挖掘适合的课程,另一方面让学校的教学资源得到充分的展示,实现学校、学生共赢的局面。图1是课程推荐引擎的基本任务图。
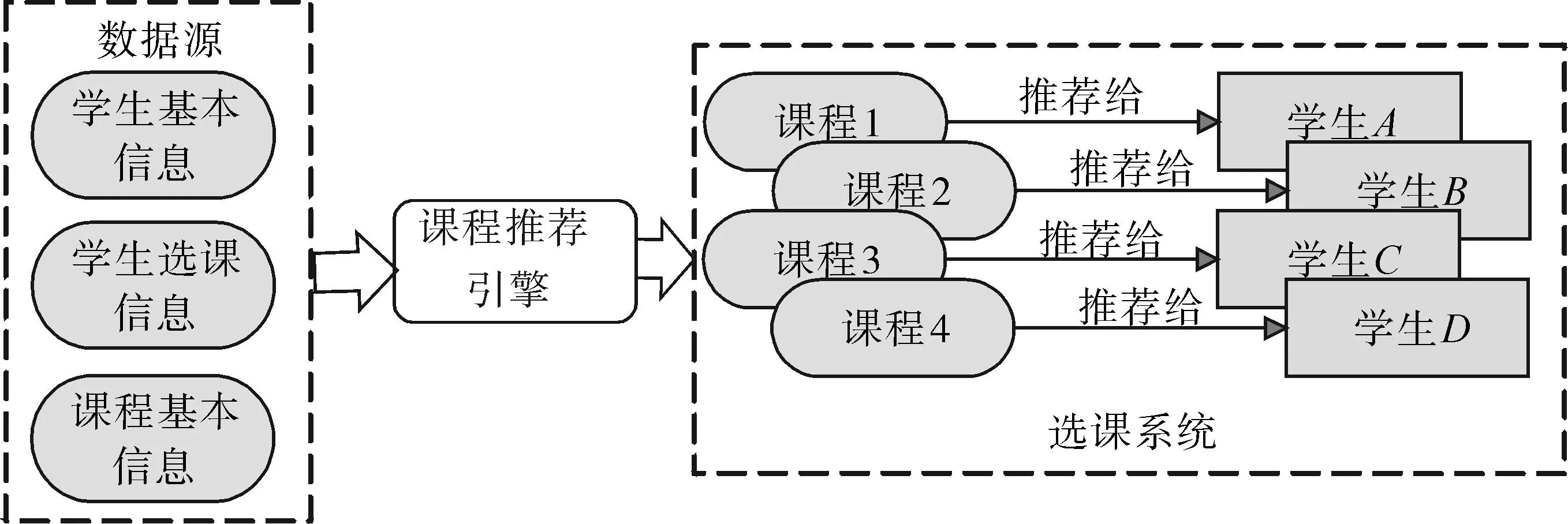
图1 课程推荐引擎基本任务 Fig. 1 The basic task map of course recommendation engine
将课程推荐与商品推荐进行比较,可以发现课程推荐具有其独特的地方:
1)推荐目标不同。商品推荐的目的是尽可能地推广商品,只要能获取利润,不用考虑商品资源平衡、商品类型等因素。而课程推荐从宏观上讲,其目的是促进优质教育资源普及共享,提高教育质量、促进教育公平、构建学习型社会和人力资源强国;从学校角度,推荐的目的是使更多的课程被学生知晓,甚至面向社会,发挥教育资源的最大作用,为学生提供更大的便利;从学生角度,推荐的目的是使学生全面了解学校资源,更好地统筹规划自己的培养计划,更多地体验自己感兴趣的课程,最终成为全面人才。综合来讲,课程推荐的目的是使每位学生都明确适合自己的培养方案,并选择自己感兴趣、有价值的课程,使学校的教学资源得到更合理的利用。
a)“马太效应”[4]。选课系统在消除“马太效应”上的要求比电子商务中的商品推荐具有更高的要求,研究表明推荐系统是具有一定马太效应的。在电子商务中的商品推荐系统中,一定的马太效应对推荐效果并不一定完全有害,比如在某个时段流行的商品或者歌曲在很大程度上大部分人都会喜欢,这个时候把这件商品或者歌曲推荐给每个用户不会有很大的问题,这种情况下马太效应反而会给电子商务网站带来很大的收益。但是选课系统的要求则完全不同,选课系统要求完全消除马太效应,某门课的选课人数是有上限的,不可能给每个人都推荐同一门课程。如果选课人数达到上限,推荐引擎应该马上停止推荐这门课程。
b)总量控制。电子商务中的推荐系统是没有总量控制的,推荐的出发点是尽可能的让用户“购买”产品或者服务,越多越好。而课程推荐系统则完全不同,学生选课的学分是有总量控制的,不是学生选的课越多越好,而是在一定总量控制下,达到最优化选择。
2)信息准确度不同。这里的信息实际上是指用户行为和属性的全面性和准确性。电子商务网站上,用户的信息仅限于注册信息,内容少且真实性差,电商能够参考的有价值信息一般是用户的行为,包含用户的历史购物、浏览记录、购物车、收藏夹及对商品的评价和评分等信息。而北京大学的选课系统建立在整个学生管理信息系统大平台下,可以轻易而准确地获取学生详细信息,如基本信息、历史选课记录、成绩信息、图书借阅信息、教学评估信息等。还可以获取到课程的详细信息,如历史开设情况、课时学分等课程属性、任课教师、选课学生的成绩列表及学生对课程的历史评价等。这些信息都具有极高的可信度,有利于定制个性化的课程推荐服务。此外,由于与传统的商品推荐所获取的用户行为、属性有差别,也导致在进行算法设计时采取不同于传统商品推荐的算法。
