
基于复合权值自调整策略的量子粒子群优化算法
2015-12-20 06:54宋益春
计算机工程与设计 2015年9期
宋益春,毛 力
(江南大学 物联网工程学院 轻工过程先进控制教育部重点实验室,江苏 无锡214122)
0 引 言
有研究结果表明,运用Solis 和Wets 对粒子群优化(PSO)算法进行关于随机性算法的收敛性准则理论分析后,发现其无法保证算法全局收敛性和局部收敛性的结论。PSO 算法虽然具有设计简单、易实现、参数少等诸多优点,但也存在着收敛速度慢、精度差等问题[1,2]。
在Clerc等关于粒子收敛性行为研究的基础上,Sun等融合量子力学的思想,提出了一种粒子进化模型,即量子粒子群优化 (QPSO)算法[3,4],该算法认为δ 势阱中粒子向势阱中心移动的过程符合粒子搜索寻优的机理,具备量子行为的粒子的搜索范围扩大至整个可行解区域,移动时不再受速度和方向的束缚,因此它的全局搜索性远好于一般的PSO 算法。近年来,QPSO 算法在函数优化、神经网络、多目标优化、聚类分析等领域得到较多的应用[5-8]。
收缩-扩张系数β 是能够调节QPSO 算法的收敛过程,平衡全局搜索和局部搜索能力,因而是算法控制收敛的一个重要参数。QPSO 算法采用收缩-扩张系数线性递减的策略[4],使得β的变化符合粒子群的总体运行方向,但在具体运行过程中没有独立于粒子群的实际状况,影响了收敛速度和收敛精度。基于进化速度-聚集度的动态改变权值策略[9]的量子粒子群 (dynamically changing weight QPSO,DCWQPSO)提出动态改变权值策略中,β的变化依赖于粒子群的进化速度与聚集度的改变,本质上不能避开粒子低效或者失效的情形,陷入局部极小值点,加之采用这策略的QPSO 本身逃逸能力很弱,导致全局搜索能力减弱,收敛精度大打折扣。
对此,本文提出了一种基于复合权值自调整策略的量子粒子群优化算法 (quantum-behaved particle swarm optimization algorithm based on the adaptive strategy of composite weight,ACWQPSO)。此算法采用复合典型线性递减策略与基于进化速度-聚集度的动态改变权值策略的方法调节收缩-扩张系数β,由此β的改变不但与迭代次数相关联,而且受算法实际运行的种群集聚态势的影响,从而可以根据运行的实际情况调整β,有效地平衡全局搜索和局部搜索,进而改善算法的性能。通过5个基准测试函数对收敛性和算法性能进行了分析。实验结果表明,ACWQPSO 算法在寻优过程中提高了收敛精度,对大部分优化函数都能找到较好的解。
1 量子粒子群优化算法
假设在一个n 维的目标搜索空间中,粒子群中第个个体在第k次迭代中,位置为向量=,…)∈Rn。第个粒子自身迄今搜索到的最优适应度值位置,记为个体最优极值位置=(,,…,);整个粒子群迄今搜索到的最优适应度值位置,记为全局最优极值位置=(,,…,)。粒子在每一次迭代中追踪这两个最优极值位置来完成位置的更新。
Clerc等对PSO 算法中的粒子运动轨迹的研究[10]表明,每个粒子必须收敛于他们各自的局部吸引子qi
