
火电企业配煤模型与优化算法
2015-12-20 06:58尉守科于俊清李石君
计算机工程与设计 2015年9期
李 彬,尉守科,于俊清,3,李石君+
(1.武汉大学 计算机学院,武汉 湖北430072;2.华中科技大学 计算机科学与技术学院,武汉 湖北430072;3.华中科技大学 网络与计算中心,武汉 湖北430072)
0 引 言
随着对混配煤研究[1-4]的不断开展发现,虽然混配比燃烧单煤更能提高锅炉效率,节约煤炭资源,减少对环境的污染,但是对单煤混配的研究还存在着不少问题。本文针对目前国内配煤模型研究中存在的问题,在深入分析与研究后,对当前的配煤优化模型与优化算法进行改进,实现一个配煤优化的应用系统。主要包括以下几个方面:①对比分析当前所具有一些的配煤模型,根据优劣性选取并建立一个火电企业实用型配煤优化模型;②配煤技术虽然存在,但是配煤理论不够深入。根据实验室项目中的燃料管理系统可以看出,各大火电企业并未形成一整套的配煤系统,虽已经开始应用配煤技术,但是缺乏一定的理论指导;③选取其它文献中已知数据以及本实验室合作项目的数据库中电厂配煤的历史数据,对改进的算法进行测试验证,更好地反馈算法的优劣性。
1 模型求解优化算法
在配煤生产过程中,产生了许多的配煤算法,如穷举法、遗传算法[5]、蚁群算法、粒子群算法[6,7]以及两种混合的算法。由于粒子群算法的高效性、精度高、收敛快、实现容易等优点,本文选取了粒子群算法作为配煤算法的主导算法,并对该算法进行了更深一步的优化。
1.1 标准粒子群算法
在最初的粒子群算法中,很难平衡粒子的局部搜索能力和全局搜索能力,就是粒子缺少对上一次的速度记忆性以及自身最好位置的影响、全局最好位置的影响所占权重的调整。粒子群优化算法首先随机产生所有粒子,通过迭代更新每一个粒子的位置、速度与个体最优适应值,然后通过比较更新全局最优位置与全局最优值,最终找到问题的最优解。
在第k次迭代时,某个粒子必须具有以下两个属性:
(1)位 置 向 量Xki=(xk1,…,xki,...,xkN),其 中xki∈[XMINi,XMAXi],1≤i≤N,XMINi和XMAXi是粒子在这一维上的左右限制;
