
一种基于内容的新闻推荐系统实例
2015-12-08 11:51代晨旭周熙晨
电脑知识与技术 2015年25期
代晨旭++周熙晨
摘要:互联网的飞速发展产生了"信息过载"问题,新闻数量的爆炸性增长使得读者受到“信息迷航”问题的困扰。为解决这一问题新闻推荐系统应运而生。文章针对该系统的关键部分即新闻特征值提取和用户画像做了深入的研究。采用了TFIDF进行新闻分词及特征值提取,将新闻用空间向量模型表示并利用PU Learning来解决用户画像时负反馈数据难以得到的问题。最后以实例证明了该方法的可行性。
关键词:推荐系统;词频-逆文档概率;用户画像;负反馈数据;PU学习
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)25-0036-03
An Instance of a Content-based News Recommendation System
DAI Chen-xu, ZHOU Xi-chen
(School of Information Engineering, North China University of Science and Technology, Tangshan 063009, China)
Abstract: The development of the Internet is always followed by several issues, such as Information overload and ‘information lost. Those issues bother Internet users among daily lives due to huge numbers of information, as so called ‘information explosion. In order to solve the problem, news recommendation system appeared. It makes a deep research on the key parts, extract of News feature value and User portrait, of the system. TFIDF is used to extract news words and feature extraction, using spatial vector model of news, and Learning PU is used to solve the problem of negative feedback data is difficult to be obtained in user portrait. Finally, the feasibility of the method is demonstrated by an example.
Key words: recommended system; TF-IDF; user portrait ; negative feedback data ; PU learning
随着网络信息量的爆炸性增长,推荐系统成为研究热点,个性化新闻推荐得到了人们的重视,个性化新闻推荐系统纷纷出现。目前比较主流推荐算法有基于协同过滤的推荐和基于内容的推荐[1]等。由于协同过滤是根据用户对新闻的访问记录来进行推荐的,只有被阅读过的新闻才能被推荐,然而新闻的生命周期十分短暂,用户的访问矩阵会相当稀疏,这对于时效性要求比较高的新闻推荐系统是相当严重缺陷,所以采用基于内容的推荐。