3)实时性要求不同。课程推荐相较于商品推荐实时性要求更高。主要体现在课程推荐是依托在选课系统中实现的,某段时间内同时访问选课系统的学生数量众多,需要系统实时判断每门课程是否达到选课限制人数、判断每位学生所选课程是否与必修课或其他选定课程在上课时间上有冲突。对于不符合条件的课程则进行其他相似的推荐。
2课程推荐算法设计
一个好的推荐系统需要满足学生、学校教务部门(开设课程的设计部门)和推荐系统本身三方面的要求。1)要给学生推荐最符合学生现今状态的课程,此为重中之重;2)要均衡学校的资源,推荐不同类型的课程,教务部门在设计开设哪些课程时一定是经过各方面权衡和计算;3)一个好的推荐系统能够不断地得到学生的反馈,完善推荐质量,从而给出更准确的推荐结果。在课程推荐中,可以通过调查问卷的形式来实现上述要求,主要是前2点是课程推荐系统的重中之重。在设计推荐算法时需要着重考虑这些要求。
正如文章第1部分对选课系统和课程推荐特征的分析,课程推荐的主要目的不是向学生推销课程,而是均衡学校的教学资源、以学生为本推荐适合学生的课程。因此在设计推荐算法时,要做到以学生为中心,对学生的信息了解越具体越详细,越有助于精准推荐。简单来说主要有以下3种推荐方法:1)身边的学长或同学进行建议,称为社会化推荐;2)根据学生历史选课记录挖掘其兴趣点、学生历史成绩判断其需求(例如学生成绩好则推荐程度较深的课程,差的则推荐容易得分的课程)、根据学生已选课程特点推荐(如某种类型的课程学分要求没达到,可以给出推荐),这种方法被称为基于内容的推荐;3)系统找出与该学生实力相当、特征最相似的一群学生,分析他们选择的课程,再找到最符合学生要求的进行推荐,这种方式称为基于学生的协同过滤推荐。可以看到,这3种推荐方法从线下学生网络到线上单个学生再到线上学生网络,逐步通过自动化的方法形成信息量大、资源丰富的学生网络和课程网络,从而自动筛选出符合要求的课程,图2是推荐系统中学生与课程的3种联系方式。
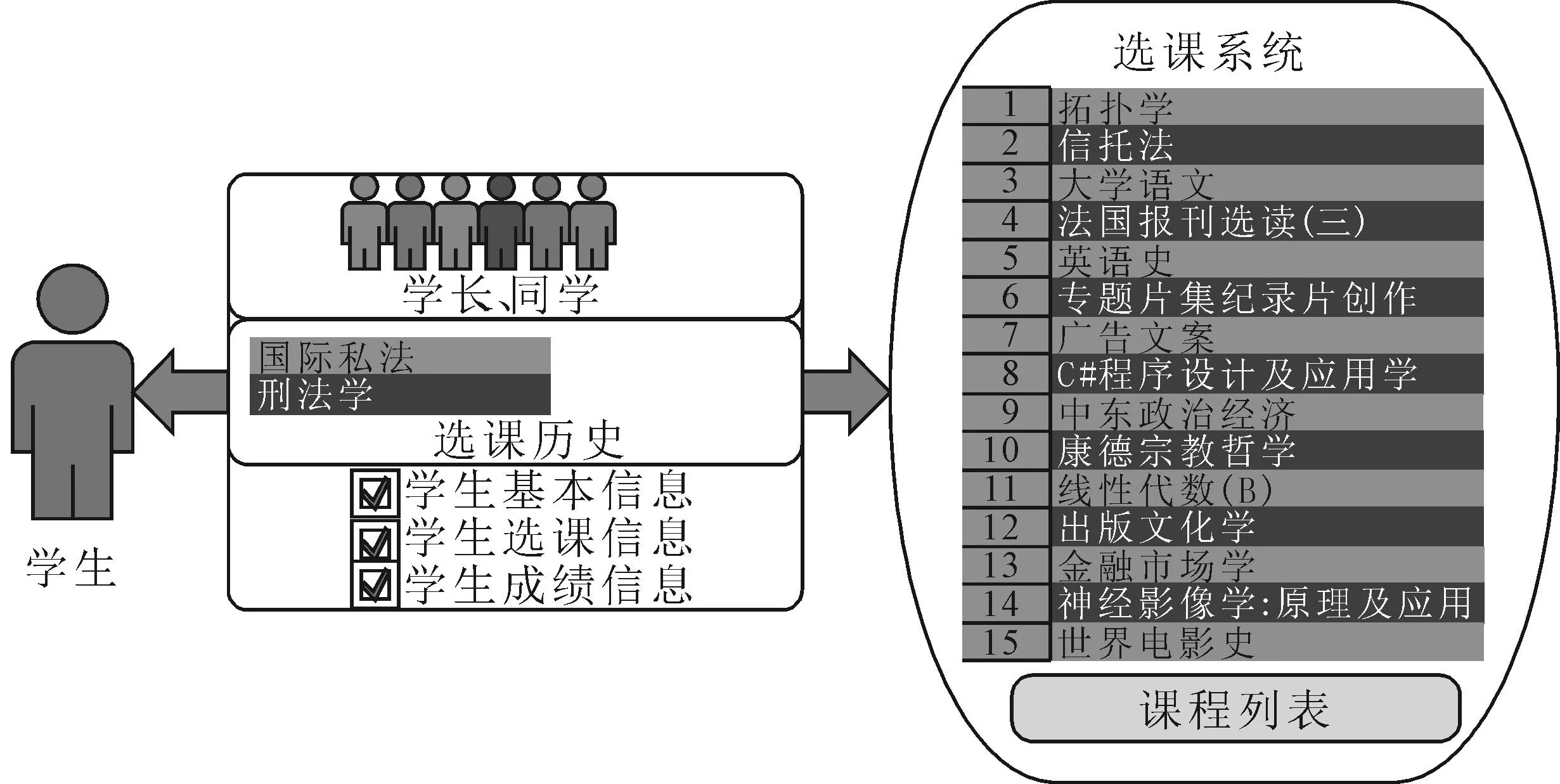
图2 推荐系统中学生与课程的3种联系方式 Fig. 2 Three contact methods of students and course in recommendation system
本文提出一种基于学生属性和课程特征的协同过滤推荐算法。该算法以协同过滤为基础,融合了人口统计学特征,采取离线计算和在线推荐协调合作的方法,满足了课程推荐的实时性、准确性要求。
2.1基于学生的协同过滤基本算法
根据商业系统中基于用户的协同过滤算法[5-6],本文提出了基于学生的协同过滤基本算法,其原理是分析所有学生的历史选课数据,找出与目标学生的选课爱好相似的K名“邻居”学生,将这K名学生所选的课程推荐给目标学生。图3是基于学生的协同过滤基本算法的原理图。

图3 基于学生的协同过滤基本算法 Fig. 3 Principle diagram of the Collaborative filtering algorithm based on students
该算法主要包含2个主要步骤:
