
日语文本语料库的开发与利用
2016-01-06 20:46耿治萌钟春琳刘玉琴
中国教育信息化·高教职教 2015年1期
关键词:数据分析
耿治萌+钟春琳+刘玉琴
摘 要:大连理工大学软件学院日语实验室创建的日语文本语料库JTCH(Japanese Text Corpus Handler)利用sen日语分词技术,以NHK、朝日新闻为主要文章数据来源,通过一系列搜索算法,对文章进行句子分析、数据分析和统计处理。为日语学习、教学以及科研提供了具有例句查找、数据统计和语句分析等多种功能的学习平台。
关键词:文本语料库;数据分析;日语分词;日语搜索
中图分类号:TP311 文献标志码:A 文章编号:1673-8454(2015)01-0058-03
一、引言
随着日语学习者的增多以及ICT(Information Communication Technology )技术的飞速发展,计算机网络技术对外语学习的辅助作用受到高度重视。传统的依靠人工积累进行例句分析,已经不能满足学习者对句子的质与量的要求,其准确性及真实性无法得到保障。
语料库是指在随机采样基础上收集的有代表性的真实语言材料的集合,是语言运用的样本(杨慧中,2002)。如果样本具有代表性,采样具有随机性,且样本的量又足够大,则可以认为,样本就是总体的真实代表;样本具有总体的统计特征,研究真正实际使用的语言材料更能体现日本文化和了解标准日本语。日语本族语料库具有代表性的是日本国立研究所(http://nlb.ninjal.ac.jp/)。其中包含句子104,805,763条,涵盖了经济、文化、政治等多个方面,有各类书籍;提供前后搭配词频统计的查询方法。虽然数据库数据庞大,但是因为功能较少,造成数据并没有被充分利用;现代日语书面语均衡语料库(BCCWJ)的目标是构筑一个均衡语料库,为使用者提供覆盖面广、代表性强、数量充足、能够全面反映现代日语书面语使用状况的语言样本(毛文伟,2011)。BCCWJ包含17万余本各类日本书籍(文学类书籍偏多),提供了两款网上检索工具,分别为“少纳言”和“中纳言”。前者不需注册,但仅提供了字符串检索功能;后者功能更加齐备,不过需要用户注册。“中纳言”提供三种语料检索方式,分别有短单位、长单位和以无长度限制字符串为单位。但是,由于BCCWJ功能较少,不能为日语学习者提供更高的查询要求。
综上,目前日本文本语料库的建设与应用,仅有日本本土的日本国立研究所和日本中纳言(https://chunagon.ninjal.ac.jp)。由于地域原因以及文化差异,中国的日语学习者在使用过程中总是无法得心应手。
大连理工大学软件学院日语实验室创建的日语文本语料库( 以下简称JTCH ),作为日语学习、教学以及日语研究的平台,提供各种搜索模式,辅助日语学习者通过大量的、原汁原味的日语例句习得日语语法、词汇,并通过各种统计功能了解日语语言的逻辑思维模式。
JTCH加载和存储NHK和朝日新闻的文章(2012-2014),包括32万个例句、4万篇文章的解析。
二、日语文本语料库建设
1.系统概述
(1)文本语料库创建模块
网络爬虫将NHK各地的新闻按照地域,将朝日新闻按照类别下载到本地数据库,同时自动生成标签、分句。
(2)功能模块
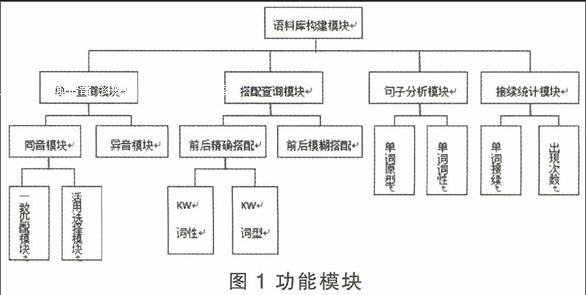