基于内容推荐,对分别对新闻和用户建模,然后把与用户历史上阅读的新闻相似的新闻推荐给用户。一般来说新闻和用户建模有两种方式:向量空间模型和浅层语义模型。向量空间模型有词袋模型和词频-逆文档概率TFIDF (Term Frequency Invert Document Frequency),浅层语义模型有概率潜在语义索引PLSI (Probabilistic Latent Semantic Indexing)和潜在狄利克雷分布LDA(Latent Dirichlet Allocation)。
1 关键技术
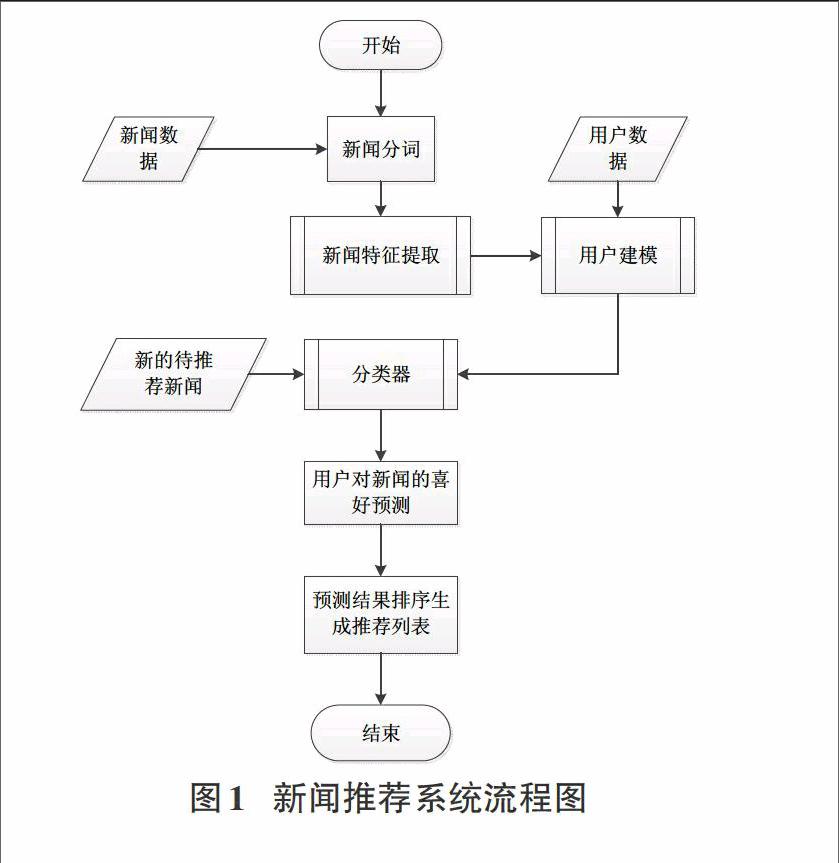
基于内容的推荐方法一般包括以下三步:
1)新闻特征提取:在新闻的内容中抽取一些特征,用于结构化表示新闻;
2)用户画像:即用户建模,利用一个用户过去喜欢(及不喜欢)的新闻的特征数据,来学习出此用户的喜好特征;
3)推荐生成:通过计算前面得到的用户画像与候选新闻的特征相似度,为此用户推荐一组用户喜好最相近的新闻。
新闻系统流程如图1所示:
1.1 新闻特征提取
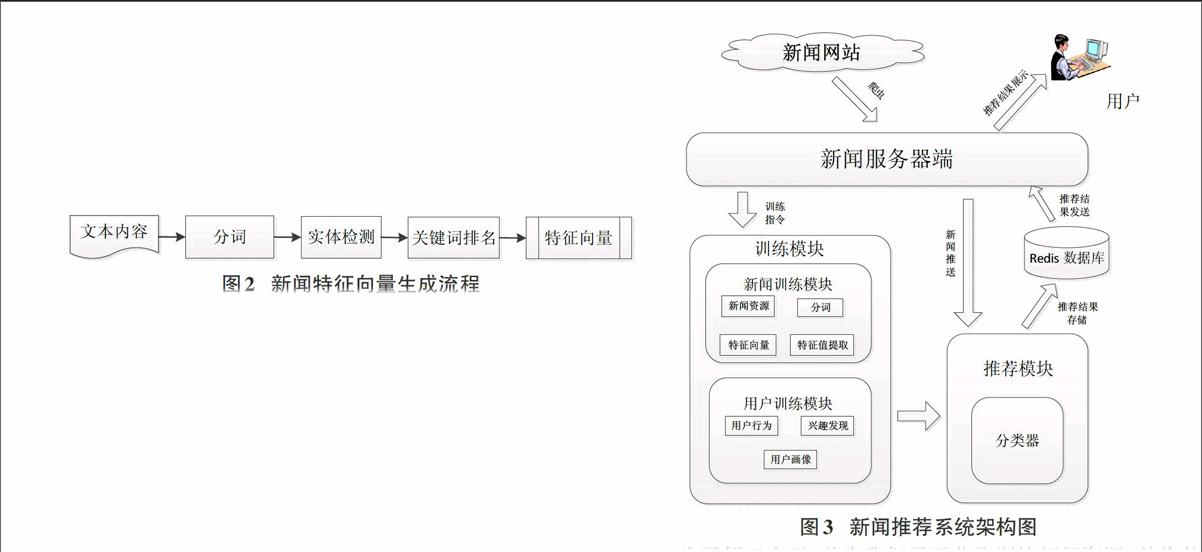
大多数的基于内容的推荐系统在处理文字类item特征时,都会尝试将一篇文章映射到量空间模型VSM(Vector Space Model),在模型中,每一篇文章都被表示为一个n维的向量,每一维都对应词典中的一个词,这时文章会被表示成为一个包含每个词的权重的向量。新闻特征向量生成流程如图2所示。
图2 新闻特征向量生成流程
为了得到新闻的特征值,首先要对新闻进行分词处理,将其划分成若干词条的组合。将新闻表示为向量空间模型带来了两个问题,即每个词的权重和向量之间的相似度计算,词频-逆文档概率TFIDF[2] 被普遍用在处理各种自然语言的应用中来解决这个问题。
1.2 用户画像学习
学习一个用户画像就是为用户建模,在这里它可以被看作一个二值分类过程,每一个文本都被分类为喜欢和不喜欢。因此,我们有了一个分类记号[C={c+,c-}] ,其中[c+]表示的是正例文本类,[c-]表示的是负例文本类。我们利用用户对新闻的历史数据对新闻画像。
如果我们拥有用户的显式反馈,那传统的监督学习方法就能应付,但是往往用户不会提供很多显示反馈,如何使用隐式反馈来做推荐是基于内容的推荐系统的难题,半监督学习在被Bing Liu等[4]发明出来用以在仅有隐式反馈时对数据进行训练。
PU Learning是一系列的概率推导,首先要生成合理的负数据,然后用这些负数据进行分类。有很多生成负数据的方法,如从无标注数据中随机的选取一些作为负数据,基于此构建分类器,如果负数据选择的足够随机,得到的效果往往都不错。其中最有名的方法是SPY间谍算法,该方法将正数据中的很小一部分当作负数据来做分类,在这样的数据上应用一些常见的分类器,将无标注的数据进行分类。最后通过比较设定阈值来得到负数据,本系统采用SPY算法。
1.3 推荐生成
推荐是应用用户画像中得到的分类器应用到未知新闻的过程。通过将用户兴趣预测值高于某一阈值的新闻推荐给用户就可以达到很好的效果。
2 系统设计
2.1 系统架构