1)找出与目标学生的选课爱好相似的“邻居”学生集合;
2)找出目标学生没选,但“邻居”学生选择的课程进行推荐。
不难发现,在步骤1)中计算目标学生与其他学生间的相似度是重点。采用余弦相似度公式(1)计算。
(1)

根据Wuv计算学生u对课程i的感兴趣程度:
(2)

2.2问题分析与算法改进
从2.1中描述的基本算法可以获取学生对课程的感兴趣程度,但是存在以下优缺点:
1)作为数据源,准确的学生选课历史信息为算法提供了数据支持,这些选课历史不会发生改变,而每学期需要选课的学生也是固定的,因此,可以将学生对课程的感兴趣程度在选课前进行离线计算,得到目标学生可能感兴趣的课程列表。离线计算弱化了算法复杂度的重要性,是课程推荐引擎设计时的最大特征优势。
2)数据前期处理。尽管本算法对时间复杂度要求不高,但是每学期选课的学生数庞大,以2011—2012学年度第1学期为例,本科生选课人数达到11 697人,这些学生要在选课系统上进行查询、选课、取消等一系列操作,可操作课程有1 247门,这里的课程已经经过处理,其中只包含选修、限选、任选和全校通选课,不包含必修课、专业必修课、课程设计、试验课、论文、社会实践等性质的课程。容易看到,如果每位学生都与其他一万多名学生进行计算相似度是没有必要的,因此,在进行协同过滤算法之前可以引入人口统计学规律,利用学生基本信息对学生进行分类,首先将学生分为不同的类,然后以类为单位计算该类学生对某门课程的感兴趣程度,这样简化算法的同时并不会影响到推荐的准确度。
这里进行如下假设:a)假设同一个院系同一个专业的学生对课程的喜好有更多的相似;b)假设历史课程成绩平均值接近的同学拥有相同的实力。基于这2个假设,聚类算法主要以学生所在专业与学生历史成绩作为主要参数进行分类
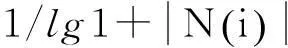
(3)
4)冷启动问题的解决。基于学生的协同过滤基本算法与基于用户的协同过滤算法相同,存在冷启动问题,当新学生要进行选课时,由于其没有历史选课记录,无法从分类后的学生类中找到与其最相似的K名“邻居”学生,本文从实际出发,单独处理新生。鉴于新生第1学期课程量少的特点,将一年级学生以专业、生源地、入学成绩分类,然后将二年级、三年级、四年级学生在一年级时选过的课程推荐给目标学生。通过实验发现推荐结果的覆盖率达到了95%以上,从而解决了冷启动问题。
总结以上问题,基于学生分类的协协同过滤算法StuCF的流程如下。
算法1 基于学生分类的协同过滤StuCF。
输入:学生基本信息、课程基本信息、学生选课信息。
输出:学生与对应推荐课程列表。
数据源:12 096名在读本科生的所有选课记录。
推荐样本:2013—2014学年度第1学期10 682名待选课本科生。
协同过滤,离线计算:
1)学生分类:以专业和成绩进行分类:
2)共119个专业的学生
3)专业人数在40人以下的不使用成绩分类;
4)共分324类,每类学生数低于40,记为集合U。
5)根据集合U找“邻居”学生集合K:
