
MongoDB在气象传感器数据处理中的应用
2016-01-12 07:59白长清刘敏
软件 2015年11期
关键词:海量数据
白长清++刘敏
摘 要:海量规模数据不断涌现,对非结构型数据的存储和处理需求日益增长,传统的关系数据库很难对其高效处理,NoSQL技术则能比较好的解决这类问题。本文将介绍NoSQL,MongoDB,以及MongoDB在处理海量气象参数的传感器数据时的应用。实践证明,以MongoDB为代表的NoSQL数据库在存储和访问海量的非结构化数据时,有着良好的性能。
关键词:NoSQL;MongoDB;海量数据;面向文档
中图分类号:TP311
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2015.11.010
0 引言
随着云计算时代的到来,web2.0的快速发展,非关系型、分布式数据存储得到了快速的发展,它们具有非常高的读写性能,尤其在大数据量下。而且NoSQL具有灵活的数据模型,即无需事先为要存储的数据建立字段,随时可以存储白定义的数据格式。在不太影响性能的情况下,就可以方便的实现高可用的架构。面向文档的MongoDB,其数据结构非常松散,可以存储比较复杂的数据类型,保证海量数据存储的同时,具有良好的查询性能,拥有广泛应用。
在本实验室气象局项目中,需要存储、查询大量气象参数测量传感器数据,每次测量的数据通道并不都是一致,即测量数据是弱一致性的,还要求保持可扩展性,并且能够便捷的获取数据,而MongoDB能很好的满足这些需求,本文将以实验室气象参数测量传感器数据的处理为背景,介绍MongoDB在实际生产中的运用。
1 NoSQL
1.1 概述
NoSQL是对非关系型数据库系统的总称,意思是No SQL(没有SQL语言)。它与关系型数据库最重要的不同是:NoSQL不使用SQL作为查询语言。其数据存储可以不需要固定的表格模式,也经常会避免使用SQL的JOIN操作,一般具有水平可扩展的特征。在大量数据存取上具备关系型数据库无法比拟的性能优势。NoSQL数据库凭借着其非关系型、分布式、开源和横向扩展等优势,被认为是下一代数据库产品。
1.2 NoSQL分类
NoSQL可以大体上分为4个种类:Key-value(键值存储)、Document-Oriented(面向文档)、Column-Family Databases(面向表列)以及Graph-Oriented Databases(面向图论)。下面就一览这些类型的特性:
键值数据库:通过key快速查询到其value,存储并不关心值的格式,比如通过国际标准书号ISBN找一本书,在这里,ISBN是键,书籍的其他信息就是值。必须知道键才能查询。
文档存储数据库:面向文档数据库会将数据以文档的形式储存。每个文档都是白包含的数据单元,是一系列数据项的集合。每个数据项都有一个名称与对应的值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。
列式数据库:也被称为列式存储或宽列存储,对数据进行列式存储。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的10优势。
图型数据库:图型数据库关注值与值之间的关系,用图型的数学概念存储数据。图型数据库用带有点、边缘和属性的图的结构表示和存储数据。在图型数据库中,每一个元素都包含一个直接的指向它毗邻元素的点,所以也就不需要索引查找。
1.3 优缺点
NoSQL数据库最大的优点在于它的去中心化、可扩展、容错能力等属性。用NoSQL数据库,你可以为每一个特殊的用例定制化你的数据管理解决方案。另外,大多数NoSQL产品都是轻量级的,因此花费比较少。自从NoSQL产品被设计用来满足特殊的用例和解决特殊的问题,它的功能也就比大多数关系型数据库少,因为后者要应用于更广泛的领域。因此,NoSQL数据库需要的代码更少,这也是和复杂的关系型数据库相比具备的一项优势。
当然,NoSQL也有它的缺点。ACID协议是关系型数据库的标准,但很多NoSQL数据库做不到。如果ACID支持很关键,你必须要确定你选的NoSQL数据库是否提供ACID。NoSQL数据库的另一个缺点是不支持SQL语言。经过40多年的发展,SQL已经成为访问数据的通用语言。一套数据库系统不支持SQL语言就意味着要求开发者学习不同的访问数据的语言。
NoSQL数据库在网页扩展、大数据和分析部署等方面越来越流行。每一个种类的NoSQL数据库都有适用的不同类型的应用程序和用例,这就涉及到一个NoSQL社区常用的一个话题,即多样持久性,或者说根据数据库处理应用程序需求的不同,使用不同的数据库系统,用于不同的应用程序和用例。因此,使用NoSQL最重要的是使用正确的数据库,满足具体的需求,哪怕是要引入一种新的数据库系统。
