
决策树模型用于结核病治疗方案的分类和预判
2015-11-01 03:41张琪周琳陈亮张晋昕温兴煊何贤英
中国学术期刊文摘 2015年19期
张琪,周琳,陈亮,张晋昕,温兴煊,何贤英
(1.中山大学公共卫生学院医学统计与流行病学系,广州 510080;2.广东省结核病控制中心,广州 510630)
专家推荐
决策树模型用于结核病治疗方案的分类和预判
张琪1,周琳2,陈亮2,张晋昕1,温兴煊1,何贤英1
(1.中山大学公共卫生学院医学统计与流行病学系,广州 510080;2.广东省结核病控制中心,广州 510630)
学科:流行病与卫生统计学
推荐专家:王斌副教授(安徽医科大学)
推荐论文:张琪,周琳,陈亮,等. 决策树模型用于结核病治疗方案的分类和预判[J]. 中华疾病控制杂志,2015,19(5): 510-513
·专家点评·
该文创新性地利用分类精度高、对数据噪声具有稳定性、且提取规则易量化与理解的数据挖掘方法——决策树构建结核病治疗方案的预测与分类模型,结果表明,初发、因症就诊且痰涂片搞酸染色阳性患者多采用2HRZE/4HR治疗方案,而初发、痰涂片搞酸染色阳性患者多采用个性化治疗。
该文重要意义表现在:研究结果有利于临床医生根据结核病患者病史、临床症状、检验结果等,对治疗方案做出更为准确地预判和指导;采用的决策树数据挖掘模型,能够充分利用患者临床资料信息等,为其他慢性疾病治疗方案选择的研究方法及研究思路提供相应的借鉴;对研究者为适应当今医学发展,即由经验医学、实验医学转向以证据为基础的循证医学,以满足医学大数据时代的要求,把决策树及其他数据挖掘技术运用于临床资料或医学其他等信息的分析有一定的启迪作用。
文章决策树建模采用的统计分析软件是SPSS Modeler,无需编写程序,易于操作与实施,医学研究者进行数据挖掘的技术瓶颈则显得荡然无存,运用SPSS Modeler软件进行数据挖掘,在预防医学工作及科研过程中值得普及与推广。
文中讨论虽陈述了研究的不足,但仍有两点稍显匮乏与不完善,1)从全文行文看,作者对决策树建模的系统知识仍未达到瑧善,表现在读者难以一气呵成地阅读并能够透彻理解;2)文章对决策树模型“预判”的灵敏度、特异度及Kappa一致性进行了分析,但如能将灵敏度和特异度结合起来,进一步做ROC曲线,对“预判”做出评价分析,或可更上一层楼。
结核病多年来一直严重威胁着各国人民的身体健康。我国每年大约新增结核病患者100万,占全球的12%,位居世界第2位,是全球22个结核病高负担国家之一[1]。而近来年随着耐多药结核分枝杆菌的出现,结核病的治疗变得越来越棘手和复杂。了解肺结核发病的危险因素,可以对肺结核患者进行风险评估和预测,也可以指导临床医生制定相应的治疗方案。本研究利用数据挖掘中的决策树构建预测模型,并提取决策树规则集,为结核病患者的临床治疗提供参考。
1 资料与方法
1.1资料来源资料来源于广东省结核病控制中心提供的2013年度广州市番禺区结核病专项档案资料,共计1141个研究对象,均为结核病确诊病例,他们来自番禺区的12个街道。其中新发病例1098例,复发病例41例;男性788例,女性353例;年龄最小15岁,最大90岁,平均年龄(39.6±15.1)岁。被调查个体的专档资料经过合并、清洗、去重等预处理形成适合进行决策树建模的数据仓库[2]。观察资料中包含性别、年龄、民族、文化程度、职业、婚姻状况、居住地、病人发现方式(因症就诊、转诊等)、病人管理方式(全程督导、住院、自服药等)、病人登记方式(新发病、复发、初治失败等)、结核病接触史、卡介苗接种史,以及痰涂片抗酸染色、结核菌培养、发热谷草转氨酶等实验室检查、治疗方案、转归情况、治疗时间等40个变量。
1.2研究方法
1.2.1决策树模型的原理决策树模型源于人工智能领域的机器学习技术,用于实现数据的分类和预测。经过多年发展,其核心算法已经逐渐成熟,被各类智能决策系统所采纳。决策树模型的两大特点是:数据分析能力高效准确、结果又直观易懂。近年来数据挖掘这一概念兴起,决策树也成为数据挖掘领域使用最广泛的算法之一[3]。决策树模型的建立围绕2个问题:(1)是决策树的生长,是用训练样本集进行决策树的构建;(2)是决策树的修剪,是用测试样本再精简已经建立的决策树。
