
面向对象存储的文件系统Lustre
2015-12-23 00:54聂瑞华
计算机工程与设计 2015年6期
梁 军,聂瑞华
(1.华南师范大学 网络中心,广东 广州510631;2.华南师范大学 计算机学院,广东 广州510631)
0 引 言
相比于传统的文件系统及存储系统存在主机带宽、内存容量以及主机可用性等性能方面的限制,分布式文件系统不仅能为用户提供海量的存储空间和高聚合的I/O 带宽,并且支持众多的客户端同时并发访问,具有良好的可扩展性。
在分布式文件系统[1-3]中,面向对象存储的文件系统成为研究热点。Lustre文件系统[4,5]是面向对象存储的文件系统中的一种,它是一个大规模的、高性能的、高可用的集群文件系统。本文通过普通PC和TCP/IP协议搭建了Lustre文件系统,并测试和优化了整个系统的性能。在TCP/IP协议上实现和优化Lustre文件系统,使Lustre大规模应用成为可能。
1 Lustre文件系统架构
Lustre文件系统由3 部分组成[6]:元数据服务器(MDS)、对象存储服务器 (OSS)和客户 端 (Client)。MDS负责元数据的管理,向客户端提供整个文件系统的元数据信息,并维护整个文件系统的目录创建、删除、修改等访问控制,向外提供元数据存储和访问接口。OSS负责客户端和物理存储之间的交互及数据的存储,向外提供数据的I/O 接口。client与MDS进行元数据的交互,与OSS进行文件对象的交互,用户通过client透明地访问数据,而不用关心数据的存储位置。MDS、OSS和clent可以安装在不同的机器上,也可以安装在同一台机器上。MDS、OSS和client相互分离,可以提高Lustre系统的性能。
2 Lustre工作机制
2.1 Lustre交互过程
Lustre内部组件如图1 所示[7,8]。在客户端 (Clent),Lustre通过把Llite层挂在linux 内的VFS层上,来实现统一的文件系统接口访问。客户端通过MDC 向MDS获取元数据,包括文件对象的布局信息。客户端中的LOV 解释文件布局信息,使OSC可以和OSS中的OST 请求交互信息;在对象存储服务器端 (OSS),通过OST 组件调用不同的函数来处理客户端的请求:锁相关请求和数据相关请求。OST 调用ldlm 处理锁相关的请求,调用obdfilter处理数据相关的请求;在元数据服务器端 (MDS),通过MDS组件调用ldlm 和Journal来处理不同的事务[9]。Client和OSS、client和MDS 都是以RPC 请求和应答的形式交互,组件PTR-RPC和LNET 实现该功能。