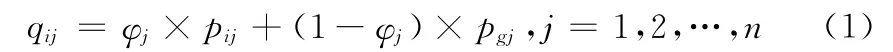
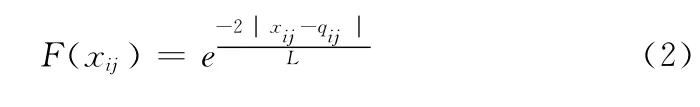
式中:L——δ势阱的特征长度,决定着粒子搜索的范围。
使用蒙特卡罗随机模拟的方式可获得粒子的位置更新方程

式中:u—— (0,1)之间符合均匀分布的随机数。L 的控制方法对QPSO 的收敛速度和性能有关键性的影响,通常采用的是文献 [3]中提出的平均最好位置 (mbestk),即所有粒子群个体最好位置的平均
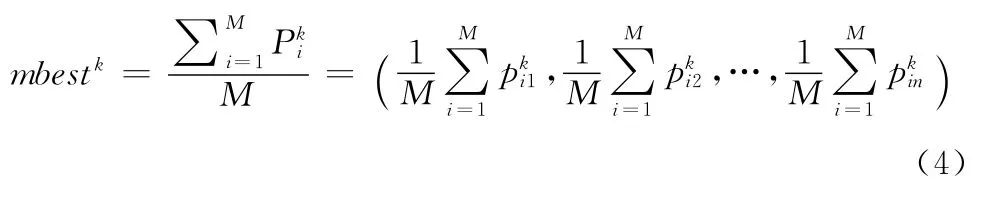
式中:M ——粒子群的种群规模。
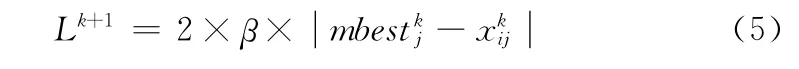
最终式 (3)被定义为

式中:β——QPSO 算法的收缩-扩张系数,用于控制粒子的收敛速度,是除了迭代次数和种群规模之外的唯一参数。
2 权值β的选择策略
文献 [4]仿真实验结果表明,在QPSO 算法中,当β<1.782时,单个粒子可以收敛到吸引子,算法的收敛性能得到保证。从式 (6)中可以看出,在算法迭代初期,较大的β,算法的收敛速度较快,可以取得较好的全局寻优效果;在算法迭代后期,较小的β,算法的收敛精度较高,可以取得较好的局部寻优效果。对参数β控制通常可以采用固定取值、线性递减和非线性递减等方式,但文献 [11]通过实验得出,固定取值策略的鲁棒性较差,而线性递减和非线性递减两种惯性权值策略则体现了求解相对稳定的特点。因此,本文尝试把这两种策略相融合的方法来确定收缩-扩张系数β。
2.1 线性递减权值策略
目前对β 的改进策略使用最为普遍的是文献 [3,4]中提出线性递减的策略,表示为
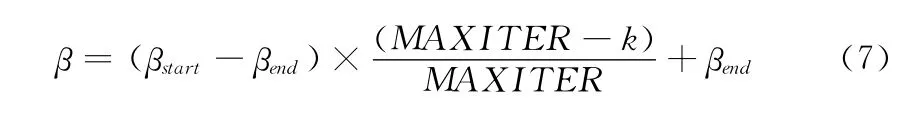
如果在全局寻优能力较强的迭代初期没有搜索到较优的点,由于搜索空间的缩小不是线性递减而是高度复杂的,所以这种简单的线性递减β,容易使算法陷入局部最优,出现所谓的早熟收敛现象,在一定程度上会影响算法的收敛速度和寻优精度。
2.2 基于进化速度-聚集度的动态改变权值策略
算法运行过程中,QPSO 的收缩-扩张系数β的变化根据粒子群的进化速度和聚集度实时进行调整,从而更加有效地搜索最优解。
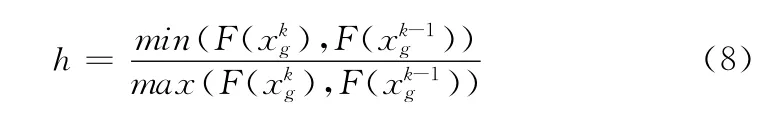
由式 (8)可知0<h≤1。h 的值越小,进化速度就越快。h的值保持为1,则可判断算法找到了问题的最优值。设Favg是当前所有粒子适应度值的平均值,则

引入聚集度因子s的定义如下
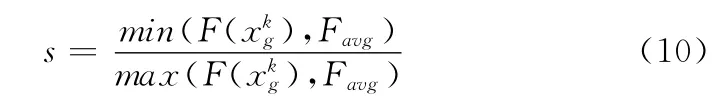
0<s≤1,s反映了粒子的聚集程度和一定程度上的种群多样性,s的值增大,表明粒子的聚集程度也提高,同时粒子的多样性降低。当s的值为1时,全部粒子具有同样的特征,此时算法陷入局部最优的状态。
基于这样的论述,可以把β表示成关于进化速度因子h和聚集度因子s的函数β =f(h,s),即
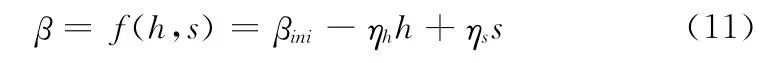
2.3 复合权值自调整策略
2.3.1 复合权值调整策略的参数
