
基于C6000系列DSP的算法优化研究
2015-11-16 05:13王金洋
中国科技信息 2015年1期
王金洋
基于C6000系列DSP的算法优化研究
王金洋

王金洋 余红英 樊永生
中北大学计算机与控制工程学院

目前DSP高性能运算芯片已经在工业数字信号处理、超高分辨率视频编解码等领域得到广泛应用。C6000属于TI公司的达芬奇系列双核处理器芯片,既具ARM对于各类外设接口的丰富支持,同时具有DSP数字信号处理器的强大运算能力。本文针对C6000的实际算法设计时候的5个关键技术展开讨论并在编程实践中研究如何具体使用。本文研究内容对于之后基于C6000的音视频应用,特别是安防产业中近年来1080P超高清分辨率IPC的普遍使用,对于算法的并行性和效率提出的越来越高的要求具有十分重要的意义。
概述
目前业内基于DSP的算法优化主要是基于DSP芯片本身硬件优化和运行于DSP的算法本身的设计优化。TI公司的C6000系列DSP具有许多架构上的优势,使得C6000很适合实时应用领域和对运算要求特别高的场合。但是为了充分的发挥C6000架构的特点,我们有必要做代码优化。本文首先介绍5个关键性技术用于理解C6000 DSP架构和优化。然后介绍在实践中遇到的问题以及采用这5种优化技术所产生的效果。
C6000系列优化的5个关键技术
C6000 DSP中为并行化处理设计的处理器核心和为高吞吐量设计的流水线技术使得其在工业应用中具有出色的表现。所以C6000的工业应用中的优化的目的就是尽可能充分的利用DSP 处理器核心和流水线技术。
C6000的优化涉及5个关键技术如下:
DSP core,DSP处理器核心,为并行化处理设计;
DSP pipeline,DSP pipeline技术,为高吞吐量设计;
Software pipelining,指令派度策略可以提高pipeline的使用率;
Compiler optimization,开发者配置编译器并引导编译器的整个编译过程,可以进行代码级和文件级优化;
Intrinsic operations,C6000系列编译器固有的库以及inline函数。
DSP C6000 Core
简化的加载/存储架构
图1描述的是一种简化的加载/存储架构,其中包含负责执行所有指令的处理器单元和大量的用于存储指令执行过程中的操作数和数据的寄存器。所有将要执行的指令从内存中获取(指令的地址存储在程序计数寄存器中)并按照顺序送入处理器单元。数据可以通过加载指令从内存中到寄存器中且寄存器数值可以通过存储指令放入到内存中。
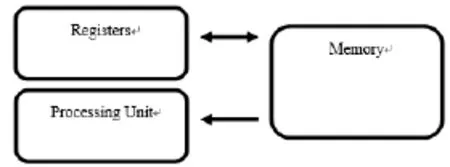
图1 一种简化的加载/存储架构
乘法与累加算法演示
数字信号处理中最常用的操作是乘法与累加,在FIR(Finite Impulse Response,有限脉冲响应)滤波器和FFT(Fast Fourier Transform,快速傅里叶变换)变换算法中使用的很多。Example 1显示的是使用C语言编写的乘法和累加循环代码。
Example 1:
for(i=0;i〈count;i++)
{
prod = m[i]*n[i];
sum += prod;
}
Example 2是用伪汇编语言编写的乘法与累加循环操作。
Example 2:
/*
pointer_m & pointer_n represent registers used to hold the address of the data in memory.
data_m, data_n, data_product, data_sum,and data_count represent registers used to hold actual data.
The branch instruction (with a condition enabled) tells the CPU to jump back to the top of the loop (loop_top) if the value in the data_count register is not zero.
loop_top:load *pointer_m++, data_m
load *pointer_n++, data_n
multiply data_m,data_n,data_prod
add data_prod,data_sum,data_sum
substract data_count,1,data_count
if(data_count !=1) branch loop_top
假设Example 2中的代码在图1所示的架构CPU核心中执行,每一个循环周期CPU需要执行6条指令。为了完成整个循环需要CPU花费6个指令周期,所以具有很大的优化空间。
C674x流水线技术
以上介绍的CPU架构对于一条指令的处理分为三步。第一步为取指令,第二步为指令解码,第三步为指令执行。对应于CPU的工作为第一步从内存中获取指令,第二步为解析指令,第三步为完成操作。为了使得系统性能最大化,就要充分的发挥硬件支持,而解决的办法就是多指令流水技术。

