
基于用户关联的热点话题检测方法
2015-11-26 01:08:44李洪利
计算机与现代化 2015年4期
李洪利,王 箭
(南京航空航天大学计算机科学与技术学院,江苏 南京 210016)
0 引言
微博的出现,让民众有了一个可以独立自主且相对自由的发声渠道,许多一手新闻甚至猛料均来自草根网民。提取微博热点话题的关键词,为搜索引擎优化提供参考是一个值得深入研究的方向。
目前,热点话题检测方法有很多。Gabriel[2]等人提出了利用时间信息的突发性事件检测方法。Cataldi[3]等人提出综合时间和社会评价关系来检测新兴事件的方法。Sayyadi[4]等人提出基于文档中特征词之间的关系建立特征词关联图,采用社区检测方法来发现和描述事件。虽然这些算法和其他几种算法[5-8]取得了一定的成果,但它们主要还是针对数据本身,没有充分利用社交与公共网络的特点,例如用户之间存在社会关系和用户的影响力大小不同等。
微博中用户正向影响力的大小对热点话题检测有着关键的影响。在关于用户影响力度量的研究中[9-13],出现过多种对用户影响力的度量方法。杨武等人在对新浪微博的研究过程中,直接将粉丝数作为指标来衡量微博用户的影响力,并根据影响力将用户分为焦点用户、活跃用户、一般用户和休眠用户,通过粗度过滤掉休眠用户发布或转发的信息,提高发现热点话题正确率。张昭等人在对微博关联网研究的基础上,提出利用用户属性信息结合网络空间的结构信息计算用户影响力的方法。上述研究提出的算法结果还处在人力影响之下,用户的情况还不够真实。为此,何静[22]等人重点研究用户关系网络特性,提出一种基于PageRank 的微博用户影响力评价模型,该方法可以有效地识别微博中的“僵尸”用户。此外,获得了用户影响力数据之后,如何将用户影响力运用到话题热度计算中,提高热点话题检测准确率,仍然是一个急需解决的问题。
微博开拓了一种新型信息传播方式,信息发布后在数分钟之内就可以获得超过百万用户的评论和转发,一些营销机构注册了大量的僵尸用户和网络水军来打造品牌的人气,要想获得真实用户的数据就成了不简单的事情,进而对热点话题检测结果产生重大的影响。因此,用户正向影响力计算对于热点话题检测显得非常关键。本文结合用户的权威度计算,提出一种基于用户关联的热点话题检测方法。用户权威度的UAR(User Authority Rank)计算是基于何静等人提出的用户影响力评价模型。最后结合微博属性信息和用户权威度,计算话题热度值。
1 用户权威度计算
可以通过有向图来直观展现微博平台上用户之间的关联关系。如图1 所示,圆圈表示一个用户,用户的粉丝越多,说明指向他的箭头就越多。这样当一个用户发布了一条信息,这条信息将会通过这些线快速传播,信息就可能成为下一个热点话题。香港大学新闻及传媒研究中心助理教授傅景华发现只有5%的用户发布原创微博,93.8%的用户只是单纯分享这5%用户的微博。关键用户是否参与到本话题的讨论当中对话题是否能成为热点话题有着直接的作用。可见,用户的权威度计算在判断用户真实性方面起关键性作用。
