
仿人脑视皮层机制的目标识别方法
2015-12-23 01:09:00李岳云许悦雷马时平史鹤欢
计算机工程与设计 2015年8期
李岳云,许悦雷,马时平,史鹤欢
(空军工程大学 航空航天工程学院,陕西 西安710038)
0 引 言
通过人脑视皮层的实验,研究学者们积累了大量的先验知识,并尝试将其推广到计算机视觉中,取得了极具意义的研究成果。Robinson等[1]在视觉皮层研究中发现,视觉信息的处理方式是一种多层分级的结构;Riresan等[2]模拟视皮层简单、复杂细胞构建了卷积神经网络,卷积神经网络多层级联的结构以及同平面上的权值共享,极大程度避免了神经网络权值训练的时间消耗,它在手写字体的识别上取得了不错的效果;Huang等[3]基于前人视皮层腹侧通路研究提出与灵长类大脑类似的皮层等级处理模型HMAX,通过抽取边缘信息的 “碎片集”作为特征集,结合支持向量机SVM 或者Adaboost能够有效地实现目标分类,但它也存在着运算量大,训练样本太多的问题;Jim Mutch等[4]根据神经元横向侧抑制的特点对HMAX 模型进行改进,稀疏了所抽取的特征,减少了冗余和计算量,在某些情况下识别率得到了提高,但它对复杂图像的处理效果却不是很理想,同样对特征的描述不够;Lowe等[5]总结了不变量的特征检测方法,并提出了一种基于尺度空间的、对图像缩放、旋转甚至仿射变换保持不变性的图像局部特征描述算子SIFT,但该描述算子复杂度太高,计算非常耗时;Duraid Abdullah等[6]将金字塔梯度方向直方图PHOG(pyramid histogram of oriented gradient)用于视觉机制中,对视觉特征的简化有一定的改进,减小了计算复杂度,提高了速度,但该方法建立的模型与脑机制契合度不够,处理的图像也比较简单。
本文针对传统方法的不足,基于视皮层分级处理的框架结构,模拟皮层腹侧通路的信息处理方式,结合Gabor滤波器与初级皮层简单细胞的相似特性,利用该滤波器提取边缘,根据复杂细胞的max-like机制,进行局部和全局的最大化操作,稀疏化边缘特征,同时能够有效增加尺度和旋转的不变性,使得目标的识别更具有鲁棒性。通过训练图像抽取的PHOG 特征构建完备字典,以该字典对测试图像进行表示描述,用最终表示描述的特征去训练多类SVM 分类器,进行分类识别。
1 视觉皮层结构
人脑不是直接根据外部世界在视网膜上的投影成像,而是经过聚集过程和因素分解过程处理以后的信息来识别物体。视皮层能够对视神经感知信号进行提取和计算,而不仅仅是对视网膜上投影的图像实现再现。生理学实验表明,视觉信息的传递有腹侧和背侧两条通路,前者主要是处理目标的形状、轮廓、边缘、颜色和纹理等静态信息,与目标的识别有很大的关系;后者主要对目标的运动和朝向等动态信息进行加工,与运动的识别密不可分。背侧通路和腹侧通路虽然所处理的视觉信息种类有所区别,但它们的工作方式有很大的相似性,并不是单独分开作用的[7,8]。图1是人眼视觉皮层结构。

图1 人眼视觉皮层结构
神经学、解剖学和生理学不断证明视觉信息的传递和处理是通过逐级分层进行的。视觉信息处理通路从结构上来说,主要包括视网膜、侧膝体 (LGN)和大脑皮层3部分。视皮层又有V1、V2、V3和V4等部分,它们都是腹侧通路和背侧通路的重要构成。在视觉皮层内视觉信息又是按照简单细胞、复杂细胞、超复杂细胞、祖母细胞[9]这样的一个特定的序列来逐级进行传递的。构成一个由低级到高级、由简单到复杂分层逐级传递的完善的视觉信息处理系统。
