
基于预测的云计算热点数据副本因子决策算法
2015-11-26 01:08杜庆伟
计算机与现代化 2015年2期
张 松,杜庆伟,孙 静,孙 振
(1.南京航空航天大学计算机科学与技术学院,江苏 南京 210016;2.中国人民解放军94860 部队,江苏 南京 210018)
0 引言
云计算的出现和发展,满足了用户对超大规模计算和存储的需求。为了克服单点失效带来的数据可用性差等问题,HDFS 等分布式云存储平台普遍采用了多副本技术[1]。副本技术的原理就是将数据的副本复制多份并放置于集群的不同节点上,使得部分节点失效时,用户依然可以通过其他副本访问资源[2]。HDFS 采用统一副本管理策略,默认副本因子为3[3-4]。然而由于数据的访问热度存在较大的差异[5-7],对于热点资源的访问竞争将导致系统瓶颈,增加作业的执行时间。因此,为了解决热点数据对节点的访问压力和集群负载的不均衡,应该对热点数据的副本因子进行动态调整。当数据的热度增加时,应增大副本因子,以降低资源竞争和网络流量,减少因访问竞争导致的作业执行时间延长;当数据的热度降低时,应降低副本因子,以节省存储空间,降低维护成本。综上所述,合理的副本因子不仅能够提升分布式存储系统负载的均衡性,更能提高数据的可用性和读写性能。
热点数据副本因子动态调整是云计算中的一个研究热点,但基于当前热度的副本调整不仅具有滞后性,亦会受到突发访问波动的影响,因此副本因子的调整应当以该文件的未来热度为依据[6,8-9]。于是,精确预测文件的未来热度成为副本决策中至关重要的一环[5,8]。若对文件的未来热度预估不准,那么有可能创建过多的副本而浪费存储空间和网络带宽,也有可能创建过少的副本,从而无法减轻热点访问对节点造成的访问压力和负载倾斜[5,7]。基于此,本文提出根据热点数据历史访问特征,基于灰色预测模型预测数据的未来访问热度,采用马尔科夫预测模型修正因数据波动和突发访问造成的预测偏差,并基于预测值建立有限通道服务模型,寻找满足用户需求的最小副本因子。
1 相关工作
副本技术不仅能够减少网络负载和访问延迟,而且还能增加存储系统的利用效率和数据的可用性。因此,其他一些相关领域,诸如P2P 网络,网格计算等也采用副本技术来增强系统性能。常见的副本技术有静态副本技术和动态副本技术。静态副本技术在文件创建时固定副本个数和副本位置,并且在文件的可用周期内副本因子无法更改,无法适应数据热度随时间变化的趋势,容易造成网络拥塞和节点过热,降低集群效用。动态副本策略依据用户需求、网络状况和副本热度进行动态调整,更适合变化较大的存储系统。近年来,云计算环境下动态副本技术逐渐成为一个重要的研究点,众多研究集中在动态副本决策方面。