主要提供单一查询(单一精确词汇查询、模糊查询、多词查询)、搭配查询(指定位置、前后搭配、前后词性)两大模块查询。此外还有句子分析和接续词统计模块。详见图1 。
单一查询中单一精确词汇查询是指用户输入关键词是什么,便查询出含有该关键词的句子。例如「ある」: 28日午後2時半ごろ、愛知県犬山市の日本モンキーパークの遊園地にある「スカイダンボ」という空中ゴンドラの1台が、地上から5mほどの高さで突然動かなくなり、後続のゴンドラも次々に停まりました。
模糊查询是指根据关键词,用户自己选择关键词的活用类型,或者全部活用,查询出含有该关键词所有活用的句子。例如「ある」则查询出包含ある所有变型使用例句。
多词查询是特别针对一些一种词有多种写法的情况,从而根据用户输入多个关键词,查询出含有每个关键词的句子,例如「茶||お茶」。
搭配查询中的指定位置是指用户自己限定关键词的前三或者后三个词汇位置的词语或者词性,来满足更高的搜索要求。例如「食べる」我们可以指定该关键词前两个位置为名词,从而得到“リンゴを食べていいです”等例句。
前后搭配和前后词性是指用户仅限定某个词语或者词性在关键词的前边或者后边,而不去关注在前几后几,从而查出想要的结果。例如「食べる」我们限定它前边有「リンゴ」,则所有关于「食べる」前边带有「リンゴ」的句子都会出现。如:①恋なんて卒业毒リンゴ 食べてみたい。②リンゴをおいしそうに食べている。③リンゴを食べていいです。
词频统计是指根据用户输入的关键词,我们经过算法分析接续词的出现频率最高的前10个词汇,例如「ある」「ある」+「た」出现的次数最多,为14次;「ある」+「よう」频率为10次,依次类推,显示排名前10的结果。
2.开发相关技术
(1)创建,处理模块
为了使数据库管理更加方便,以Mysql数据库作为数据管理工具,基于Navicat for mysql的辅助以日本信赖度很高的NHK(http://www.nhk.or.jp/lnews/)和朝日新闻(http://www.asahi.com)为数据来源。因为这两个主流网站包含的数据量庞大(每天每个网站更新200篇文章左右),并且具有实时性和准确性。
创建语料库利用了java的多线程编程;httpclient、jsoup、ibatis实现了网站到java代码到数据库的连接。具体创建过程如下:
①通过httpclient的API调用实现主页加载,对加载获得的主页进行分析,获取关于文章的URL。
②通过URL,再次访问网络,将加载每篇文章,这里我们使用线程池技术避免了大量的资源占用,同时减轻CPU的负担。
③通过jsoup提供的解析功能对得到的每一个文章页面进行解析。得到我们希望得到的相关数据,例如文章title、content、url、type、author等信息。这些信息我们用article的类进行封装。
④使用iBATIS工具进一步处理。将数据库中的id设置为自增长型,将文章分解为一个个的sentence存到数据库中,每个sentence中都保留了文章的id和在文章中的位置。
⑤文章分类问题
语料库的类别在对语料库的研究中也起着关键性的作用,我们对朝日新闻和NHK的文章分类如下。朝日新闻:スポーツ、社会、国際、経済、政治、サイエンス、カルチャー、教育テック&サイエンス 等;NHK由于主要使各个地方的新闻汇聚在一起,所以它是按照地域分类的,由于地方较多,不一一列举,我们选择在搜索的时候将地域展示给读者,以方便了解地域文化和地域差异。