6)根据式(3)计算每位学生u与集合U中的其他学生间的兴趣相似度;
7)取相似度最高的K名“邻居”学生。
8)计算学生对课程的感兴趣程度:
9)获取K名“邻居”学生的所选课程集合I:
10)只关注“邻居”学生已选,学生u未选的选修课程。
11)根据式(2)计算学生u对集合I中的课程i的感兴趣程度;
12) 获取每位学生对应的推荐课程列表R。
选课系统,实时推荐:
13)以选课系统为平台,获取每个推荐样本的学号;
14)实时过滤课程最新状态,剔除停开课,上课时间与必修课冲突课程;
15 )实现推荐。
本算法给学生推荐那些与他有共同专业、相同兴趣、一致实力的学生选过的课程,推荐结果着重反映与学生最相似的小群体的共同点。之所以选择2013—2014学年度第1学期的学生作为推荐样本,是因为该批学生的选课情况已经成为历史,可以根据这些学生的历史选课结果与推荐结果进行对比,判断算法准确度。算法中没有描述一年级新生的选课信息,按冷启动问题的解决方法直接进行推荐。2.3算法测评
一个好的推荐引擎包含学生、课程和载体(选课系统)三方面,推荐引擎首先要为学生推荐其感兴趣、能获取最大知识和综合技能的课程;其次学校开设的课程要能够被推荐给感兴趣的学生,而不是覆盖面小,只推荐几门热门课程;最后,好的推荐引擎可以通过推荐系统获取学生反馈,从而修改、完善推荐结果,一般可以从学校的教学评估、问卷调查获取到。不同于传统的商业推荐系统,课程推荐不仅要求准确预测学生的行为,而且能够帮助学生发现他们感兴趣的课程;同时为了平衡学校教学资源,还需要克服“长尾问题”。因此,准确度、覆盖率成为评测StuCF推荐算法的2个重要指标。
1)预测准确度。
基于选课系统StuCF算法最终提供给学生提供1个个性化的课程推荐列表,这种推荐也被成为TopN推荐,预测准确度通过准确率/召回率度量。根据图4分析准确率P与召回率R的概念。

图4 课程推荐的4种情况 Fig. 4 Four cases of course recommendation system
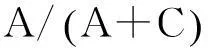
(4)
(5)
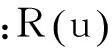
2)覆盖率[8]。
预测准确度是最关键的算法评测标准,即系统推荐的课程最终被学生选择的比率。但是存在的问题是,假设学生本来计划选择一门课程,那么实际上这个推荐是没有意义的,因此,不但要准确预测学生的预期,还要扩展学生的视野,帮助学生认识更多被埋没的精品课程,挖掘他们可能感兴趣的课程。采用覆盖率C来表示推荐系统能够推荐出来的课程占总课程集的比例:
(6)
式中:J表示所有课程的集合,U为学生集合。
3选课系统中的课程推荐服务
本课程推荐引擎主要为已有选课历史的学生样本进行推荐,以2013—2014学年度第1学期的选课为例,计算其准确率、召回率和覆盖率,分析算法结果。