为了让新闻推荐系统处理其复杂的流程,本系统需要被设计成多个子模块用于处理不同的事务。主要分为三个模块,训练模块、推荐模块和服务器模块。系统的模块化架构如图3所示。
为了便于实现,首先我们需要获取训练新闻资源,并将其存放到新闻服务器端。然后,训练模块从新闻服务器端获取训练指令,开始其训练周期。训练中需要调用内部的新闻训练模块和用户训练模块。
新闻训练模块需要将读取新闻串,构建新闻字典,完成对新闻的分词,转化到词袋模型,利用TFIDF转化到TagSpace,最后利用SVD 矩阵分解完成特征向量转化。用户训练模块需要将用户的数据根据历史浏览新闻数据构建出用户矩阵。根据用户矩阵进行训练,构建出分类器,该分类器被用于推荐模块给用户进行推荐。
推荐模块需要及时和新闻服务器进行交互,与服务器的交互模块利用的是socket编程,为推荐模块和训练模块分别创建一个socket,等待新闻服务器与其通信。
新闻服务器将采集的待推荐新闻交递给推荐模块。推荐模块利用训练模块准备好的分类器对用户进行推荐并把推荐结果存放到Redis数据库,Redis数据库将推荐结构反馈到新闻服务器端,新闻服务器端根据此给客户端以反馈。
2.2 推荐结果
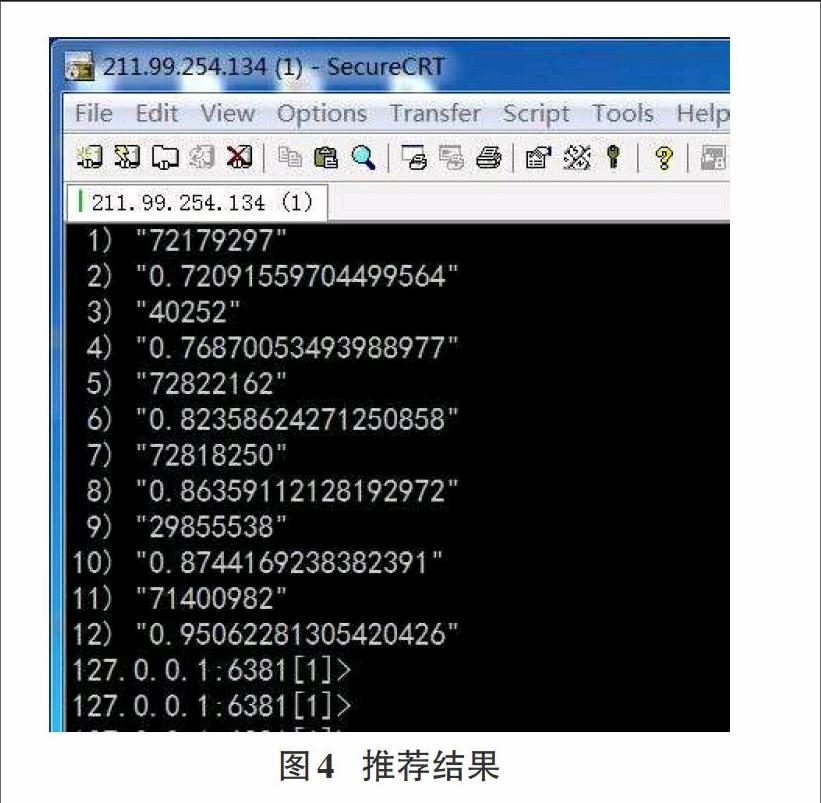
推荐模块需要从新闻服务器那里获取数据,训练模块那里获取分类器,使用分类器对新闻数据进行预测。在该模块中需要处理的问题是将训练结果的矩阵数据转化成新闻服务器可用的推荐结果。
用系统实现将用户兴趣度大于阈值0.7的新闻推荐给用户,推荐结果如图4:
3 结束语
本系统以Cent OS 5.5为运行平台,使用Python实现系统。除此之外,为了提高系统的实时性,我们使用的redis内存数据库实现数据存储。
系统对基于内容的新闻推荐系统的关键技术及系统架构进行研究,并以Cent OS 5.5为运行平台,使用Python语言实现了一种新的基于内容的新闻推荐系统实例,证明了该方案的可靠性。为新闻推荐系统的研究工作,提供了一定的帮助。
参考文献:
[1] 张宜浩. 基于半监督学习的个性化推荐研究[D]. 重庆: 重庆大学, 2014.
[2] Juan Ramos. Using TF-IDF to Determine Word Relevance in Documents Queries[M]. Industrial Practice and Experience, 2001: 1-16.
[3] Salton G, McGill M J. Introduction to Modern Information Retrieval[M].NewYork: McGraw Hill, 1983: 147.
[4] Bing Liu. Web Data Mining, Exploring Hyperlinks, Contents, and Usage Data[M].2nd ed. Springer, 2010: 56-321.
猜你喜欢
园林科技(2021年3期)2022-01-19
中国广播(2017年1期)2017-02-21
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
现代情报(2016年10期)2016-12-15
电脑知识与技术(2016年25期)2016-11-16
现代经济信息(2016年24期)2016-11-09
电脑知识与技术(2016年7期)2016-05-19
读者·校园版(2015年7期)2015-05-14