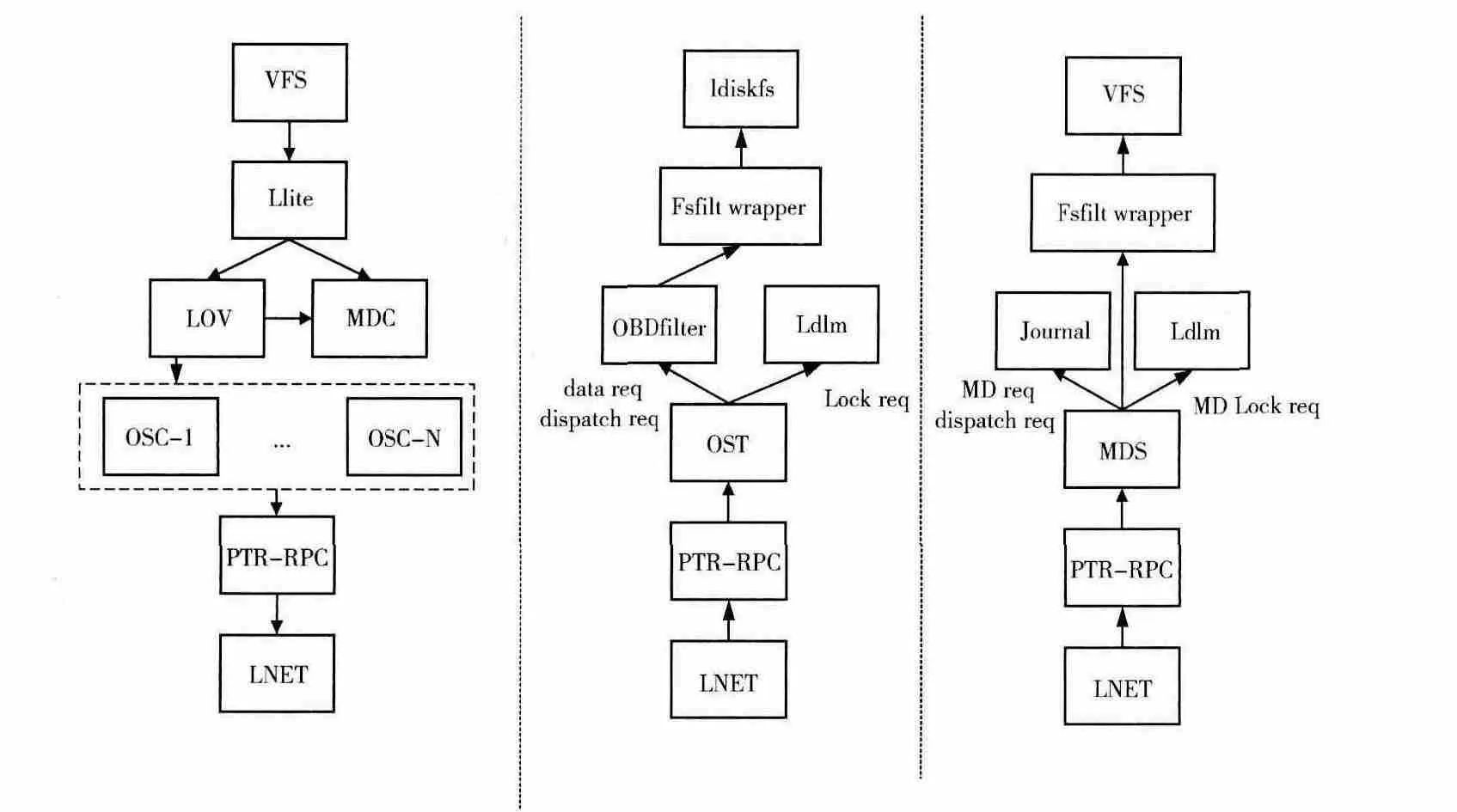
图1 Lustre内部组件
2.2 分布式锁模式
分布式锁管理器使集群系统中的节点或进程可以同步访问共享资源。在图1 中,OSS和MDS都有ldlm 锁组件来处理锁相关的操作。Lustre系统中锁模式有6 种,如下所示。
(1)独占模式 (exclusive,EX),独占获得的资源,并且其它进程不能读写该资源。
(2)保护写模式 (protective write,PW),允许资源持有者读和写,非持有者并发读,不允许其它访问者写操作。
(3)保护读模式 (protective read,PR),允许所有访问者并发读,不允许写操作。
(4)并发写模式 (concurrent write,CW),允许资源持有者和其它访问者并发读写操作。
(5)并发读模式 (concurrent read,CR),允许资源持有者和其它访问者并发读操作。
(6)空模式 (NULL,NL),当没有其它锁存在时,为空模式。
2.3 分布式锁的获取与释放[10,11]
当有客户端请求对资源进行锁模式时,OSS和MDS中通过ldlm 组件处理该请求。当客户端持有锁时,它不会主动释放,当其它客户端请求的锁与它相冲突或者锁过期时,才会释放锁。
获取分布式锁的过程如下:
(1)锁客户端首先匹配锁请求,首先调用ldlm_cli_enqueue函数检查ns_client标志来判断锁请求是否属于本地名字空间。如果是本地的,不需要发送RPC 来通信,跳转到第 (5)步;否则,需锁服务器来处理。
(2)当锁服务器收到锁请求时。首先重新建立一个锁,然后检查该锁是否有意图。如果没有,则跳到第 (3)步,如果有,则调用意图处理函数决定是否授权锁,当客户端从服务器获取返回的锁获得授权后,客户端进程就能对资源进行访问了。
(3)如果没有锁意图,DLM 检查该锁与要访问的资源上的锁是否有冲突,如果没有,锁将被授权,同时返回授权的锁。
(4)如果有冲突,DLM 将新锁放入队列等待,然后通知冲突锁的持有者撤销冲突锁,直到没有冲突。这时新锁被授权,DLM 通过回调函数通知客户端它请求的锁已获得授权。
(5)对于本地锁请求,首先创建一个锁,然后调用ldlm_lock_enqueue()来检查这个锁是否被批准。如果锁被批准或者出现了错误,则返回。否则,锁加入锁等待队列,需等待。
