
基于AST的网页木马解混淆技术*
2015-11-02 05:51项家齐王轶骏薛质
信息安全与通信保密 2015年4期
项家齐, 王轶骏, 薛质
(上海交通大学信息安全工程学院,上海200240)
0 引言
网页木马是最近几年非常流行的一种恶意代码分发的形式,它通常被用作一种自动向受害者植入恶意程序的手段。网页木马一般是由一段或者一系列互相有链接关系的恶意的HTML片段以及恶意脚本所构成,它通常位于正常网页之中。当客户端访问该网页时,会同时加载和渲染网页木马所嵌入的代码,导致浏览器本身以及相关的插件中的漏洞被利用,从而可以隐蔽地下载恶意程序并进行安装、执行。国外一般称这种类型的攻击方式为drive-by-download attack[1],即“下载驱动型攻击”。
近年来网页木马也不断进化,从最初的不成体系的特征明显的单一攻击代码,转而形成了一系列复杂的、具有良好可扩展性的恶意代码框架[2],这类框架被称之为exploit kit,即“漏洞利用工具包”。这些工具包提供了对多种的恶意代码的支持,其不仅引入了多种多样的躲避和反制检测的机制,同时还兼具有自动化的部署和攻击支持,并且生成的也不再是针对单一漏洞或者某一特定软件进行攻击的代码,而是多种恶意代码的复合代码。这一系列的特性使得攻击者所需要达到的技术门槛大大降低,而其危害程度则大大增加。面对这种网页木马进化的趋势,检测和防御方也有必要对网页木马的样本的代码特征进行抓取和分析,以了解其流行态势和新近的躲避和反制检测的机制。
本文主要关注网页木马为了隐藏自身并提高攻击成功率而引入的混淆技术,通过利用抽象语法树(Abstract syntax tree,下文中称AST)对网页中的脚本进行分析和预处理,再利用低交互式客户端蜜罐的模拟浏览器和模拟脚本执行的上下文环境,从而达到解混淆的目的。通过利用这种解混淆技术,可以降低分析网页木马的门槛,为研究其特点、工作机制和攻击特性提供宝贵的分析数据,从而为进一步的研究提供了一种新的思路。
1 相关研究
1.1 人工分析
对于网页木马的人工分析通常是利用一些静态分析用的工具,首先抓取被挂马网页的HTML源码,然后人工查看其中是否存在可疑的混淆代码或者攻击代码,然后利用这些静态工具中提供的一些简单的解混淆函数或者功能来进行解混淆分析。这种分析方法对分析人员的经验要求较高,需要能够正确地发现混淆代码并挑选出正确的解混淆功能来使用。
另外一种常见的人工分析的手段是利用一些浏览器或者工具中存在的调试功能,跟踪被挂马网页的加载过程,从而发现其中的可疑的混淆代码或者攻击代码,并利用一些调试功能对这些代码进行人工解混淆和分析。比如Firefox插件JavaScript deobfuscator[3]。
1.2 基于展开(unfolding)的自动化解混淆
基于展开的自动化解混淆是当前被最为广泛使用的一种对网页木马代码进行自动解混淆和分析的手段。网页木马的攻击代码中经常使用一系列的可以动态执行代码的函数,比如eval()和document.write()函数来避免攻击代码的直接出现,以躲避特征码等静态检测方法。利用这一特点,基于展开的自动化解混淆系统给出了以下这样的一种假设:“被混淆前的原始攻击代码一定会在某一个javascript上下文环境中以明文出现。”
基于这一假设,许多网页木马检测系统都引入了解混淆的能力,如 Zozzle[4],JSAND[5]等。
这种自动解混淆手段是相对成熟有效的,但是Lu等人提出了可以精心构造出一种违反上文中假设的混淆代码[6],使得大多数基于展开的自动化解混淆手段无法有效地完成解混淆。
1.3 基于代码行为语义分析的自动化代码解混淆
基于代码行为语义分析的自动化代码解混淆是由Lu等人提出的一种对javascript混淆代码进行解混淆的手段[6]。这种手段并不追求完全还原出原始的攻击源代码的解混淆方式,而是通过保持语义的方式来进行解混淆。Lu等人认为如果两段代码和他们的执行上下文环境以相同的方式进行交互,则可以认为这两段代码是观察等价的,可以互相取代的,Lu等人称这种等价为“语义保持”。
基于这种思路Lu提出了根据代码对系统调用的参数的影响来判别其是否是“语义相关”的方法,并通过javascript的字节码层面上的分析,从而生成相对于混淆代码“语义保持”的解混淆代码,完成对代码的解混淆。其他类似的系统还包括 JSOD[7]等。
2 基于AST与蜜罐解混淆系统
本文第1节中所提到了两种自动化代码解混淆的手段各有其优势和缺点,基于展开的自动化解混淆较为成熟有效,但是存在被躲过的方法;而基于代码行为语义分析的自动化解混淆采用的“语义保持”的等价方法还原出的并不是原始的攻击代码。
针对这些问题,本文提出了一种自动解混淆的原型系统,在基于展开的自动化解混淆技术上进行扩展,引入AST和开源客户端蜜罐Thug[8],以实现更加准确有效的解混淆。
2.1 系统简介
如图1中所示,系统主要由三部分组成:
(1)AST预处理模块
(2)混淆信息采集模块
(3)混淆代码还原模块

