
空间局部重合图像的快速聚类
2015-12-15 05:20汪国安
河南教育学院学报(自然科学版) 2015年2期
关键词:数据挖掘
汪国安, 郭 昕
(1.河南大学 计算机与信息工程学院,河南 开封 475004; 2.河南大学 网络信息中心,河南 开封 475004)
空间局部重合图像的快速聚类
汪国安1,2, 郭昕1
(1.河南大学 计算机与信息工程学院,河南 开封 475004; 2.河南大学 网络信息中心,河南 开封 475004)
摘要:采用视觉词袋模型表示图像,以快速检测空间上部分重合图像对的最小哈希算法为基础,提出一种对局部重合图像聚类即数据挖掘的方法,能够找到类种子的概率随着类别中图像数目的增长显著增加.对聚类的结果进行空间上的验证,并在大小分别为104、105以及5×106的图像数据集上对该算法的效果进行测试.算法的速度依赖于数据集中图像的数目和数据集中类别的数目,类种子生成的时间复杂度线性相关于数据集大小.
关键词:最小哈希;视觉词袋模型;图像聚类;局部重合图像;数据挖掘
0引言
近年来,图像数据的规模因商业用途和个人用途等因素呈爆炸性增长.检索海量图像数据成为一个具有挑战性的问题[1].
文献[2]表明,基于三维采集和空间重合获取到的图像特征点很直观,也很容易满足用户的需求.但是,该方法用空间相关的图像数据集进行模型训练时,需要手工标注大量数据.文献[3-5]表明,在当前主流的图像检索系统中,检索一个用户感兴趣的实例对象时,其结果能够同时具有相当高的准确率和召回率.如果把其中的方法直接应用到海量图像集的检索任务中去,由于它要将实例对象和数据库中每个图像两两进行比对,所以时间复杂度将会是数据集大小的平方,因此这种方法不适用于海量图像数据库的检索任务.
本文以图像检索知识为背景提出一种快速的空间局部重合图像聚类算法.与文献[2]相比,该算法不需要人工进行大量的数据标注工作.与文献[3-5]相比,该算法不是将查询的实例对象和数据库中的每个图像两两进行比对,而是快速检测空间上部分重合图像对的最小哈希算法,也就是所谓的类种子.类种子生成的概率随着该类别中图像数目的增长显著增加,实际的时间复杂度(生成类种子的时间)与数据集大小线性相关.
1空间局部重合图像聚类中的最小哈希算法
本节主要对空间局部重合图像聚类中的最小哈希算法进行详细描述.
把找到空间相关图像的任务看作是搜寻一个无向图中的连通分支.无向图中的顶点代表图像.如果两个图像拥有共同的场景,那么就说它们在空间上是相关的.从快速聚类算法的角度给出一个更实际的定义:如果两个图像能够被一些鲁棒的匹配算法匹配,那么它们描述着同一个场景.
尽管无向图的顶点都是已知的(图像数据库),但无向图的边结构并不是作为一个先验已知的,需要用聚类算法去发掘.一个图像检索系统可以被抽象地理解为:给定无向图中的一个顶点(一个图像),返回与这个顶点(图像)相关的所有边.在大多数的现代检索系统中,一次查询的时间复杂度是和数据库的大小近似于线性相关的,要比遍历数据库并且比对数据库中的每一个图像,在速度上有着数量级上的优势.
最小哈希算法是一种快速检索无向图中边的哈希方法,但是快速检索的代价却是相对低的召回率:检索到实例对象相关的一条边的概率收敛于Pc.Pc正比于以图像对共有的视觉单词度量的相似度.相似度和概率Pc的定义将在1.1节详细描述.对于空间局部重合图像来说,Pc会有一个比较大的值(接近于1),这也是最小哈希算法主要的应用领域[6-7].
整个处理的步骤如下:
1)哈希.图像描述子被存储在哈希表中.实验使用251个不同的描述子.两个图像落入同一个哈希桶的概率(精确描述子匹配)正比于它们的相似度.