释放分布式锁的过程如下:当锁的读计数和写计数有一个不为0时,则需等待其它进程不使用该锁的资源。当它们都为0时,客户端会根据锁的类型清除缓冲的数据,然后从本地锁命名空间中删除该锁,并通知锁服务器释放该锁。
3 性能测试
本文使用6台普通PC机、1台服务器和1台千兆交换机做性能测试。PC机的配置为:AMD 双核处理器、2G 内存、千兆网卡;服务器的配置为:四核Intel处理器、8G内存、千兆网卡,网络拓扑如图2 所示。在3.1 和3.3 节中,5台PC机单独做5个OST,1台PC机单独做客户端,服务器做MDS。在3.2节中,4台PC 机单独做4个OST,1 台PC机同时做OST 和客户端,1 台PC 机单独做客户端,服务器做MDS。
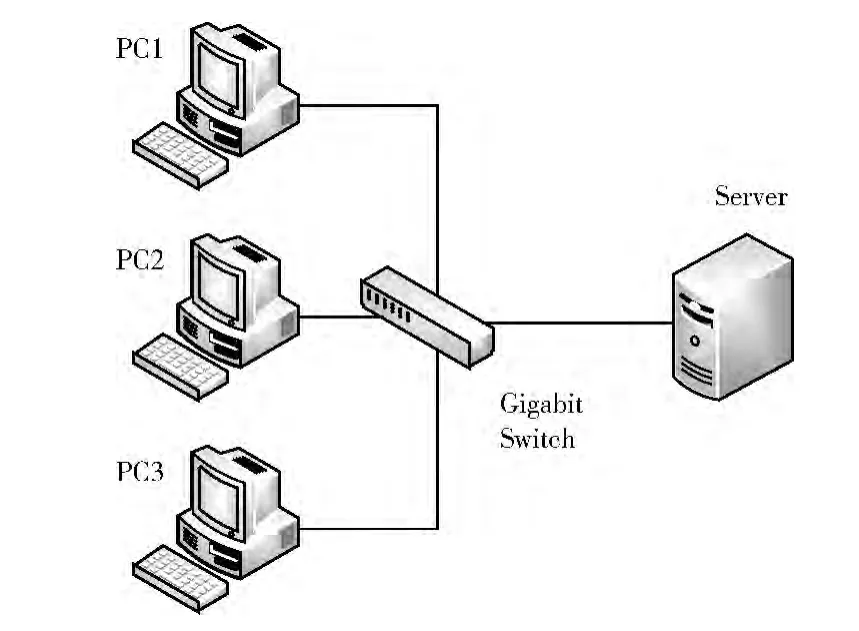
图2 网络拓扑
在各节点中,使用的操作系统版本为CentOS5.3,Lustre文件系统版本是1.8.1,测试工具是IOzone3.4。假设client_num 表示客户端数,stripe_count表示Lustre系统的条块数,stripe_size 表示Lustre 系统的条块大小,block_trans表示块传输大小,file_size表示读写文件的大小,start-ost等于-1表示目标文件会条块化存储在所有可用的OST 上。
3.1 Lustre参数设置测试
3.1.1 stripe_count参数
假设client_num=1,stripe_size=2MB,start-ost=-1,file_size=4GB。在不同大小的stripe_count下,Lustre的读性能和写性能如图3和图4所示。
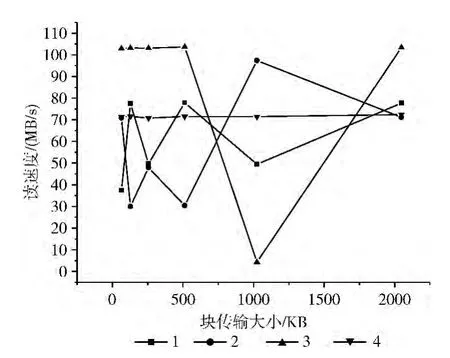
图3 不同stripe_count下的Lustre读文件性能
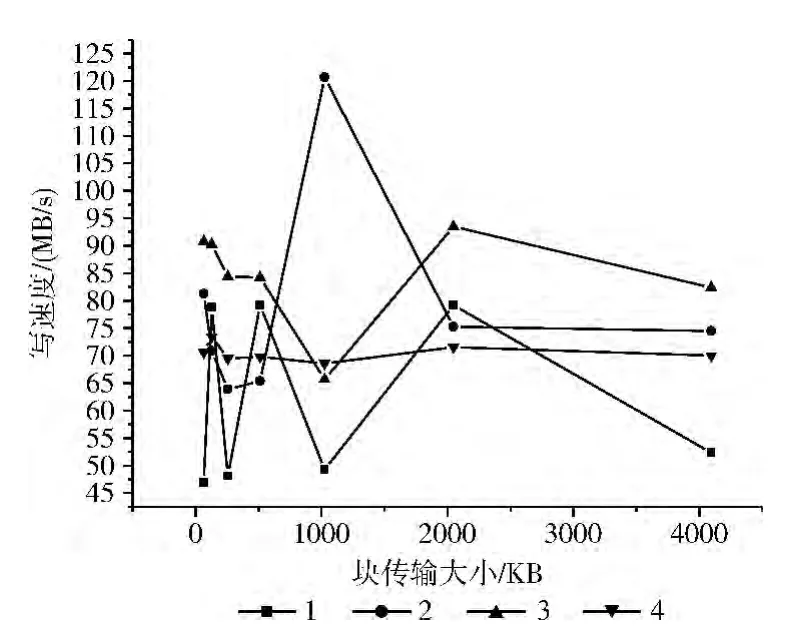
图4 不同stripe_count下的Lustre写文件性能
从图3 和图4 可以看出:在block_trans=64、128、256、512、2048,stripe_count设置为3时,Lustre系统的读文件速度和写文件速度最优。当block_trans=1024时,Lustre系统不稳定,有明显的波动。从理论上说,随着stripe_count的增加,系统可以同时进行多个读写任务,Lustre文件系统的并发性能逐渐提升,系统的读写系统应该更高。但在实际测试中,当stripe_count等于4 时,Lustre系统读写4GB 文件的速度小于stripe_count=3 的情况,说明文件的分解、网络的传输等额外的开销会对Lustre文件系统的并发性能产生很大的影响。