图1 系统基本结构
首先向系统输入含有混淆后代码的被挂马页面,系统的AST预处理模块解析页面中的脚本代码并生成对应的AST,然后对AST进行预处理后并还原为脚本,以便通过客户端蜜罐采集相关的混淆信息;混淆信息采集模块主要利用客户端蜜罐本身的功能,从而采集到一些脚本的运行时信息;在混淆信息采集模块采集到相关信息之后,再由混淆代码还原模块对最初生成的AST进行处理,最后根据处理后的AST还原出解混淆后的脚本代码,完成一次“展开”的解混淆,而输出的脚本代码可以再一次输入系统,从而实现“多次展开”的解混淆。
2.2 抽象语法树(AST)
抽象语法树是一种用于表示源代码的抽象语法结构的树状结构。一般来说,直接对源代码的处理是相对复杂困难的,而将其转换为抽象语法树后,各个结点的属性和位置将会变得更便于处理,而抽象语法树本身并不依赖于源语言的文法,从而使得可以通过一些简单通用的方法来处理抽象语法树,达到对源代码的分析和处理的目的。其定义如定义1所示。
定义1给定一个图G=(V,E),V是图中所有节点的集合,E是图中所有边的集合,若其满足以下条件:
G是无向树
∀v∈V,v满足:
v={p1,p2,...,pn},
pi:< key,value> or<key,v'> ,v'∈V
∃pi∈v,pi:< ″type″,value >
∀e∈E,e=(v1,v2),v1,v2∈V
∃p∈v1,p:< key,v2>
则称图G为一个抽象语法树;称V中的所有节点为语法结点,代表着语言的基本结构;称每个节点所包含的元素p为节点属性,代表语言基本结构的一些属性,key为属性名,value为属性值;称E中的所有边为语法关系,代表着语言基本结构之间的关系。
由于各类主流的javascript解析引擎在其支持的语法标准上存在一定的差异,本文以最通用的 ECMAScript 5.1标准[9]为基准,参照Mozilla Parser AST[10]中设计的接口和定义来表示一棵抽象语法树。图2给出了一段javascript代码所对应的抽象语法树。

图2 一个抽象语法树的例子
2.3 AST 预处理
对于一份输入被挂马页面,首先要解析出其中所包含的javascript脚本,然后再分别将各部分javascript脚本解析为AST,进行预处理后,最后再还原为javascript脚本。AST预处理的工作过程如图3所示。

图3 AST预处理过程
脚本解析部分由Thug中的Beautiful Soup 4负责,通过解析HTML源代码,根据标签来取得所需要的javascript脚本代码;AST解析部分则利用 Esprima[11]来获得一个符合 Mozilla Parser AST标准的以JSON表示的AST字符串,并解析JSON来将其转换为一个真正的AST对象;随后对AST对象进行预处理,并在AST对象中生成信息采集表;最后利用Escodegen[12]将处理后的AST重新转换为javascript脚本代码,与处理后的AST对象一同交还给Thug继续进行处理。处理过程的算法如算法1所示。