2)相似度估计.对于在同一个哈希桶中的图像对,也即在一个哈希桶中发生冲突,相似度将被计算.比较两个弱化的视觉词袋特征向量并且计算完全一致的元素(都为0或者都为1),这个过程是快速的.在本文的实验中,弱化的视觉词袋特征向量的维度为512.之后,相似度可被阈值化.
3)空间一致性验证.对于每个通过相似度检测的图像,将进行空间一致性验证.通过空间一致性验证的图像将成为最终的类种子.
1.1最小哈希算法概述
最小哈希算法是一种局部敏感哈希算法[8].在高相似度图像中它的概率收敛于1,不相关的图像收敛于0,对于一般的相似图像对(有比较低的相似度,但是本质上是相似的图像,诸如同一个场景的图像对)却收敛于一个比较小的概率(图1)[5,9],这样一个低的召回率使最小哈希算法不能直接应用于图像检索中.笔者认为它可以很有效地应用在图像聚类和数据挖掘中.

注:(b)的函数图像是对(a)中函数图像左下部的一个局部放大表示,(b)中函数的垂直坐标是用log作为刻度的
下面将概述最小哈希算法.图像将用视觉字典集合(词袋模型)表示.本文中是用视觉字典集合的一种相对较弱的表示,映射到视觉字典的视觉词袋特征向量的每一维(对应于相应视觉单词出现的频率)将被弱化为二值表示(存在或不存在),称为弱化的视觉词袋特征向量.
一个最小哈希函数f弱化的视觉词袋特征向量的每一维赋予一个数值.该函数有这样一个性质:两个弱化的视觉词袋特征向量经过f之后相等的概率和两个弱化的视觉词袋特征向量之间的相似度完全相同,
P{f(A1)=f(A2)}=sim(A1,A2).
(1)
用杰卡德距离度量两个特征向量之间的相似度,其中A1和A2是两个图像弱化的视觉词袋特征向量表示,它们的相似度即为它们的交集比它们的并集,
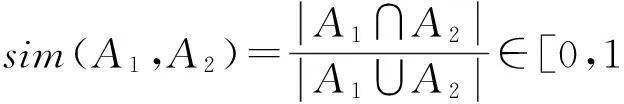
(2)
为了更高效更准确地进行检索,最小哈希fi的函数值被分组在s元组中,称为草图.由相似度的定义可知,相似的图像拥有很多相同的最小哈希函数值,因此拥有相同的草图的概率比较大.在另一方面,不相似的图像拥有同一个草图的概率是比较小的.
两个弱化的视觉词袋特征向量之间至少有一个相同的草图(在k个草图中)的概率为
Pc(A1,A2)=1-(1-sim(A1,A2)s)k.
(3)
这个概率依赖于两个图像之间的相似度以及草图的大小s和彼此相互独立的草图数目k.图1描述了两个图像至少有一个草图冲突的概率和图像对相似度之间的函数关系,将有着不同相似度的图像与“视觉相关度”建立联系,其中在每个草图中k=512,s=3.
有一点值得注意,公式(2)的相似度度量假设弱化的视觉词袋特征向量的每一维度都是同等重要的,然而在实际中,某些维度是比其他维度更重要.一个扩展的方法允许对于不同的维度赋予不同的权重[10].令dw≥0作为维度Xw的权重,则加权的相似度度量为
(4)
这种加权的相似度度量和非加权相似度度量的相比,可以更好地表明图像对之间的相似度以及减少错误的草图冲突数目[10].
1.2类种子的生成
本小节描述一个随机的类种子生成的过程.首先观察图1中的曲线,这样一个类似sigmoid函数的曲线对于空间局部重合图像聚类任务来说很有研究价值.图像对之间拥有较高的相似度,可被检索出(哈希函数发生冲突)的概率接近于1.然而尽管一些图像对的内容只是同一场景的些许视角不同,也可能会被检索(哈希函数不发生冲突),即认为是不相关的图像对,函数曲线迅速下降并接近于0.