2 MongoDB
2.1 简述
MongoDB是一个高性能,开源,可扩展,无模式的文档型数据库,由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案,是当前NoSql数据库中比较热门的一种。它是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
传统的关系数据库一般由数据库(database)、表(table)、记录(record)三个层次概念组成,MongoDB是由数据库(database)、集合(collection)、文档对象(document)三个层次组成。集合对应于关系型数据库里的表,但是集合中没有列、行和关系概念,这体现了其模式自由的特点。
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
1)面向集合存储,易存储对象类型的数据。
2)模式自由。
3)支持动态查询。
4)支持完全索引,包含内部对象。
5)支持查询。
6)支持复制和故障恢复。
7)使用高效的二进制数据存储,包括大型对象(如视频等)。
8)自动处理碎片,以支持云计算层次的扩展性。
9)支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
10)文件存储格式为BSON(一种JSON的扩展)。
11)可通过网络访问。
所谓“面向集合”(Collenction-Oriented),意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定义任何模式(schema)。
模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。
存储在集合中的文档,被存储为键一值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各种复杂的文件类型。我们称这种存储形式为BSON(Binary JSON)。
2.2 Mongodb安装配置
根据自己的实际系统环境,下载所要的文件,我的是RHEL 7 Linux 64-bit。下载:
# wget https: //fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhe170-3.0.7.tgz解压至/usr/local/mongodb/,创建数据目录/data/mongodb,创建配置文件mongodb.conf。配置文件mongodb.conf如下,其中dbpath指定数据库目录,logpath指定日志路径,logappend=true使日志累加,fork=true使MongoDB以守护进程运行,port指定端口号,默认27017。
dbpath=/data/mongo/
logpath=/data/mongo/mongo.log
logappend=true
fork=true
port=27017
MongoDB有两种启动方式,配置文件启动和参数启动,如下:
1.配置文件方式启动mongo
#/usr/local/mongodb/bin/mongod -f/data/mongo/mongodb.conf
2.参数启动mongo
/usr/local/mongodb/bin/mongod -logpath /data/mongo/mongo.log -logappend -fork -dbpath /data/mongo/-port 27017
3.设置开机启动:
#echo“/usr/local/mongodb/bin/mongod—f/data/mongo/mongodb.conf”>>/etc/rc.local
3 气象传感器数据在mongo系统中的存储
3.1 数据的插入
使用Python创建数据库的方法如下:
client=MongoClient()
db=client.meteor_data
collection=db.res
连接到mongo数据库metor_data,并选中集合(cellection) res,注意:这里并没有创建集合,mongo采用延时创建的方法,当有document插入时才真正创建相应的数据库和集合。
如下所示是一条测量数据,‘CHIO代表通道10的测量数据,102941.437对应气象参数的传感器测量值。每条测量数据中通道数并不固定,可以根据测量需要选择。‘TIME则代表测量的时刻。
{u'CHl0':102941.437,u'TIME':'2015-09-22 20:33: 10',u'CH5': 918.236714, u'CH6':270.424495,u'CH7': 328.123456, u'CH8':465.627787,u'CH9':386.63469}