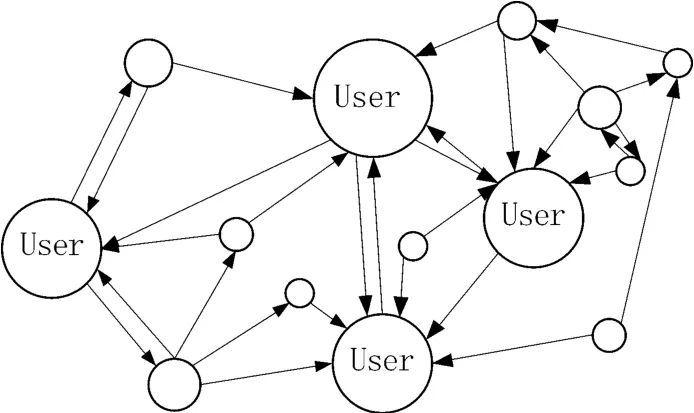
图1 微博平台上的用户关联图
PageRank 算法是谷歌排名运算规则之一,是一种链接分析方法,由谷歌创办人拉里·佩奇和谢尔盖·布林提出的。该算法根据网站的外链和内链的数量和质量来衡量一个网站的价值,算法值越高,网站排名越靠前。可以将微博用户关系网看成网站,若用户Alice 是Bob 的粉丝,则意味着Alice 给Bob 权威度加值;Alice 的权威度越高,则传递给Bob 的权威度就越高。这种用户之间的连接关系与网页之间的链接相类似,因此微博用户的权威度评估也可以通过改进PageRank 算法来计算。PageRank 算法计算公式如下:

其中,PR (p)表示网页p 的PageRank 值;Ti表示指向网页p 的页面集合;C (Ti)表示指向网页p 的页面,其外部链接数量;d 为阻尼因子。
在微博关系网络中,一个微博用户的权威度不仅与其粉丝数有关,还与用户微博发布频率、用户评论、转发微博频率等因素有关。因此,若直接利用PageRank 算法来评估微博用户的权威度,单纯地对其粉丝的PR 值进行叠加,就忽略了用户自身因素的影响,并不能客观地反映真实情况。分析微博用户属性,添加新的评价因素来改进PageRank 算法计算用户权威度。
1)粉丝数。用户的粉丝数表示如图1 中指向User 的箭头数量。箭头数越多,则粉丝数越多,即话题传播的速度更快、范围更广。
2)活跃度。用户的活跃程度主要与用户发布微博的频率、转发和评论的微博数量有关,会影响事件传播的速度与范围。
3)粉丝的权威度。事件在微博中的传播主要由用户的粉丝通过评论及转发微博来推动,因此粉丝越权威,博主自身的权威度也越大。
综上,用户权威度计算公式如下:
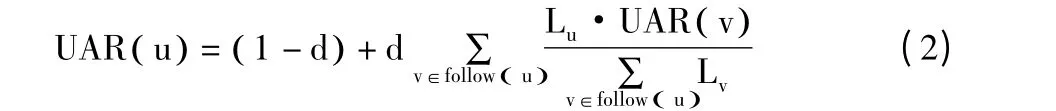
其中,UAR (u)表示用户u 的UAR 值;follow (u)表示用户u 的粉丝集合;Lu为用户u 的活跃度;d 为阻尼因子。
用户的活跃程度主要与用户粉丝数、用户发布微博的频率、转发和评论的微博数量等有关。因此,用户u 的活跃度可以用式(3)计算:

其中,Lu为用户u 的活跃度,Aj为活跃度的影响因素值,wj为Aj的对应权值。
用户的粉丝数量、转发和评论的微博数量可分别根据实际数据获得。用户发布微博频率可以用式(4)得到:

其中,Tfirst表示用户第一次发布微博的日期,Tend表示用户最后一次发布微博的日期,N 表示在这段日期期间内发布的原创微博数量。
以下为UAR 值的详细计算流程:
算法:用户UAR 值计算。
输入:N 个用户的关系网,包括N 个用户活跃度值的集合;
输出:N 个用户的UAR 值。
1)N 个用户的旧UAR 值,对其赋初值为1;
2)根据式(2)计算各个用户的新UAR 值;
3)当各个用户的旧UAR 值和新UAR 值相差大于某个阈值时,则将各个用户的旧UAR 值赋值为新UAR值,再根据式(2)计算每一个用户的新UAR 值;
