
制造物联网中高吞吐率复杂事件检测技术研究*
2015-12-07 06:54李幸斌程良伦
传感器与微系统 2015年9期
李幸斌,程良伦
(广东工业大学计算机学院,广东广州510006)
0 引言
制造业物联网中,提高流数据处理的吞吐率具有重要意义。对流处理的研究已经有很多,最开始的流处理方式是流数据库[1],它们以数据存储为中心,提供丰富的查询语言,然而这种事件处理的方式,由于要先将数据存入数据库再取出,效率非常低。比较典型的流式数据库有:以开源数据库PostgreSQL[2]为基础,通过体系结构改造以支持连续查询的TelegraphCQ[3]以及提供历史查询功能的Truviso[4]。之后出现了一些流处理系统,经典的有 STREAM[5],Aurora以及 PIPES[6]等。它们的共同特点是都采用了发布/订阅模式,优点是提高了处理速度,主要的缺点是查询语言的表现力有限,只能执行简单的选择操作。数据流处理系统通常是分布式和高度并行的,尽管数据流处理系统查询的效率很高,但它们不能处理多个事件模式的查询,因此,不适合处理制造业物联网中复杂多源的原始数据。
最近提出了一些基于主动数据库技术的新的流处理系统,被称之为复杂事件处理(以下简称CEP)。现有CEP项目有 SASE,SASE+[7]和 Cayuga[8]等。SASE 系统采用了基于本地序列操作符和管道查询的数据流模型,使用关系运算符来定义随后到来的序列。在SASE中,一个查询被转化为一个非确定有穷自动机,非确定有穷自动机的每一个状态有一个相应的活动实例栈保存匹配的事件。当一个事件到达时,如果它匹配转换条件,就将它压入到合适的活动实例栈中。如果事件到达接受状态,活动实例栈中的事件都被退栈了,并且模式匹配构造被执行完成,则模式匹配完成。与许多其他系统不同,SASE不仅会报告用户感兴趣的查询结果,而且会报告匹配此查询的所有事件,这在很大程度上增加了查询处理的复杂度。SASE的主要局限性在于不能处理层状结构的复杂事件类型,即一个查询的结果不能用作另一个查询的输入。康奈尔开发的Cayuga弥补了这个不足。Cayuga使用了传统的发布/订阅技术,因此,它支持大量并发的订阅事件。Cayuga引擎使用单线程读取数据和利用自动机处理数据。自动机允许对输入数据进行存储,这使得新的输入可以与先前存储的事件做比较。Cayuga还使用了类似流水线的处理模型,该模型需要每个查询结果实时输出给下个处理过程使用。另外,Cayuga中采用了查询优化技术,将多个拥有相同时间戳的具有等价状态的事件一起处理。然而,由于它的内核是单线程的,这些优化技术并没有显著提高Cayuga的性能,难以满足制造物联网中对事件流的实时响应需求。
本文提出聚集活动实例栈中的连接,并批量执行序列构造的方法来提高CEP查询的吞吐率。仿真实验结果表明:该方法有效的提高了复杂事件处理的吞吐率。
1 SASE
首先解释一下SASE中CEP的处理过程。本文假设窗口的大小是9,查询模式是“SEQ(A,B,D)”,输入事件序列如下

其中,第一个字母表示事件类型,第二个字符表示到达的时间。例如:“c2”表示事件类型为“C”,时间戳为“2”。“SEQ(A,B,D)”表明B在A的后面。本文遵循“跳过直到匹配”的策略[1,2],因此,A 和B 之间的事件、B 和 D 之间的事件会被忽略。所以,从上面事件中获取的结果是(a1,b3,d5)。
下面描述SASE中输入事件如何被处理到接收状态:
1)查询转化为NFA。
2)每一个NFA都会有一个相应的AIS,AISs存储事件匹配的状态,当一个事件输入到NFA,如果它转换到其他状态而不是当前状态,则将这个事件将被压入到AIS。
3)当NFA到达接受状态时,它使用连接构造模式匹配序列。
4)在完成模式匹配序列构造之后,调用模式匹配序列构造的事件将从接受状态的AIS中删除。之后将重复步骤(2)~ (4)。
根据上面的描述,可以简明地描述SASE中NFA的行为:它首先接收一个事件,然后,如果事件引起状态转换,NFA压入事件到一个合适的AIS,然后创建一个从当前事件到之前AIS中事件的连接。如果NFA到了接受状态,模式匹配构造器被触发,将生成匹配序列。用算法1描述过程如下:
算法1
1:Wait for an event;
2:Receive an event e;
3:IF(e does not invoke state transition)
4:Go to line 1;
5:ENDIF
6:Invoke state transition and push e onto appropriate AIS;
7:Create a link from e to an event in the previous stack;
8:IF(current state is acceptance state)
9:Construct pattern occurrences using links originated from e;
10:Delete e and its link;
11:ENDIF
12:Drop events in the outside of window from all AISs;
13:Go to line 1.
2 建议的方法
观察算法1,将发现算法的第8~11行有一个潜在的瓶颈:模式匹配序列构造处理需要花费长时间。因此,如果减少模式匹配序列的构造花费,就可以获得高的吞吐率。在本文中,提出了聚集AISs中的连接,批量执行模式匹配序列构造的方法。因为聚集连接减少了检索连接的花费,它将加快查询处理。下面,解释这种方法如何进行“SEQ(A,B,D)”查询。窗口的大小同样设为9,输入事件如下