我们通过把多条测量数据作为document插入集合res中,来存储测量数据,python插入document的方法为:collection.insert_one(data),其中date代表要插入的测量数据。插入后的document如下。其中,'_id'域为mongo为我们自动添加的,作为主键。
{u'CHl0':102941.437,u'TIME':u'2015-09-22 20:33:10', u'CH5': 918.236714, u'CH6':270.424495, u'CH7':328.123456,u'CH8':465.627787,u'CH9':386.63469, u'_id': Objectld('563afebee138233a73b2at20')}
3.2 数据的查询
测量数据存储后,我们可以很方便的去查询,有相等匹配(equality matching)和条件匹配。相等匹配格式为:{
3.3 更新
集合更新的python接口有update_one()和update_many(),更新时需指定过滤条件和匹配的document要执行的动作。如result=collection.update_one({'TIME': '2015-09-22 20:33:10'},{“$set”:{"discription":“measure resistance”}}),会先匹配‘TIME域为‘2015-09-22 20: 33: 10的记录,然后更新其”discription”域的值为”measure resistance”,若没有该域,则会添加该域。其中,”$set”为设定域值运算符,其他更新运算符:”$inc”为指定域的值增加指定值,”$rename”用于重命名域名,”$push”向域值列表中添加元素。更新后的document为:
{u'CH10':102941.437, u'TIME': u'2015-09-22 20: 33: 10,u'discription': u'measure resistance',u'CH5': 918.236714, u'CH6': 270.424495, u'CH7':328.123456, u'CH8': 465.627787, u'CH9': 386.63469,u'_id':Objectld('563afebee138233a73b2af20')
3.4 聚合
MongoDB提供了一个聚合框架,其中包括常用功能,比如”$match”用于过滤记录、“$unwind”用于解绑列表、“$group”用于根据指定域聚合。其聚合是基于阶段( stage)来进行的,其参数为一个个阶段组成的列表,格式如下:db.collection.aggregate([
cursor=collection.aggregate(
[
{“$match”:{“CH5”:None}},
{“$group”:{“_id”:“$CH5”,“count”:{“$sum”:1}}}
]
)
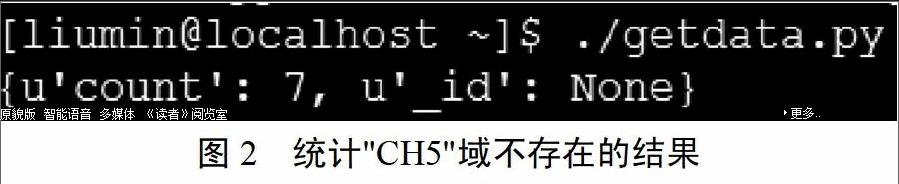
此聚合首先在第一阶段匹配”CH5”域不存在的记录,第二阶段以”CH5”域的值分组,并以“id”作为key,统计各组记录的数量,由于第一阶段只匹配”CH5”域不存在的组,所以该聚合统计的是集合中”CH5”域不存在的记录数。结果如下:
然而更多的高级聚合函数,比如sum、average、max、min、variance方差)和standard deviation(标准差)等需要通过MapReduce来实现。
4 结论
MongoDB提供了面向文档的存储结构,其模式十分自由,这很大程度增加了document的灵活性,可以很容易扩展支持TB级数据。同时其插入、查询、更新、聚合等操作也十分方便简易,支持C++、Python、Java等多种语言。本文结合实验室气象局研究项目,介绍了MongoDB的安装,以及它在气象传感器数据存储时的应用,项目实践证明了其灵活、易用等优点。相信在不久的将来以MongoDB为代表的Nosql将有更加广泛的应用。
猜你喜欢
现代电子技术(2017年3期)2017-03-04
软件工程(2016年11期)2017-01-17
经营者(2016年19期)2016-12-23
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2015年34期)2016-03-07
软件导刊(2015年8期)2015-09-18
电脑知识与技术(2015年10期)2015-05-29
软件导刊(2015年1期)2015-03-02