
基于RGB-D的在线多示例学习目标跟踪算法
2015-12-23 00:53高毅鹏曾宪华
计算机工程与设计 2015年7期
高毅鹏,郑 彬,曾宪华
(1.重庆邮电大学 计算机科学与技术学院,重庆400065;2.中国科学院 重庆绿色智能技术研究院,重庆400714)
0 引 言
近年来一种称为 “tracking-by-detection”的方法受到了广泛关注,该算法通过建立在线更新分类器实现目标跟踪,其关键在于将序列图像中的前景目标从背景中分割出来,将跟踪视为一种特殊的二元分类问题[1]。例如,文献[2]中融入先验知识的在线Boosting跟踪算法;文献 [3]提出将跟踪、学习、P-N 检测进行整合以此来跟踪的框架的方法;文献 [4]提出一种半监督的在线增值学习算法,利用将第一帧的样本进行标记而其它样本不进行标记的方式来跟踪;文献 [5]提出一种实时压缩跟踪方法,它利用随机感知矩阵对图像特征进行降维,从而提高运算速度,但跟踪过程中尺度无法随目标尺度自适应改变,容易导致跟踪失败;MIL (在线多示例学习跟踪算法)利用多示例学习算法构建出一个鲁棒的跟踪框架然,但由于时间复杂度较大而难以实际应用[6];WMIL (在线加权多示例学习目标跟踪算法)赋予不同的正样本不用的权值,以此来加快特征选择提高算法的实时性,然而由于算法本身特征尺度单一又缺乏目标的3D 运动信息,因此,当目标外观模型的尺度,姿态变化和平面旋转时容易导致跟踪失败[7]。
微软深度传感器Kinect的出现为研究者提供了新的研究思路。在目前的跟踪领域已经有了一些开创性的工作[8-10],但是它们仅限于跟踪人体。针对上述基于2D 特征难以处理的问题和目前融合3D 信息的目标跟踪算法的局限性,本文在WMIL[7]框架下,提出一种基于RGB-D 的在线多示例学习目标跟踪算法。该算法首先利用深度信息的优势和Haar-like特征的特点在深度图和彩色图中构建多尺度的Haar-D特征和Haar特征,然后利用多示例学习策略将多尺度的Haar-D特征和Haar特征融合。
1 基于RGB-D的在线多示例目标跟踪
深度图中的每一个像素值表示场景中某一点与摄像机之间的距离。距离摄像机近时,像素值较小。距离较远时,像素值较大根据深度图的像素值的这一特性和Haar特征的特点,本文算法分别在深度图中和彩色图中构建了多尺度特征空间。在文献 [9]中利用Comobo-HOD 进行行人检测,此方法是在深度图上计算HOD (深度梯度直方图)描述子,在彩色图的同一窗口上计算HOG 描述子。当HOG和HOD 描述子都经过分类后,进行信息融合来达到行人检测的目的。本文算法在上述多尺度特征空间中提取多尺度的Haar特征和多尺度的Haar-D 特征,然后利用多示例学习策略 (如图1所示)融合。
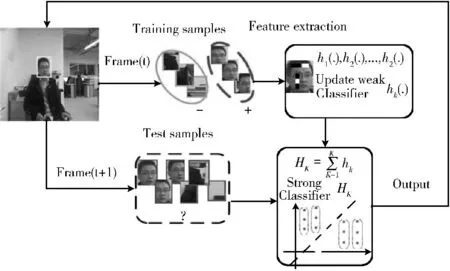
图1 多示例学习框架
1.1 MIL框架
在如图1所示的MIL[10]框架下,定义标记样本x 是正样本的后验概率由贝叶斯理论可知为
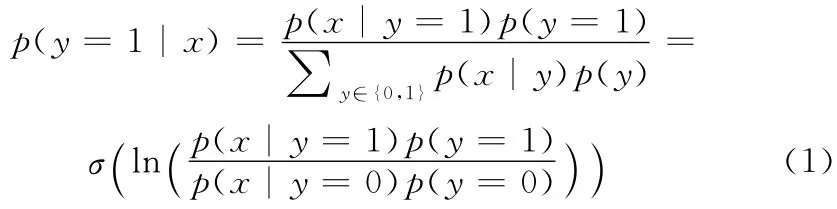
式中:x 为标记样本,y∈ {0,1}是标记样本x 的标签(0表示负样本1表示正样本),σ(z)=1/ (1+e-z)是S型线性回归拟合函数。
在MIL中分类器HK(x)定义为