线性递减权重的策略,β 的数值只与迭代次数k 有关,虽没有很好地匹配算法运行过程中搜索空间非线性变化的特点,但是能够符合粒子群整体运动的趋势;动态改变权重的策略中,虽契合粒子群当前的变化态势,但也存在一旦种群粒子出现低效或失效的情形,就难以避开陷入局部极小的困境,因而此时的β不能准确地反映粒子群的实际状态变化。综合考虑,本文引入权重参数λ,提出了用典型的线性递减策略和动态改变策略相复合的方法来确定收缩-扩张因子β的量子粒子群优化算法
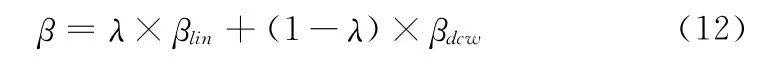
通过对λ值的调整来控制线性递减策略和进化速度-聚集度的动态改变策略对每一代收缩-扩张因子β的影响程度λ 作为平衡线性权重和动态权重改变的核心参数,它的取值将直接影响到算法的收敛效率。过大的取值将使得混合权重调整策略退化成权值线性递减策略,算法寻优性能欠佳;过小的取值又将混合权重调整策略改变成动态调整策略,丧失了一般性。
本文使用黄金分割的比例来确定λ,即λ =0.618。本文算法以线性递减策略为主、动态改变权值策略为辅的复合权值,既保证了算法能够以线性递减策略跟随粒子群整体运行趋势,又避免了过度使用动态改变策略带来的粒子低效或失效导致收敛精度低的问题。
2.3.2 ACWQPSO 算法执行流程
步骤1 设置种群规模为M,寻优维数为n,最大进化代数MAXITER,h=0,s=0,随机初始化粒子群个体位置;
步骤2 根据目标函数计算出每个粒子的适度值;
步骤3 比较每个粒子的适度值和个体极值,若较优则更新当前个体极值;
步骤4 比较每个粒子的适度值和全局极值,若较优则更新当前全局极值;
步骤5 使用式 (4)计算得到粒子群的平均最优位置;
步骤6 对于粒子的每一维,使用式(1)计算得到一个随机点的位置,使用式(6)计算得到下一代粒子的位置;
步骤7 根据式 (7)计算出βlin;根据式 (8)、式 (9)、式 (10)、式 (11)计算出βdcw;再根据式 (12)计算出β;
步骤8 重复步骤2~步骤7,直到当前迭代的次数达到预先设定的最大次数,输出粒子最佳位置,算法结束。
3 仿真实验及效果评价
本实验采用表1中5个常用的基准测试函数,这些函数包括了单峰非独立 (Schwefel)、多峰独立 (Rastrigin)、多峰非独立 (Rosenbrock、Griewank、Ackley)3种类型。

表1 全局优化的测试函数
现使用3种不同权值策略的QPSO 算法分别对表1中所列的函数分别进行20次实验,测试函数的维数为30。算法中参数设置:采用线性递减策略的标准QPSO[4]中,βstart=1.0,βend =0.5;基于进化速度-聚集度的动态改变权值策略的DCWQPSO[9]中,βini =1,ηh =0.5,ηs =0.2。最大进化次数均取MAXITER =1000,种群规模均取M =120。经过用Rosenbrock、Rastrigrin和Griewank等典型测试函数测试发现:λ∈(0.6,0.8)时,算法的整体性能较优。
实验中每种算法对每个测试函数优化所得的平均值、标准差、最优值,见表2。

表2 3种不同权值策略的QPSO 优化结果比较