文献[1]提出一种基于工作负载变化的动态副本管理模型CDRM。该模型以提高系统性能、均衡负载为优化目标,综合考虑存储空间和访问模式的变化,并以节点的阻塞概率作为副本调整的评价指标,动态调整副本因子;文献[5]基于对实际商业云计算平台的运行数据进行分析,阐述了数据热度的不均衡性以及热点数据对MapReduce 集群的影响,强调了数据本地化和准确预测副本热度的重要性,为本文的研究提供了重要的理论依据。然而副本因子的决策依据文件的最大并发访问数,缺乏理论分析,依赖专家经验;文献[6,9]充分利用文件的历史访问信息决策未来热度,并以此为基础调整副本因子,提高系统性能和最小化存储负载;文献[8]以辅助资源调度提高数据本地化为研究目标,指出数据热度的增加易造成本地化的下降,从而加重网络负载。通过充分利用非本地化任务获取远端数据的优势,基于数据热度决策数据的存留,在不增加多余网络负载的同时,提高了数据的本地;文献[7,10-12]以提高数据的可用性和可靠性为目标,动态调整副本因子,实验表明集群的性能和存储资源的利用率都有了显著的提高;文献[13]采用灰色预测技术预测文件未来热度,但没有考虑文件热度的波动性。且在副本因子决策阶段,单纯依靠文件热度是否超过平均热度决策副本创建。
以上工作都没有考虑到数据访问的突发波动以及部分访问随机性等状况对热度预测的影响。因此本文以副本因子的决策为目标,修正数据访问突发波动对预测值的影响,并建立有限通道服务模型,寻找满足用户设定文件服务策略的最小副本数。
2 热度预测和副本因子决策
2.1 热度预测
2.1.1 灰色预测和马尔科夫预测
灰色预测结合马尔科夫预测已经被证实是一种行之有效的解决数据序列波动较大情况下预测准确度降低的时间序列预测模型。在路由节点行为预测[14]、经济指数、网络流量预测[15]等领域得到了广泛运用。灰色预测模型的特点是样本预测所需的数据量较小、计算简单,可以提高新信息的权重,符合副本预测的特点。通过累加生成来寻找数据的规律性,但对于波动数据预测准确度不高。通过使用Markov模型对预测结果进行修正,可以达到较高的预测准确度。
而其他预测算法,诸如神经网络模型[16]、小波等,需要大量样本空间进行训练,并且对于神经网络的层次设置依赖专家经验[14],在数据量较小的情况下,训练精度不高,准确度无法保证。ARMA 预测模型[17]依赖于对参数的准确估计,数据的突发波动会影响数据发展的规律性,对于预测的准确性造成较大的干扰。
2.1.2 灰色预测GM(1,1)模型的建立
灰色预测的目的是预测文件在未来时刻的访问热度,原始数据序列为该文件在前n 个等时距内的访问频次。具体建模过程如下:
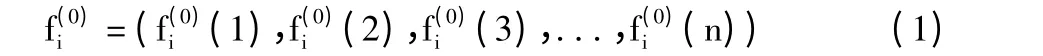
2)对原始访问频次序列进行累加处理,寻找其中蕴含的规律性:
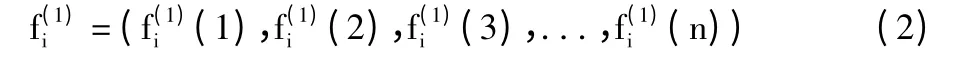

