
关联规则在青少年违法犯罪预防中的应用研究
2015-11-13 11:28王海燕陈红伟
电脑知识与技术 2015年23期
王海燕++陈红伟


摘要:近年来青少年违法犯罪问题已经越来越成为亟待解决的社会问题,如何提出科学的有坚实理论依据的建议一直是研究的关键。本文将数据挖掘技术应用到青少年违法犯罪研究中,利用关联规则寻找青少年违法犯罪中隐藏的不直观的规律,比如多种罪行之间的关联以及外部环境对青少年犯罪的影响等。同时对相关实例数据进行关联规则分析来实现这个理论,最后得到了令人信服的结果,并根据这些结论提出了具有针对性的建议。
关键词:青少年;违法犯罪;预防;数据挖掘;关联规则
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2015)23-0003-02
The Application Research of Association Rules in Adolescent Illegal Crime Prevention
WANG Hai-yan,CHEN Hong-wei
(Computation Center of Laboratory Management Apartment,Zhengzhou Institute of Aeronautical Industry Management,Zhengzhou 450046,China)
Abstract: Adolescent illegal crime in recent years has become a pressing social problem to be solved and the research key of it is how to put forward the advice with a solid theoretical foundation. In this paper data mining is applied to the adolescent illegal crime prevention and using association rules to find the rule of not intuitive, for example, the link between various crimes and the external environments influence on juvenile crime. To achieve this theory, analyze the relevant instantiate data with association rules and get the convincing results. At last the pertinent advices are put forward according to the conclusion.
Key words: adolescent; illegal criminal activity; prevention; data mining; association rules
如今青少年违法犯罪事件层出不穷,更有犯罪人数不断增多,犯罪年龄不断下降,犯罪越来越类型复杂等趋势。因此找出青少年的犯罪规律,有效预测,对有犯罪倾向的青少年多多加以疏导和关注,及时有效的阻止犯罪行为的发生迫在眉睫。
文献已有研究青少年违法犯罪预防的,比如文献“犯罪少年心理特征调查与教育建议”[1],是通过直观问卷调查的方式进行总结给出建议;文献“预防青少年犯罪研究”[2]是根据多年青少年管理工作经验研究提出青少年犯罪的预防和矫正对策。二者皆是根据社会经验来判断分析,缺乏有力的数据依据。所以本文尝试将数据挖掘中的关联规则分析应用到青少年违法犯罪预防的研究中来,找出隐含的不直观的犯罪规律,为预防工作提供强有力的数据支持和指导意见。
1 相关概念介绍
1.1 数据挖掘
数据挖掘,顾名思义是从大量数据中挖掘有趣模式和知识的过程[3],它融合了统计学、可视化、数据库技术、算法分析与设计、机器学习等不同学科和领域的知识。数据挖掘可发现多种类型的知识,主要是广义知识、关联知识、分类知识、聚类知识和偏差知识。
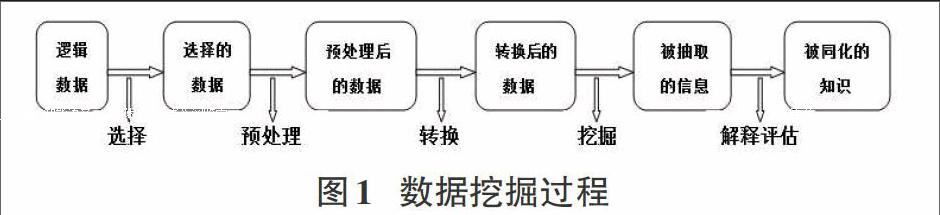
对所有知识类型的挖掘流程主要分三大步骤:数据准备,数据挖掘,模式评估。其中数据准备又包含数据选择、数据预处理和数据转换等阶段。整体流程如图1所示[4]。
图1 数据挖掘过程
1.2 关联规则
关联规则反映一个事物与其他事物之间的相互依存性和关联性。如果两个或者多个事物之间存在一定的关联关系,那么,其中一个事物就能够通过其他事物预测到。主要应用在购物篮分析、交叉销售、产品目录设计等方面,此外对分类、聚类和其他挖掘任务也有帮助。
进行关联规则挖掘的过程中为了寻找有趣的规则,需要两个关键性的度量,支持度与置信度。支持度s是指D中包含A和B的事务数与总的事务数的比值,如公式1所示;置信度c是指D中同时包含A和B的事务数与只包含A的事务数的比值,如公式2所示。
s ( A?B ) = P ( A∪B ) (1)
c ( A?B ) = P ( B∣A ) (2)