表2中对Griewank的寻优结果为0,理论上结果不为0;产生这种结果的原因是在MATLAB2009 的仿真环境下,当某个数小于1.0e-324时,输出结果就为0。
对于表1 中的所有测试函数,表2 的实验结果表明ACWQPSO 算法寻优的平均值和最好值比其它权值策略的算法跟接近最优值,在算法收敛精度上有一定的提高,标准差反映算法在寻优过程中表现出较强的稳定性。
为了比较这几种算法的收敛速度,绘制以横坐标为进化代数,纵坐标为20次实验的每代的平均最优值的对数的收敛曲线图,如图1~图5所示。
由图1~图5的进化曲线中很直观地看出,算法初期,对比标准QPSO,ACWQPSO 和DCWQPSO 粒子均表现出更快的收敛速度,其中ACWQPSO 的收敛速度稍逊于DCWQPSO,这是因为DCWQPSO 算法初期能够很好地契合了粒子群运动的方向。但也正是因为收敛速度过快,粒子在局部寻优性能上表现不足,陷入早熟的困境,所以在算法运行的迭代后期,ACWQPSO 的收敛精度上超过DCWQPSO。

图1 f1 Rosenbrock函数寻优曲线对比

图2 f2 Rastrigin函数寻优曲线对比
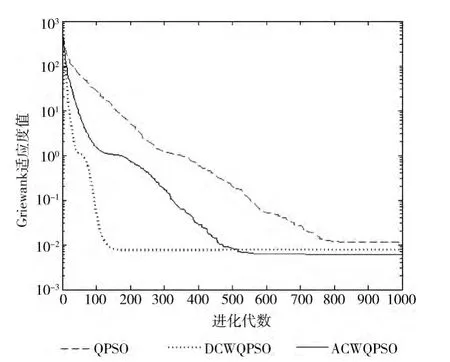
图3 f3 Griewank函数寻优曲线对比
特别在图2中,Rastrigin函数具有大量按正弦拐点排列的局部极小点,对优化算法来说是一个极难优化的函数。优化过程中,标准QPSO 和DCWQPSO 都出现了失效状态,即二者都无法找到全局最优值。DCWQPSO 优化效果次于标准QPSO,表明仅仅使用动态改变权值策略QPSO跳出局部最优值的能力次于标准线性递减策略QPSO。但两种策略复合后的ACWQPSO,寻优精度有了一定的提高,比单纯的DCWQPSO 好。
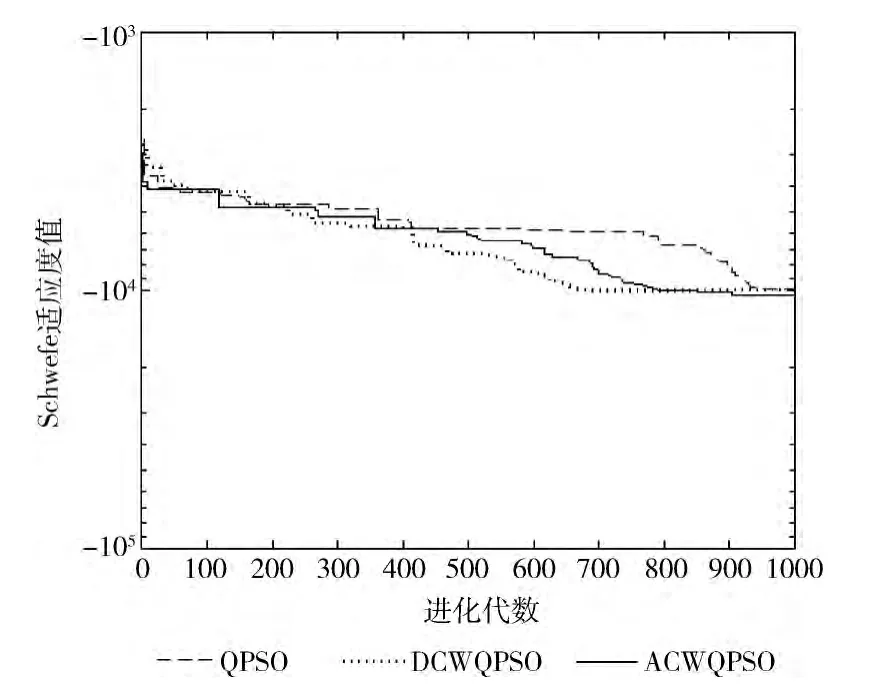
图4 f4Schwefel函数寻优曲线对比

图5 f5 Ackley函数寻优曲线对比
本文构造的复合权值,整合线性递减策略和动态改变权值策略,改善了种群的多样性,能够有效地均衡全局搜索和局部搜索能力,增进了算法的寻优性能,同时算法的收敛速度也有一定程度地提高。
4 结束语
本文针对QPSO 算法收敛速度缓慢及收敛精度低的问题,对算法收缩-扩张系数β进行了复合权值策略的改进,提出了基于复合权值自调整策略的量子粒子群优化算法。同时将该改进算法与其它两种权值策略的QPSO 对5个标准测试函数进行了数值实验。实验结果表明,复合权值策略能够适应QPSO 算法早期收敛速度快,尽快让算法进入局部搜索的要求,也能够有效地避免陷入局部最优值,提高了算法的收敛精度和稳定性,也说明了算法改进的可行性和有效性。利用本文提出的算法求解其它基准测试函数和解决工程实际问题是笔者下一步的研究方向。
[1]HUANG Shaorong.Survey of particle swarm optimization al-gorithm [J].Computer Engineer and Design,2009,30 (8):1977-1980 (in Chinese).[黄少荣.粒子群优化算法综述 [J].计算机工程与设计,2009,30 (8):1977-1980.]