3.1.2 stripe_size参数
在3.1.1节中,stripe_count设置为3使得Lustre系统在大多数块传输中读写文件性能最优。假设client_num=1,stripe_count=3,start-ost=-1,file_size=4GB,改变stripe_size的大小,测试其对系统性能所带来的影响。不同stripe_size下的Lustre读写文件性能如图5和图6所示。
从图中看出:当block_trans=64、256、1024、2048、4096时,设置stripe_size为4MB,系统读文件性能最优;当block_trans=64、128、256、512、2048、4096 时,设置stripe_size为4MB,系统写文件性能最优。当block_trans等于其它的值时,设置stripe_size为4MB,系统读文件和写文件的性能虽然不是最优,但也有较好的性能表现。当stripe_size设置偏小时,文件被分割成块的数量增多,块数过多会加重MDS的管理负担和增加网络延时,将会造成整个文件系统的读写性能不佳;当stripe_size设置偏大时,文件被分割成块的数量减少,不能充分利用系统的并发系统,也会使文件系统的读写性能达不到最优。所以,需要设置合适的stripe_size的大小来优化整个系统的性能。
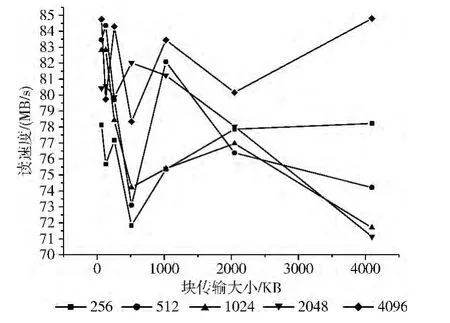
图5 不同stripe_size下的Lustre读文件性能
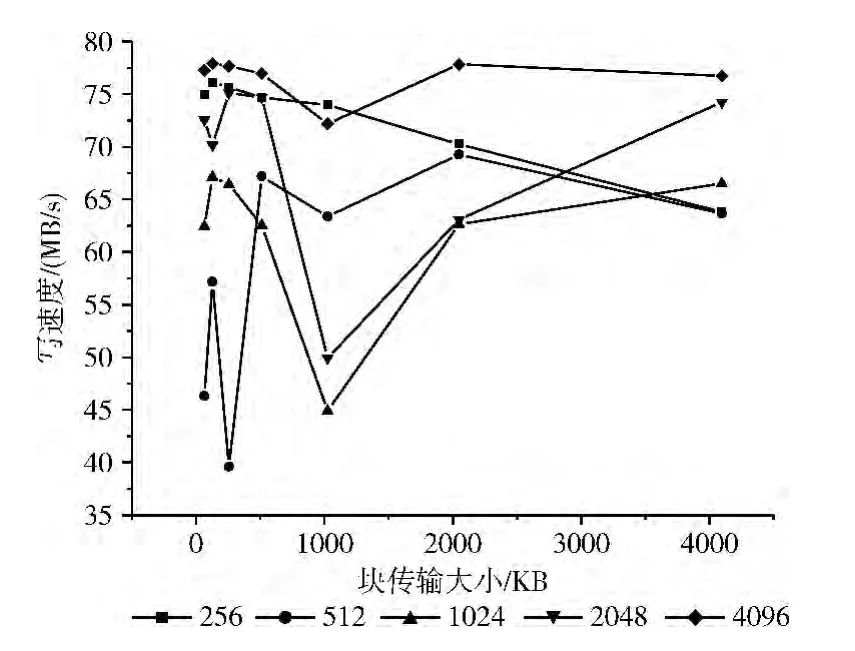
图6 不同stripe_size下的Lustre写文件性能
3.2 客户端数大于2的Lustre性能测试
假设client_num=2,stripe_size=2MB,start-ost=-1,file_size=4GB,lutre系统在不同的stripe_count下的读文件性能、写文件性能如图7和图8所示:当stripe_count=1、2、3时,Lustre集群系统的读写性能曲线呈现出抛物线形式;当stripe_count=4时,Lustre集群系统性能相对稳定。当Lustre客户端增加时,增大stripe_count值才能使集群系统的性能较稳定。
