
中原地区古代陶器数据预处理研究
2016-01-12 08:58:40王松会,杨姗姗,李云娟
电子科技 2015年9期
中原地区古代陶器数据预处理研究
王松会,杨姗姗,李云娟
(华北水利水电大学 信息工程学院,河南 郑州450011)
摘要利用数据挖掘技术对中原地区古代陶器数据进行分析研究,会对探究古陶器的发展演变规律及中原地区各类型文化之间的传承源流、关系起到积极的推动作用。数据预处理作为数据挖掘过程的主要步骤,可提高数据质量和其后挖掘过程的准确率及效率。阐述了针对中原地区古代陶器数据具有的类型复杂、数据量大、不正确、不完整和不一致的特点,采用数据清理、数据集成和数据变换技术对其进行数据预处理,从而提高了数据挖掘模式的质量。
关键词数据预处理;数据清理;数据集成;数据变换
收稿日期:2015-04-12
作者简介:王松会(1988—),女,硕士研究生。研究方向:数据挖掘。E-mail:1042026596@qq.com
doi:10.16180/j.cnki.issn1007-7820.2015.09.007
中图分类号TP274
Data Preprocessing of Ancient Pottery of Central China
WANG Songhui,YANG Shanshan,LI Yunjuan
(School of Information Engineering,North China University of Water Resources and
Electric Power,Zhengzhou 450011,China)
AbstractData mining techniques are employed to analyze the ancient pottery data in Central China to explore the evolution of ancient pottery and the origins of roughly inheritance relation of the Central China between each type of culture,which is of great significance in archeology and anthropology.As the major step of data mining,data preprocessing can improve data quality,thereby helping to improve the accuracy and efficiency of the subsequent mining process.Because the ancient pottery in Central China has the features of complex types with large amount of incorrect,incomplete and inconsistent data,the data preprocessing techniques of data cleaning,data integration and data transformation are used,thereby greatly improving the quality of data mining models.
Keywordsdata preprocessing;data cleaning;data integration;data transformation
本文提出运用聚类分析方法对中原地区古代陶器的发展演变规律及中原地区各文化类型之间的大致传承源流和关系进行研究的设想,即对中原地区古代陶器的数据进行挖掘,以便从这些海量数据中发现有价值的信息。数据挖掘与知识发现过程中的第一个步骤就是数据预处理。统计发现,在数据挖掘的过程中,数据预处理占到整个工作量的60%。数据预处理是提高数据质量,为数据挖掘内核提供更有针对性的可用数据的关键[1]。本文主要阐述针对中原地区古代陶器数据的特点,采用相应的处理技术对其进行数据预处理,并以具体数据检测结果验证了预处理的效果。
1中原地区古代陶器的数据特点
本文所研究的中原地区古代陶器数据主要来源于中国知网提供的近千篇发掘简报,简报主要以河南省、陕西省、山西省、山东省和河北省的史前发掘为主,并且分别以文化区域、省份、遗址名称、地层分期、发掘情况、文物编号、数量、形制、质地、颜色、纹饰、壁厚、宽、高、口径、柄径、底径、腹径、肩径、足高、通高、颈高、流高、盘深、盘径等为属性对典型器物罐、盆、鬲、钵、豆、鼎、碗、壶、杯、瓮、盘、尊等建立数据库。数据类型涵盖标称属性、二元属性、序数属性和数值属性,总数据量约11 000条。由于简报中对器物的描述不尽详细或器物本身存有残缺,再加上人工建立数据库偶尔造成输入错误,这些问题都难免使数据存在缺失与不一致的现象。综上可知,中原地区古代陶器的数据具有类型复杂、数据量大、不正确、不完整和不一致的特点。
2数据预处理
现实数据大体上均是不完整,不一致的脏数据,无法直接进行数据挖掘,或挖掘结果差强人意。为了提高数据挖掘的质量产生了数据预处理技术。数据预处理包括数据清理、数据集成、数据归约和数据变换等几个方面[2]。这些数据处理技术在数据挖掘之前使用,大幅提高了数据挖掘模式的质量,降低实际挖掘所需的时间。因此,为防止低质量数据的侵扰,针对中原地区古代陶器数据的特点,本文提出了使用数据清理、数据集成和数据变换的数据处理技术对这些数据进行预处理,以提高数据挖掘过程的准确率和效率。
2.1 数据清理
数据清理例程试图填充缺失的值、光滑噪声并识别离群点、纠正数据中的不一致。本文对中原地区古代陶器的数据进行数据清理的基本方法是:(1)采用多元线性回归方法确定最可能的值填充缺失值。(2)采用离群点分析技术光滑数据,去掉数据中的噪声[3]。需注意的是,在某种情况下,缺失值并不意味数据有错误。理想情况下,每个属性都应当有一个或多个关于空值条件的规则。
2.2 多元线性回归
回归是用一个函数拟合数据来光滑数据。线性回归涉及找出拟合两个属性(或变量)的“最佳”直线,使一个属性可用于预测另一个[4]。多元线性回归是线性回归的扩充,其中涉及的属性多于两个,并将数据拟合到一个多维曲面,即根据一个或几个变量的值,预测或控制另一个变量的取值,并了解这种预测或控制能达到何种精确度。假设拟合函数是线性函数,则P元线性回归数学模型的方程组的矩阵表示形式为
Y=BX+ε
(1)
其中,Y=(y1,y2,…,yn)′,B=(b0,b1,…,bp)′,ε=(ε1,ε2,…,εn)′为求出多元线性回归模型中的参数b0,b1,…,bp,可采用最小二乘法,即在其数学模型所属的函数类中找一个近似的函数,使得这个近似函数在已知的对应数据上尽可能和真实函数接近。
2.3 离群点分析
可通过聚类来检测离群点。聚类技术将数据元组看做对象。其将对象划分为群或簇,使得在一个簇中的对象相互“相似”,而与其他簇中的对象“相异”[5]。通常,相似性基于距离函数。形心距离是簇质量的一种度量,其定义为簇中每个对象到簇形心的平均距离。簇Ci的“质量”可用簇内变差度量,其是Ci中所有对象和形心ci之间误差的平方和,定义为
(2)
其中,E是数据集中所有对象的误差的平方和;P是空间中的点,表示给定的数据对象;ci是簇Ci的形心。这个函数试图使生成的结果簇尽可能紧凑和独立。最典型的一种基于形心的技术的是k-均值。