3)对累加后的访问频次序列建立GM(1,1)模型的一阶微分方程,其相应的白化微分方程为:

其中,a 和b 为待识别常量,a 为发展系数,b 为灰作用量。
采用最小二乘法求得待识别常量的估计值:

其中:

λ 为新旧数据的权重,为突出新数据优先的思想,即最近的数据访问特征应当具有更高的权重,λ 取值0.75。
4)将求得的估计值代入公式(4),得访问频次的时间响应函数为:
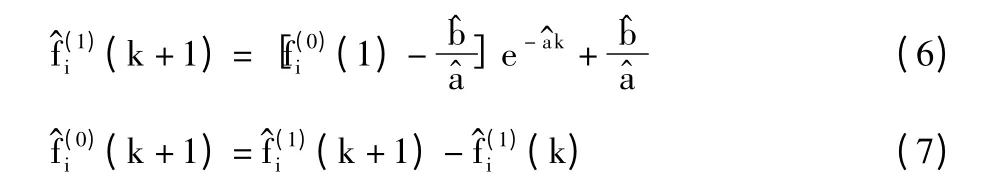
2.1.3 对预测数据的马尔科夫修正
马尔科夫预测根据系统的初始状态和状态转移概率,预测未来一段内系统可能处于的状态。由于用户访问的随机性和数据热度变化的突发性,灰色预测可能存在较大偏差,因此本文采用马尔科夫模型修正因访问热度的波动造成的预测偏差。具体步骤如下:
1)首先计算拟合值与实际值之间的相对残差。
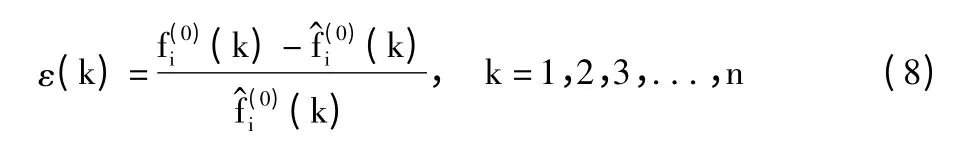
2)根据相对残差的大小以及检验精度对残差的要求,将相对残差划分成6 个状态区间,具体状态如表1 所示。
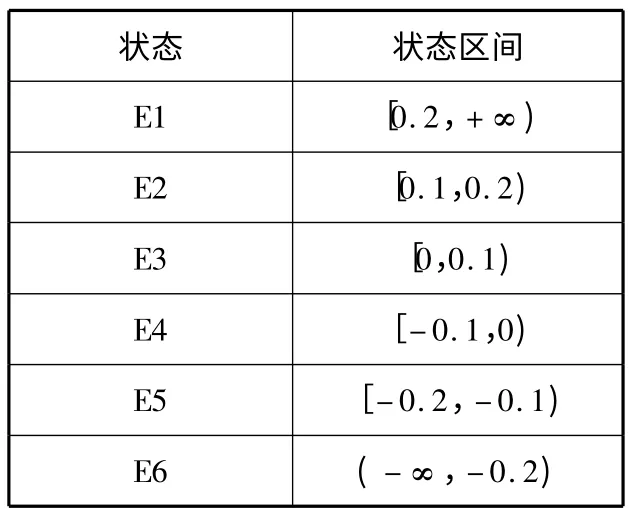
表1 状态及其相应状态区间
3)计算状态转移概率。

其中,nij(k)表示状态Ei 经过k 步到状态Ej 出现的次数,且ni为Ei 出现的次数。于是可得到一步状态转移概率矩阵为:

其中,m 为状态数。
通过状态转移概率矩阵和当前时间段拟合值的状态,可以预测下一时刻灰色预测值的相对残差的状态。取相对残差状态区间的中值作为灰色预测值的修正值,具体公式见式(10):
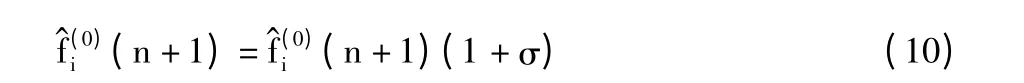
2.2 副本因子决策
通过前述预测模型,得到了一个相对较为精准的文件热度值,下面通过文件的未来热度建立有限通道服务模型,依据用户设定的访问竞争概率,计算合适的副本因子。为保证数据的可用性,采用HDFS 默认的副本因子数作为文件的最小副本因子。
HDFS 分布式存储平台中,如果同时访问某一文件的作业数量超过该文件的副本数,那么部分作业对数据的访问将产生竞争,或者从远端读取数据[5],此时必然增加作业的执行时间和网络负载。文献[5]通过对实际商用集群的分析指出对热点数据的访问竞争将导致作业的平均执行时间延长16%。
考虑某一热点文件访问分布情况。由于作业的执行相互干扰导致执行时间的波动性和数据访问到达时刻的随机性,因此可以假设时间间隔T 内作业的执行时间服从参数为μ 的负指数分布,并假设数据访问到达的时刻符合泊松流。其中1/μ 表示作业的平均执行时间,该值可通过统计作业的执行时间并计算均值获取。即单位时间内有k 次访问的概率为:

