
基于动态规划的云计算虚拟机簇聚类方法
2015-12-06 09:33:30祝衍军
图学学报 2015年6期
祝衍军
(东莞职业技术学院计算机工程系,广东 东莞 523808)
基于动态规划的云计算虚拟机簇聚类方法
祝衍军
(东莞职业技术学院计算机工程系,广东 东莞 523808)
多虚拟机聚簇的快速高效实现,对于云数据处理能力的提升具有重要意义。基于虚拟机聚簇的一般原理,引入动态规划全局优化策略,构建一种新的虚拟机聚簇方法。首先根据预设的虚拟机属性判别函数,对虚拟机资源执行升序排列;进而选取升序集合中心位置的虚拟机作为聚簇起点,根据动态规划策略从两个方向开始进行聚簇;聚簇的原则本着全局聚簇最优的动态规划准则。实验结果表明,基于动态规划的虚拟机聚簇方法,聚簇速度快,聚簇效果稳定。
虚拟机;聚簇;云计算;动态规划
随着信息技术和大数据处理技术的飞速发展,人们对于信息处理和数据处理的要求越来越高,这也直接导致了计算任务的复杂度和难度不断攀升[1]。在这种情况下,个人终端的计算资源很难独立解决计算任务,抑或需要花费更大的成本来完成计算任务。为了解决上述问题,科学家们提出了云计算模型和云服务技术。云计算模式,是在分布模式、并行模式、网格模式之后的又一种新型计算模式,其信息处理能力相比于以往获得了空前提高。云端服务器不仅硬件配置好,软件功能强大,而且整合了网络间各种可以利用的计算资源,可以解决个人终端无法解决的复杂计算任务[2]。
为了提高云计算的效率和云服务的质量,研究者构建了虚拟化技术。通过虚拟化处理,一台真实的服务器被动态分割成多个虚拟服务器[3]。虚拟机模式的构建,不仅大大降低了云端计算资源的管理难度,也大大提升了云端计算资源的利用效率,这对于快速高效地解决用户的计算任务具有重要意义[4]。也正因为如此,云计算领域近年来出现了大量有关虚拟机部署的研究成果。李强等[5]指出,启发式的搜索方法对于虚拟机部署是比较合适的,因为其有利于云端全局优化的实现。何东晓等[6]认为,虚拟机的调度应该综合考虑多方面的原因,尤其是用户的需求和云内计算资源的利用情况,并为此构建了一种基于多要素聚类的虚拟机调度方案。刘进军和赵生慧[7]的研究结论显示,物理服务器上的负载状况对于虚拟机资源的分配有着重要影响,基于服务器负载去构建虚拟机调度策略才能真正提高云端的计算效率。王光波等[8]针对云计算中虚拟机部署问题,提出了一种基于架构负载感知的虚拟机聚簇部署算法。