下面一步一步描述本文提出的方法:
1)一个事件输入NFA,如果它引起状态转换,将事件压入下一状态的AIS,然后创建一个连接到这个事件。连接的目的事件的时间戳必须小于源事件的时间戳,目的事件必须是满足条件的事件中时间戳最大的。
2)有相同连接(RIP)的事件被聚集并打包成一个簇:在这个例子中,“d7”和“d9”有相同的连接,因此,这两个连接打包到一个簇。
3)从连接中检测是否发生模式匹配:在本例中,d7连接的目的事件是b3和b6.d9连接的目的事件与d7相同。因此,模式匹配构造只被执行1次,在SASE中将被执行2次。在NFA达到接受状态时,本文的方法并没有调用模式匹配序列构造器,而是批量执行模式匹配序列构造。在本例中,将构造以下模式匹配序列:〈a1,b3,d5〉,〈a1,b3,d7〉,〈a1,b6,d7〉,〈a4,b6,d7〉,〈a1,b3,d9〉,〈a1,b6,d9〉,和〈a4,b6,d9〉。
4)删除接收状态的AISs中的事件:“d9”之后生成的事件,不满足目的事件的时间戳需大于源事件的时间戳的连接条件。因此,d5,d7,d9是非必需事件,删除它们。
5)删除过期事件:窗口之外的事件将过期,因为窗口的大小是9,例如:最后的事件是“d9”,当下一个事件到来时,“a1”就过期了,需要删除“a1”。之后,回到步骤(1)继续执行。用算法2描述过程如下:
算法2
1:Wait for an event;
2:Receive an event e;
3:IF(current time step%window size is 0)
4:Construct pattern occurrences using links originated from events in the AISfor acceptance state;
5:Delete expired events from all the AISs;
6:Go to line 1;
7:ENDIF
8:IF(e does not invoke state transition)
9:Go to line 1;
10:ENDIF
11:Invoke state transition and push e onto appropriate AIS;
12:IF(link destination of e already exists for e')
13:Merge e and e'and pack them as a cluster;
14:ELSE
15:Create a link from e to an event in the previous stack;
16:ENDIF
17:Go to line 1.
与SASE不同的是,本文的方法在接收状态的AIS上压入事件时,可能不执行模式匹配构造,而是批量构建模式匹配序列,如算法2中3~7行所述。为了减少批量构造的代价,聚集连接成簇,如算法2中12~14行所述。
3 性能分析
为了验证本文方法的有效性,下面比较了本文的方法和SASE中的传统方法的吞吐率(计算两种方法处理多个事件的时间,然后计算每秒的吞吐率)。实验操作系统为Windows XP Professional;内存为3GB;CPU为Intel Core2Duo E8400;编程语言为Java(JRE 1.7.0_04)。
在实验中,事件数设置为10 000,窗口大小从500~1000进行改变,使用四种类型的事件:A,B,C,D。通过随机数生成器对4取模实现四种类型事件发生的可能性都是25%。使用的查询语句为:“SEQ(A,B,D)”和“SEQ(A,B,D,C)”。
图1是查询“SEQ(A,B,D)”的实验结果。由图可见所提出的方法的吞吐率高于传统方法。最小的性能提高是窗口大小为500时,吞吐率为传统方法的1.097倍;另一方面,当窗口大小为1000时,获得最大的吞吐率,此时是传统方法的1.551倍。