其中λ 表示单位时间t'内的平均访问频次,该值可由预测访问频次计算得知。设N(t)表示在时间区间[0,t)内的访问频次(t >0),那么{N(t),t≥0}就构成了一个符合生灭过程的有限通道服务模型(M/M/r/∞)。副本因子的决策转化为寻找满足用户设定访问竞争概率的最小通道数r。为得到N(t)的分布Pn(t)=P{N(t)=n},n=0,1,2,...,需获得系统到达平衡后的平稳分布,记做Pn,n=0,1,2,...。
由生灭过程理论可知单通道平稳状态的分布为:
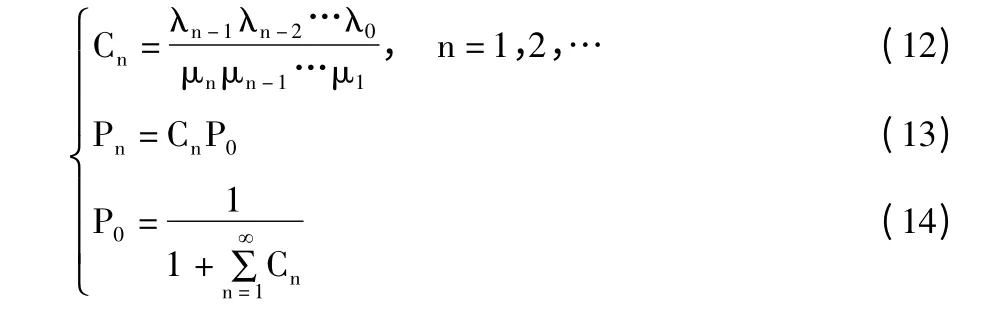
在多通道服务模型中,通道数r 即为当前副本因子。有λn=λ,n=0,1,2,…,且:记。

注意到只有当ρr<1 时,该模型才有意义。因此,需修正当前通道数r 值为。
由公式(12)~公式(14),根据生灭过程理论得:
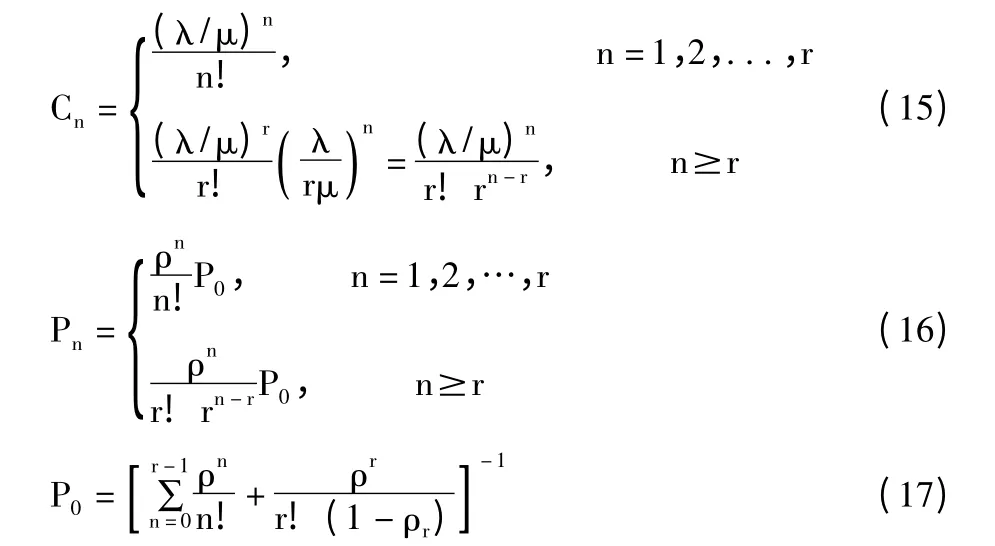
公式(16)给出了在平稳分布条件下,该热点文件同一时刻文件并发访问为n 的概率。当n≥r 时,系统中对数据的并发访问大于或等于通道个数。这时,新来的数据访问必然将产生数据竞争,因此记访问竞争概率为:

用户基于访问竞争概率Pc划分文件服务等级。对于高优先级文件或高级用户文件,可赋予较小的访问竞争概率,以降低并发访问竞争带来的执行时间延长,为用户提供高质量的服务,此时需要更大的副本因子,以空间换时间。对于低优先级文件或临时用户文件,可赋予较大的访问竞争概率,容许高并发对作业执行时间的延长。
对于某一热点文件,基于用户设定的访问竞争概率,代入公式(18),计算满足用户需求的最小副本因子。
3 实验分析
测试环境包括3 个机架共9 个节点组成,每个机架都有1 台交换机,Namenode 节点位于机架B 中编号为3 的节点。所有节点安装Ubuntu12.04 操作系统,其拓扑结构如图1 所示。