大量的虚拟机调度和部署方面的研究成果,极大地推动了云计算技术走向成熟。当前,一个新的热点研究就是从单个虚拟机资源的部署转变到包含多个虚拟机资源的虚拟机簇的部署[9-10]。本文将在过程研究成果的基础上,借助全局优化算法中的动态规划方法,对虚拟机簇的部署问题展开研究。
1 虚拟机簇和云计算整体架构
为了便于明确本文研究在云计算领域中的位置,以及明确本文的核心研究内容,先对虚拟机簇的概念以及云计算任务配置的整体架构进行阐述[11-12]。
簇,本身就带有集合的含义[13]。所以,虚拟机簇实际上就是多个虚拟机构成的集合。当然,能够进入一个虚拟机簇的虚拟机,彼此之间应该有着某种联系,或者同时符合了进入该虚拟机簇的条件。虚拟机簇的聚集和部署,必然要依赖构成云的硬件架构。在一个云端的数据处理过程中,参与进来的硬件资源包括:服务器主机、刀片中心、机架,数据中心等,这些硬件资源按照处理能力和在云端所处位置的差异,一般分属于不同的层次,其结构如图1所示。
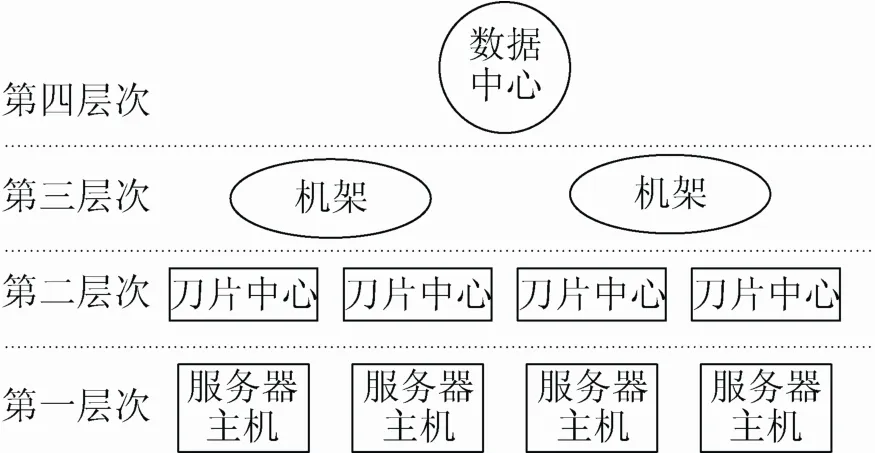
图1 云数据处理的硬件架构
在图 1中,云数据处理的硬件架构被分为 4个层次,每个层次中硬件设备的数量是不固定的。虚拟机的聚簇和部署要根据任务的实际需要,分别部署在服务器主机上、刀片中心上、机架上、及数据中心上,无论在哪个层次上部署,虚拟机必须达成和硬件资源的匹配。
2 基于动态规划的虚拟机聚簇方法
实际上,为了提高云数据处理的效率和提高云端的服务质量,如何将性能近似的虚拟机资源聚集在一起并和硬件资源实现协调的配置是关键,这本身是一个云端计算资源的全局优化问题。为此,本文将一种全局优化理论应用于云端的虚拟机聚簇之中,提出了基于动态规划的虚拟机聚簇方法。
2.1动态规划理论