算法1 预处理算法
2.4 混淆信息采集
经过预处理的javascript脚本代码中包含着一系列回调语句,当Thug的脚本引擎V8执行到预处理中嵌入的回调语句时,会触发Thug调用对应的处理函数,通过嵌入特定的回调语句并实现Thug中对应的处理函数可以使得Thug在运行中采集到系列与混淆有关的信息,如回调位置,当前调用函数的参数等等,Thug会将这些信息存储入对应AST对象的信息采集表中,以供后续混淆代码还原时使用。
2.5 混淆代码还原
通过预处理和信息采集后,AST对象中已经包含了原始脚本预处理后的AST的和相应采集的信息,首先利用算法2中所描述的混淆代码还原算法来对AST对象进行解混淆处理,随后再通过Escodegen将处理后的AST对象转换为javascript脚本代码,最后输出的即为完成一次“展开”后的javascript代码。

算法2 预处理算法
2.6 多次展开
由于混淆代码的日益复杂,一次“展开”操作并不能完全还原出javascript代码的原貌,这时需要对代码进行多次“展开”。当获得一次“展开”后的javascript代码后,将其取代挂马网页中对应的原来的代码,再将处理后的挂马网页作为新的挂马网页重新输入系统,得到的输出即为二次“展开”的javascript代码,重复进行多次这样的操作即实现了多次“展开”。当结果输入系统后不再触发解混淆操作,即混淆信息采集过程中采集不到信息时,认为系统已经无法再对代码进行解混淆,此时输出和输入将会相同,再进行更多次的“展开”已经无法得到更多有用的信息,可以结束多次“展开”的过程。
3 基于AST与蜜罐解混淆系统
本文基于前文中阐述的解混淆技术,基于低交互式蜜罐Thug,AST解析模块Esprima和AST还原模块Escodegen,实现了一套原型系统,并采用了一系列的测试用例来对系统的有效性进行了验证。测试用例主要分为3类:人工构造的功能性测试网页、真实被挂马网页和对照用的正常网页,以下将逐一给出各类网页的实验结果。
3.1 人工构造的功能性测试网页
这里选取了一个人工构造的含有多重混淆的斐波那契数列计算代码为例对原型系统进行测试,其原始代码如图4所示:

图4 功能性测试原始代码
构建一个包含这段代码的页面并输入原型系统后,输出的代码如图5所示。

图5 一次“展开”后的代码
继续将输出的代码输入原型系统,代码展开的过程如图6中所示。
在最后的结果中,除去一些混淆中使用的多余的变量声明残留外,系统已经完全还原出可读的完整的斐波那契数列的计算代码,验证了原型系统的功能性。
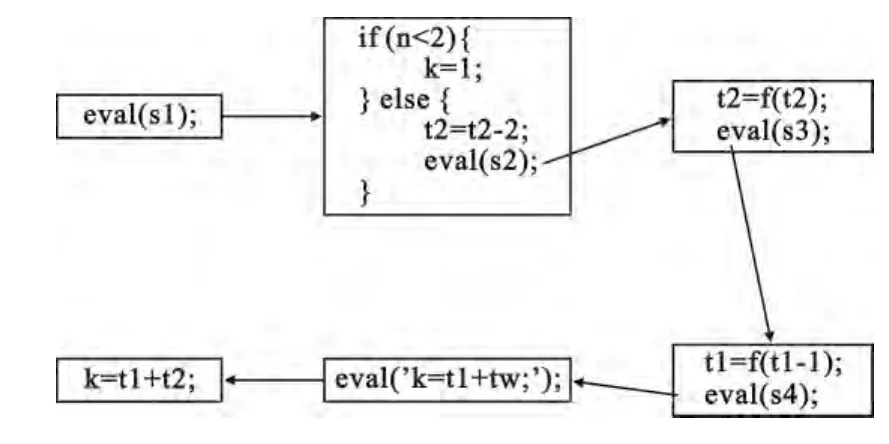
图6 多次“展开”的过程
3.2 真实被挂马网页
本文收集了五个最近抓取获得的真实的被挂马网页来对原型系统进行验证性测试,被挂马网页皆来源于网上公开公布的列表,并经过人工验证的确包含混淆后的恶意代码。该部分实验的测试结果如表1所示。
测试网站用例1的解混淆结果与人工解混淆的结果相比缺少了一个根节点的儿子节点及其子女,原因在于该部分代码是根据不同浏览器环境分别触发不同恶意代码,通过修改Thug中的一些模拟浏览器的设置后即可抓取到该儿子结点及其子女。测试网站用例3的解混淆结果中则缺失了一个单一的叶子节点,原因在于该节点对应恶意脚本的地址已经不再有效而无法访问到。对于这种由于恶意代码特性以及地址失效而导致的部分缺失是非致命的,可以认为系统仍然是正常工作的,故根据实验的结果可以验证系统的可用性和有效性,但同时也说明系统仍然欠缺一些适应性,仍然需要部分人工的介入来确保解混淆的完整。