图1k-均值划分算法
2.4 数据集成
数据集成可减少结果数据集的冗余和不一致,这有助于提高其后挖掘过程的准确性和速度[6]。针对本文所研究的数据存在模式集成的错误,即属性间的匹配问题。这主要表现在属性集中字段的重复出现,如 “壁厚”与“厚度”、“底径”与“座径”都是同一概念的属性。
2.5 数据变换
数据变换就是通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式[7]。对于本文研究的数据,其中壁厚、宽、高、口径、柄径、底径、腹径、肩径、足高、通高、颈高、流高、盘深、盘径等字段都属于数值类型,其距离度量所占的权重要远超过距离度量在二元属性上所取的权重,因此趋向于使这样的属性具有较大的影响或较高的“权重”。为了避免对距离度量的依赖性,数据应该规范或标准化,规范化数据试图赋予所有属性相等的权重。这涉及变换数据,使之落入较小的共同区间,如[0.0,1.0]。在多种数据规范化的方法中,在此使用“最小-最大规范化”。
最小-最大规范化对原始数据进行线性变换。假设minA和maxA分别为属性A的最小值和最大值。最小-最大规范化通过计算

(3)
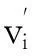
对于标称属性、二元属性和序数属性可使用混合类型属性的相异性技术将所有属性类型一起处理,只做一次分析。这将不同的属性组合在单个相异性矩阵中,把所有有意义的属性转换到共同的区间[0.0,1.0]上[9]。
混合类型属性的相异性:假设数据集包含p个混合类型的属性,对象i和j之间的相异性d(i,j)定义为
(4)


对于标称属性可对其进行细化,细化后包含如下一组属性:盖、沿、口、唇、领、颈、耳、肩、腹、裆、底和足。这可将数据变换为多个粒度,方便针对指定的部位进行数据挖掘,并使挖掘结果更加准确。
3实验与分析
实验所用数据为100条罐记录,其中包含河北省龙山文化、河南省二里头文化、山西省庙底沟文化、陕西省仰韶文化、山东省大汶口文化各20条。图2是针对于各文化区域挑选出的部分样本实例。

图2 100条罐记录的部分样本
由图2可知,罐中存在大量缺失数据。其中如盖、耳、裆、足、柄径等属性均是罐没有的特征,所以并不意味数据有错。可将这些数据定义为空值,其并不影响各对象之间相似性的比较。对于其他属性的缺失值先对它们进行规范化,具体用到式(3)对数值属性进行规范,之后利用多元线性回归方法对这些缺失值进行分析填充。对100条罐数据进行预处理,得到对应图2的数据预处理后的结果,如图3所示。