动态规划全局优化理论,是典型的将复杂问题拆解并通过多个阶段决策来实现的方法。对于拆解的各个阶段,用变量k表示,对应于第k个阶段的状态可用变量 xk表示。每执行一个阶段的优化,整个系统的状态就会发生一次改变,决定系统状态如何向下一阶段改变的策略称之为决策,用变量 uk表示。这样,一个系统实现全局优化的问题就变成了一个系统全部阶段状态转换的判断准则设计问题,对应会形成一个全局优化函数,即:
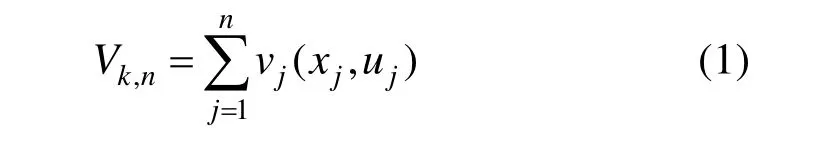
其中,n代表系统执行全部过程可以拆分的阶段总数; vj表示每一个阶段的判断准则函数;Vk,n表示全局判断准则函数。
动态规划全局优化理论,具有一个重要特点,就是根据全局优化策略判断当前状态的决策以后,后续状态不再受当前状态的影响,这也是动态规划理论中典型的无后效性。动态规划的准则函数具有可分性,即:
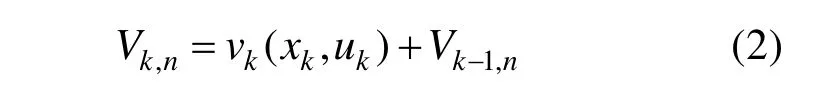
2.2虚拟机聚簇
要解决云数据处理中的虚拟机聚簇问题,就需要依托虚拟机的各种属性和状态,构建有针对性地动态规划全局优化函数。因为聚簇问题,就是要寻找各方面属性接近的虚拟机构成一个集合,以便为同类问题服务。所以,先对云处理系统中可用的虚拟机进行排序,其排序是根据各个虚拟机属性差异最小的原则进行的。据此,为每个虚拟机构建一个如下的性能判断函数,即:
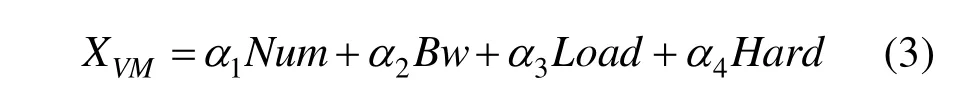
其中,Num表示与此虚拟机通信的其他虚拟机数目;Bw表示此虚拟机需要的带宽总量;Load表示此虚拟机已经承担的负载情况;Hard表示此虚拟机和服务器主机等硬件设施进行匹配时所需的硬件资源;αi表示每一种子属性在总属性之中的权重。
Bw的计算为:
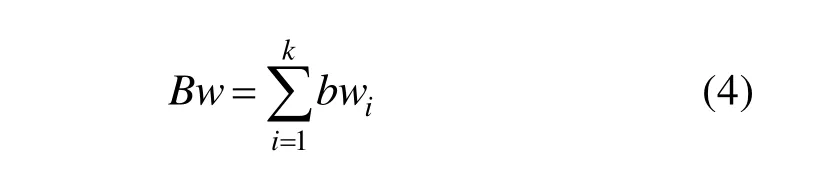
其中,bwi表示第i个和此虚拟机通信信道所需的带宽;k表示与此虚拟机联系的所有其他虚拟机的数目。
Hard的计算为:
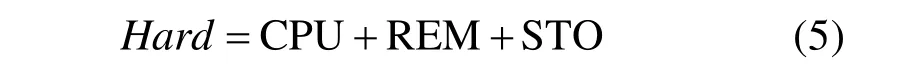
其中,CPU表示此虚拟机需要硬件匹配的 CPU主频高低;REM表示此虚拟机需要硬件匹配的内存大小;STO表示此虚拟机需要硬件匹配的硬盘大小。