4)经过若干次迭代计算,每一个用户的旧UAR值与新UAR 值趋于相等;
5)N 个用户的UAR 值为新UAR 值,输出。
2 基于用户关联的话题检测
2.1 整体框架
如图2 所示,本方法主要包括信息采集、数据预处理、聚类、话题热度计算以及关键词提取5 个部分。
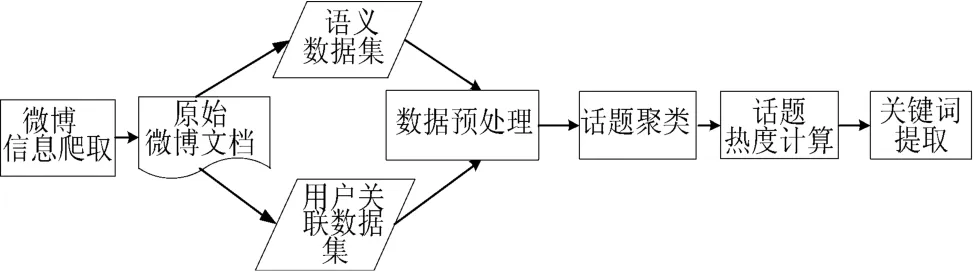
图2 话题检测的流程
2.2 预处理
对采集的微博文本作预处理,主要包括微博信息噪声过滤、文本分词、停用词过滤、权重计算、文本向量表示、特征提取等。具体流程如图3 所示。首先根据用户的权威度值对得到的微博内容进一步过滤,过滤掉低权威度值用户的相应微博信息。
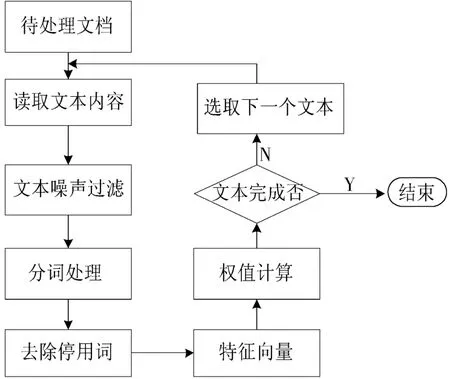
图3 预处理流程图
2.2.1 噪声过滤
信息噪声过滤步骤如下:
1)获取微博语义数据和用户关联数据,删除无用信息。
2)利用UAR 算法计算权威度值,对计算结果排序,过滤掉权威度低的用户发布或转发的微博语义数据。
3)采取新浪微博作为数据的来源网站。由于所采集的微博格式复杂多样,并且干扰噪音大,严重影响词频统计。所以制定如下信息筛选规则:
①去除“@用户名”格式的信息;
②过滤掉开头含有双#格式的语义数据。
2.2.2 语义特征提取
噪声过滤后,对文本做分词并去停用词。本文采用的分词工具为汉语词法分析系统ICTCLAS(其由中国科学院开发),去除了对文本主题表达贡献较小的低效词,如“为了”、“这些”、“然而”等,以及微博内容中包含的网址及表情,保留包含关键信息的名词、动词、形容词、副词作为特征项。对停用词是在程序中使用停用词表来去除。
文本使用向量空间模型(VSM)来表示。向量空间模型中给不同的特征项分配不同的权重,通过特征项的权重能反映该特征项对文本文档的贡献度和文档之间的区分能力[21]。传统的TF-IDF 权重计算方法在计算特征词条在文本中的权重时,只考虑该特征词条在文本集合中的分布情况,并没有考虑到一个语义可能有多种表达方式,计算公式将每个词条都独立起来,是不符合实际应用的。针对此问题,采用参考文献[16]提出的结合语义相似度的归一化TF-IDF函数,如式(5):
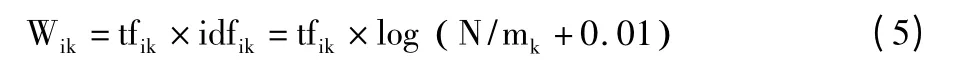
其中,tfik为特征词条Tk在文本Di中的出现次数;idfik为特征词条Tk的逆词频;N 为整个文本的数量;mk为含有Tk的文本数量和与Tk语义相似的特征项出现的文本数量的平均值的和。mk的计算公式[17]如下:

其中,nk为包含Tk的文本数量;pj为包含其它文本中与Tk语义相似的特征项的文本数量;c 为与Tk语义相似的特征项数量。
式(6)中,特征词条之间的语义相似值要大于0.8,才能说其语义相似;且本文的语义相似计算是采用基于“知网”的词汇语义相似度计算方法[17]。
2.2.3 文本相似度计算
在向量空间模型中,2 个文本间的相似度常用余弦法表示,公式为:
