
一种基于社会化标签的协同过滤推荐算法
2015-12-18 13:17王宝林韩帅帅张德海
电子科技 2015年7期
王宝林,韩帅帅,张德海
(西安电子科技大学电子工程学院,陕西西安 710071)
个性化推荐系统能够根据用户的行为记录将用户感兴趣的信息主动推荐给用户,是解决信息超载问题的一个重要手段[1]。随着Web2.0的发展,社会化标签作为一种互联网资源组织方式被广泛使用[2]。社会化标签是用户兴趣的反映,将社会化标签与个性化推荐系统结合,不仅能改善传统的资源分类方式,而且能根据用户的标注记录给用户推荐个性化的资源[3]。
但社会化标签存在诸如同义词、一词多义、单复数、缩略词和拼写错误等语义模糊和冗余问题[4],给用户和资源建模带来了垃圾信息,从而损害了推荐效果。近年来,一些学者研究了如何改进标签质量。文献[5]采用层次聚类的方法来降低标签噪声带来的影响;信息检索领域的PLSA(Probabilistic Latent Semantic Analysis)和LDA(Latent Dirichlet Allocation)[6]等方法也被用来改进传统的标签建模方法以期获得更好的推荐效果[7]。与这些方法不同,本文通过流行标签建模来降低标签噪声给推荐算法带来的影响。
1 流行标签的选择
流行标签指被很多用户使用过的标签。流行标签更能反映资源的主题而那些被较少使用的标签对其他用户来说是主题无关、缺乏意义甚至是拼写错误的。所以,合理选择流行标签能够过滤标签噪音。
定义
(1)用户集合 U={u1,u2,…,un},包含了所有对站点资源进行过标注的用户。
(2)资源集合 R={r1,r2,…,rm},包含了用户集合中所有用户标注过的资源。每个资源项rj可以被不同的用户以多个标签来描述。
(3)标签集合 T={t1,t2,…,tk},包含用户集合 U使用的所有标签。
(4)流行标签集合 C={c1,c2,…,cq},包含所有流行标签。
定义u(ti)表示使用过标签ti进行过标注的用户集,ti∈T;u(ti,rj)表示用标签 ti标注过资源 rj的用户集合,rj∈R;R(ti)表示用标签ti标注过的资源集合,R(ti)⊆R;那么 u(ti)={u(ti,rj)rj∈R(ti)}。标签ti的全局流行度可以用 u(ti)来表示,u(ti)为用标签ti标注过的用户数,标签ti对资源rj的局部流行度可以用 u(ti,rj)来表示。
若仅基于全局的流行度来选择流行标签,一些具有低全局流行度但高局部流行度的重要标签将被排除。此外,那些具有高全局流行度,但低局部流行度的标签将被错误选择。
综合考虑后,基于标签的最大局部流行度来选择流行标签。令O(ti)是标签ti的最大局部流行度,则O(ti)=maxrj∈R(ti){u(ti,rj)};令 θ是阈值,满足O(ti)>θ的标签ti将被作为流行标签。
定义 T(rj)为资源 rj的标签集合,maxti∈T(rj){u(ti,rj)}是资源rj的标签集T(rj)中的最大局部流行度。显然,如果阈值θ大于最大局部流行度,那么资源rj的所有标签将不会被选为流行标签,导致没有流行标签可描述资源rj的主题。