⑥定时器
每天晚上12点网络爬虫开始工作,下载数据。
(2)各检索模块功能实现
为了提高搜索速度,第一版文本语料库采用的是Lucene作为一个全文检索引擎,虽然lucene检索引擎具有很多优点,但是由于要和数据库进行连接,数据库是在传统硬盘中进行存储,硬盘检索速度和内存检索速度相比,仍然有着几千倍的速度差,所以我们考虑将数据读入内存来提高检索速度。传统的数据库只是用来进行文本存储,更新和备份使用。
通过序列化形式将文章和句子加载到内存中,直接在内存中对文章和句子进行检索,检索并不是每一条挨着查找,而是创建合适的索引,在我们的文本语料库中选择以每个日语词汇的基本型为key,value表示词汇出现句子的id,在检索时首先通过对索引的检索,来减少检索次数,提高速率。
依靠sen工具将一个句子分成发音、原型、分词以及变形,实现对日语句子或者文章进行分析。首先把句子的每个词分解出来,然后对每个词进行词性(属于哪一类词、哪种变形等)、基本型、发音、平假名写法、在句子中的位置等做出解析,同时也能统计出句子长度。
日语文本语料库正是在sen工具包(简称sen)的基础上,通过对sen的二次开发,实现对日语文本语料库进行分析和查询。
在大量数据的基础上,通过sen进行数据解析,然后对数据再分析,从而查询到需要的结果。
(3)句子分析和语料分析
通过sen分词技术对用户输入的语料(短语、句子、文章)进行词法、语法、词频等方面的分析和统计。词频统计是针对关键词的各种后续搭配出现的频率及数目进行统计,并显示具体例句。算法主要是利用排序算法和sen本身带有的数据统计功能。
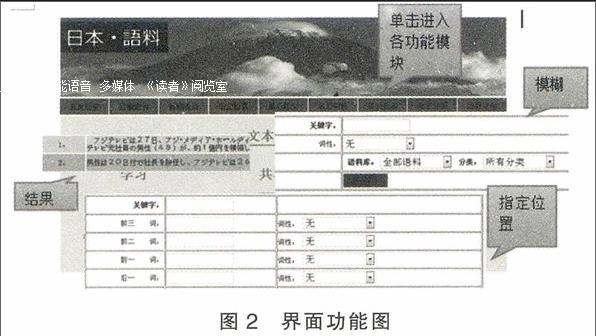
(4)界面部分功能展示(见图2)
三、今后的课题
我们所开发的文本语料库还只是日语语料库中的冰山一角,伴随算法的进一步完善,如何使查询速度有更大的提高,面对将来可能的数千万计的数据又该如何处理,这些都将是我们今后研究的课题。
(1)召集一些有想法有能力并且热衷于研究的学生参与到我们的项目中,增加和完善文本语料库的功能,美化界面,简化操作。
(2)增加语料库内容的丰富性,使语料包含更多的信息。
(3)对语料库数据进行整体分析,而不是局限于某个词语,从而分析出日本当前关注点在哪里,了解日本各方面的发展趋势。
(4)在学习和研究的过程中,及时对使用者的使用情况进行反馈,不断改进系统的不足,使系统愈加完善,尽可能满足用户的使用。
四、结束语
系统开发的过程是艰难而又充满挑战的,经过7个月的研究开发,目前文本语料库已经基本成型,需求分析的所有功能基本实现,并且在算法优化、数据稳定以及网络支持方面都有较好的突破。
良好的平台设计和技术支持,为更大数据量的语料提供了坚实的基础。截至发稿日,日语语料库已有文章41026篇,语料库的语料容量大、代表性强,为日语学习者提供了强有力的支持。
参考文献:
[1]杨慧中.语料库语言学导论[M].上海:上海外语教育出版社,2002.
[2]谭晶华,毛文伟.中国日语学习者语料库CLJC建设及应用综述[J].日语学习与研究,2011(4):23-29.
(编辑:王天鹏)
猜你喜欢
商情(2016年40期)2016-11-28
科技资讯(2016年18期)2016-11-15
考试周刊(2016年84期)2016-11-11
商场现代化(2016年22期)2016-10-18