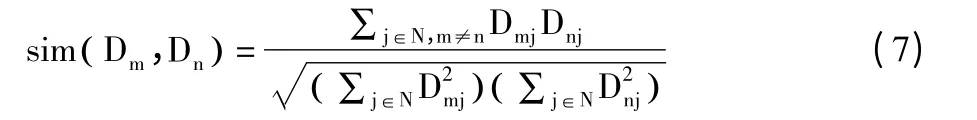
其中,Dmj,Dnj分别表示文本Dm和Dn中第j 个特征词条的Wik值。
从对文本内容相关度计算公式来看,对各个文本特征项的权值计算是非常关键的,因为其值直接降低文本间相似度的准确率,进而会影响后面文本聚类结果。
2.3 话题聚类
K-Means 算法也称为K 均值聚类算法,由J.B.MacQueen 于1967 年首次提出,属于一种基于划分的方法。在热点话题检测方法中,当前最常使用的聚类算法包括K-Means 算法。
K-Means 聚类算法具有聚类速度快的优点[18],尤其适合大量数据聚类。K-Means 算法的时间复杂度为O(TKN),其中,T 为迭代次数,K 为聚类簇数,N为待分类的对象数,一般情况下,K,T 远小于N,因此TKN 值较小。但是K-Means 算法也存在缺陷,初始聚类中心的选取对聚类结果很敏感,当初始聚类中心值选取的不好时,聚类结果容易陷入局部最优。
本文聚类算法采用一种改进的K-Means 算法[18],改进后的K-Means 算法与原有的K-Means 算法之间的不同点是,在迭代聚类前要先利用每个文本的平均相似度值来确定聚类的初始中心点。2 条微博文本间的相似度值越大,表明它们所讨论的事件越相关,更可能属于同一个话题。
算法实现的思想:先计算文本的平均相似度,然后对相似度集合P 排序,从中选择最大的作为中心点并删除与选中文本簇相关的文本,多次重复上述步骤,直到有k 个中心点,如果P 为空集且中心点个数小于k 时,那么就把之前删除的文本重新加入到集合中选择中心点。
算法流程如下:
算法:计算聚类初始中心的算法Original(Doc,K,α)
输入:文本集Doc 的空间向量模型,聚类个数K,相似度阈值α,i=0(i 表示已确定的初始中心点个数)。
输出:初始中心点集I。
1)计算微博文本间的相似度值,然后构建文本间相似度的矩阵Matrix;
2)根据构造的矩阵Matrix,构建一个集合P,并对其进行排序,按照升序的方式即可;
3)初始中心点集I 设置为空集,删除集变为空集,即Delete=Ф;
4)从P 中选取数值最大的文本dj作为一个中心点,并将其加入到初始中心点集中,即I=I∪{dj},已设置选择中心点个数i 自动加1,即i=i+1;
5)根据构造的矩阵Matrix,找寻文本dj簇相关的全部文本,并将这些文本从集合P 中全部删除,即如果sim (di,dj)>α,则P=P-{ai}且Delete=Delete∪{ai};
6)当集合P=Ф 且i <K 时,使Delete 中所有的文本放入到集合P 中并且将Delete 置为空,即P=Delete,Delete=Ф;
7)循环执行步骤3)~步骤6),直到满足终止条件i=K,输出初始中心点集合I。
改进的K-means 聚类算法流程如图4 所示。
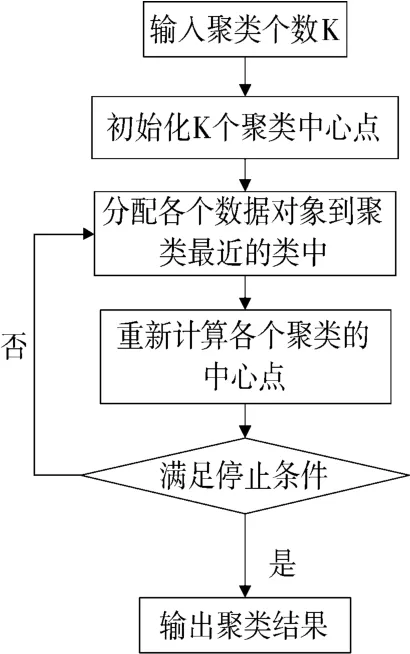
图4 改进的K-means 聚类算法流程图