图1 网络拓扑结构
实验采用的测试用例为Hadoop 云计算平台自带的WordCount 例程。本实验目标是为了验证副本动态变化对系统性能的影响,由于集群环境较小,为使实验结果更加明显,将HDFS 的默认副本因子设定为2。用户设定访问竞争概率为10%,由于作业的执行时间大约为10 分钟,因此,可以设定等时距间隔T=10 min。作业的到达模拟文件的热度增减以及突发访问。实验从副本数的动态变化、网络流量以及作业的完成时间来评价现有HDFS 静态副本管理策略与本文的动态副本管理策略。这里引出了副本管理中的副本放置策略的问题,而该问题超出了本研究范畴,将在后续研究中讨论该问题。本实验新增副本的放置采用随机放置的策略,并遵循不同副本不能放置在同一数据节点的原则。2 种副本管理策略下,调度算法均采用容量调度器。用Default 表示HDFS 的静态副本因子策略用DR2P(Dynamic Replicas based on Predicted Popularity)表示本文的动态副本因子策略。
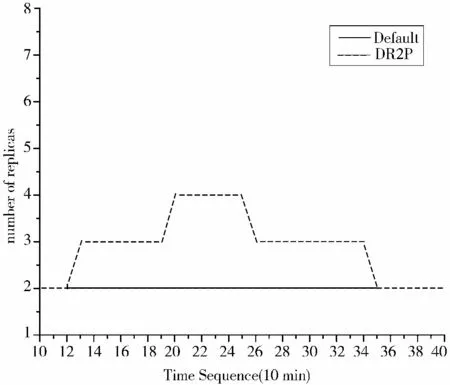
图2 副本数
图2 为默认HDFS 副本策略和机制下,文件的副本数变化的示意图,其中横坐标表示时间间隔序号,从第10 个时间间隔开始观察,纵坐标表示热点文件的副本个数。由图2 可知,当文件的访问热度增加时,文件的副本数增加,以降低作业执行时的访问竞争对作业执行时间的影响,当文件的访问热度降低时,算法计算出满足访问竞争的最低副本数,此时文件的副本数降低,节约了存储空间和系统一致性维护的难度。而现有的HDFS 副本策略下,副本的数目保持不变。