令 λ =minrj∈R{maxti∈T(rj){u(ti,rj)}};若 θ≤λ,则可保证所有的资源都能被至少一个流行标签所描述。因此,流行标签集合C定义为
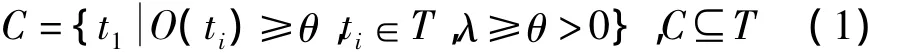
2 基于流行标签的协同过滤算法
协同过滤算法是目前广泛应用的个性化推荐算法,其核心思想可分为两部分:(1)利用用户的历史信息计算用户间的相似性。(2)利用目标用户相似性较高的邻居对其他产品的评价来预测目标用户对特定产品的喜好程度,系统根据这一喜好程度来对目标用户进行推荐[8]。
基于协同过滤技术的推荐过程可分为3个阶段:数据表示、发现最近邻居和推荐资源[9]。
2.1 数据表示
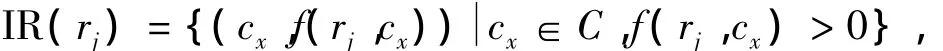
f(rj,cx)是资源rj被流行标签cx标注的频率
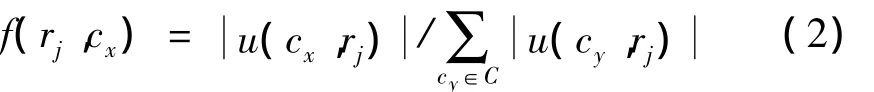
(1)资源的表示。
对于一个规模为q的流行标签集合C,C=q,对任意资源 rj∈R 都可以表示为一个向量,bj=(bj,1,bj,2,…,bj,x,…,bj,q),其中 bj,x=f(rj,cx)。
(2)标签的表示。对每个用户而言,尽管他使用的标签对其他用户不是都有用,但却反映了该用户对资源的个性化分类喜好。因此,每个用户使用过的标签对用户的建模都有作用,而无论标签是否流行。文中考虑如何用流行标签来表示用户使用过的标签,从而最大限度的保留用户的个性化信息。
令t是用户u使用过的一个标签,C={c1,c2,…,cq}是流行标签集合,则t可由带权重的流行标签来表示:TR(t,u)={(cx,w(cx,t,u ))cx∈C,w(cx,t,u)>0},w(cx,t,u)是标签 cx的权重。
标签cx的权重w(cx,t,u)可通过计算用户u用标签t标注过的资源集中流行标签cx的使用频率来表示。因不同标签标注过的资源数可能不同,用户u使用标签t标注的资源数来对 w(cx,t,u)归一化。定义 R(t,u)为用户u用标签t标注的资源集,则cx的权重为
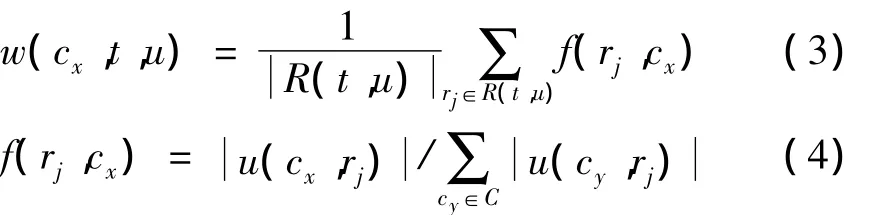
显然,标签的表示 TR(t,u)由用户u用标签 t标注过的项目集产生而来,反映了用户u对资源的分类的个性化观点。因此,用流行标签表示每个标签的主题依然保留了用户的喜好。
(3)用户的表示。对用户ui,流行标签集C={c1,c2,…,cq},用户ui的兴趣模型可用一个规模为q的向量来表示,定义为

sc(ui,cx)是 vi,x项的权重得分,表示用户 ui对流行标签 cx的兴趣度;(ui,cx)=1;sc(ui,cx)∈[0,1]。
综上,可用规模为U ×C的矩阵v来为所有的用户U建模。矩阵v中的任意一行vi表示用户ui的兴趣模型。
为了计算每个用户主题兴趣的权重sc(ui,cx),首先,对该用户使用过的标签计算兴趣分布。