为了实现空间局部重合图像聚类亦即数据挖掘,注意一下图1曲线的左下部分.根据公式(3),相似度sim=0.05的图像对可以被检索出来的概率为6.2%(其中s=3,k=512).如此低的召回率对于一个检索系统显然是不能接受的.然而我们并不是要在这样一个简单的步骤中检索到所有的相关图像,而是要快速找到类种子,在每个类中找到至少一个类种子是完全可以实现的,因为每个类的重要性是和这个类在数据库中所占的大小相关的.
使用最小哈希算法但一个类种子都未能找到的概率由下面两个因素决定:类内图像的相似度和实际代表着同一场景的图像的数目.假设一个确定的场景有v个不同的视角.因此对于类内的图像对(Ai,Aj),一个类种子都未能找到的概率可以表示为
(5)
其中,ε代表着一个“平均”的冲突概率.图2的曲线表明,对于一个比较热门的场景(诸如摄影师经常喜欢取景的地方),一个类种子都未能找到的概率曲线接近于0.图中3条曲线代表相似度分别为5%(上方曲线),6%(中间曲线),7%(下方曲线).既然相似度的定义是两个弱化的视觉词袋特征向量的交集比它们的并集(见式(2)),因此相似度为6%与相似度为5%的差别还是很大的.从6%的相似度到5%的相似度意味着要移除它们相交部分17.5%的元素.

注:(a)与(b)水平轴的刻度是不同的.每个图的3条曲线描述了不同的“平均”
下面讨论最小哈希算法的时间复杂度,该算法建立在固定数目为M个哈希桶的哈希方法上.假设哈希键服从均匀分布,C个哈希键落入同一个哈希桶的随机变量服从泊松分布,冲突发生的期望为λ=D/M(即文件被分割到哈希表中的数目),那么一对哈希键落入同一个哈希桶的期望为

(6)
由式(6)可知,时间复杂度为O(D2).然而,对于有限的数据库来说,当数据库的大小D≤M时,该算法复杂度接近于一个线性时间,因为D2/M+D≤2D.在最小哈希算法中,哈希桶的数目M由两个参数决定:视觉词典的大小w以及草图的大小s,并且正比于ws.本文实验中,令w=217,s=3或s=4,则M=251和M=268,这个数目已足够模拟互联网上的实际数据量.
1.3空间一致性验证
在空间一致性的验证过程中,笔者采用了多对多的类RANSAC方法[3].用一个共有的视觉单词ID号定义尝试性的对应.几何约束是一个仿射变换.这样的一个选择是便捷的,因为只是一个椭圆到椭圆的仿射对应(加上一个约束在重力向量上),这对实例化这样的一个近似模型是足够的,该模型还可以用局部优化算法进一步优化[11].有着一个松散阈值的仿射变换模型,允许检测一个在场景里面没有明显透视形变的接近平面的结构.之后,在这些模型上的全局一致性将通过RANSAC方法去验证,满足核面几何学或者单应性[11-13].最终的检查速度是非常快的,因为对这个阶段的尝试性对应是从前一阶段统一起来的内层对应,并且存在一个较高的内层对应系数.
这里有两个误匹配的来源:感兴趣点的退化(靠近共线点集合)和重复结构(许多特征被映射到了同一个视觉单词上,典型的情况是类网格结构).在本文提到的实验中,为了正确验证图像对,必须有足够多的匹配不是感兴趣点的退化以及重复结构.
2实验结果与评估
笔者做了两个相关实验.第一个是为了验证在1.2节提到的理论上的种子生成概率在实际数据上是否足够高;第二个实验是为了验证在海量数据上的效果,实验数据为一个包含10万张图像的数据集.