2 PHOG 和卷积神经网络
2.1 PHOG
PHOG 是能够同时对物体整体形状和局部形状空间分布有较好描述的形状特征描述符,在不同层次上统计边缘图像的梯度方向直方图分布情况,具有较强的抗噪性能和一定的抗旋转能力。其基本流程是:首先得到一幅边缘图像,并求取边缘图像的梯度方向,量化梯度方向值,统计各梯度方向值的个数,形成梯度方向直方图,然后逐级分割图像,计算每一个分割区域的梯度方向直方图,再将全部区域的梯度方向直方图连接起来,从而形成一个梯度方向金字塔 (这不同于SIFT 的直方图),最后将直方图进行归一化。梯度方向的计算由式 (1)、式 (2)完成
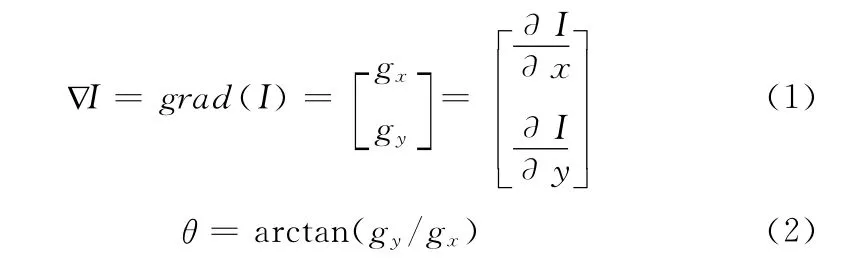
式中:I表示原图像,gx,gy分别是x,y方向的方向导数,求得的θ即为梯度方向。一般将360°的梯度方向量化成若干个区间 (每个区间在直方图中以条状表示称为bin),例如:在很多人脸识别中采用8个bin,这样每个bin表示的角度范围为45°。当采用8个bin,分层数Level=0时,梯度维数为8;Level=1 时,梯度维数则为8× (1+4)=40;Level=N 时,梯度维数的一般计算式为8×(1+4+42+…+4N)。图2是以一幅自然图像为例抽取其PHOG特征的简单过程。
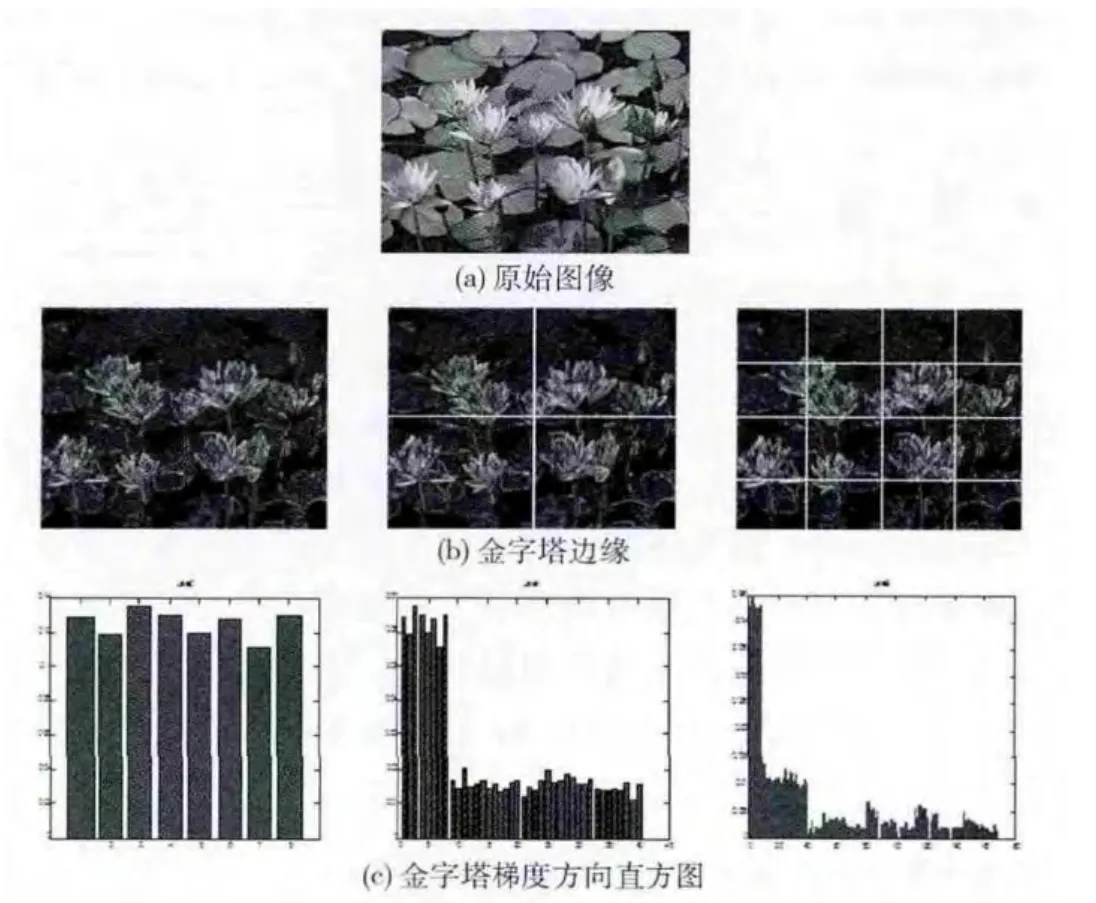
图2 抽取PHOG 特征流程
2.2 卷积神经网络
卷积神经网络由特征提取层和特征映射层所组成。特征提取层选取一系列不同的滤波器与图像进行卷积,得到的结果称为特征图谱,多个滤波器可以分别探测出不同的特征。特征映射层是计算层,同样有多层,它是神经网络的连接方式,一个映射层为一个平面,其所有神经元权值相等,该层一般采用sigmoid函数作为激活函数。通过多级卷积层和计算层级联连接到一个或多个全连层,全连层的输出就是最终的输出。
卷积神经网络的结构如图3所示。
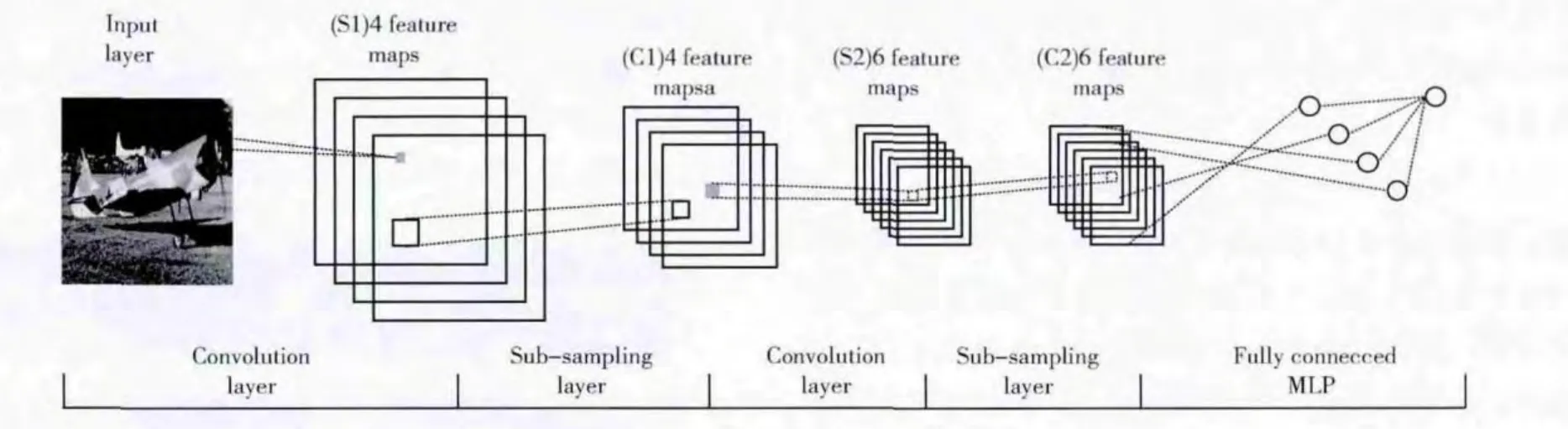
图3 卷积神经网络的结构
3 仿人脑视皮层机制目标识别模型
在视觉信息分层等级处理的框架上,利用PHOG 能够对形状边缘很好描述的特性,根据腹侧通路处理信息的流程构建如图4 所示的仿人脑视觉皮层机制目标识别模型。它主要包括卷积层、下采样层、特征提取层和特征形成层4个层,特征提取层层递进,逐级运算,由简单到复杂,由初级到高级。下面具体解释各层的实现方式。

图4 仿人脑视皮层机制目标识别模型
V1区简单细胞对特定位置特定朝向的简单线条比较敏感,在模型中用Gabor滤波器来模拟实现,它能够有效地描述简单细胞的感受野特性。对于卷积层,将输入图像简单预处理后,通过与一系列Gabor滤波器卷积便得到特征图谱。一个二维的Gabor滤波器表示形式为

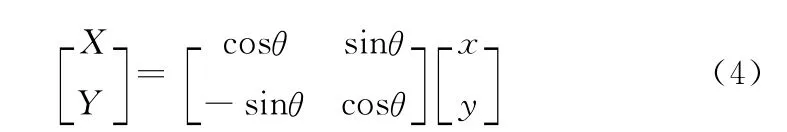
式中:λ为复正弦函数的空间波长,σ2为高斯函数方差,代表Gabor滤波器的尺度,θ是滤波器的方向,γ为空间宽高比。因此,卷积层输出的特征图谱可以表示如下