令 Ti={ti,1,…,ti,k,…,ti,a}是用户 ui使用过的标签集合,ti,1,ti,k,…,ti,a∈T,用s(ti,k)来表示用户ui对标签ti,k的兴趣度,则用户ui的兴趣分布可用得分向量(s(ti,1),…,s(ti,k),…,s(ti,a))表示,s(ti,k)=1。
显然,若用户对一个标签或一个主题更感兴趣,那么他会利用该标签标注更多的资源。这表明,用户使用一个标签的数量是评价用户对该标签的兴趣度的重要指标。
定义 R(ti,k,ui)为用户ui用标签ti,k标注过的资源的数量,则可通过计算 R(ti,k,ui)占用户ui标注资源总数的比例来衡量用户对标签ti,k的兴趣度
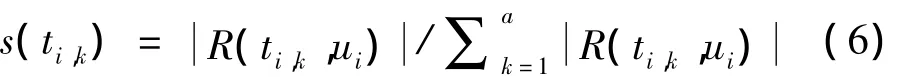
由前文所述,每个标签都能由流行标签集表示,则用户使用过的标签的权重都可转化为流行标签的权重
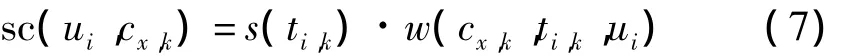
用户ui对主题cx的兴趣度为
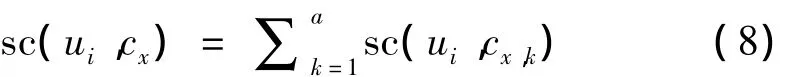
综上,用户兴趣度的表示方式就由个人标签转化为流行标签。这种建模方法能在降低标签噪声的同时还能保留用户对分类的个人偏好。此外,转化后的矩阵规模大幅减小,利于后续操作。
2.2 发现最近邻居
生成近邻的任务就是为指定用户寻找最相似的用户集合,本文用余弦相似性来计算用户的相似度
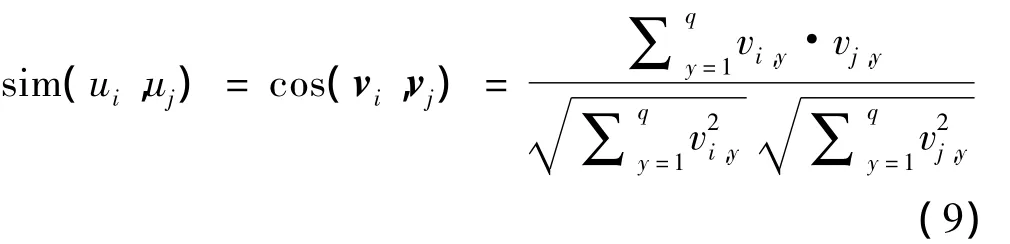
据此,可得到指定用户最相似的K个用户
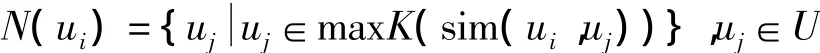
maxK()函数用于获取最大的K个值。
2.3 推荐资源
根据找到的K个相似用户,将属于相似用户资源集但自己没浏览过的资源推荐给用户。
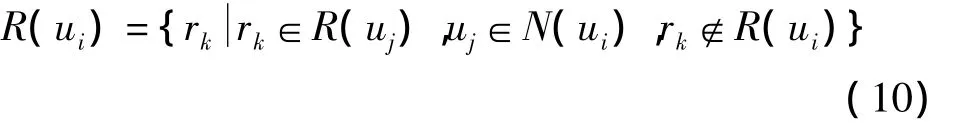
根据式(10)得到待推荐的资源集合,但并未考虑待推荐资源与用户模型的相似性。通过计算用户兴趣模型与资源模型的相似性,找到最相似的N个资源推荐给用户
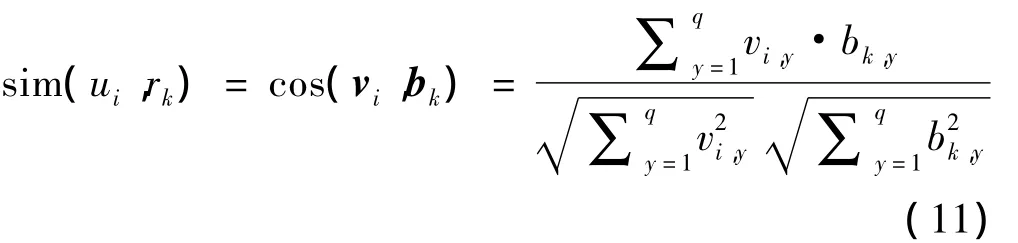
3 实验评估
3.1 实验数据
文中采用MovieLens 10M作为算法实验的数据集,其包含了71 567个用户对10 681部电影的评分记录,共10 000 054个评分和95 580个标签。本文只研究基于标签的推荐算法,所以只选用其中的tags.dat数据。
数据集选择方法:为了不受数据稀疏性的影响,选取打过最多标签的50个用户作为用户集;然后在这50个用户的标注记录中筛选出被标注次数最多的100部电影作为资源集,得到这50个用户在这100部电影上的7 772条标注记录,其中包含1 572种不同的标签。对每个用户按1∶4划分测试集与训练集,通过学习训练集中的用户标签数据预测在测试集上用户会给哪些电影打标签。
3.2 评测指标