(2)速度向量Vki=(vk1,…,vki,...,vkN),其中每个分量都不能超过指定的最大速度。
粒子群算法的每一次发生迭代时,整个群体中粒子位置和速度按照一定的方式进行更改,具体公式如下

式 (1)中,r1和r2是随机数;c1和c2被称作学习因子,通常c1=c2=2;wk是权重,常用的取值范围是0.1-1.2之间。wk也可以是变动的,经过验证,若权重值随着迭代次数线性减小,可以有效的提高算法的收敛性。Shi和Eberhart指出:当最大速度很小时 (例如小于2),使用接近于1的惯性权重;当最大速度不是特别小时 (例如大于3),使用权重w=0.8较好。如果没有给出最大速度,则选取0.8作为权重比较好。惯性权重w 比较小时粒子群算法的局部搜索能力比较强;惯性权重较大时将会偏重于发挥粒子群算法的全局搜索能力。
粒子群算法在迭代进行时,粒子速度的大小不能超出一定的范围,同样粒子位置的更新也要不超出指定的范围内。同时,Pi和Pg在迭代过程中不断更新,迭代结束后得到的Pg就是所要求的全局最优解。
标准粒子群算法虽然有较好的特性,但是针对不同的问题表现出来的效果是不一样的,当用于本文配煤优化模型时还是出现了一些迭代次数偏高,易陷入局部最优的问题,因此对粒子群算法的改进工作也是必不可少的。
1.2 粒子群算法改进
通过分析可知,对粒子群算法的改进很大程度上体现在对wk、c1和c2的改进上,惯性权重因子wk控制着迭代前的速度对迭代后速度的影响。wk可以对算法的全局搜索能力和局部搜索能力进行平衡调节,因此,若要优化粒子群算法,该参数的参与必不可少,惯性权重越大,群体全局搜索能力越强,群体局部搜索能力越弱;否则,局部搜索能力较强,而全局搜索能力较弱[8]。
本文针对配煤的数学模型求解的问题,将粒子群算法进行了深入改进,改进重点描述如下:
(1)每次迭代结束后得到的全局最优位置Pg,再给一个轻微的随机扰动,这样的随机扰动符合正态分布,保证扰动大部分都比较小,并且通过系数控制,使得随着迭代的进行波动性也越来越小,这样改进之后不但增加了每个粒子的运动轨迹的随机性,而且也没有失去粒子聚集的一般特性。本文中设定的公式如下