[2]van den Bergh F.A new locally convergent particle swarm optimizer[C]//IEEE International Conference on Systems,Man and Cybernetics,2002.
[3]Sun J,Fang W,Palade V,et al.Quantum-behaved particle swarm optimization with Gaussian distributed local attractor point[J].Applied Mathematics and Computation,2011,218(7):3763-3775.
[4]SUN Jun.Research of quantum-behaved particle swarm optimization algorithm [D].Wuxi:Jiangnan University,2009 (in Chinese).[孙俊.量子行为粒子群优化算法研究 [D].无锡:江南大学,2009.]
[5]Ahmad Bagheri,Hamed Mohammadi Peyhani,Mohsen Akbari.Financial forecasting using ANFIS networks with quantum-behaved particle swarm optimization [J].Expert Systems with Applications,2014,41 (14):6235-6250.
[6]Omkar SN,Khandelwal R,Ananth TVS,et al.Quantum behaved particle swarm optimization(QPSO)for multi-objective design optimization of composite structures [J].Expert Systems with Applications,2009,36 (8):11312-11322.
[7]XU Min,XU Wenbo.Parameter estimation of complex function based on quantum-behaved particle swarm optimization algorithm [J].Computer Engineering and Design,2007,28(15):3665-3667 (in Chinese).[徐敏,须文波.基于量子粒子群算法的复杂函数参数估计 [J].计算机工程与设计,2007,28 (15):3665-3667.]
[8]Sun Jun.Gene expression data analysis with the clustering method based on an improved quantum-behaved particle swarm optimization [J].Engineering Applications of Artificial Intelligence,2012,25 (2),376-391.
[9]HUANG Zexia,YU Youhong,HUANG Decai.Quantum-behaved particle swarm algorithm with self-adapting adjustment of inertia weight [J].Journal of Shanghai Jiaotong University,2012,46 (2):228-232 (in Chinese).[黄泽霞,俞攸红,黄德才.惯性权自适应调整的量子粒子群优化算法 [J].上海交通大学学报,2012,46 (2):228-232.]
[10]TANG Jitao,DAI Yueming.Regional shock search embedded particle swarm optimization algorithm [J].Computer Engineering and Applications,2013,49 (21):33-36 (in Chinese).[汤继涛,戴月明.内嵌区域震荡搜索的粒子群优化算法 [J].计算机工程与应用,2013,49 (21):33-36.]
[11]FANG Wei,SUN Jun,XIE Zhenping,et al.Convergence analysis of quantum-behaved particle swarm optimization algorithm and study on its control parameter [J].Acta Physica Sinica,2010,59 (6):3686-3694 (in Chinese). [方伟,孙俊,谢振平,等.量子粒子群优化算法的收敛性分析及控制参数研究 [J].物理学报,2010,59 (6):3686-3694.]
猜你喜欢
数学物理学报(2022年4期)2022-08-22
成都信息工程大学学报(2022年3期)2022-07-21
数学物理学报(2022年2期)2022-04-26
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
计算机工程与设计(2020年4期)2020-04-23
金桥(2018年4期)2018-09-26
物联网技术(2017年5期)2017-06-03
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
上海理工大学学报(2016年2期)2016-06-02