通常用准确率和召回率来评价推荐算法的性能。令R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表。则推荐结果的准确度P定义[10]为
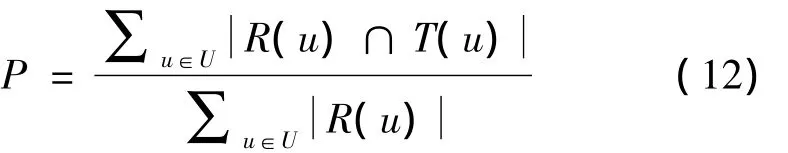
推荐结果的召回率R定义为
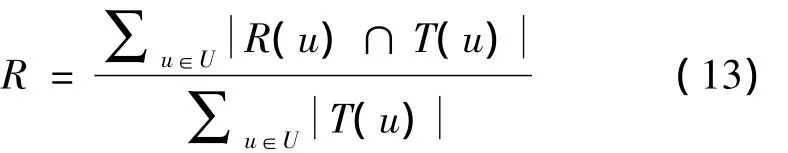
3.3 实验对比
方法1 基于本文提出的基于流行标签的协同过滤算法PopularTag-Based。
方法2 基于未经处理的传统的基于标签的协同过滤算法Tag-Based。具体步骤为:
(1)从所有的标注记录中找出所有不同的标签组成标签集合。设标签集合为T={t1,t2,…,tn},不同标签的种类为n。
(2)为每个用户构建在整个标签集合上的向量空间模型。则每个用户可被表示为一个n维向量,第k维的权重为标签tk在该用户所有标注的标签中出现的频率。则对用户ui而言,其的兴趣模型为ui=(wi1,wi2,…,win)。
(3)对用户ui寻找最相似的K个用户组成最近邻,用余弦相似度来计算两个用户向量模型间的相似度。
(4)在这个最近邻内部寻找他们标注过的资源,将每项资源用向量表示。每个资源可用一个n维向量表示,第k维的权重为标签tk在所有标注过该资源的标签中所占的频率,则 Ij=(wj1,wj2,…,wjn)。
(5)将目标用户的兴趣向量与资源向量求相似性,按从大到小的顺序排列,取前N项资源推荐给目标用户。两种算法的准确率对比图如图1所示,召回率对比图如图2所示。
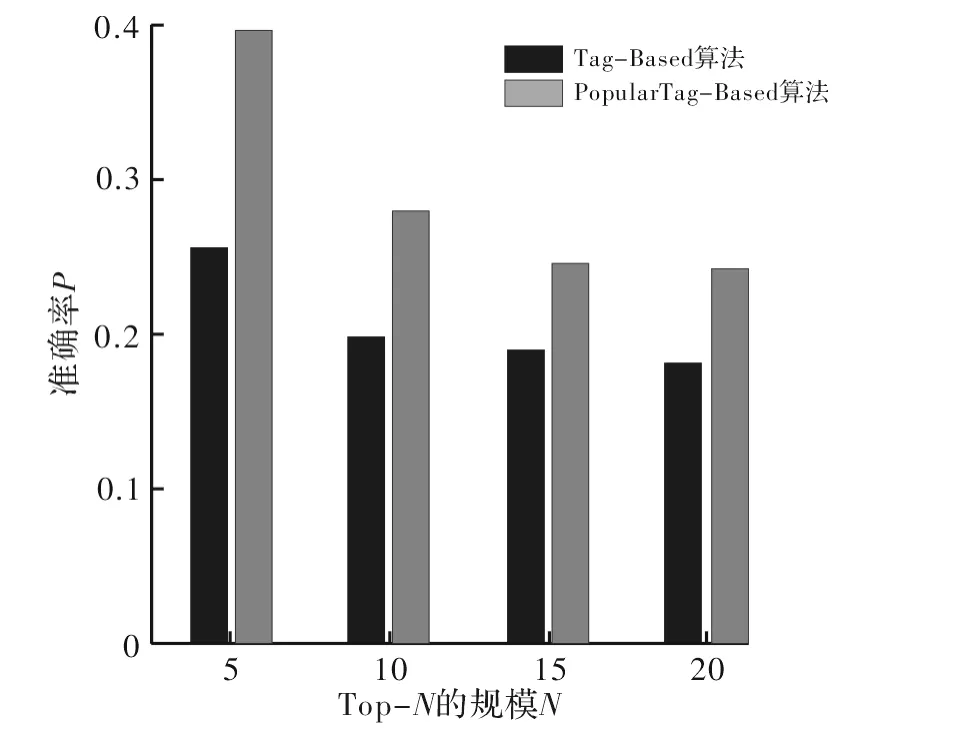
图1 准确率对比图
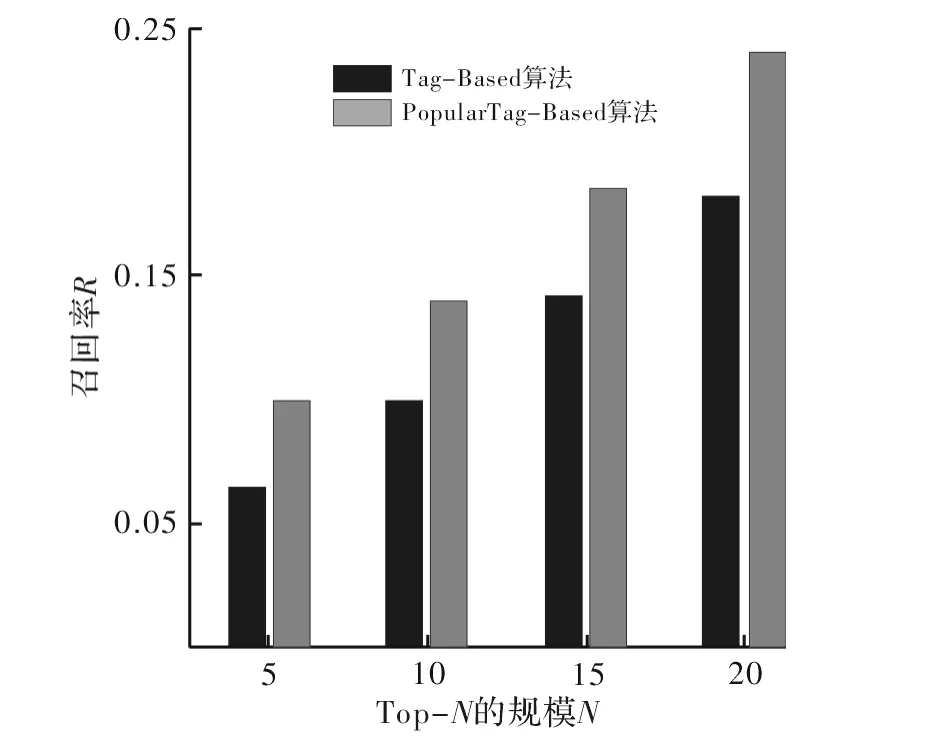
图2 召回率对比图
从实验结果可看出,PopularTag-Based算法在准确率和召回率两方面均较传统的Tag-Based算法有显著提升。因Tag-Based算法并未考虑社会化标签的噪声,而是直接利用原始标签信息进行建模,标签的维数达到1 572维,导致了建模维度过高而且推荐精度低的结果。本文提出的基于流行标签的算法通过对每个资源统计标签的局部流行度,选择流行标签的阈值为θ=5,将标签的维数降为流行标签集的个数(343个),在降维的同时还过滤掉了标签的噪声,改善了推荐的效果。
4 结束语
本文根据大众智慧改进了传统的基于社会化标签的协同过滤算法。针对社会化标签出现的语义模糊和冗余问题,结合大众智慧选择流行标签,利用流行标签来表示资源、用户的个性标签和兴趣模型。基于流行标签的建模方法有效降低了标签噪声的影响。阐述了基于流行标签的协同过滤算法的实现,并在MovieLens 10 M数据集上进行了对比实验,实验结果表明该方法能有效改善传统推荐算法的性能。
[1] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66 -76.
[2] 张海燕,孟祥武.基于社会化标签的推荐系统研究[J].情报理论与实践,2012,35(5):103 -106.