把图7、图8和图3、图4相比较,可以看出:在其它参数一样的情况下,客户端为2的Lustre集群系统比客户端为1的Lustre集群系统的读写速度普遍要低。图9是stripe_count=4时,不同客户端下Lustre的读性能。分析以上图可得出结论:增加客户端数不仅没有发挥Lustre系统的并发性,而且还降低了整个集群系统的性能,这可能是网络速度较低或MDS的性能较低引起的。这也说明了中间的传输开销和控制开销也会使Lustre系统发挥不出并发性能。
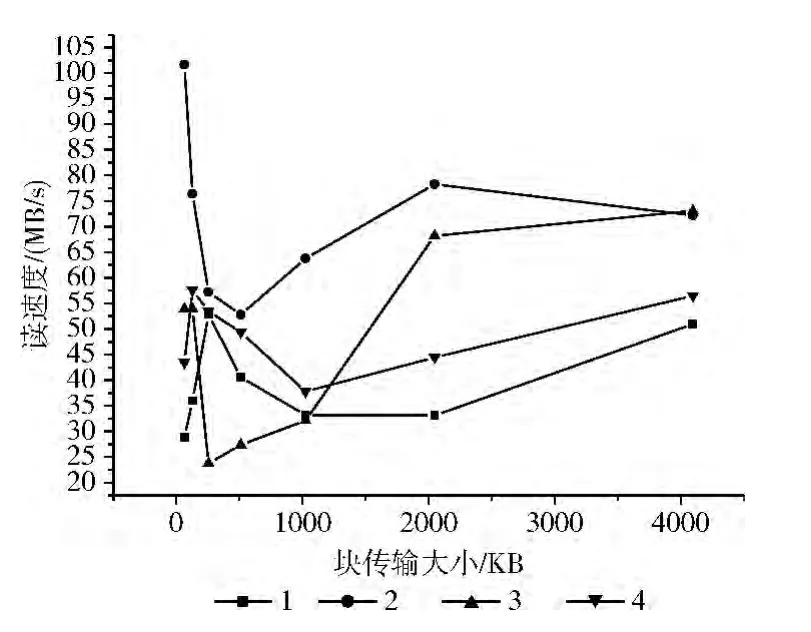
图7 客户端数为2的Lustre读文件性能
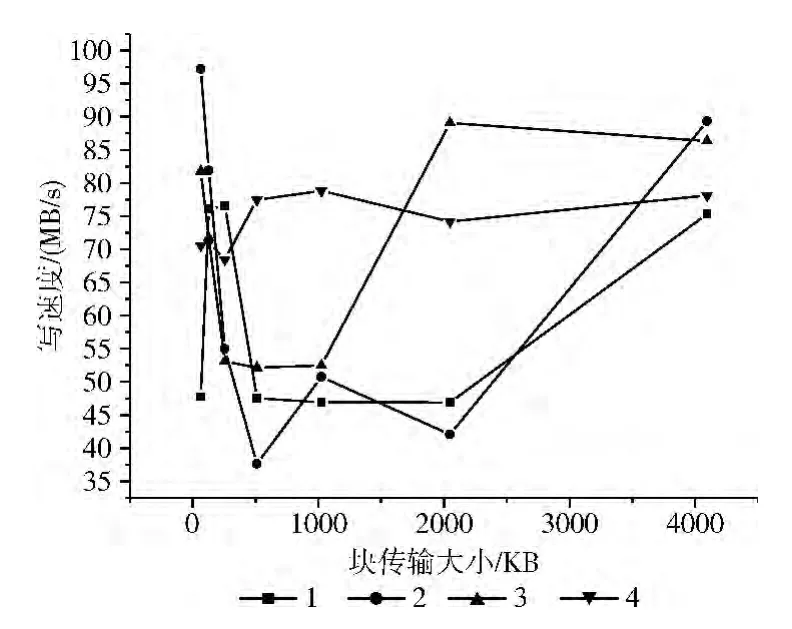
图8 客户端数为2的Lustre写文件性能

图9 不同客户端数的Lustre读文件性能
3.3 Lustre与本地文件系统的比较
传统的文件系统操作简单,管理方便,但它的扩展性差和吞吐量低,同时也无法实现多个平台之间的资源共享。Lustre采用条带化存储技术,以类似RAID0方式将文件分割成多个数据块对象存储于OST 上,每一个条块都作为一个对象存储在一个OST 上,即一个文件对应多个OST,同时每个OST 上也分布有多个不同文件的条块。
在Lustre系统中,假设client_num=1,stripe_count=3,stripe_size=4MB,start-ost=-1,file_size=4GB。图10是本地磁盘与Lustre读写性能的比较,从图中看出:本地文件系统的读文件速度为40MB/s~60MB/s,写速度为38MB/s~45MB/s;Lustre的读文件速度为79MB/s~85MB/s,写速度为72MB/s~78MB/s。所以,相对本地文件系统,Lustre读写速度更快。Lustre系统在infiniband交换机上的写文件速度大于读文件速度,但在千兆交换机上测试的写文件速度小于读文件速度,说明网络延迟会颠覆Lustre系统的特性。
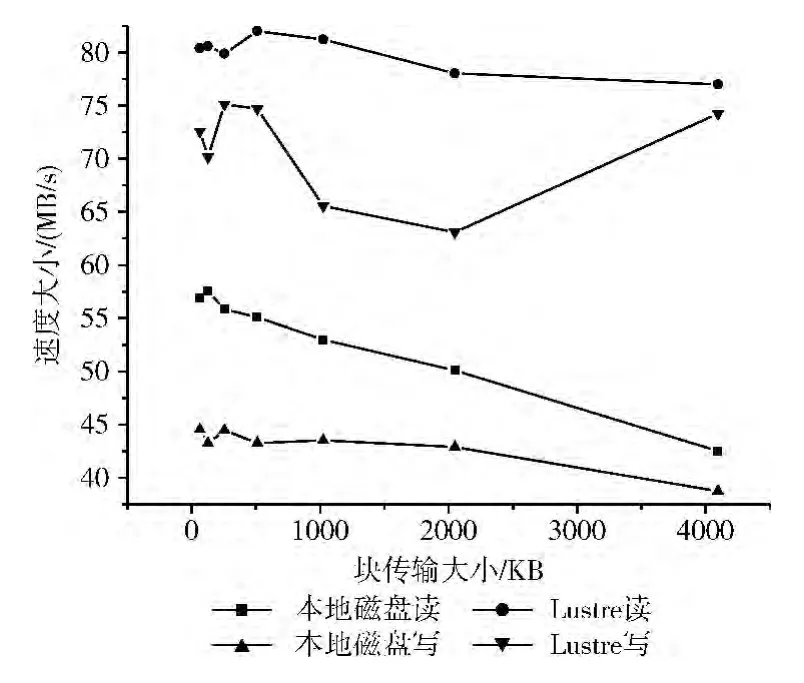
图10 Lustre与本地文件系统的比较
4 结束语
通过以上的实验测试分析可知:Lustre集群系统在TCP/IP协议下,通过千兆网络交换机实现时,设置start-ost=-1,file_size=4GB,stripe_size=4MB,stripe_count=3,client_num =1,Lustre 系统性能较优,因此,Lustre文件系统的参数设置对其性能发挥有较大的影响,合理的参数配置能提升Lustre文件系统性能。在该环境下,网络延迟、传输开销和控制开销都会极大影响,甚至颠覆Lustre系统的特性,但相对本地磁盘系统,Lustre系统仍有较大的性能提升,有一定的实用性。