其中,randn是服从标准正态分布的随机数,k是当前的迭代次数,式 (3)中10的作用是为了控制波动不至于太大,以防对算法改进起到相反的作用。随着迭代的进行,由于受到迭代次数k 的影响,R 会随之变小,达到了预期的效果。
(2)一次实验中,在粒子群可能已发生早熟的时候,再次将部分的粒子重新随机打乱,也可以很高效的解决粒子的局部收敛的缺点。本算法中的处理是默认算法运行过半后就会出现收敛,此时将粒子20%再随机生成,不过,该步骤只有当粒子个数和迭代次数都不是很少的时候才执行。此方式借鉴了粒子群算法和变异因子的结合。
(3)惯性权重的选取,研究发现,迭代前期较大的惯性权重全局搜索能力较强,后期较小的惯性权重局部搜索能力较强,因此对惯性权重的探索是必不可少的,本文中对该值进行设定,使满足以上条件

本文通过测试,非线性减小的惯性权重比线性减小的效果有一定的改进,因此本文选取的惯性权重如式 (5)所示,其中k为当前迭代次数,N 为总迭代次数。
(4)当最优解的某一维是该维度上的边界值时,收敛速度会有一定程度的减慢,因此,当精度要求较高,且全局最优位置出现在某一维的边界附近 (提前设定一个阈值,如0.1)时,尝试将该维度上的值修正成边界值,作为新的全局最优位置。同时本次迭代结束后还需要检验修正后的全局最优位置的适应值是否小于修正前的全局最优位置的适应值,若确实小,则无需再更改;否则,将全局最优位置恢复成修正之前的值。
(5)求解算法中默认的每个煤种所占比例的取值范围在 [0,100],但实际配煤时某种单煤所占比例一般会有所限制的,例如根据需求,煤种一所占比例最少为30%,而煤种二的比例不得超过50%,因此本算法中加入了相应的限制参数,使得配煤工作更加灵活,也较符合实际。
(6)如果发现某次实验没有达到收敛,对算法进行修正,合并前后两次实验,将前一次的实验结果应用到下一次当中,双保险来保证实验结果的准确性。这样的做法也在某些问题上弥补了粒子群算法的 “早熟”行为,且下一次的实验的收敛速度一般更高于上一次,节约了运行时间。
(7)本算法中需要添加检验函数,判断粒子在某一位置是否满足约束条件。若不满足,舍弃并重新计算新的位置。