2.1种子生成的成功率
为了验证种子生成阶段在真实数据上的成功率,笔者使用了一个标准图像检索基准数据集(美国肯塔基州大学数据集).该数据集包含10 200个图像;每4个图像描述同一个场景,也就是说总共有2 550个类别,其中每个类别的大小为4.并且,数据集提供了图像、已经检测的图像特征以及SIFT描述子.在实验中使用提供的特征和描述子.在这个数据集上的实验是对每个检索实例去查询数据集,并从它所在的类别中找出检索实例对应的其他3个图像.检索的成功率由前4个结果中正确检索图像的数目衡量(检索实例图像也需要被检索到),因此最好的得分就是4.

图3 在Kentucky数据集上种子生成成功率与期望成功率关系的直方图分布 Fig.3 Histogram of relationship between success average of generate seeds and expectation on Kentucky dataset
然而我们对另外的一些数据感兴趣.目标是有多少个类别(每类中图像数目是4),我们的方法可以找到至少一个类种子.本实验使用包含217个单词的视觉词典.对于每个图像,512个独立的随机最小哈希函数将被使用,并把这些函数分组,得到512个大小为3的草图(独立的最小哈希函数将被多次使用).通过这样的设置,将有11 556对图像有至少一个公共的草图冲突,对于3 553个通过相似度检测的图像,3 210个是正确的.至少有一个图像在它对应类中的4个图像之一的数目是1 196(在2 550个所有的类别中).换句话说,在每个类大小为4的2 550个类中,种子生成的成功概率为46.9%,这个值相当于解决失败值的期望.接近50%的种子生成成功率看起来比理论的低,但是一个类只有4个图像这种情况比一般实际情况每个类别中包含105~107个图像要少得太多了.
实验比较了预测的成功率/失败率和理论上的失败率(图3),精确计算了“平均”冲突概率ε,即每个类中枚举类中的所有图像.对每个类来说,能够观察到一个类种子能否成功生成.图3的曲线描述出不同预测成功率下类种子生成的成功率,直方图非常接近于灰色的实线.
这里需要注意的是,本实验只是对类种子生成的伪阴性感兴趣,而不是假阳性概率.潜在的种子并不在每类4个正确图像之中,即并不是需要的假阳性问题,因为许多场景都在同一个背景中呈现.对数据集的正确分类图像来说,这些图像被分到了不同的组.比如,一些不在同一个组中并且生成空间不相关的数据集,它们实质上在背景中存在明显的局部重合情况.因此,在这种情况下空间一致性验证将不能发挥作用,因为笔者仅仅使用提供的数据集,这些数据集并不包括用于几何验证的必要信息.
用上文提到的标准的检索分数去度量最小哈希算法,得分为1.63.这个效果比目前的检索系统报告的3.3分到3.6分要低.因此,考虑最小哈希的收尾工作很重要,也就是加上检索实例本身,这样会有一个平均的2.27分.这个效果和一个足够的召回率(46.9%在类别大小为4的数据集上的类种子生成成功率),使得最小哈希方法适合于随机数据挖掘工作中的类种子生成.
2.2在10万张牛津标志性建筑数据集上的聚类实验
本实验使用从Flickr个人主页下载的大数据图像集[2],这个数据集包含5 062个从牛津标志性建筑数据集[14]上获得的图像和99 792张从Flickr1数据集(文献[3]使用的数据集)中取得的图像数据.两个数据集都由高分辨率的图像(1 024 pixel×768 pixel)组成.这个数据集同样也包含已经提取出来的SIFT特征描述子——这些标准的特征以及描述子将被直接用在本实验中.这里共有104 844张图像附带294 105 803个SIFT特征描述子(平均每张图像2 805个特征).SIFT描述子特征占用35GB空间,在这个数据集中,11个标志性建筑场景是手工标注的.