表1 对于真实被挂马网页的测试果
3.3 供对照的正常网页
这里选取了几个国内外著名网站的首页来对实现的原型系统进行测试,并与直接查看到的源代码进行比较,以验证原型系统面对不含混淆的正常网页也能够正常工作。测试结果如表2。
通过对正常网页的测试结果的分析,可以认为系统在面对各类网页时基本能够稳定正常地工作。

表2 对于正常网页的测试结果
4 结语
本文提出了一种基于低交互式客户端蜜罐和抽象语法树分析和重构的网页木马解混淆技术,通过对代码的多次展开,以达到对网页木马的攻击代码进行解混淆的效果。本文实现了一套原型系统,并采用了多种类型的无混淆和混淆后的页面对系统进行了测试,从而验证了该解混淆技术的有效性。但是原型系统依然停留在验证性阶段,部分功能存在缺陷,多次“展开”也尚处于需要人工介入的阶段,下个阶段将进一步提高原型系统的可用性和适应性,以期能更好地面对各类网页木马中的混淆技术。
[1] DAY O,PALMEN B,GREENSTADT R.Reinterpreting the Disclosure Debate for Web Infections[M].Managing Information Risk and the Economics of Security.Springer.2009:179 -97.
[2] 张慧琳,邹维,韩心慧.网页木马机理与防御技术[J].软件学报,2013,24(4):843-858.
[3] PALANT W.FireFox add-on:JavaScript deobfuscator[EB/OL].(2013-07-30)[2014-11-26].https://addons.mozilla.org/en - US/firefox/addon/javascript- deobfuscator/.
[4] CURTSINGER C,LIVSHITS B,ZORN B G,et al.ZOZZLE:Fast and Precise In-Browser JavaScript Malware Detection[C]//Proceedings of the 20th USENIX conference on Security(SEC'11).Berkeley,CA,USA:USENIX Association,2011:3-3.
[5] COVA M,KRUEGEL C,VIGNA G.Detection and Analysis of Drive-by-Download Attacks and Malicious JavaScript Code[C]//Proceedings of the 19th International Conference on World Wide Web(WWW'10).New York,NY,USA:ACM,2010:281-290.
[6] LU G,DEBRAY S.Automatic Simplification of Obfuscated JavaScript code:A semantics- based Approach[C]//2012 6th International Conference on Software Security and Reliability.Gaithersburg,MD,USA:IEEE Reliability Society,2012:31-40.
[7] AL-TAHARWA I A,LEE H M,JENG A B,et al.JSOD:JavaScript obfuscation detector[J].Security and Communication Networks,2014.
[8] DELL'AERA A.Thug[EB/OL].(2014-11-11)[2014-11 -26].https://github.com/buffer/thug.
[9] ECMA International.ECMA -262,ECMAScript Language Specification Edition 5.1[S].Geneva:ECMA International,2009:1-245.
[10] NETWORK M D.Mozilla Parser AST[EB/OL].(2014-09 -22)[2014 -11-26].https://developer.mozilla.org/en-US/docs/Mozilla/Projects/SpiderMonkey/Parser_API.
[11] HIDAYAT A.Esprima[EB/OL].(2014-10-07)[2014-11 -11].http://esprima.org/
[12] SUZUKI Y.Escodegen[EB/OL].(2014-10-31)[2014-11 -26].https://github.com/Constellation/escodegen.
猜你喜欢
作文小学中年级(2022年11期)2022-11-25
娃娃乐园·综合智能(2021年11期)2021-12-06
科普童话·学霸日记(2021年6期)2021-09-05
课堂内外(小学版)(2020年11期)2020-12-04
中外文摘(2019年20期)2019-11-13
读友·少年文学(清雅版)(2019年6期)2019-10-15
知识窗(2019年6期)2019-06-26
系统管理学报(2018年3期)2018-08-13
创新作文(小学版)(2018年34期)2018-05-23
中学生(2017年19期)2017-09-03