1.2.1.1决策树的生长决策树的生长是对训练样本数据集不断地重新分组的过程。决策树模型的各分枝是在数据被不断地分组过程中逐步生长出来的。当某亚组数据继续新的分组不再有意义时,它所对应的分枝就不再生长。而当所有的数据分组都不再有意义时,决策树将会不再生长,此时完整的决策树就建好了。而建立决策树模型时所采用的核心算法不同,决策树的分枝准则也有所不同。
1.2.1.2决策树的修剪建好的决策树模型虽然对样本数据的拟合得非常好,但是可能因此失去一般代表性而无法用于对新数据的外推应用,出现了所谓的过度拟合。在决策树模型构建中解决此问题的方法就是对建立的决策树进行修剪,常用的方法有预修剪和后修剪。预修剪是在决策树成长时就对它的规模进行一定的限制,后修剪是先让决策树充分生长,再对其进行修剪。
1.2.1.3C5.0算法原理[4]C5.0算法可以建立多分叉的决策树,自变量可以是数值或者分类型变量,因变量只能为分类型变量。C5.0以信息论为理论基础,用信息增益率来确定最佳的分组变量和连续变量的分割点。信息量的数学定义如下:
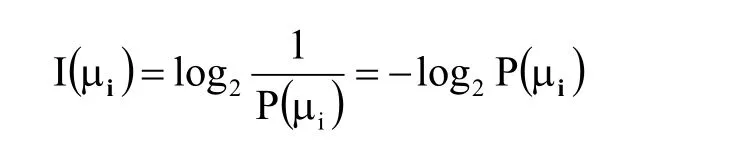
信息量是以2为底的对数形式,它的单位是比特(bit)。而信息熵为信息量的数学期望,其数学定义是:
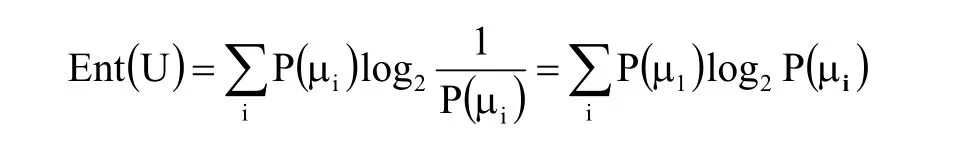
相应的信息增益和增益率为:
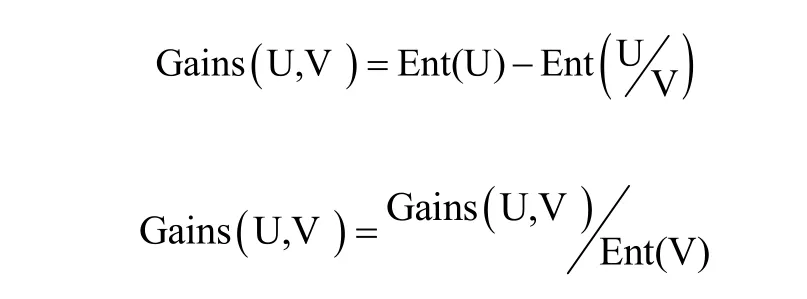
1.2.1.4CHAID算法原理[5]卡方自动交互诊断器(chi-squared automatic interaction detector,CHAID)的核心算法依旧是最佳分组变量以及分割点的确定,基本思路与C5.0相同,但不同的有两点。首先,对于输入变量的预处理。对数值型输入变量进行分箱处理,而合并分类型输入变量的取值。预处理的目的在于减少决策树的分枝,防止过度拟合。其次,根据统计检验的结果确定最佳分组变量以及分割点。输出变量如果是分类型的则采用卡方检验,如果是数值型则采用F检验。
1.2.2决策树算法的选择目前比较常用的决策树算法有:ID3、C5.0、CHAID、QUEST、CART等,其中最早是Quinlan提出的ID3算法[6],其他算法都是在此基础上的改进或拓展[7,8]。但是ID3算法仅能用于分类型变量构建决策树,而不能用于连续型的变量,因此本次研究采用CHAID和C5.0算法建立决策树模型。
1.3统计分析统计描述及一致性分析使用IMB SPSS 21.0,决策树模型建模与预测使用SPSS Moder 14.2。
2 结果
随机抽取70%的个体构成训练样本,30%的个体构成测试样本,分别使用C5.0算法和CHAID算法建立决策树模型。C5.0算法使用自动建模,预期噪声设置为5%;CHAID算法设置最大树状深度为3,以控制决策树生长过于“茂盛”,避免过拟合的问题。另外,停止规则为使用百分比,父分枝最小记录数设置为2%,子分枝最小记录数设置为1%,以防止样本量过小的分枝的出现。为减少样本随机抽样引起的抽样误差,输出类型勾选交叉验证,折叠次数10次。
2.1变量筛选使用SPSS Moder 14.2建立预测模型时可以对各个自变量的重要程度进行排序。使用C5.0算法建模得到的各自变量重要程度从大到小依次为:痰涂片抗酸染色、其他阳性体征和病人登记方式;使用CHAID算法建模得到的各自变量重要程度从大到小依次为:痰涂片抗酸染色、病人登记分类、发热、结核病类型、病人发现方式。
2.2模型建立决策树模型建立后,可以输出树形图,简单易懂,C5.0算法模型输出的树形图见图1。根据树形图也可以提取规则集,见表1,2,表中置信度表示该条规则应用于样本数据的预测成功率,表1、2中赋值情况:结核病类型:1=原发性肺结核,2=血型播撒性肺结核,3=继发性肺结核,4=结核性胸膜炎,5=其他肺外结核;痰涂片抗酸染色:1=未检,2=阴性,3=阳性;病人登记分类:1=新患者,2=复发;病人发现方式:1=因症就诊,2=转诊;发热:0=否,1=是。