和上一个实验一样,笔者使用一个包含217个单词的词典,并用最小哈希方法去生成类种子.牛津标志性建筑数据集中每个类别包含102到103个图像.为了表明这个方法的可扩展性,使用512个最小哈希函数并分组到512个大小为3的草图中.与前一个实验类似,这些设置允许我们发现很小的类别.平均来看,最小哈希对每个图像产生了38.4个草图冲突.这个减少到了平均每个图像经阈值校验之后产生可能的1.23个类种子——和129 341个类种子对应.此外,3 103个图像被发现有着明确的部分重合在数据集中.所有的刚被发现的部分重合图像被去除,其他剩下的类种子去进行空间一致性验证,最后剩下441个经过验证后的类种子,这是类数目的一个上界.
表1总结了在真实信息上的实验结果.对每一个标志性建筑场景,我们发现所聚的类包含了更多的正确的标志性建筑场景图像,并且在类中计算出很多正确的真实图像信息.同时,通过观察这些类别,一个绝对数量的不相关图像也被展示出来.另外的一些建筑出现在相同的一个类别中,如果它们彼此之间在空间上是相邻的(有连接部分),并不认为是不相关的图像.举个例子,All Souls和Radcliffe Camera是在同一个类中,因为彼此在空间上相邻,并且同时出现在若干个图像中.

表1 在牛津地标数据集上的标注图像结果
数据集大小对运行时间的影响反映在图4上,图4(c)是聚类完成的时间作为数据集大小的一个函数表示.类种子生成的时间和数据集大小约近线性相关(和类种子生成的数目与数据集大小的关系十分相近),并且能够被检索的部分随着数据集大小以及种子生成数目的增大而增大.全局的复杂度近似平方相关.注意到种子的数量是数量级低于数据库的大小——相较于文献[3-5]中与数据库的大小平方相关的时间复杂度,随机聚类在速度上明显快于单独去查询每个图像.

图4 标注结果在10万张牛津地标数据集上进行10次实验的平均表示
2.3对500万张图像的大规模聚类
我们将在数据集大小为500万的Flickr图像集上进行聚类实验,在这个实验中,使用海森仿射特征,视觉词典是由1M的视觉单词构成,草图参数:s=4,k=512.聚类过程在PC机(CPU 3.0 GHz 单核,内存 64 GB)上运行了大约28 h,平均0.020 s处理一张图片.在大约500万个图像中,474 434张被指定到16 957个类中.
3结论
提出了一种海量数据集中空间局部重合图像的快速聚类算法,该算法的基本步骤为:(1)将图像描述子存储在哈希表中,即最小哈希的过程;(2)进行相似度估计;(3)空间一致性验证,其中最关键的技术为利用图像检索的原理进行空间局部重合图像的聚类工作.不是将查询的实例对象和数据库中的每个图像两两进行比对,而是快速检测空间上部分重合图像对的最小哈希算法.
本文提出的算法收敛速度依赖于数据集的大小,在实际中非常快,并且与数据集的大小线性相关(大约234≈1010张图像).聚类成功的概率依赖于每个类别的大小,以及每个类中图像之间的平均相似度,这个概率是和数据集的大小无关的.该算法的效果已在大小分别为104、105以及5×106的图像数据集上进行测试.
参考文献
[1]李向阳,庄越挺,潘云鹤.基于内容的图像检索技术与系统[J]. 计算机研究与发展,2001,38(3):344-353.
[2]SNAVELY N, SEITZ S M, SZELISKI R. Photo tourism: Exploring photo collections in 3D[J]. ACM Transactions on Graphics (TOG).ACM,2006, 25(3): 835-846.
[3]PHILBIN J, CHUM O, ISARD M, et al. Object retrieval with large vocabularies and fast spatial matching[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2007: 1-8.
[4]JEGOU H, HARZALLAH H, SCHMID C. A contextual dissimilarity measure for accurate and efficient image search[C]//IEEE Conference on Computer Vision and Pattern Recognition.IEEE, 2007: 1-8.