表1 具备流水线和非流水线技术CPU对比
从表中可以得出使用流水线技术的CPU比不使用流水线技术的CPU效率和吞吐量至少高50%。
软件流水
软件流水技术是指在循环中使用并行运算技术以尽量的发挥CPU的并行处理能力。我们用以下代码演示软件流水的技术过程。
Example 3:在内存中累加15个变量
解决方案1:传统的指令分布:重复以下代码15次,汇编伪代码如下:
Load *pointer_value++, data_value
Add data_value, data_sum
解决方案2:软件流水技术,汇编伪代码如下
Load1 Load2 Load3 Load4 Load5
Load6 Add1 Load7 Add2 …
在解决方案1中使用了非流水线技术,它每次要耗费CPU6个时钟周期完成取指令和加指令。整个操作过程中,CPU需要耗费90个时钟周期,其中没有使用并行技术,在绝大多数的时钟周期中硬件的并行性都没有用到。在解决方案2中使用了软件流水技术,在Load1执行后Load2马上执行,以后的时钟周期都会多执行一个Load指令。另一方面Add1在第6时钟周期执行。从代码执行级别来看和解决方案1类似,但是如果从CPU执行角度看完成内存中15个变量的只需要20个时钟周期,比解决方案1效率和吞吐量快4.5倍。
编译器优化
编译器优化指的是使用C编译器产生汇编代码文件,过程中要求最大化地使用C6000的核心功能性单元和CPU核心的流水线。TI官方推荐使用C语言进行应用开发,便于以后的应用更新和移植。C语言编译器负责生成高度优化的汇编语言文件,并且支持大量的与优化和调试配置选项。一般情况下编译器会生成高度优化的汇编代码文件,但是许多情况下为了保证执行的正确性,我们采取保守的方法,也即开发者提供额外的信息和指令给编译器去引导编译器的编译过程从而达到最大优化。
通常引导编译器优化过程的方法有:
控制优化过程的编译器选项;负责处理所有的编译器输入文件,例如—opt_level控制编译优化过程达到的程度。
;C674x C语言编译器支持多个ANSI C和C6000关键字,这些关键字添加到要优化的函数或者对象之前。
编译指令;告知编译器如何处理特别的函数和对象或者代码段。例如MUST_INTERATE添加到一个循环前,规定了循环的最小和最大循环次数。
显式代码优化
编译器优化是一种非常有效并且节约时间的优化方法,但是在循环中调用函数或者开发者要实现复杂的操作情形下,编译器优化就不能满足要求了。C674x提供了三种方法分别是内置操作,DSP库函数,C内联函数。
C6000功能性单元支持大量的复杂的函数,例如shuffle算法(将某个32 bit变量按照奇数位、偶数位分拆成两个变量)的实现在内置操作中2个时钟周期即可完成,但是如果用C代码实现则需要大量的代码耗费大量的时钟周期。为了帮助开发者在类似的情形中进一步地提升性能,C6000提供的内置操作类似于函数声明,使用下划线进行特别说明。如shuffle位操作可以调用_shfl。对于许多的信号和数学操作不必全部使用内置操作,因为TI提供了高度优化的软件库,例如FastRTS和DSPLIB。库中的函数可以用来减少开发和优化的时间,也可以用来作为内置函数使用的参考示例。例如DSPLIB中的基于混合基函数的反傅里叶变换DSPF_sp_iffSPxSP很好地综合了显示代码优化技术。
快速傅里叶变换FFT算法优化
依据递归计算FFT的算法步骤是:第一步将输入数组元素进行反置变换,第二步遍历树的每一层,第三步遍历一层中每一对数据,第四步根据这一对数据和蝶形公式计算上一层;其中涉及的复数和向量的运算代码归并为两个类。
C6000的FFT算法对于输入的每一帧图像看做是线性数组进行处理,在串口上打印出每一帧的处理时间和当前帧速。当输入为1080P图像时候,帧速为4~5FPS,而采用了内置操作、编译器优化、DSPLIB、SRam双缓冲之后帧速可以提高到24FPS,基本满足人眼对于视频的实时性和连贯性要求。
总而言之,TI C6000 DSP的优化技术在目前的超高分辨率音视频解决方案中得到越来越多的使用,合理的采用和平衡优化技术对于提高算法的效率、并行性和实时性要求具有十分重要的意义。
10.3969/j.issn.1001-8972.2015.01.035
*/
猜你喜欢
数学小灵通·3-4年级(2021年9期)2021-10-12
计算机研究与发展(2021年3期)2021-04-01
小学生学习指导(低年级)(2020年10期)2020-11-09
小学科学(学生版)(2020年2期)2020-03-03
铁道通信信号(2020年7期)2020-02-06
电子制作(2019年19期)2019-11-23
计算机与网络(2019年9期)2019-10-21
永善文学(2017年1期)2017-07-18
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·A版(2016年4期)2016-04-16