图1 SEQ(A,B,D)的结果Fig 1 Result of SEQ(A,B,D)
随着窗口大小的增大,本文提出的方法和传统的方法的吞吐率都减少了。这是因为随着窗口大小的增大,给了足够的时间使模式匹配发生,从而使模式匹配发生的数量增加。因此,长的窗口趋向于生成更多的模式匹配序列,显然,这需要更多的资源,从而使处理新事件的模块的执行机会减少了,吞吐率就下降了。
图2是查询“SEQ(A,B,D,C)”的实验结果。它的吞吐率低于查询“SEQ(A,B,D)”。最小的性能提高是在窗口大小为1000时,提高了1.55倍。在窗口大小为700时,获得最大的性能提升,达到了1.62倍。
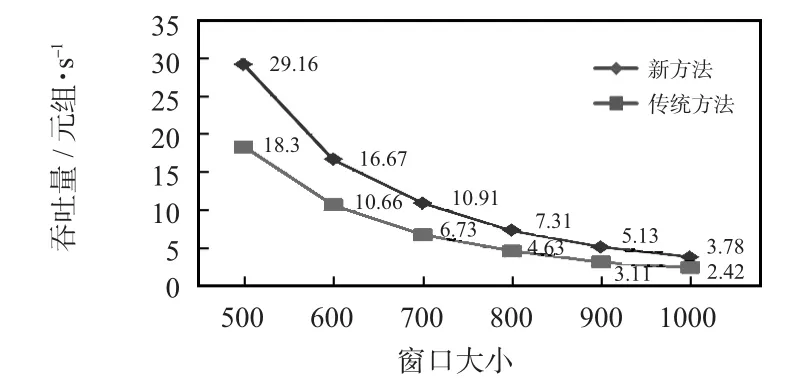
图2 SEQ(A,B,D,C)的结果Fig 2 Result of SEQ(A,B,D,C)
与查询“SEQ(A,B,D)”相比,查询“SEQ(A,B,D,C)”吞吐率低的原因为:查询“SEQ(A,B,D,C)”的 AISs中的事件数量更多,遍历连接的时间更长,模式匹配序列构造的花销更大。查询“SEQ(A,B,D,C)”对应的 NFA的结点数为4,这比之前的查询高出了25%,导致了性能的巨大下降。
模式匹配发生数随窗口大小的变化如图3,可见模式匹配发生数正比于模式的长度和窗口的大小。因此,吞吐率反比于窗口大小和模式的长度。

图3 吞吐率随窗口的变化Fig 3 Change of output with window size
采用查询“SEQ(A,B,D)”衡量聚集连接的有效性。输入下面的事件作为一个分簇无效的例子,它没有生成簇
a1,b2,d3,b4,d5,a6,b7,d8,b9,d10,….另外,输入一个分簇有效的例子
a1,b2,b3,b4,d5,d6,d7,d8,d9,d10,a11,….
所有“D”类型的事件都在窗口中被分簇。图4展示了分簇无效的仿真结果。图5展现了分簇有效的仿真结果,在最好的时候达到了5.24倍(此时的窗口大小为1000)的性能提升。
4 结论
本文提出了一种通过聚集连接来提高CEP查询吞吐率的方法。在分簇有效的情况下,本文的方法相比于SASE,达到了5.24倍的性能提升,这证明了聚集连接对提高吞吐率的有效性。由此得出结论:本文提出的聚集连接的方法对提高CEP查询的吞吐率是有效的。

图4 分簇无效的仿真结果Fig 4 Simulation result of ineffective clustering

图5 分簇有效的仿真结果Fig 5 Simulation result of effective clustering
[1]Wu E,Diao Y,Rizvi S.High-performance complex event processing over streams[C]∥Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data,ACM,2006:407-418.
[2]Arasu A,Babu S,Widom J.The CQL continuous query language:Semantic foundations and query execution[J].The VLDB Journal—The International Journal on Very Large Data Bases,2006,15(2):121-142.
[3]Chandrasekaran S,Cooper O,Deshpande A,et al.TelegraphCQ:Continuous dataflow processing[C]∥Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data,ACM,2003:668-668.
[4]Chen J,DeWitt DJ,Tian F,et al.NiagaraCQ:A scalable continuous query system for Internet databases[C]∥ACM SIGMOD Record,ACM,2000:379-390.
[5]Abadi D J,Carney D,etintemel U,et al.Aurora:A new model and architecture for data stream management[J].The VLDB Journal—The International Journal on Very Large Data Bases,2003,12(2):120-139.
[6]Motwani R,Widom J,Arasu A,et al.Query processing,resource management,and approximation in a data stream management system[C]∥CIDR 2003,Stanford Info Lab,2002.
[7]Diao Y,Immerman N,Gyllstrom D.SASE+:An agile language for kleene closure over event streams[J/OL].[2012—12—23].http:∥archive,systems,ethz.ch/www,dbis.ethz.ch/education/ws0708/adv_top_infsyst/papers/sase_tr07,pdf,2007.
[8]Demers A J,Gehrke J,Panda B,et al.Cayuga:A general purpose event monitoring system[C]∥International Conference on Innovation Database Research,Online Proceedings,2007:412-422.
猜你喜欢
电子制作(2019年13期)2020-01-14
小学生作文(低年级适用)(2019年5期)2019-07-26
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
读友·少年文学(清雅版)(2018年12期)2018-04-04
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
山东青年(2016年3期)2016-02-28
财经(2016年6期)2016-02-24