2.4 话题热度计算
文本聚类后获得一组话题簇,每个簇内文本数量还是非常多。为了能够更准确地获取一段时间内的热点话题,需要对聚类结果进行话题热度计算。孙胜平[19]提出文本是话题的组成部分,所以文本的热度决定了话题的热度,而文本数量是话题热度最直观的反映。文本的热度主要通过发布者的粉丝数、该文本信息被转发和评论的数目来判断。最终提出利用上述3 个因素来计算文本热度,进而得到话题热度。该方法被多位研究学者采用计算话题热度[11,15]。
由于每个话题都是从微博文本中提取的,所以文本的热度直接决定话题热度。而微博文本可能是用户发布或加上自己的评论后转发,因此用户的权威度、此条微博的转发数和评论数是微博文本热度的影响因素。考虑以上因素对微博文本实际热度的贡献率,本文基于孙胜平的热度计算公式结合第1 节得到的用户权威度计算值来计算热度值,计算公式如下:
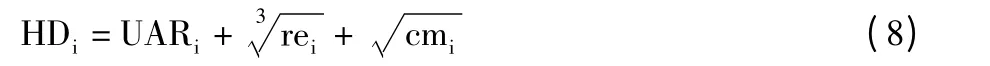
其中,UARi表示微博发布者的权威度值,rei表示微博转发数目,cmi表示微博评论数目。
3 实验结果与分析
3.1 实验数据
本文通过新浪微博API 爬取了2356 个用户的微博数据,主要是从2014 年8 月25 日到27 日这3 天的,微博语义数据集共31 410 条。停用词表采用哈尔滨工业大学信息检索研究中心发布的。
3.2 实验的评价指标
参照TDT 会议对TDT 话题检测任务的评测规范,微博热点话题检测的评价采用漏检率PMiss、错检率PFA和误测开销值CDet来衡量。

为能够综合考虑PMiss和PFA,引入误测开销值CDet如式(11):

其中,CMiss和CFA分别表示漏检和错报的代价值;PMiss和PFA分别表示漏检和错报的条件概率;Ptarget是先验的目标话题出现概率,Pnon-target=1 -Ptarget。CMiss、CFA和Ptarget都是预先设置好的,作为调节PMiss和PFA在评价结果中所占比例参数,通常分别设置为1.0,0.1,0.02[20]。CDet通常被规范化,公式如下:

3.3 用户权威度
获取用户关联数据,包括用户粉丝数、发布的原创微博数量及其时间段、转发和评论的微博数量等。
基于用户活跃度计算符合层次分析法计算的特性,利用层次分析法计算获取用户活跃度中各种影响因子的权重wj=(0.267,0.483,0.250)。取阻尼因子d 为0.85,根据第1 节中的算法计算得到权威度值将前十的用户的粉丝数量、活跃度值和UAR 值作对比,如图5 所示。

图5 用户权威度和其他数据的比较
从实验结果可以看出,用户的权威度与用户的粉丝数和活跃度等影响因子之间并非呈现出一定的正相关性。粉丝数量大的用户,其UAR 值不一定也高;同理活跃度高的用户,其UAR 值也不一定高。但是相比用户的活跃度,用户的粉丝数对用户权威度的影响较大,主要是在用户的权威度中起到了主导作用,而用户活跃度对用户权威度的作用则相对较小。得出的结论与实际的微博信息中的状况基本相一致。在实际的微博中,存在明星用户、僵尸用户和普通用户等。对于明星用户和普通用户来说,其粉丝数和活跃度在一定程度上决定了他在局域网络中的权威度;而对于僵尸用户,由于其活跃度很小,计算得到的权威度也就非常小。因此,通过该算法基本上能够客观真实地反映微博用户的实际权威度,过滤权威度相对较小的用户,可以减少微博噪声数据对检测结果的影响。将该算法利用到热点话题检测中具有实际的应用价值。