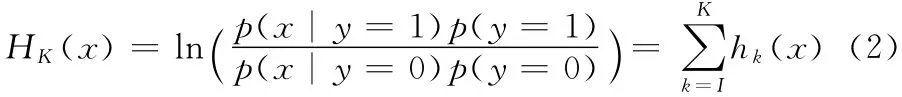
因此由式 (1)可知标记样本的后验概率为
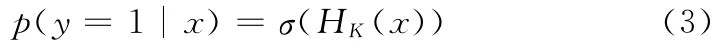
样本由特征向量f(x)= (f1(x),…,fK(x))T表示。我们假设在f (x)中的特征是独立同分布的,而且先验概率p(y=1)=p(y=0)。则式 (2)中的强分类器可由特征向量f(.)表述为
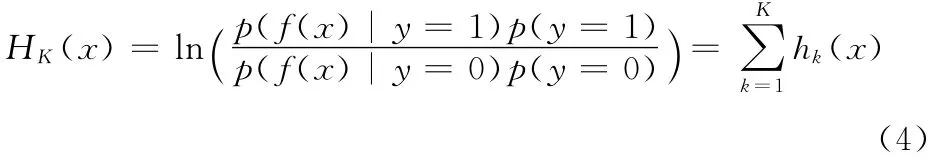
其中
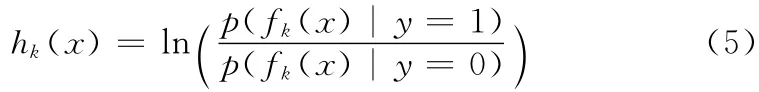
式 (5)是判别函数,hk(x)表示一个弱分类器。从以上过程可以看出MIL算法的核心就是如何设计一个合适判别分类器Hk(.)。在文献 [3,11]中是在线特征的选择的方式创建分类器。下文将详细介绍WMIL[7]特征选择创建分类器和本文算法是如何创建分类器Hk(.)的。
1.2 在线WMIL特征选择
WMIL中的判别分类器实质是一个实例分类器,跟实例的条件概率有关。由式 (1),式 (2)可知样本实例xij的概率为pij=σ (HK(xij)),i为样本包索引,j为样本实例索引。HK(.)=∑Kk=1hk(.),式 (5)中hk(.)关联一个Haar-like特征fk(.)的弱分类器。在弱分类器hk(.)中的条件概率分布模型服从高斯分布
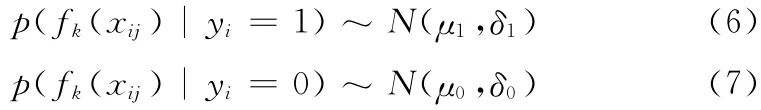
我们利用极大似然估计的知识更新μ1 和δ1
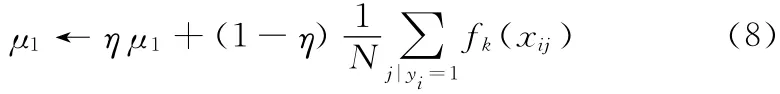
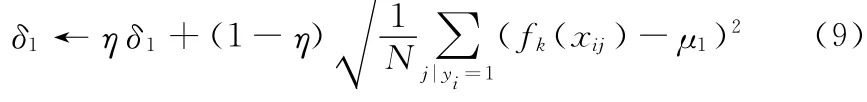
N 是正样本的个数,η是学习系数。更新μ0 和δ0的方法类似。同时定义 {X+,X-}两个样本包的概率如下
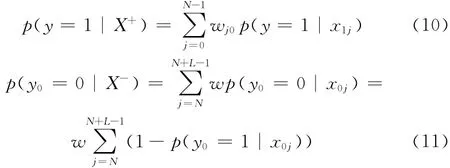
wj0为实例样本的权值,是一个与实例样本位置跟目标位置之间的欧氏距离相关的递减函数
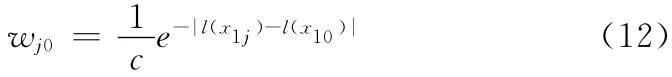
由此可见距离目标越近权值越大。w 是式 (11)中负样本包的加权值,由于负样本包距离目标较远,因此设样本包权值为一相同的定值。
与MIL中跟踪的方法类似在WMIL中是首先构建一个包含M 个弱分类器的分类器池Φ= {h1,...,hM},然后利用贪心策略从分类器池Φ中选择K 个弱分类器按照类似于MIL的方法如下进行迭代
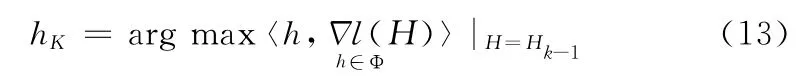
1.3 基于RGB-D的在线多示例特征选择
1.3.1 多尺度特征空间
深度图的像素值代表的是深度传感器到目标的距离,距离传感器越近图像的分辨率就越高,然而根据上文可知深度图的像素值越小。本文算法根据深度图中像素值与深度传感器到目标的距离、分辨率之间的关系构造出多尺度特征空间来解决尺度问题。
首先,在第t帧时求得跟踪标框重心,并计算出此重心到传感器的距离为d1。由于相邻两帧之间的跟踪框重心到传感器的距离变换较小。因此采用每3帧进行处理的方式。因此当在第t+3帧时,计算出跟踪框重心到传感器的距离为d3,我们可求得尺度缩放因子为