(8)初始化时稍微扩大边界范围,可以使得粒子的初始位置更加分散些,更具备一定的随机性。同时,控制好粒子不飞出边界。
我们把相应的改进方式应用到算法当中,下面给出了本文中改进的粒子群算法流程如图1所示。对改进后算法的测试将会在下一章节的系统测试中介绍。
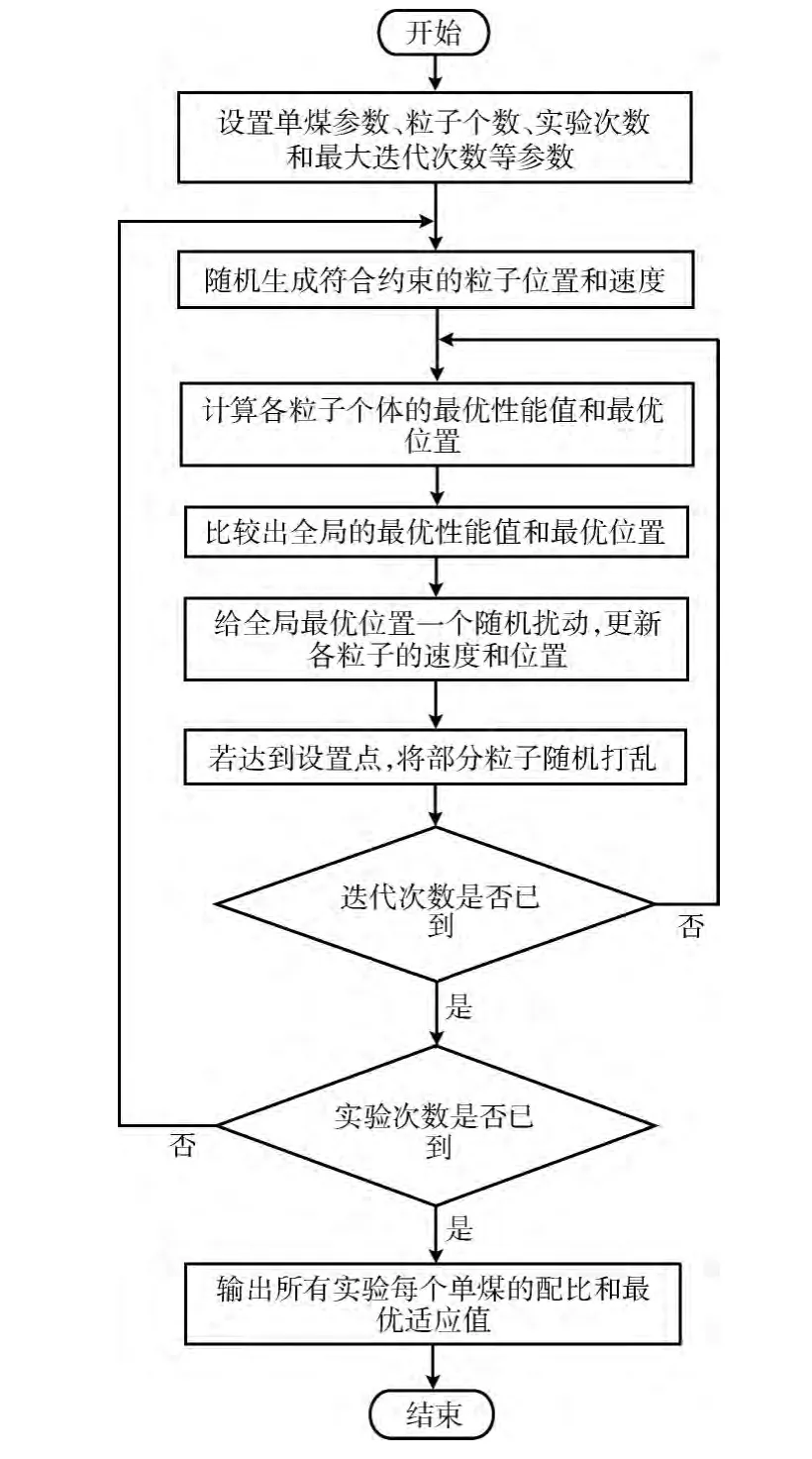
图1 算法流程
2 系统实现与测试
在配煤系统中,我们把Windows当做操作平台进行设计开发系统图形界面,而具体的编程实现和功能设计采用了强大的数学软件MATLAB。
2.1 功能模块实现与测试
系统结构大致由读取数据库数据、煤种选择、煤质指标范围设置、实验参数设置、精度设置和优化计算组成,界面显示如图2所示。

图2 配煤优化图形界面
本系统的数据库包含了各种单煤的煤质信息:发热量、挥发分、硫分、水分、灰分,还有单煤名称和单价,这些问题是解决配煤问题的基础信息,正好利用火电企业已有的数据库新建一个存储单煤信息的表。我们可以在图2所示系统界面中对煤种、煤质指标范围、实验参数和精度进行设置。
设置完各项参数后,点击 “开始计算”按钮 (如图2所示),程序开始运行计算,数秒之后将得到一些配煤结论。通过多次实验,得出结论:实验次数建议取1-20 之间,迭代次数建议取40-200之间,粒子个数建议取20-100之间,这样得出的效果比较有说服力,也不至于系统计算时间过长。
假设单煤数据见表1。
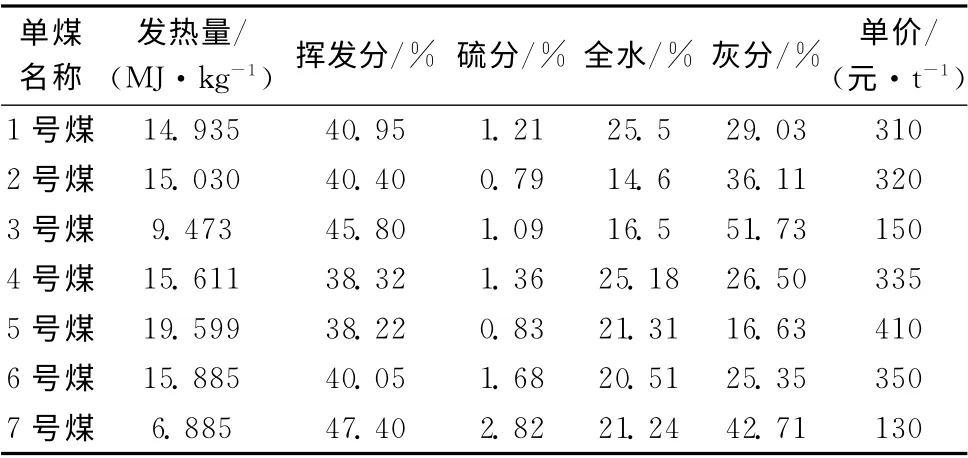
表1 单煤数据
煤质指标范围 (约束条件)见表2。

表2 煤质指标
本系统一共设置了选取了7种单煤进行掺配,煤种较多,更能检验出本系统的性能。同时设置了7种不同的精度供用户选择,可以根据不同的锅炉和实际要求,设置不同的精度。下面进行了3组实验,分别选择3组典型的实验精度进行测试,实验精度分别为5%、0.5%和0.01%。
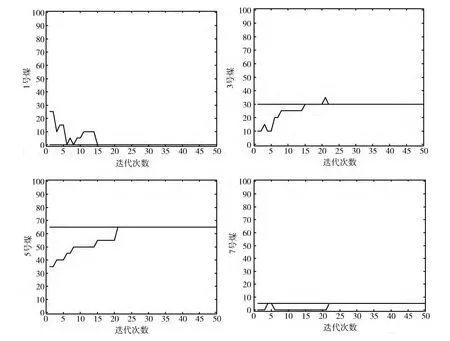
图3 精度为5%时的1、3、5、7号煤所占比例变化