3.4 话题检测实验结果与分析
选取实验数据UAR≤10 的用户2 500 位。图6显示了用户的“权威度-人数”关系,可见大多数用户的权威度值小于2,当权威度值大于2 时,用户数随权威度值增加而显著减少。线条尾部的权威度相对较大,少数名人权威度可以达到50 以上,实验表明这将会影响到UAR 平均值的计算。综上分析,本实验仅选择UAR ≤10 的UAR 值计算平均值得到UARaverage=0.83。实验分析,过滤掉UAR ≤1/3 UARaverage的用户,该范围内的用户总数为508,大概为实验总体用户数的20.3%。
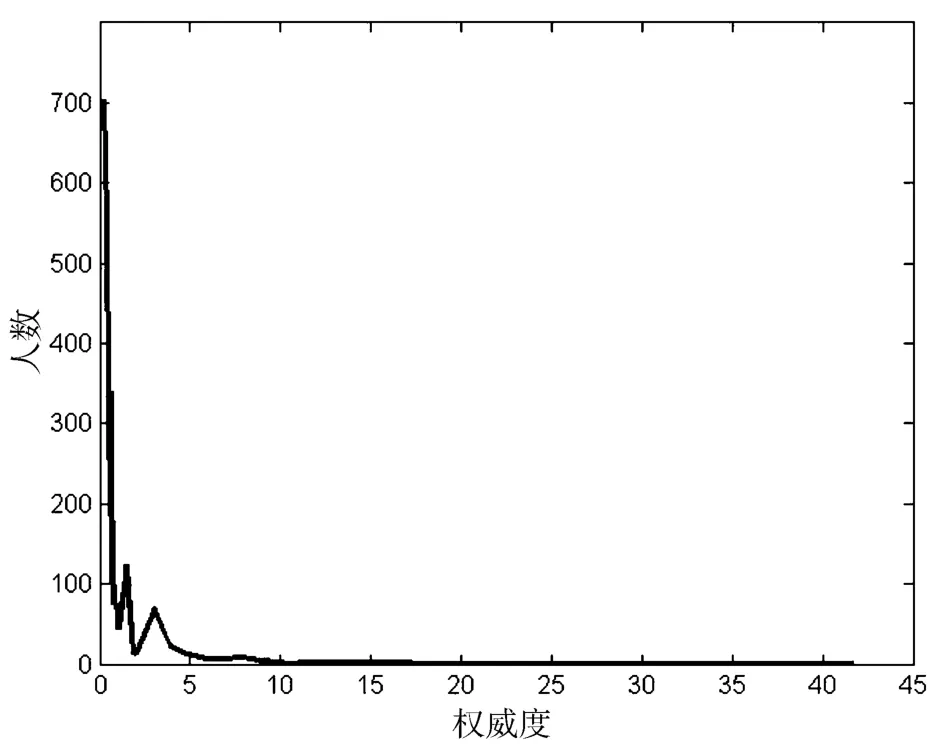
图6 User“权威度-人数”情况
对采集的微博语义数据做预处理,话题聚类得到话题簇。提取出热点话题中最具代表性的特征词作为该话题的代表关键词,主要利用话题簇中那些特征项权重排名靠前的特征词。最终得到的话题以及相应的关键词如表1 所示。本文将聚类得到的话题与新浪微博评选的热点话题对比以及第2.4 节中改进的话题热度计算公式与原公式结果对比,结果如表2所示。

表1 聚类得出的话题

表2 话题热度计算结果对比
从表2 可以看出,实验选取的该时间段,本文话题热度改进公式计算得出的话题热度,最热的话题是冰桶挑战,通过与同时段新浪公布的热门话题对比,发现改进后公式在热点话题检测性能上提高了10%,则说明该改进公式是可行的。
以未引入用户权威度过滤为Base,将本方法与文献[11-12]和Base 做对比,实验数据如表3 所示。表3 数据表明,在微博热点话题检测中引入用户权威度的方法,可以有效提高话题检测性能。
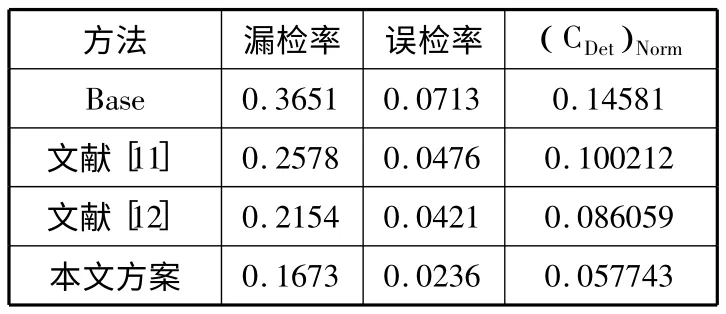
表3 话题检测结果对比
4 结束语
本文提出的基于用户关联的热点话题检测方法,重点分析用户间的关联关系,将用户权威度衡量用于微博热点话题提取时对爬虫抓取的微博信息中的干扰数据进行提前过滤。同时利用改进的K-Means 聚类算法得到聚类结果,最后将用户权威度信息与传统热度信息有机结合,得到热点话题检测结果。从实验结果看,本文的方法在话题检测性能方面比其他文献方法有更好的效果。另外对话题热度计算引入权威度信息,实验数据表明,该改进公式能够有效吻合官网上提供的数据。在下一阶段的研究中,进一步优化用户权威度算法,过滤微博干扰信息,提高话题检测精度是重点方向。
[1]薛峰,周亚东,高峰,等.一种突发性热点话题在线发现与跟踪方法[J].西安交通大学学报,2011,45(12):64-69.