在CT[5]算法中我们可知,高维边缘型的Haar特征相当于高斯滤波器。高斯核实唯一可构建出多尺度空间的核。本文算法在彩色图中每一个搜索区域内利用当前尺度s=1、较小尺度s=1-φ、较大尺度s=1+φ,由如图2所示尺度变换提取Haar边缘型特征从而构建出多尺度特征空间。然后分别在深度图深度图中采用上述方式得到多尺度空间。

图2 尺度变换
1.3.2 RGB-D特征融合
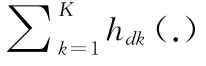
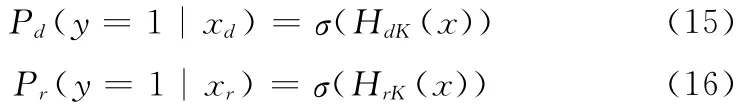
xdepth,xrgb分别为在彩色图和深度图中的标记样本实例,y∈{0,1}是标记样本实例的标签,σ(Z)=1/ (1+e-Z)是S型线性回归拟合函数,HrK(.),HdK(.)分别为在彩色图和深度图中的分类器。然后让分类器中的条件概率p(fk(.)|y=0)和p (fk(.)|y=1)服从如式 (6),式(7)所示的正态分布。利用极大似然估计的方式更新分类器参数 {μd1,δd1,μr1,δr1}

式中: {μd1,δd1}为正样本在深度图中的均值和方差,{μr1,δr1}为正样本在彩色图中的均值和方差。η是学习系数,更新 {μd0,δd0,μr0,δr0}的方法类似。本文算法根据式 (15),式 (16)可得在深度图上的正负样本包的概率{Pd1,Pd0}和在彩色图上的正负样本包概率 {Pr1,Pr0}。利用式 (19)所示的滤波器的形式将来自Haar-D 正样本包的后验概率Pd1和Haar-like正样本包的后验概率Pr1进行融合
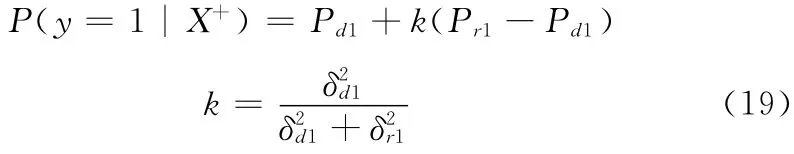
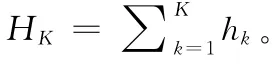
2 算法实现
跟踪算法步骤如下:
步骤1 在第t帧手工选取跟踪目标,根据式 (14)由d1、d3计算出尺度因子φ,然后构建多尺度特征空间 (初始给定尺度缩放因子φ0 构建尺度空间),并计算目标框重心到传感器的距离d1。
步骤2 利用上文所述WMIL 中的方法分别在深度图和彩色图中生成正、负样本包。然后利用上述生成的多尺度空间在彩色图中计算多尺度Haar特征,在同一窗口的深度图中计算多尺度Haar-D特征。
步骤3 根据式 (17),式 (18)分别在深度图中和彩色图中更新分类器参数。根据式 (6),式 (7)计算弱分类器hk(.)中的条件概率分布模型p(fk(.)|y=0)和p(fk(.)|y=1)的后验概率。
步骤4 根据式 (4),式 (5)计算出分类器H rK(.),HdK(.),然后根据式 (10),式 (11),式 (15),式 (16)计算出样本包的后验概率Pd、Pr。

步骤6 在第t+1帧,(每3帧处理一次,计算第t+3帧时跟踪框的重心到传感器的距离d3)我们将在深度图和彩色图中以半径γ范围内的样本Xγ= {x |作为测试样本集。然后计算Haar特征和Haar-D特征。
步骤7 我们利用上一帧训练好的分类器HK(.)将这些测试样本分类,利用非极大值抑制的方法找到置信度最大的样本x*,此时样本x*所在的位置就是目标在第t+1帧中所在的位置。返回步骤1,直到跟踪结束。
3 实验结果与分析