(1)精度设置为低精度 (5%),实验次数为2,迭代次数为50,粒子个数为20,点击 “开始计算”之后粒子都是在朝着全局最优的位置聚集,每一种煤所占比例随着迭代的变动如图3所示。
两次实验的结果一致,7种煤的最终比例分别为:0,0,30,0,65,0,5。最终混煤最低单价为318元。此结果的精度是5%,因此可以满足一般的配煤需求,已经起到了尽可能降低成本的作用,接下来继续测试更高精度的配煤结果。
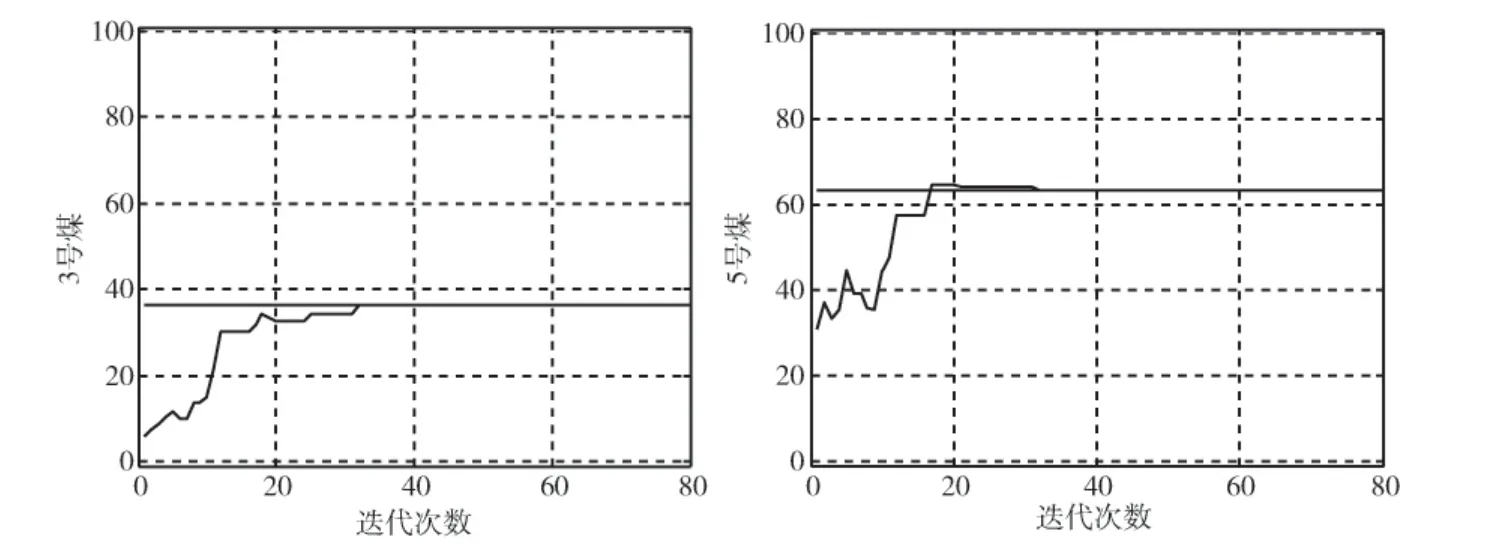
图4 精度为0.5%时的3号煤和5号煤所占比例变化
(2)设置配煤精度为0.5%,实验次数为2,迭代次数为80,粒子个数仍为20,计算后的结果如图4所示。
两次实验的结果一致,7 种煤的最终比例分别为:0,0,36.5,0,63.5,0,0。最终混煤最低单价为315.1元。
以上的结果发现,第一次实验迭代到30次左右的时候开始收敛,直到结束,之后的第二次实验,以此结果为出发点,一直保持着这个结果不变,而且此结果同文献 [9]的完全吻合,可见这样的结果是比较满意的,可以作为配煤的最终结果,也验证了本论文算法的可行性。
(3)设置配煤精度为最高精度 (0.01%),实验次数为2,迭代次数为100,粒子个数为20,进行实验之后得到配煤比例的结果,同样只用3号煤和5号煤进行演示,结果如图5所示。
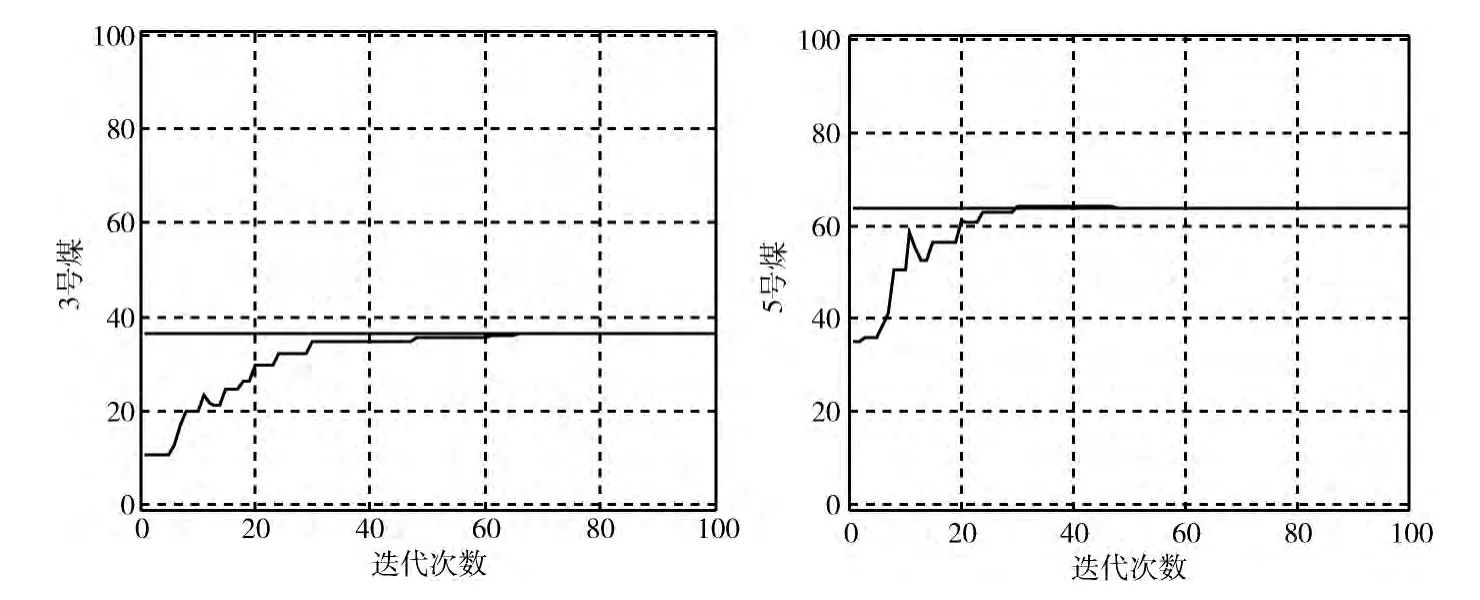
图5 精度为0.01%时3号煤和5号煤所占比例变化
该精度下在迭代进行到70次左右时开始收敛,并得到了最优解。实验结果同精度为0.5%类似,均是第一次实验就已经收敛,在之后的实验保持该最优解,都得到了7种单煤的最终比例:0,0,36.5,0,63.5,0,0;最终混煤最低单价为315.1元。
通过以上3组不同精度的实验比较发现,实验的结果都是高度一致的 (除了第一组实验受到精度的限制,也非常接近最优解),而且完全符合文献 [9]中的实验结果,经过论证,这样的结果确实是最优的。
2.2 实验结果比较
通过已知煤质数据测试了系统的一些功能,得到了比较满意的结果,下面将对优化方法的优劣性和稳定性进行验证,实验数据包括文献 [9]中提供的数据,以及文献[10]提供的数据。