[5]CHUM O, PHILBIN J, SIVIC J, et al. Total recall: Automatic query expansion with a generative feature model for object retrieval[C]//IEEE 11th International Conference on Computer Vision. IEEE, 2007: 1-8.
[6]SCHINDLER G, BROWN M, SZELISKI R. City-scale location recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2007: 1-7.
[7]BRODER A Z. On the resemblance and containment of documents[C]//Proceedings of Compression and Complexity of Sequences. IEEE, 1997: 21-29.
[8]INDYK P, MOTWANI R. Approximate nearest neighbors: towards removing the curse of dimensionality[C]//Proceedings of the thirtieth annual ACM symposium on Theory of computing. ACM, 1998: 604-613.
[9]CHUM O, PHILBIN J, ISARD M, et al. Scalable near identical image and shot detection[C]//Proceedings of the 6th ACM international conference on Image and video retrieval. ACM, 2007: 549-556.
[10]CHUM O, PHILBIN J, ZISSERMAN A. Near Duplicate Image Detection: Min-Hash and tf-idf Weighting[C]//BMVC. 2008: 812-815.
[11]CHUM O, MATAS J, OBDRZALEK S. Enhancing RANSAC by generalized model optimization[C]//Proc of the ACCV. 2004: 812-817.
[12]CHUM O, WERNER T, MATAS J. Two-view geometry estimation unaffected by a dominant plane[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE, 2005: 772-779.
[13]FRAHM J M, POLLEFEYS M. RANSAC for (quasi-) degenerate data (QDEGSAC)[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE, 2006: 453-460.
[14]PERD’OCH M, CHUM O, MATAS J. Efficient representation of local geometry for large scale object retrieval[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009: 9-16.
声明
为扩大本刊及作者知识信息交流渠道,加强知识信息推广力度,本刊已许可CNKI(中国知网)及其系列数据库、万方数据资源系统数据化期刊群、维普中文科技期刊数据库等,以数字化方式复制、汇编、发行、信息网络传播本刊全文.该著作权使用费及相关稿酬,本刊均用于为作者文章发表、出版、推广交流(含信息网络)以及赠送样刊等用途,不再另行向作者支付.凡作者向本刊提交文章发表之行为即视为同意我刊上述声明.
河南教育学院学报编辑部
Fast Cluster of Partial Duplicate Images
WANG Guo-an1,2, GUO Xin1
(1.CollegeofComputerandInformationEngineering,HenanUniversity,Kaifeng475004,China;
2.NetworkInformationCenterOffice,HenanUniversity,Kaifeng475004,China)
Abstract:A method came up which finds clusters of partial duplicate images. The main idea relies on the Min-Hash algorithm for fast detection of pairs of images with spatial partial overlap. The probability of finding a seed for an image cluster rapidly increases with the size of the cluster. After that a RANSAC spatial consistency test will be passed. The properties and performance of the algorithm are demonstrated on data sets with 104,105, and 5×106images. The speed of the method depends on the size of the database and the number of clusters.
Key words:min-hash; bag of visual word; image clustering; partial duplicate images; data mining
中图分类号:TP391.4
文献标识码:A
文章编号:1007-0834(2015)02-0023-07
doi:10.3969/j.issn.1007-0834.2015.02.007
作者简介:汪国安(1957—),男,河南新蔡人,河南大学计算机与信息工程学院、网络信息中心教授,主要研究方向:计算机视觉与模式识别.
收稿日期:2015-03-01
猜你喜欢
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
中国交通信息化(2020年1期)2020-07-27
电力与能源(2017年6期)2017-05-14
中国中医药信息杂志(2016年7期)2016-12-01
现代电子技术(2016年15期)2016-12-01
信息通信技术(2015年6期)2015-12-26
西安工程大学学报(2014年2期)2014-02-28
电子设计工程(2014年18期)2014-02-27
电子设计工程(2014年18期)2014-02-27