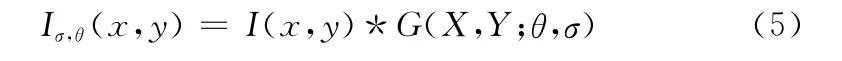
式中:I(x,y)——灰度变换后的原图像,Iσ,θ(x,y)——滤波后的特征图谱。这里选取滤波器8个尺度,9个方向,共72幅特征图。
下采样层模拟的是V1区的复杂细胞,它的感受野是简单细胞的两倍,同时具有同朝向边缘的位置和尺度不变性等特性,它的主要功能是对特征图进行计算。在模型中,对特征图谱实现下采样操作。具体而言,取特征图谱中相同方向相邻尺度的图像,分别以相同尺寸的小模板滑动取最大值,该操作可以实现一定的平移和尺度不变性。将所有特征图谱进行该操作,此时的特征图减少了一半。人视觉对所有感受野中的目标不是一视同仁的,Jim Mutch等[4]认为人所注意的区域非常有限,因此进一步稀疏了特征图,即求取同一尺度上各个方向上的最大响应值,该响应方向便是视觉最感兴趣的主方向。此时特征图已经减少到了8幅,实现了特征图极大的精简。
特征抽取层是为了抽取下采样层输出图像的PHOG 特征。首先将下采样层输出图像,通过上节提到的PHOG 方法提取特征。但是,得到的PHOG 特征与传统方法是不一样的,因为该直方图具有主方向,它的主方向便是下采样层稀疏化时最大响应值方向,类比Lowe等[5]的SIFT 特征描述子思想可以得到结论,采用带有主方向的PHOG 描述子同样具备很好的旋转不变性,从而将训练所得的字典用于识别时更具有鲁棒性。若是训练阶段则选取一定数量的图像的PHOG 特征,存储起来作为字典;测试阶段,则把提取的测试特征与存储字典求取直方图交叉。直方图交叉算法被Cheng 等[10]用于行人的识别,取得了非常好的结果。通过计算相应图像直方图的交叉部分,用来衡量图像的匹配率,这可以被认为是直方图之间的相似性度量,直方图交叉值越大,则相似度越高。假设两幅图像的直方图以HX和HY来表示,它们均有K 个bin,第i(i=0,1,…,K)个bin的响应值可以表示为hxi与hyi,则直方图交叉的数学表示为

特征形成层旨在对抽取的PHOG 特征与字典元素进行匹配,即求取直方图交叉的最大值,找寻与所存储的最相似的直方图,用找到的相似字典元素线性组合表示当前抽取的特征,以此作为最终形成的特征。该特征可以用来训练多类SVM 分类器,以完成目标识别和分类的任务

式中:HIP——在测试图像上获得的直方图与存储字典的直方图交叉,hIi,hPj——第i个测试图的直方图与字典的第j个元素,M 是字典元素的总个数。
4 实验及结论分析
4.1 选用数据库和实验环境
为了检验所提出模型对目标识别的有效性,选用Caltech101数据库进行实验。该数据库由美国加州理工大学开发完成,其中有Car、Motorbike、Face和各种背景图等多类图像,是图像识别领域上的经典数据库。通过在CPU频率为2GHZ、内存1.0G 的电脑上编写Matlab2010 程序进行仿真,Gabor滤波器参数设置σ=0.7,γ=0.6。将特征形成层得到的特征输入到多类SVM 分类器进行训练分类,得到在3类实验图的识别率,从而对所提出的模型实现论证。图5列出了所选择的实验数据库中部分图像。图6是列举的4类部分图像抽取到的PHOG 特征。

图5 实验数据库中的部分图像
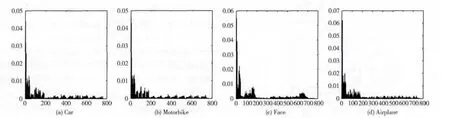
图6 4类部分图像抽取到的PHOG 特征