图3 网络流量
图3 为现有HDFS 和本文副本管理机制下,数据节点之间的数据传输量示意图,网络流量的统计宏观上以非本地化任务引起的网络负载为基准,统计依据为热点数据的热度增加导致非本地化任务的增多。从图3 中可以看出,在文件被频繁访问时,数据节点间数据传输频繁,网络流量增加。通过本文的动态副本管理策略,系统为热点数据动态创建多余副本,相较于现有HDFS 下默认的静态副本管理策略,在文件被热点访问期间,系统的网络流量明显下降。
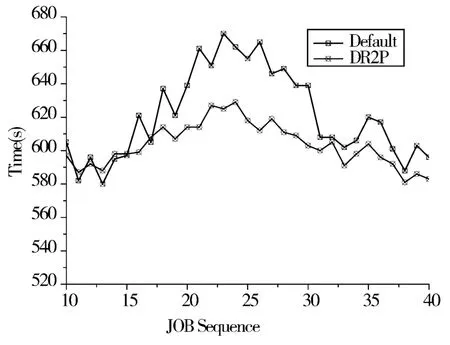
图4 作业完成时间
图4 为默认HDFS 静态副本策略和本文动态副本策略下,作业执行时间的对比。从图4 中可以得知,在文件的热度较低时,数据访问频次较少,此时为非热点数据,副本数没有增加,作业的执行时间与静态副本策略相比没有明显变化。当文件热度较高时,并发访问发生数据竞争,此时文件的副本数增加,以降低竞争,相较于静态副本策略,作业的执行时间有相应的减少。
4 结束语
针对现有的HDFS 副本管理策略没有考虑文件热度的不均衡性,在文件的生存周期内创建固定数目的副本,无法满足现实环境中文件热度随时间周期性规律波动的情况,本文提出根据数据的最近访问特征,建立灰色预测模型,并采用马尔科夫预测模型修正因数据波动和突发访问造成的预测偏差,并基于预测热度建立有限通道服务模型、决策最优副本因子。实验表明,较之现有的副本管理策略和实时热度调整策略,本文的副本因子决策算法可以有效减少热点数据的访问冲突,降低热点数据作业的执行时间和网络负载。
[1]Wei Qingsong,Veeravalli B,Gong Bozhao,et al.CDRM:A cost-effective dynamic replication management scheme for cloud storage cluster[C]// IEEE International Conference on Cluster Computing(CLUSTER).2010:188-196.
[2]王意洁,孙伟东,周松,等.云计算环境下的分布存储关键技术[J].软件学报,2012,23(4):962-986.
[3]White Tom.Hadoop:The Definitive Guide[M].O'Reilly Media,Inc.,2009.
[4]Kala Karun A,Chitharanjan K.A review on Hadoop—HDFS infrastructure extensions[C]// IEEE Conference on Information & Communication Technologies(ICT).2013:132-137.
[5]Ananthanarayanan G,Agarwal S,Kandula S,et al.Scarlett:Coping with skewed content popularity in mapreduce clusters[C]// Proceedings of the 6th ACM Conference on Computer Systems.2011:287-300.
[6]Kousiouris G,Vafiadis G,Varvarigou T.Enabling proactive data management in virtualized Hadoop clusters based on predicted data activity patterns[C]// IEEE 8th International Conference on P2P,Parallel,Grid,Cloud and Internet Computing(3PGCIC).2013:1-8.
[7]孙大为,常桂然,高尚,等.Modeling a dynamic data replication strategy to increase system availability in cloud computing environments[J].Journal of Computer Science and Technology,2012,27(2):256-272.
[8]Abad C L,Lu Y,Campbell R H.DARE:Adaptive data replication for efficient cluster scheduling[C]// IEEE International Conference on Cluster Computing (CLUSTER).2011:159-168.
[9]Wang Zhe,Li Tao,Xiong Naiyue,et al.A novel dynamic network data replication scheme based on historical access record and proactive deletion[J].The Journal of Supercomputing,2012,62(1):227-250.
[10]Shen Chunhui,Lu Weiming,Wu Jiangqin,et al.A digitallibrary architecture supporting massive small files and efficient replica maintenance[C]// Proceedings of the 10th Annual Joint Conference on Digital Libraries.2010:391-392.
[11]Li Wendong,Yang Yun,Yuan Dong.A novel cost-effective dynamic data replication strategy for reliability in cloud data centres[C]// IEEE 9th International Conference on Dependable,Autonomic and Secure Computing(DASC).2011:496-502.
[12]Khaneghah E M,Mirtaheri S L,Grandinetti L,et al.A Dynamic Replication Mechanism to Reduce Response-Time of I/O Operations in High Performance Computing Clusters[C]// IEEE International Conference on Social Computing(SocialCom).2013:738-743.
[13]陶永才,张宁宁,石磊,等.异构环境下云计算数据副本动态管理研究[J].小型微型计算机系统,2013,34(7):1487-1492.
[14]夏怒,李伟,罗军舟,等.一种基于波动类型识别的路由节点行为预测算法[J].计算机学报,2014,37(2):326-334.
[15]温祥西,孟相如,马志强,等.小时间尺度网络流量混沌性分析及趋势预测[J].电子学报,2012,40(8):1609-1616.
[16]周开利,康耀红.神经网络模型及其MATLAB 仿真程序设计[M].北京:清华大学出版社,2005.
[17]Box G E,Jenkins G M,Reinsel G C.Time Series Analysis:Forecasting and Control[M].John Wiley & Sons,2013.
猜你喜欢
黄河之声(2022年10期)2022-09-27
加油站服务指南(2022年6期)2022-07-28
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
车迷(2019年10期)2019-06-24
计算机系统应用(2019年2期)2019-04-10
快乐语文(2018年7期)2018-05-25
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
计算机与生活(2016年11期)2016-11-22
现代电子技术(2015年2期)2015-09-18