本系统实现时,难点是K值的判断。K表示与目标学生最相似的学生数,以目标学生未选择而这K名学生已选择的课程为预推荐名单,分析目标学生对这些课程的兴趣程度,最终选出8~10门目标学生可能最感兴趣的课程进行推荐。这里K的选取很重要,当K取值较小时,可能造成算法复杂度的增加以及覆盖率的降低,K值很大时推荐准确度会受到影响,表1详细给出了基于StuCF算法和新生的课程推荐实验结果。

表 1 不同K值下的StuCF算法实验结果
从表1可以看出,课程推荐系统的准确率和召回率并不是与K值成线性关系,选择K为20左右会得到较准确的推荐结果。而随着K的增大,系统越来越倾向于推荐热门课程,导致覆盖率降低。
以北京大学选课系统为平台,在进入选课系统后,页面会弹出“你可能感兴趣的课程”对话框,其中列出为该学生量身定制的课程名称。图5是选课系统中的推荐界面。

图5 选课系统中的推荐界面 Fig. 5 The recommended interface of Elective system
4结束语
本文提出的基于选课系统的课程推荐引擎填补了国内高校智能校园、人性化教育方面的空白,将推荐引擎的技术应用到课程推荐中,不但均衡了学校的教学资源,也为学生量身定制最适宜的培养方案,起到了非常好的辅助作用。从纵向来说,对于课程推荐还存在很多地方可以深入探讨,如由于算法限制,本系统没有给出课程推荐原因,对学生缺乏说服力;另外分类算法相对简单,以假设为基础,未能综合考虑每位学生的个性化特点。横向来说,可以应用到图书馆借书系统中,为学生做图书推荐,因此下一步的研究重点也可以放在对学生属性的特征详细分析和加权统计上,通过对学生属性特征的分析找到一套自适应的聚类模式,不但可以应用到课程推荐,还可以应用到图书推荐等方面。
参考文献:
[1]赵晨婷, 马春娥. 探索推荐引擎内部的秘密, 第1部分:推荐引擎初探[EB/OL]. [2014-09-25]. http://www.ibm. com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html.
[2]张瑶, 陈维斌, 傅顺开. 基于大数据的高校图书馆推荐系统仿真研究[J]. 计算机工程与设计, 2013, 34(7): 2533-2541.
ZHANG Yao, CHEN Weibin, FU Shunkai. Simulation study of recommendation system for university library based on big data[J]. Computer Engineering and Design, 2013, 34(7): 2533-2541.
[3]祁褎然, 潘志成, 罗敬, 等. 大学选课推荐系统的数学模型[J]. 南开大学学报:自然科学版, 2011, 44(4): 50-55.
QI Youran, PAN Zhicheng, LUO Jing, et al. The mathematical model of the university course recommendation system[J]. Acta Scientiarum Naturalium Universitatis Nankaiensis, 2011, 44(4): 50-55.