4.2 识别率的比较
为了得到一个比较合适的分层梯度方向直方图的层数和bin数,预先选用数据库中的几类图像进行试验。通过不同的分层数实验,得到图7所示的PHOG 分层数——识别率曲线。从曲线中可以看出:当所分的层数是3层时得到的识别率结果最好。对于金字塔梯度方向直方图PHOG而言,不是分层数越多结果越好。当分层数太少时,形状空间分布信息不能够有效的表达;当分层数太多时,整幅图像都被分成小块,块与块之间的差异被严重削弱,形状信息就会很弱。在本文后续实验中,都采用3 层的结构。图8是在计算PHOG 时所选用的不同bin数对4类图像平均识别率的影响曲线。通过实验发现,在选取bin=9时的效果是最好的。这是因为,bin的选取涉及到了一个类间与类内特征的平衡问题。在bin的数量比较少时,梯度方向量化等级少,类与类之间的区分度不够,识别效果当然不会太好;当bin达到某个值时,根据图8得出,本文在7~9附近,类间与类内特征实现了均衡,使得识别率最高,也就是说此时既能够保证同类之间的聚合,又能够实现不同类之间的区分;继续增大bin数则使梯度方向量化等级太多,使得同类的特征聚合度很差,无法实现同类之间的聚合,这样肯定会降低识别率。
分类器的选择对目标识别的成功与否至关重要,作为一种经典识别分类方法,SVM 对高维线性数据分类具有很好的效果,因此本文选用多类SVM 作分类器。表1是本文算法在Caltech 数据库中的Car、Motorbikes和Faces这3类图像中实验得到的混淆矩阵。

图7 PHOG 层数—识别率曲线

图8 bin数量—识别率曲线
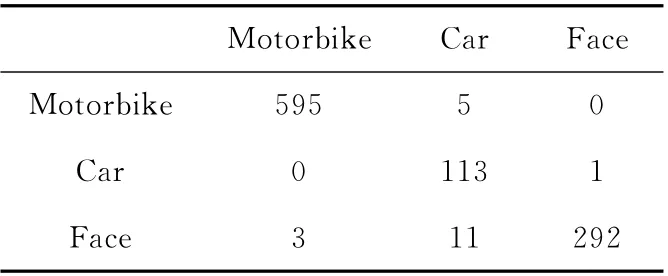
表1 实验图像所得混淆矩阵
将本文算法与文献 [11]所使用的方法作为基准Benchmark,文献 [12]中Serre 在Caltech 数据库中所使用的SMF特征分类以及文献 [6]提出的基于视觉机制的PHOG 特征识别方法相比较。计算混淆矩阵中正确识别的数量比率,得到了如表2所示的不同类识别率,并绘制比较算法的虚警率—检测率曲线 (ROC)如图9 所示。通过表2和ROC曲线可以看出:本文所提出的识别方法较其它3类方法都要好。从识别率统计表看,不仅整体的平均识别率得到了提高,而且单个类的识别率也有比较大的改善;对比ROC曲线可以明显看出,本文算法曲线下面积是最大的,同样在虚警率比较小的情况下,检测率便已经达到很高的值。需要说明的是,与其它算法相比,本文所使用的训练图像少得多,只占到了测试图像的1/10。分析原因是本文算法避免了抽取大量碎片集作为特征描述的不足之处,而是采用梯度方向直方图对边缘特征进行了有效的描述,既建立了合适的训练字典,又大大的减少了计算量,Gabor滤波器和max-like机制的全局及局部最大化操作保证了尺度缩放的不变性;此外,带有主方向的PHOG 直方图使目标识别更具有旋转不变性,从而使文章算法更具有鲁棒性。
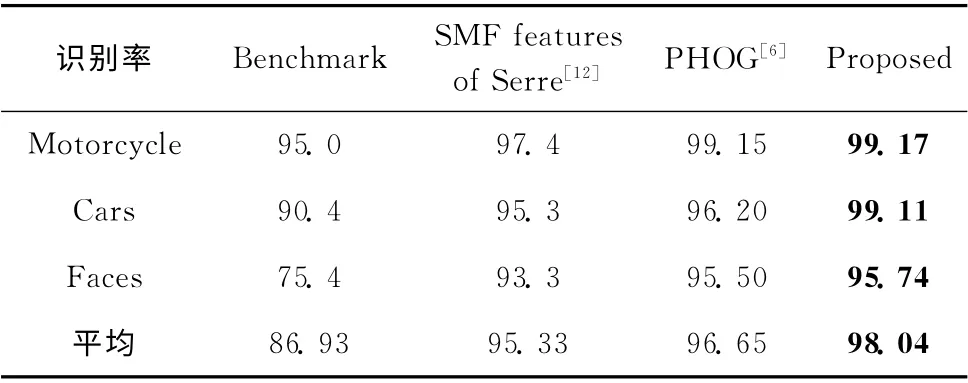
表2 识别率统计比较

图9 本文算法和对比算法ROC曲线
5 结束语