(1)算法性能优越性比较:首先测试标准的粒子群算法,设置粒子个数为20,迭代次数为150,进行20 次实验,把求得最优解时的迭代次数作为比较标准,得到20个结果:92,61,79,134,100,75,80,85,70,98,93,90,151,120,135,126,106,53,58,114。平均迭代次数为96次,程序耗时374s。从图6 中也可以看出,随着迭代的进行粒子逐渐取到了最优值,并在平均迭代九十多次后趋于稳定。
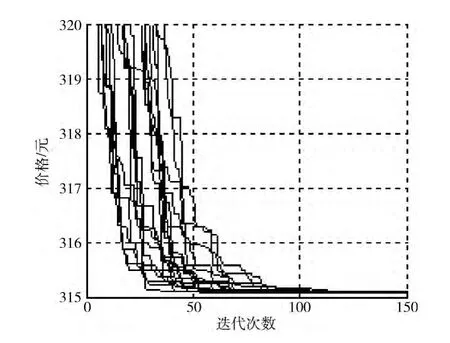
图6 标准粒子群算法
然后测试本文中的改进粒子群算法,同样进行类似的设定,粒子个数为20,迭代次数为100,进行20 次实验,还是把求得最优解时的迭代次数作为比较的标准。测试时,同样把取得最优解时已经发生的迭代次数作为参考,得到20 个结果:61,64,69,79,61,65,79,68,71,74,86,66,75,66,59,62,54,73,66,84。平均迭代次数为69次,程序耗时320s。迭代过程如图7所示。
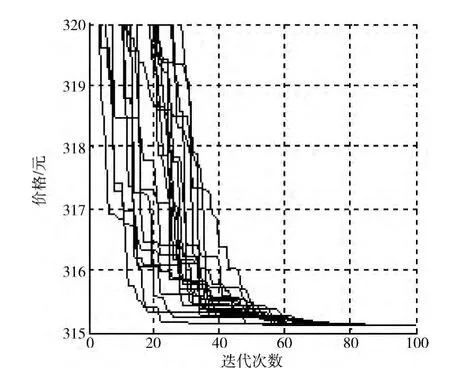
图7 改进粒子群结果
通过比较可以发现,本文的方法不但可以取到最优解,而且所需要的平均迭代次数也是比较少的,平均减少了十几次。可见本论文中对标准粒子群算法的改进确实是有效的,体现出了其优越性。
(2)算法稳定性比较:算法的优越性已经体现,但稳定性也是同样重要的,接下来我们继续对本论文方法的稳定性进行验证。
1)根据文献 [10]提供的单煤数据和设计要求检测,表3给出了5种单煤及其配煤要求。
将数据录入并根据文献要求配置好系统参数,精度为5%,实验次数为1,迭代次数20,粒子个数10,5种单煤的比例变化如图8所示。图中用不同的形状将不同煤种进行了区分。

表3 单煤数据及配煤要求

图8 5种单煤比例变化
最终得出5 种单煤的比例为兖州煤:45%,邰武煤:10%,新集煤:35%,巩义3 煤:10%,龙口3 煤:0%,最低配煤成本单价为224元/吨。这些结果与文献中的结果完全吻合,并且本系统仅耗时0.456 秒就得出结果,效率是相当高的。