为了评估本文算法的实时性和鲁棒性以及对于遮挡处理的能力。本文算法用MATLAB 语言实现,在一台AMD 3.10GHz CPU 和4GB RAM 的PC机上面进行测试。我们用Kinect深度传感器采集包含姿态变化、背景杂波、严重遮挡和平面旋转等3个视频序列来评估本文算法。还将本文算法与另外3 个稳定,实时的目标跟踪算法 (real-time compressive tracker (CT)[5],real-time object tracking via online discriminative feature selection (OFDS)[13],online weighted multiple instance learning (WMIL)[7])进行了比较。对比结果如下文所示。
3.1 实验参数设置和评估标准
确定当前帧目标的位置,以α=4~8为半径的范围内生成45~190个正样本作为正样本包。在半径为ζ=2α与半径为β=38半径的范围内生成负样本,为了避免正负样本之间的二义性,本文算法实验过程中ζ=2α。当下一帧到来时,我们以γ=β/1.5 为半径的范围内生成2000 个测试样本。针对不同的序列所选择的γ值是不相同的。将特征池中候选特征的个数M 设置为150~180,从中选择15个特征,在将学习参数设置为η=0.78~0.93 之间情况下。经实验验证可知较小的学习参数可以适应较快的表面变化,而较大的学习参数可以减少目标的漂移且能达到实时跟踪的要求 (见表1)实时性FPS利用平均每秒跑的帧数来衡量。在本文算法实验过程中最佳值为0.92。
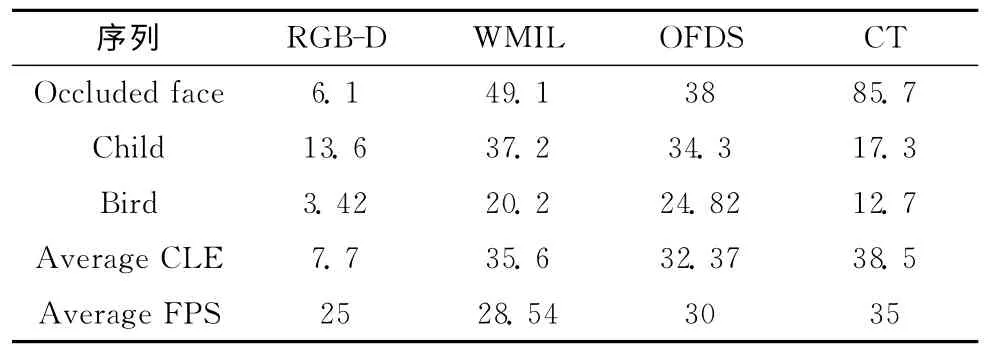
表1 中心定位误差和实时性/Pixels
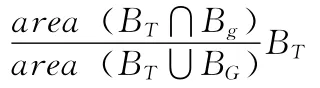
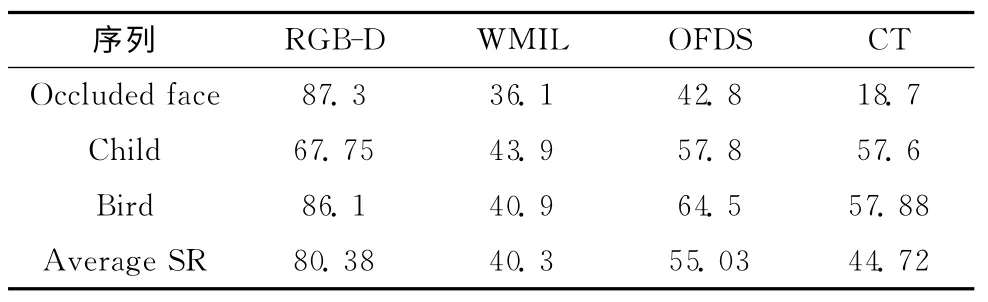
表2 算法的成功率 (SR/%)
3.2 实验结果
3.2.1 遮挡和姿态变化
为了体现本文算法对于处理遮挡和姿态问题的优越性,我们用自己采集的类似于经典的Occluded face 2,Woman系列的视频序列进行验证。在图3Occluded face视频序列中,目标在部分遮挡 (See frame#93,#206,#241)的情况下,由图4中心定位误差所示,CT 算法、WMIL 算法和OFDS算法处理遮挡的能力不是很好,RGB-D 算法却能处理的很好。而且在后续完全遮挡部分 (See frame#270,#355,#370)完全显示了RGB-D 算法对于遮挡处理的优越性。

图3 Occluded face视频序列的跟踪结果
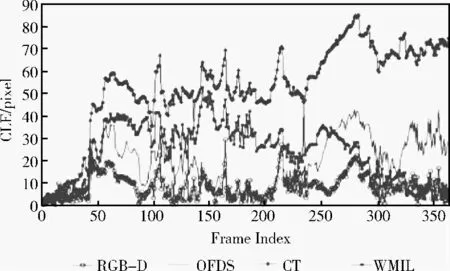
图4 Occluded face跟踪结果的中心定位误差
3.2.2 姿态,平面旋转,背景杂波
由于计算RGB-D数据进行目标跟踪,在图5 (a)child视频序列的#79、#162 看出目标在表面姿态发生变化和平面旋转时,CT、WMIL、OFDS 跟踪效果不佳。Struck算法在处理表面姿态变化和平面旋转时算法性能优于CT、WMIL、OFDS算法,而在图5 (b)bird视频序列中的#61、#132、#154存在相似背景和部分遮挡时,CT,WMIL 算法的跟踪框会发生漂移,但本文算法和OFDS算法表现较好。图6、图7的跟踪结果中心定位误差看出本文算法在处理平面旋转,姿态变化和背景杂波等问题时鲁棒性较好。