根据式(3)所构建的排序判断公式,云端所有可以利用的虚拟机资源就可以按照属性差异的大小进行一个升序的排列,从而形成一个按顺序排列的虚拟机属性集合
依托动态优化全局优化策略实现虚拟机聚簇,其核心思路就是从中寻找处于中间位置的虚拟机,然后逐渐向两端搜索与其各方面差异最小的虚拟机聚集成簇。这个决策函数为:
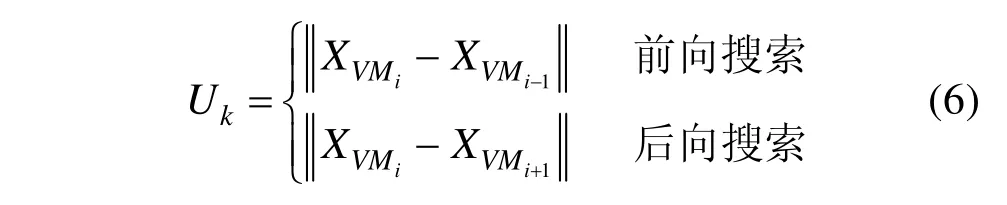
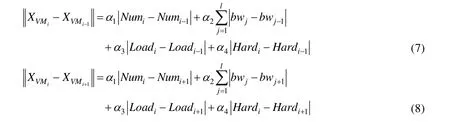
至此,构建出依托于动态规划全局优化策略的虚拟机聚簇判断准则函数,即:
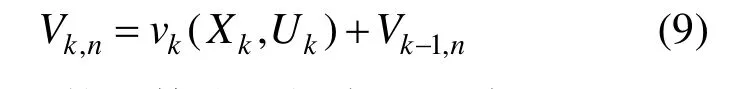
其中,Xk和Uk的计算分别如式(3)和式(6)。
2.3虚拟机聚簇算法的流程
基于动态规划全局优化的虚拟机聚簇算法的基本流程如图2所示,具体步骤如下:
步骤 1. 设置虚拟机属性判断函数,如式(3)所示,计算云端可利用的每一个虚拟机属性。
步骤2. 对云端所有可以利用的虚拟机,按照属性高低进行升序排列。
步骤3. 构建用于聚簇判断的动态规划全局优化函数。
步骤4. 选择升序集合中处于中间位置的虚拟机,作为聚簇的起始位置。
步骤5. 执行动态规划优化的聚簇处理,从两个方向判断临近虚拟机是否符合聚簇条件。满足聚簇条件的,将临近虚拟机设置为下一阶段判断的起始位置,继续执行聚簇判断。不满足聚簇条件的,将临近虚拟机纳入候选虚拟机集合,继续判断下一个虚拟机是否满足聚簇条件。
步骤6. 不断更新虚拟机的状态,重复步骤5,直到升序集合和候选集合中的所有虚拟机都执行了聚簇判断。
步骤7. 将形成聚簇的虚拟机归并为一个簇,用于后续和硬件资源的匹配。没有纳入此簇的其他虚拟机,可以重新执行一个新的聚簇处理,或留用待命。
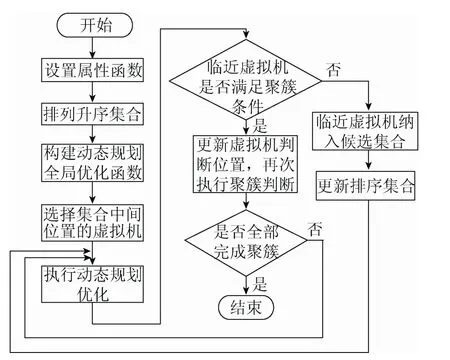
图2 虚拟机聚簇算法流程
3 实验结果与分析
通过如下的实验过程验证本文提出的虚拟机聚簇方法的有效性。实验仿真平台选用云计算性能测试常用的软件CloudSim。在CloudSim平台下,云数据处理硬件结构的数据中心,主要依托于采取的机架数目。以一个机架配置 8个刀片中心、一个刀片中心配置16台服务器主机的模式设置。一个数据中心下的服务器主机数量就是 128个,两个数据中心下的服务器主机数量就是256个,3个数据中心下的服务器主机数量就是 512个,以此类推。在虚拟机的设置方面,设置10种类型的虚拟机,其CPU主频、内存、硬盘等硬件的匹配需求,如表1所示。