2挖掘过程
下面依次经过案例搜集、数据实例化、算法分析、结果解释和提出针对性意见等步骤来实现将数据挖掘应用到青少年违法犯罪预防中的理论。
2.1 数据预处理
本文所用数据为网络公示案例,第一步搜集真实可靠的案例,第二步实例化数据,第三步将数据保存到关系数据库中,第四步总结数据取值的值域,对数据进行离散化规范化等处理,具体处理标准如表1所示。
2.2 算法描述
Aprirori算法为关联规则技术分析中应用广泛且成熟的经典算法,因此本文也选用此算法建模对数据进行关联分析。Apriori具体步骤如下:
本算法大致分两步进行,第一步是找出所有大于等于最小支持度阈值min_support的频繁项集,第二步是找出频繁项集之间的强关联规则,即大于等于最小置信度阈值min_conf。
2.3 结果分析
通过将整理后的数据利用Apriori算法进行关联规则分析,满足最小支持度及最小置信度等条件,其中最小支持度定义为30%,最小置信度定义为20%,最后所得规则集如表3所示:
表3为满足最小支持度及最小置信度的规则,第一列为规则集,第二列为该规则集对应的置信度,如第一条规则“{13-14,男,暴力,网瘾}斗殴”,置信度为“50%”,解释为年龄为13-14岁,家庭有家暴行为且自身有网瘾的男性少年在所有的犯罪类型中,“斗殴”所占比例高到50%。可见其成长背景对孩子的性格养成影响有多大。其他规则可依此进行解释。
规则集中绝大多数理解起来都很直观,但是规则“{男,城市,小康,放任不管,烟酒}盗窃抢劫”却有些费解,为什么小康家庭的孩子还会有盗窃抢劫的行为呢,一般这种家庭的孩子很少出现零花钱不够的情况,在结合了相应案例之后发现,同学之间的攀比是直接诱因,为了满足虚荣心,满足“别人有的我要有,别人没有的我也要有”的欲望,继而走上了犯罪的道路。由此可见数据挖掘在发现不直观的知识方面很有优势。
通过规则集的解释和总结不难发现, “网瘾”和“放任不管”出现的频率很高,其次是 “单亲”、“辍学”、“烟酒”出现频率也较高,“留守”、“溺爱”和“吸毒”等因素也对青少年犯罪起到了推动作用。其他可以发现青少年犯罪以男生居多,年龄也多集中在“15-17”岁。
2.4 对策制定
由以上规则集及总结可以很明显地发现社会、学校和家庭对青少年引发犯罪行为的重要影响。由于青少年正处于生理和心理发育的关键阶段,还未树立正确的人生观、世界观和价值观,并且对世界有强烈的求知欲望,因此需要从社会、学校和家庭三个方面共同努力来预防青少年走上违法犯罪的道路。
社会方面,加强对网吧酒吧的监管,严格禁止未成年人进入,加大相关处罚力度;相关部门及时整顿游戏厅录像厅网吧等场所,对青少年有危害的要坚决打击;净化社会风气,整顿文化市场,坚决查处传播暴力、淫秽及伪科学等不健康的出版物,严格审查面向未成年人的游戏软件。努力为青少年营造积极向上的健康的社会成长环境。
家庭方面,众所周知父母的言行对子女的成长影响最大。因此父母应该为青少年营造良好和睦的家庭环境气氛,对青春期的孩子多多关注,与学校多沟通,及时了解其心理历程,防止青少年沾染不良嗜好,如果青少年染上了“网瘾”、“烟酒”甚至是“吸毒”等行为,要及时同老师或心理医生一起与青少年多沟通,帮助其矫正戒除恶习,重新树立对生活的热爱和信心。
学校方面在注重成绩的同时要加强法律基础教育,同时营造良好的校风及学风,遏制攀比虚荣等不良风气;丰富校园文化,使学生热爱校园生活,消除社会负面影响;加强管理机制,严肃校纪校规,正确规范和约束学生的行为;与家长多沟通,对问题学生要多多关注,及时引导。帮助引导青少年走健康向上积极进取的道路。
3 总结
本文将关联规则应用到青少年违法犯罪的预防工作中,相比传统的统计总结方法而言,不仅可以发现不直观不易发觉的规律,而且每条规则还有准确的数据支持,对后续方案策略的制定有了更详细更明确的指导作用。
下一步尝试将聚类分析、分类分析也应用到此工作的研究中,利用聚类将具有相似特征的青少年聚成一簇,使教育工作更有效,利用分类根据青少年特征预测其可能的犯罪行为,重点关注,多做工作,避免问题少年走上犯罪道路。
参考文献:
[1] 冯春.犯罪少年心理特征调查与教育建议[J].云南大学学报法学版,2008,21(4):84-89.
[2] 周伦文,郭劲.预防青少年犯罪研究[J].天府新论,2004(Z2):146-147.
[3] Jiawei Han, Micheline Kamber. Data Mining Concepts and Techniques[M]. 范明,孟小峰.译.3版.北京:机械工业出版社,2004:4-17.
[4] Fayyad U, Piatetsky S G, Smith P. The KDD process for extracting useful knowledge from volumes of data[J]. Communications of the ACM,1996,39(11):27-34.
猜你喜欢
电力与能源(2017年6期)2017-05-14
中学课程辅导·教师教育(中)(2016年9期)2016-10-20
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