图5 child,bird视频序列的跟踪结果
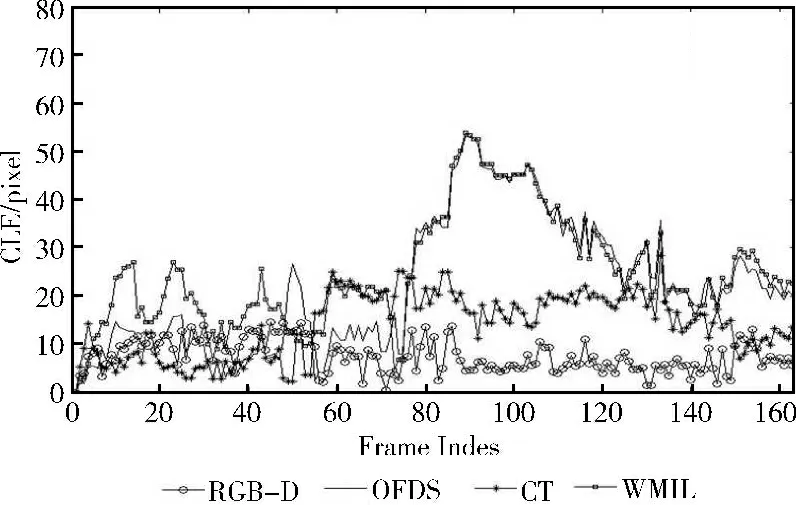
图6 Child跟踪结果的中心定位误差
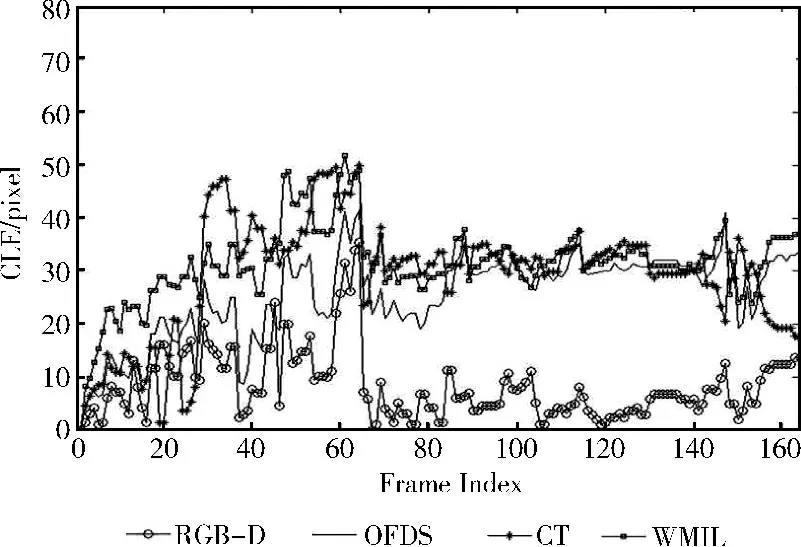
图7 Bird跟踪结果的中心定位误差
4 结束语
本文应用多示例学习框架,结合RGB-D 数据的优势。提出基于RGB-D的多示例目标跟踪算法。充分利用深度数据的优势,将在深度图中训练的贝叶斯分类器和在彩色图中训练的贝叶斯分类器进行融合的方式来跟踪目标。本文算法融合3D 信息可解决由于目标姿态变化和平面旋转时引起的尺度问题。在跟踪过程中,该算法本文算法根据深度图中像素值与深度传感器到目标的距离、分辨率之间的关系构造出多尺度特征空间来解决目标框大小发生变化时引起的尺度问题。
[1]Yi Wu,Jongwoo Lim, Ming-Hsuan Yang.Online object tracking:A benchmark [C]//Conference on Computer Vision and Pattern Recognition,2013.
[2]CHENG Youlong,LI Bin,ZHANG Wencong.An adaptive pedestrian tracking algorithm with prior knowledge[J].Pattern Recognition and Artificial Intelligence,2009,22 (5):704-708(in Chinese).[程有龙,李斌,张文聪.融合先验知识的自适应行人跟踪算法 [J].模式识别与人工智能,2009,22 (5):704-708.]
[3]Kalal Z,Mikolajczyk K,Matas J.Tracking-learning-detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34 (7):1409-1422.
[4]Grabner H,Leistnerand C,Bischof H.Semi-supervised online boosting for robust tracking [C]//European Conference on Computer Vision,2008.
[5]ZHANG KH,ZHANG L,YANG MH.Real-time compressive tracking [C]//European Conference on Computer Vision,2012.
[6]Babenko B,YANG M,Belongie S.Robust object tracking with online multiple instance learning [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33 (8):1619-1632.
[7]ZHANG KH,SONG HH.Real-time visual tracking via online weighted multiple instance learning [J].Pattern Recognition,2013,46 (1):397-411.