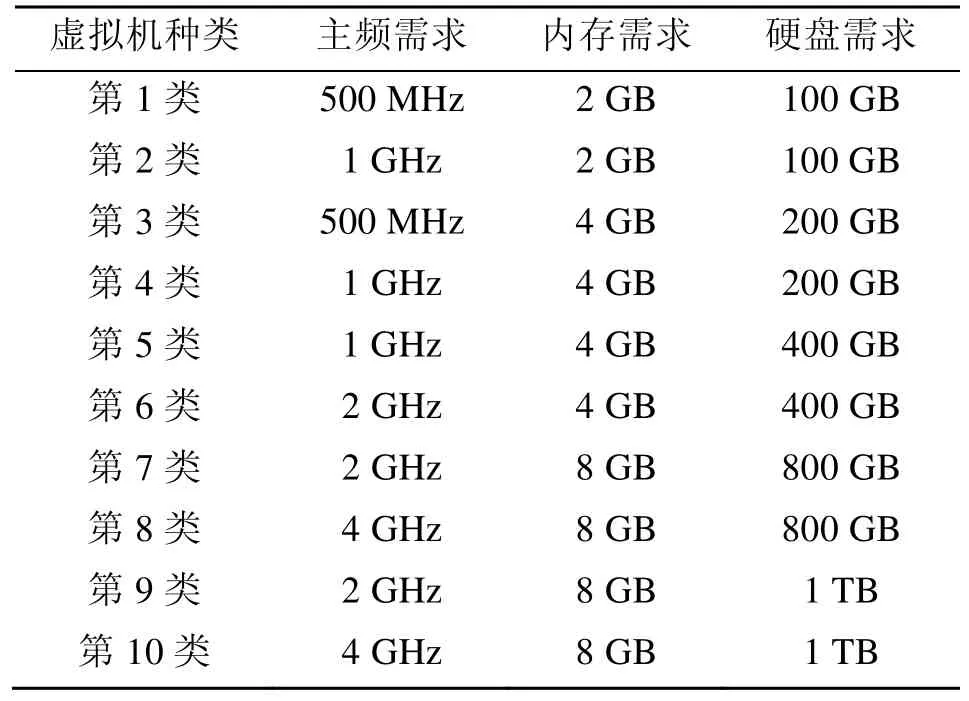
表1 虚拟机的设置
虚拟机和其他虚拟机通信的带宽需求以及虚拟机上的实际负载情况,是根据系统设置的随机指令更替系统而随机发生变化的,以模拟云端实际虚拟机的使用情况。这种随机变化,也就为后续的动态规划聚簇提供了可以判别的依据。对应于硬件资源,每一个数据中心配置500个虚拟机,500个虚拟机都按照表1的方式分为10类,每类50个虚拟机。
分别按照Greedy算法、启发式算法、本文提出的动态规划聚簇方法执行虚拟机的聚簇处理,考察这 3种方法形成聚簇效果的时间差异,结果如图3所示。
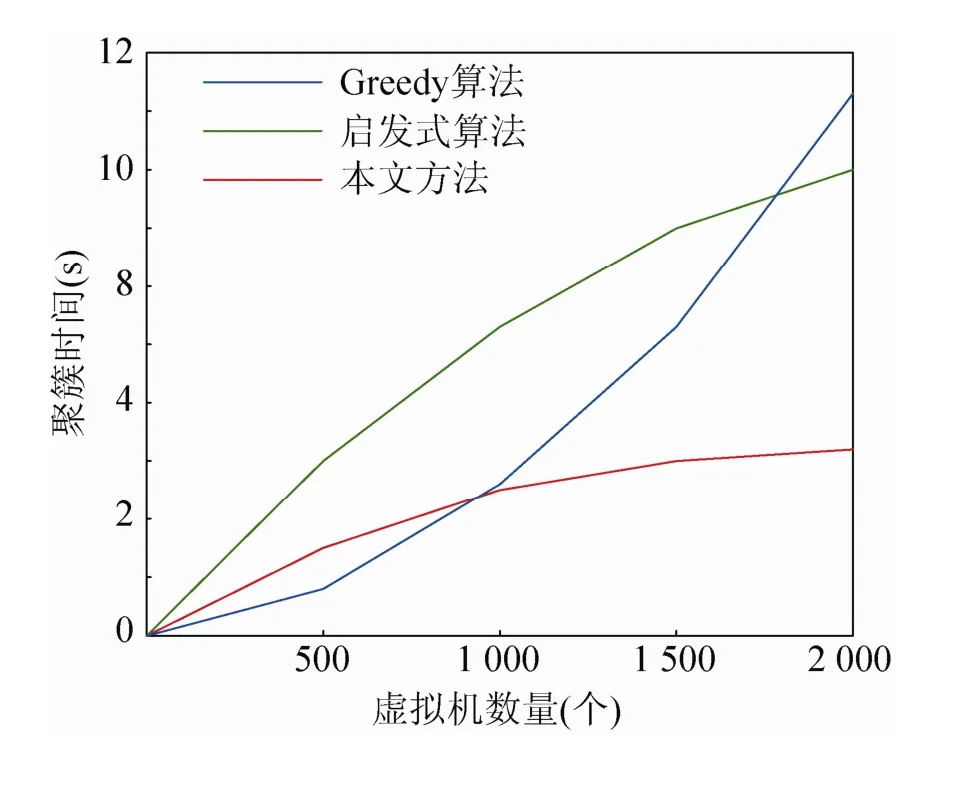
图3 三种方法的聚簇时间对比
从图 3中可以看出,本文方法和启发式方法的聚簇时间都是增加幅度由快变慢,且本文方法在聚簇的绝对时间上明显偏低,实现2 000个虚拟机的聚簇,仅仅花费了3.2 s,而启发式方法则花费了近10 s。Greedy聚簇算法虽然起初的聚簇时间较低,但之后增长趋势越来越明显,实现2 000个虚拟机的聚簇,时间消耗达到了11.3 s。可见,3种方法的聚簇时间对比,明显证实了本文方法的聚簇速度更快。
聚簇对云数据处理效率的提升是否有益,一般通过跳数来进行衡量。如果聚簇合理,虚拟机之间的通信就会相对稳定,跳变发生的次数少,跳数也偏低,这有利于云数据高效处理。反之,跳数越高,聚簇越不稳定,云数据处理的效率也就会大大降低。3种方法聚簇后的跳数比对如图4所示。
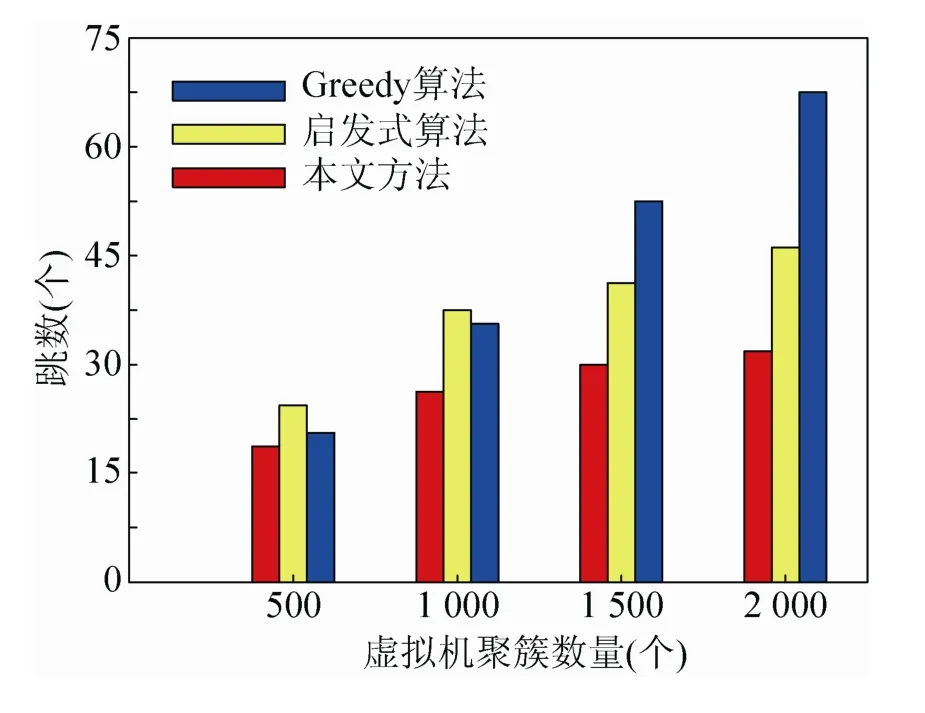
图4 3种方法聚簇的跳数对比
从图4中可以看出,3种方法形成的聚簇效果比对,本文的方法最为理想,其跳数随着聚簇虚拟机数量的增加出现的数量最少,最有利于云数据处理过程稳定地实现。
4 结 论