[1]Marshall Kirk McKusick,Sean Quinlan.GFS:Evolution on fastforward [J].ACM Queue,2009,7 (7):10-20.
[2]Mohamad Sindi.Evaluating MPI implementations using HPL on an infiniband Nehalem Linux cluster[C]//Seventh International Conference on Information Technology:New Generations,2010:19-25.
[3]Olson M.HADOOP:Scalable,flexible data storage and analysis[J].IQT Quarterly,2010,1 (3):14-18.
[4]Oracle.LustreTM 1.8operations manuaL [EB/0L].http://wiki.lustre.org/images/0/09/821-0035_v1.3.pdf,2010.
[5]Sun microsystems,lustre file system datasheet [R].Santa Clara:Sun Microsystems,2008.
[6]Swapnil Patil,Garth Gibson.Scale and concurrency of GIGA+:File system directories with millions of files [C]//Proceedings of the 9th USENIX Conference on File and Storage Technologies,2011.
[7]ZHOU Jiang,WANG Weiping,MENG Dan,et al.Key technology in distributed file system towards big data analysis[J].Journal of Computer Research and Development,2014,51(2):382-394 (in Chinese).[周江,王伟平,孟丹,等.面向大数据分析的分布式文件系统关键技术 [J].计算机研究与发展,2014,51 (2):382-394.]