针对传统方法在目标识别、特征提取上的不足,从仿生学角度和工程应用出发,提出了一种仿人脑视皮层的目标识别新模型。①用卷积神经网络的卷积层和下采样层分别模拟初级皮层简单、复杂细胞,该方法克服了传统识别方法人工标定特征的不足,这与人脑识别是一致的;②以PHOG 作为特征描述子,对全局特征和局部特征分布可以很好的描述,同时赋予PHOG 一个主方向,使得该描述子具有比较好的旋转不变性;③充分考虑到人类视觉信息的稀疏性,运用max-like机制简化了特征并能够大大减小计算量,并借鉴压缩感知及稀疏表示的思想,建立了图像目标特征库。
[1]Robinson E Pino,Michael Moore,Jason Rogers,et al.A columnar V1/V2visual cortex model and emulation using a PS3 Cell-BE array [C]//The International Joint Conference on Neural Networks,2011:1667-1674.
[2]Ciresan D,Ueli Meier,Juergen Schmidhuber.Multicolumn deep neural networks for image classification [C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2012:3642-3649.
[3]Qiao Hong,Li Yinlin,Tang Tang,et al.Introducing memory and association mechanism into a biologically inspired visual model[J].IEEE Transactions on Cybernetics,2013,44(9):1485-1496.
[4]Mutch J,Lowe D G.Object class recognition and localization using sparse features with limited receptive fields[J].International Journal of Computer Vision,2008,80 (1):45-57.
[5]Muja M,Lowe D G.Fast matching of binary features[C]//Ninth Conference on Computer and Robot Vision,2012:404-410.
[6]Duraid Abdullah,Iqbal Murtza,Asifullah Khan.Feature extraction and reduction strategy based on pyramid HOG and hierarchal exploitation of cortex like mechanisms [C]//16th International Multi Topic Conference,2013:160-165.
[7]Jia Cheng Ni,Yue Lei Xu.SAR automatic target recognition based on a visual cortical system [C]//International Congress on Image and Signal Processing,2013:778-787.