2)根据文献 [10]中单煤数据和设计煤种的要求对算法进行检测,表4给出了5种单煤信息和设计要求。

表4 单煤数据及设计要求
将数据输入到系统中,设置精度为最高 (0.01%),实验次数为2,迭代次数150,粒子个数40,同时合并前后两次实验,最终求得到5种单煤的比例结果见表5。

表5 单煤数据及设计要求
以上结果与文献 [10]的结果也是完全吻合,可见粒子的稳定性确实是存在的。
综上,根据以上几组测试实验可以发现,本文中所应用的模型和对粒子群的优化算法是具有优越性和稳定性的。
3 结束语
本文通过对粒子群算法进行进一步的改进并应用于配煤模型的求解当中,最后形成了一个完整的配煤优化系统。本文通过重复大量的探索测试,改进粒子群算法的各个参数和逻辑关系,最后得出本文中出现的配煤优化算法,进而应用在了模型的求解当中,同时利用实验验证了本文模型中所利用的粒子群的优化算法是具有优越性和稳定性的,但是通过大量的实验也发现了本系统仍存在一些不足的地方,主要有包括以下几个方面:
(1)对配煤人员的要求比较高。由于本文中涉及到了对粒子群算法中参数的设置,包括实验次数、迭代次数和粒子个数,虽然在界面中已经给出了默认值和部分提示信息,但还是免不了工作人员对这些数据的疑问。
(2)对粒子群算法的改进虽有效果,但不是非常显著。虽然本文中对粒子群算法的改进之后,使得计算过程中需要的收敛次数减少(从96降到69),但是效果还不是特别的明显。
(3)初始化粒子的时候具有很大的盲目性,随机生成的大部分粒子可能不满足约束条件。目前还没找到一个更好的初始化方法,希望在以后的研究中可以解决。
[1]Zeng Ming,Liu Ximei.Review of renewable energy investment and financing in China:Status,mode,issues and countermeasures[J].Renewable &Sustainable Energy Reviews,2014,31:23-37.