[8]Carns P,Lang S,Ross R,et al.Small-file access in parallel file systems[C]//Processdings of the 23rd IEEE International Parallel and Distributed Processing Symposium,2009.
[9]ZHAN Keyu,LIU Haitao,LI Xiaoyong.Design of metadata high availability in distributed file systems[J].Journal of Chinese Computer Systems,2013,34 (4):801-805 (in Chinese).[战科宇,刘海涛,李小勇.分布式文件系统元数据服务器高可用性设计 [J].小型微型计算机系统,2013,34(4):801-805.]
[10]QIAN Yingjin.Research on key issues in large scale clustered file system lustre[D].Changsha:National University of Defense Technology,2011 (in Chinese). [钱迎进.大规模Lustre集群文件系统关键技术的研究 [D].长沙:国防科学技术大学,2011.]
[11]CHENG Yu,LI Xiaoyong,DONG Xiaoming,et al.Design and implementation of a highly concurrent client in distributed storage systems[J].Journal of Chinese Computer Systems,2014,35 (1):24-29 (in Chinese). [程煜,李小勇,董晓明,等.分布式存储系统中高并发客户端的设计与实现 [J].小型微型计算机系统,2014,35 (1):24-29.]
猜你喜欢
能源工程(2022年2期)2022-05-23
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
电子测试(2018年10期)2018-06-26
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