[8]Norbert Kruger,Peter Janssen,Sinan Kalkan,et al.Deep hierarchies in the primate visual cortex:What can we learn for computer vision [J].Pattern Analysis and Machine Intelligence,2013,35 (8):1847-1871.
[9]SHOU Tiande.Visual information processing mechanism of the brain [M].2nd ed.Hefei:Press of University of Science and Technology of China,2010:87-113 (in Chinese). [寿天德.视觉信息处理的脑机制 [M].2版.合肥:中国科学技术大学出版社,2010:87-113.]
[10]Cheng Y,Su S Z,Li S Z.Combine histogram intersection kernel with linear kernel for pedestrian classfication [C]//IET International Conference on Information Science and Control Engineering,2012:1-3.
[11]Huang Lihong,Chen Xiangan,Gao Zhiyong,et al.Human action recognition by imitating the simple cells of visual cortex[C]//International Conference on Intelligent Computation and Bio-Medical Instrumentation,2011:313-320.
[12]Kuehne H,Jhuang H,Garrote E,et al.HMDB:A large video database for human motion recognition [C]//International Conference on Intelligent Computation and Bio-Medical Instrumentation,2011:2556-2563.
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
铁道建筑(2021年11期)2021-03-14 10:01:48
中国现代医药杂志(2020年3期)2020-05-08 04:33:08
中国生物医学工程学报(2019年6期)2019-07-16 07:52:48
科技风(2019年13期)2019-06-11 15:48:29
现代电子技术(2018年12期)2018-06-12 06:41:20
中外医疗(2016年15期)2016-12-01 04:25:39
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
数字技术与应用(2016年6期)2016-07-09 08:06:51