[2]Gabriel Pui Cheong Fung,Jeffrey Xu Yu,Philip S Yu,et al.Parameter free burst events detection in text streams[C]// Proceedings of the 31st International Conference on Very Large Data Bases.2005:181-192.
[3]Cataldi M,Di Caro L,Schifanella C.Emerging topic detection on twitter based on temporal and social terms evaluation[C]// Proceedings of the 10th International Workshop on Multimedia Data Mining.2010.
[4]Sayyadi H,Hurst M,Maykov A.Event detection and tracking in social streams[C]// Proceedings of the International Conference on Weblogs and Social Media.2009.
[5]龙志炜,程葳.基于词聚类的热点话题检测算法[J].计算机工程与设计,2011,32(6):2214-2217.
[6]张寿华,刘振鹏.网络舆情热点话题聚类方法研究[J].小型微型计算机系统,2013,34(3):471-474.
[7]陈友,程学旗,杨森.面向网络论坛的高质量主题发现[J].软件学报,2011,22(8):1785-1804.
[8]鲁明羽,姚晓娜,魏善岭.基于模糊聚类的网络论坛热点话题挖掘[J].大连海事大学学报,2008,34(4):52-58.
[9]Cha M,Gummadi K P.Measuring user influence in Twitter:The million follower fallacy[J].Artificial Intelligence,2010,146(1):10-17.
[10]Kimura M,Saito K,Nakano R,et al.Extracting influential nodes on a social network for information diffusion[J].Data Mining and Knowledge Discovery,2009,20(1):70-97.
[11]杨武,李阳,卢玲.基于用户角色定位的微博热点话题检测方法[J].计算机应用,2013,33(11):3076-3079.
[12]张昭,艾中良.一种基于用户关联分析的热点话题识别算法[J].计算机与现代化,2014(1):156-160,163.
[13]原福永,冯静,符茜茜.微博用户的影响力指数模型[J].现代图书情报技术,2012(6):60-64.
[14]杨冠超.微博客热点话题发现策略研究[D].杭州:浙江大学,2011.
[15]薛素芝,鲁燃,任圆圆.基于速度增长的微博热点话题发现[J].计算机应用软件,2013,30(9):2598-2601.
[16]任姚鹏,陈立潮.结合语义的特征权重计算方法研究[J].计算机工程与设计,2010,31(10):2381-2383.
[17]刘群,李素建.基于《知网》的词汇语义相似度的计算[EB/OL].http://download.csdn.net/detail/c183662101/1668191,2013-04-20.
[18]尹婵娟.基于聚类分析的微博热点话题检测研究[D].南京:南京工业大学,2012.
[19]孙胜平.中文微博客热点话题检测与跟踪技术研究[D].北京:北京交通大学,2011.
[20]National Institute of Standards and Technology.The 2003 Topic Detection and Tracking Task Definition and Evaluation Plan[EB/OL].http://www.nist.gov/speech/tests/tdt/tdt2003/evalplan.htm,2013-04-26.
[21]迟呈英,李红.基于改进TF PDF 算法的网络新闻热点话题检测和跟踪[J].计算机应用与软件,2013,30(12):311-314.
[22]何静,郭进利.基于改进PageRank 算法的微博用户影响力研究[J].中国报业,2013(01):21-23.
猜你喜欢
今日农业(2020年24期)2020-03-17 08:58:14
电子测试(2017年15期)2017-12-18 07:19:27
人大建设(2017年7期)2017-10-16 01:42:40
作文通讯·高中版(2017年6期)2017-07-10 03:21:34
电影(2017年6期)2017-06-24 11:01:26
网络空间安全(2016年3期)2016-06-15 20:27:07
智能系统学报(2015年4期)2015-12-27 09:38:39
小说月刊(2015年1期)2015-04-19 02:04:19
电子设计工程(2015年6期)2015-02-27 12:04:53
中国有色金属(2014年23期)2014-03-13 02:10:27