2.3模型评估本次研究建模前采用SPSS Moder 14.2的“分区”节点,设立随机数种子,将70%样本797例作为训练样本,30%样本344例作为测试样本。为避免单次分区的抽样误差对结果的影响,在决策树建模的时候需勾选交叉验证。使用CHAID决策树模型训练样本正确率为77.92%,测试样本正确率为76.74%;使用C5.0决策树模型训练样本正确率为90.72%,测试样本正确率为88.37%。说明C5.0算法在构建本次研究的分类预测模型中预测效果更好。
2.4一致性分析由于C5.0算法在本次研究中预测效果更佳,此处仅仅列出C5.0决策树模型对训练样本和测试样本的预测结果与实际情况一致性对比情况,见表3、4。训练样本的灵敏度为95.9%,特异度为86.8%,Kappa系数为0.814,测试样本的灵敏度为96.4%,特异度为82.8%,Kappa系数0.767。
3 讨论
决策树是一种非常重要的数据挖掘算法,具有分类的精度高、提取的规则能量化易理解以及对噪声数据也有比较好的稳健性等优点,在预防医学、公共卫生及临床的辅助诊断等方面已经取得了较好的效果[9-12]。本研究采用决策树的CHAID算法和C5.0算法筛选出一些影响因素,对模型进行评估结果表明,C5.0算法决策树模型预测的准确性高于85%,预测结果与实际情况的一致性也较好,训练样本和测试样本的Kappa系数均高于0.7。由于在SPSS Moder暂不能通过编写程序实现计算,因此要获得较理想的预测模型,需对建模过程中的涉及到的参数进行反复多次调整,采用最优模型。此外训练样本和测试样本的随机选取对决策树模型的稳定性和预测效果也可能有一定的影响,通过建模过程中使用交叉验证的方法可以一定程度避免。临床医生在选择患者的治疗方案时,主要是基于卫生部制定的结核病诊疗指南,仅仅基于是否初治和是否涂阳来选择治疗方案[13,14],而千篇一律的治疗方案是造成结核病广泛耐药的重要原因之一。本研究中CHAID算法提取的规则集显示,结核病类型、痰涂片抗酸染色及病人发现方式、病人登记方式、发热与否会影响治疗方案的选择;而C5.0算法提取的规则集显示,痰涂片抗酸染色、病人登记分类以及其他阳性体征会影响治疗方案的选择。7条规则集有5条置信度高于90%。综合决策树模型产生的规则集,可以发现有如下规律:发现初发、因症就诊且痰涂片抗酸染色阳性的患者多采用2HRZE/4HR治疗方案,而初发、痰涂片抗酸染色阴性的患者以及复发患者多采用个性化治疗。两种算法提取的规则不完全相同,主要原因是两种算法在决策树模型的生长和修剪中的思路和方法不同,C5.0算法主要基于信息学中信息熵的理论,而CHAID算法有对数据预处理的过程,主要基于统计检验的理论[15,16]。本研究利用已有的结核病专档数据,筛选预后良好的1141名结核病患者,利用与治疗相关的40多个变量建立结核病治疗的预测与分类模型,旨在评估和预测结核病患者的患病状态,为临床医生选择治疗方案提供一定的借鉴。此外,本研究的研究思路和方法也可以适用于其他的慢性疾病治疗方案的选择,例如高血压、糖尿病。本研究也有不足一些不足之处,比如纳入研究的变量数较多,而样本量仅有1141,可能会存在样本不足导致检验功效降低的问题。相信随着采集样本和指标的不断增多,使用决策树模型能够对结核病患者应使用哪种治疗方案做出更为准确地预判和指导,从而使结核病患者能够得到更有效的治疗,改善其预后。
医学的发展已经由经验医学、实验医学转向以证据为基础的循证医学,产生的医学数据量大,且具有客观性。临床医生应结合患者的病史、临床症状,逐渐学会使用大样本下建立的数据挖掘模型,分析病情、制定合理治疗方案及预测疾病的发展。决策树模型及其他数据挖掘模型在大数据时代将会体现出更重要的实用价值和经济价值。
责任编辑:吴晓丽
猜你喜欢
保健医苑(2022年5期)2022-06-10
医学概论(2022年4期)2022-04-24
大众科学(2022年3期)2022-04-09
科技创新与应用(2020年6期)2020-02-29
电子制作(2018年16期)2018-09-26
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
智能系统学报(2015年4期)2015-12-27
中国卫生(2015年1期)2015-11-16

- 中国学术期刊文摘的其它文章
- 雾霾难逃气象卫星监测
- 海洋学
- 土壤污染与修复
- 化学
- 2015中国刊博会开幕
- 地质学