随着云计算的发展和逐步成熟,在云端实现大数据处理的计算任务越来越多。原本针对虚拟机部署的执行策略,已经逐步向多个虚拟机形成的虚拟机簇进行部署的执行策略转变。本文针对虚拟机如何实现有效聚簇来展开研究, 依托虚拟机簇的构建原理和云数据处理的普适性硬件结构,引入一种动态规划的全局优化策略,以实现虚拟机的聚簇处理。整个聚簇过程的实现,首先设置虚拟机的属性判断函数,进而执行升序排序处理,然后执行动态规划全局优化判断策略,从升序集合的中心位置开始向两个方向进行聚簇。实验结果表明,本文构建的基于动态规划的聚簇方法,不仅实现了虚拟机资源的快速聚簇,而且聚簇的效果也比较合理,对于云数据处理过程稳定的实现是有益的。
[1] Jayasinghe D, Pu C, Eilam T, et al. Improving performance and availability of services hosted on IaaS clouds with structural constraint-aware virtual machine placement [C]//2011 IEEE International Conference on Services Computing. Piscataway: United States, 2011: 72-79.
[2] 杨博, 刘大有, Liu J M, 等. 复杂网络聚类方法[J].软件学报, 2009, 20(1): 54-56.
[3] Gupta R, Bose S K, Sundarrajan S, et al. A two stage heuristic algorithm for solving the server consolidation problem with item-item and bin-item incompatibility constraints [C]//SCC 08: Proceedings of the 2008 IEEE International Conference on Services Computing. Piscataway: United States, 2008: 39-46.