[3] Shilad Sen,Jesse Vig,John Riedl.Tagommenders:connecting users to items through tags[C].Madrid,Spain:Proceedings of the 18th international conference on World wide web,2009.
[4] Aleksandra Klasnja Milicevic,Alexandros Nanopoulos,Mirjana Ivanovic.Social tagging in recommender systems:a survey of the state-of-the-art and possible extensions[J].Artificial Intelligence Review,2010,33(3):187 -209.
[5] Shepitsen Andriy,Gemmell Jonathan,Mobasher Bamshad.Personalized recommendation in social tagging systems using hierarchical clustering[C].Lausanne,Switzerland:Proceedings of the 2008 ACM Conference on Recommender Systems,2008.
[6] Ralf Krestel,Peter Fankhauser,Wolfgang Nejdl.Latent dirichlet allocation for tag recommendation[C].New York,USA:Proceeding of the Third ACM Conference on Recommender Systems,2009.
[7] 张子柯.社会化标签系统的结构、演化和功能[J].上海理工大学学报,2011,33(5):444 -451.
[8] 刘建国,周涛,汪秉洪.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1 -15.
[9] 田莹颖.基于社会化标签系统的个性化信息推荐探讨[J].图书情报工作,2010,54(1):50 -53.
[10]项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
猜你喜欢
少先队活动(2021年5期)2021-07-22
当代陕西(2020年17期)2020-10-28
中国非营利评论(2019年1期)2019-06-18
车迷(2018年11期)2018-08-30
人大建设(2018年5期)2018-08-16
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
体育科技(2016年2期)2016-02-28
应用科技(2015年5期)2015-12-09
学习月刊(2015年7期)2015-07-09