[8]Luber M,Spinell L,Arras K O.People tracking in RGB-d data with on-line boosted target models[C]//International Conference on Intelligent Robots and Systems.IEEE Conference Publications,2011:3844-3849.
[9]Spinell L,Arras KO.People detection in RGB-d data [C]//International Conference on Intelligent Robots and Systems.IEEE Conference publications,2011:3838-3843.
[10]Spinell L,Luber M,Arras KO.Tracking people in 3Dusing a bottom-up top-down detector [C]//International Conference on Robots and Automation IEEE Conference Publications,2011:1304-1310.
[11]Grabner H,Leistner C,H,Bischof H.Semi-supervised online boosting for robust tracking [C].European Conference on Computer Vision,2008:234-247.
[12]ZHU Qiuping,YAN Jia,ZHANG Hu,et al.Real-time tracking using multiple features based on compressive sensing[J].Opt Precision Eng,2013,21 (2):438-444 (in Chinese).[朱秋平,颜佳,张虎,等.基于压缩感知的多特征实时跟踪 [J].光学精密工程,2013,21 (2):438-444.]
[13]ZHANG KH,ZHANG L,YANG MH.Real-time object tracking via online discriminative feature selection [J].IEEE Transactions on Image Processing,2013,22 (12):4664-4677.
猜你喜欢
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
计算机应用(2019年3期)2019-07-31
山东冶金(2019年1期)2019-03-30
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
软件导刊(2016年9期)2016-11-07
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
科技视界(2016年2期)2016-03-30
电测与仪表(2014年15期)2014-04-04