[2]Dienst Carmen,Schneider Clemens.On track to become a low carbon future city?First findings of the integrated status quo and trends assessment of the pilot city of Wuxi in China [J].Sustainability,2013,5 (8):3224-3243.
[3]Tian Lixin,Jin Rulei.Theoretical exploration of carbon emissions dynamic evolutionary system and evolutionary scenario analysis[J].Energy,2012,40 (1):376-386.
[4]Zhao Zhenyu,Yan Hong.Assessment of the biomass power generation industry in China [J].Renewable Energy,2012,37 (1):53-60.
[5]YANG Shengchun.Power coal blending model research [J].Guangdong Electric Power,2012,25 (1):36-39 (in Chinese). [杨圣春.火电厂配煤模型研究 [J].广东电力,2012,25 (1):36-39.]
[6]DONG Husheng,LU Ping,ZHONG Baojiang,et al.The automatic coal blending system based on collaborative quantum particle swarm optimization [J].Manufacturing Automation,2014,30 (1):74-77 (in Chinese).[董虎胜,陆萍,钟宝江,等.基于协同量子粒子群的自动配煤系统优化 [J].制造业自动化,2014,30 (1):74-77.]
[7]ZHANG Lifeng,HU Xiaobing.Hybrid particle swarm optimization algorithm for solving nonlinear constrained problem [J].Computer Science,2011,38 (10A):178-188 (in Chinese).[张利凤,胡小兵.求解非线性约束问题的混合粒子群优化算法 [J].计算机科学,2011,38 (10A):178-188.]
[8]SUI Conghui.Study on the method of particle swarm optimization(pso)algorithm to improve [D].Chengdu:Southwest Jiaotong University,2010 (in Chinese). [随聪慧.粒子群算法的改进方法研究 [D].成都:西南交通大学,2010.]
[9]LIU Yongjiang,GAO Zhengping,HAN Yi,et al.Coal-fired power plants based on particle swarm algorithm to optimize coal blending research [J].Journal of Boiler Technology,2012,43 (5):18-24 (in Chinese). [刘永江,高正平,韩义,等.基于粒子群算法的火电厂优化配煤研究 [J].锅炉技术,2012,43 (5):18-24.]
[10]TAN Baocheng,LI Yuanke.Coal blending technology and its mathematical model research [J].Journal of Xi’an University of Technology,2011,31 (2):156-159 (in Chinese). [谭宝成,李元坷.配煤技术及其数学模型研究 [J].西安工业大学学报,2011,31 (2):156-159.]
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
智能建筑电气技术(2022年2期)2022-02-06
商用汽车(2021年4期)2021-10-13
数学物理学报(2020年6期)2021-01-14
当代陕西(2020年17期)2020-10-28
金桥(2018年4期)2018-09-26
人大建设(2018年5期)2018-08-16
中学生数理化·中考版(2017年12期)2017-04-18
应用科技(2015年5期)2015-12-09