[4]陆刚. 数字信息资源利用中的“马太效应”及消除策略[J]. 图书馆建设, 2003(6): 43-45.
LU Gang. The Matthew effect of the digital information resources using in the library and its solutions[J]. Library Development, 2003(6): 43-45.
[5]GOLDBERG D, NICHOLS D, OKI B M, et al. Using collaborative filtering to weave an information tapestry[J]. Communications of the ACM, 1992, 35(12): 61-70.
[6]RESNICK P, IACOVOU N, SUCHAK M, et al. Grouplens: an open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work. New York, USA, 1994: 175-186.
[7]项亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012.
[8]GE M Z, DELGADO-BATTENFELD C, JANNACH D. Beyond accuracy: evaluating recommender systems by coverage and serendipity[C]//Proceedings of the 4th ACM Conference on Recommender Systems. New York, USA, 2010: 257-260.

沈苗,女,1985年生,工程师,主要研究方向为高校信息化。

来天平,男,1977年,高级工程师,主要研究方向为高校信息化。

王素美,女,1980年生,工程师,主要研究方向为高校信息化,负责和参与信息管理系统的设计开发工作10余项,曾获“北京大学第五届实验技术成果奖”二等奖,发表学术论文10篇。
猜你喜欢
经济与管理(2022年2期)2022-03-24
经济与管理(2021年2期)2021-03-15
艺术品鉴(2020年5期)2020-07-27
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
法语学习(2016年1期)2016-12-18
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年25期)2016-11-16
数字技术与应用(2016年9期)2016-11-09