图3 预处理后的数据样本
对数据预处理后,利用“混合类型属性的相异性”中的式(4)计算两两对象之间的相异性d(i,j),其中1≤i≤100,1≤j≤100。这里以图3为例计算其10个对象的相异性矩阵,其中文化区域、省份、遗址名称、文物名称、盖、沿、口、唇、领、颈、耳、肩、腹、裆、底、足、质地、颜色等字段按标称属性来计算各对象之间的相异性,纹饰字段按二元属性计算相异性,高、口径、柄径、底径、腹径、肩颈、足高、颈高等字段按数值属性来计算。最后得到各对象之间的相异性矩阵如表1所示。
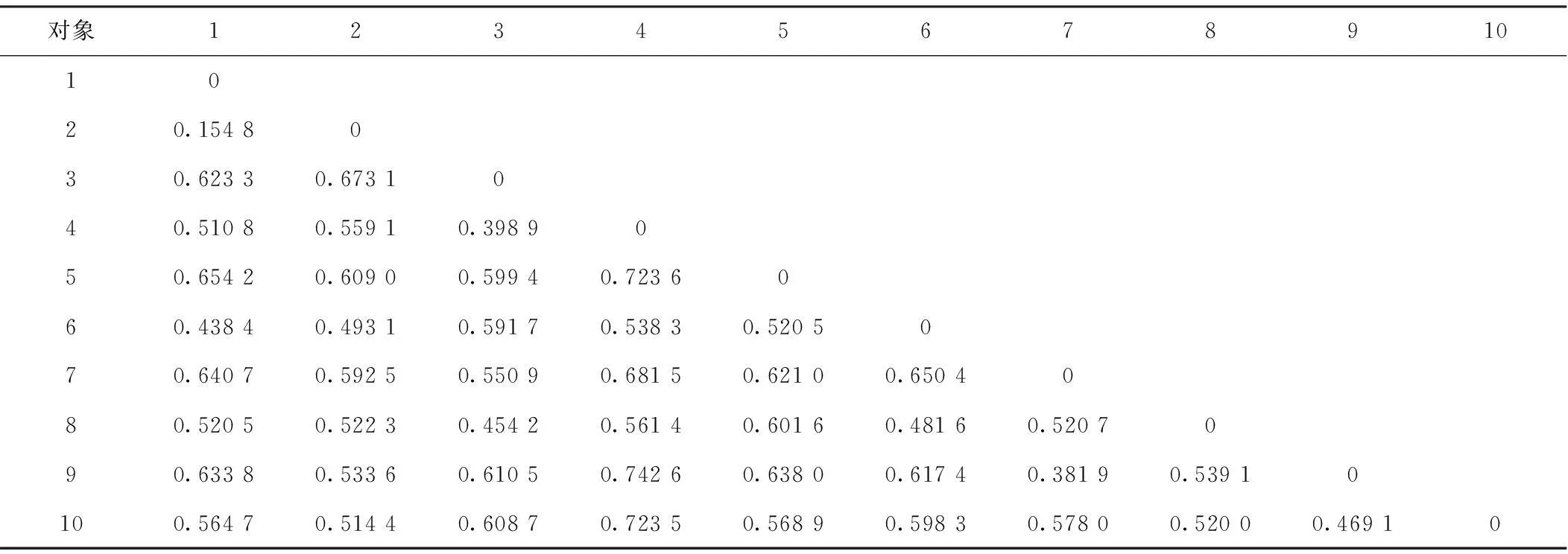
表1 对象之间的相异性矩阵
从表1中可知,对象1与对象2的相异性比较小,其值为0.154 8,即对象1与对象2的相似性较大。由k-均值的思想可知,对象1与对象2可归到一个“簇”中。同理,将100条罐记录按照上述方法进行数据预处理,并使用k-均值(参数k=5)聚类后的分析结果如图4所示。

图4 实验结果及准确度
4结束语
本文讨论了使用数据预处理技术对中原地区古代陶器的数据进行处理,具体介绍了多元线性回归、k-均值、最小-最大规范化、混合类型属性的相异性等技术。并以100条罐记录为实验数据,利用上述技术对中原5省的古陶器进行了分析,最终从数据聚类的实验结果可看到较高的准确度。这为接下来进一步研究中原地区古代陶器的发展演变规律及各文化类型之间的大致传承源流和关系打下基础。然而,数据预处理
伴随着整个实验过程,还需要做进一步研究以提高数据质量。
参考文献
[1]方洪鹰.数据挖掘中数据预处理的方法研究[D].重庆:西南大学,2009.
[2]程开明.统计数据预处理的理论与方法述评[J].统计与信息论坛,2007,22(6):98-103.
[3]菅志刚,金旭.数据挖掘中数据预处理的研究与实现[J].计算机应用研究,2004(7):117-118,157.
[4]汪明.数据挖掘综述[J].河北软件职业技术学院学报,2012,14(1):46-47.
[5]胡佩,夏绍玮.基于大型数据仓库的数据采掘[J].软件学报,1998,9(1):53-63.
[6]姜伟.基于数据挖掘聚类算法的研究及其应用[D].阜新:辽宁工程技术大学,2004.
[7]孙雪莲.数据挖掘中分类算法研究[D].长春:吉林大学,2002.
[8]孙孝萍.基于聚类的数据挖掘算法研究[D].成都:西南石油学院,2002.
[9]朱扬勇.数据挖掘实践[M].北京:机械工业出版社,2003.
[10]HanJiawei,KamberMicheline,PeiJian.数据挖掘:概念与技术[M].3版.北京:机械工业出版社,2012.

猜你喜欢
科技视界(2016年27期)2017-03-14 22:45:40
现代农业科技(2017年1期)2017-03-06 12:59:21
中国市场(2016年41期)2016-11-28 05:30:48
现代经济信息(2016年5期)2016-09-22 12:55:19
电脑知识与技术(2016年10期)2016-06-16 21:32:52
电脑知识与技术(2016年8期)2016-05-19 13:23:42
电脑知识与技术(2016年5期)2016-04-14 13:28:18
现代电子技术(2015年22期)2015-12-02 20:37:31
现代电子技术(2015年18期)2015-09-16 22:14:13
中国中医药图书情报(2015年3期)2015-09-09 20:49:23