[4] Calheiros R N, Ranjan R, De Rose C A F, et al. CloudSim: a novel framework for modeling and simulation of cloud computing infrastructures and services, Grids-Tr-2009-1 [R]. Melbourne Australia: the University of Melbourne, Grid Computing and Distributed Systems Laboratory, 2009.
[5] 李强, 郝沁汾, 肖利民, 等. 云计算中虚拟机放置的自适应管理与多目标优化[J]. 计算机学报, 2011, 34(12): 2253-2264.
[6] 何东晓, 周栩, 王佐, 等. 复杂网络社区挖掘——基于聚类融合的遗传算法[J]. 自动化学报, 2010, 36(8): 1160-1170.
[7] 刘进军, 赵生慧. 面向云计算的多虚拟机管理模型的设计[J]. 计算机应用, 2011, 31(5): 1417-1422.
[8] 王光波, 马自堂, 孙磊, 等. 基于架构负载感知的虚拟机聚簇部署算法[J]. 计算机应用, 2013, 33(5): 1271-1275.
[9] Rana S, Jasola S, Kumar R. A hybrid sequential approach for data clustering using K-means and particle swarm optimization algorithm [J]. International Journal of Engineering, Science and Technology, 2010, 2(6): 167-176.
[10] Zhou W Y, Yang S B, Fang J, et al. Vmctune: a load balancing scheme for virtual machine cluster using dynamic resource allocation [C]//Grid and Cooperative Computing (GCC), 2010 9th International Conference on. IEEE, 2010: 81-86.
[11] Cui L, Li B, Zhang Y Y, et al. Hotsnap: a hot distributed snapshot system for virtual machine cluster [C]// Proceedings of the 27th International Conference on Large Installation System Administration, 2013: 59-74.
[12] 赵银亮, 朱常鹏, 韩博, 等. 以虚拟机为核心实现动态行为调整的方法[J]. 西安交通大学学报, 2013, 47(6): 6-11.
[13] 孙鹏劼, 翟奋楼, 刘东旭, 等. 基于Web的拉丝模仿真系统开发与研究[J]. 图学学报, 2013, 6(6): 106-109.
Clustering Method of Virtual Machine in Cloud Computing Based on Dynamic Programming
Zhu Yanjun
(Department of Computer Engineering, Dongguan Polytechnic, Dongguan Guangdong 523808, China)
Fast and efficient implementation of multiple virtual machine cluster is greatly significant to enhance processing ability of cloud computing. In this paper, a new clustering method is proposed for virtual machine with general principle of virtual machine cluster and dynamic programming strategy. First, all virtual machine resources are performing in ascending order according to default discriminant function. Second, virtual machine at center position of ascending set is selected as starting point of clustering, and dynamic programming strategy begins from two directions. Clustering principles are based on dynamic programming criterion. Experimental results show that cluster method based on dynamic programming has a fast speed and a stable effect.
virtual machine; clustering; cloud computing; dynamic programming
TP 393
A
2095-302X(2015)06-0955-05
2015-06-25;定稿日期:2015-07-21
2014年度东莞职业技术学院院级科研基金资助项目(2014b05);东莞市高等院校、科研机构科技计划一般项目(2014106101037,2014106101033);东莞职业技术学院政校行企合作开展科研与服务资助项目(ZXHQ2014d010);广东省省级科技计划项目(2014A010103002)
祝衍军(1982–),男,湖南邵阳人,工程师,硕士。主要研究方向为云计算、商业智能。E-mail:zhuyanjunhn@126.com
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
心理学报(2022年4期)2022-04-12 07:38:02
水泵技术(2021年3期)2021-08-14 02:09:20
现代装饰(2020年5期)2020-05-30 13:01:58
金桥(2018年4期)2018-09-26 02:24:54
丝路艺术(2017年5期)2017-04-17 03:11:50
初中生(2017年3期)2017-02-21 09:17:43
小学生优秀作文(趣味阅读)(2017年3期)2017-02-11 03:11:31
中国惯性技术学报(2015年1期)2015-12-19 13:12:17
