
一种改进的动态数据聚集算法及仿真
2015-10-17 00:48苏娇娆
电子科技 2015年5期
苏娇娆
(北京军区总医院 信息科,北京 100700)
一种改进的动态数据聚集算法及仿真
苏娇娆
(北京军区总医院 信息科,北京 100700)
针对当前计算数据中心中的动态数据分配方法中存在局限性强、公式复杂、算法运行效率低等问题,提出了动态数据聚集算法,结合计算数据中心实际情况进行改进,分析了动态数据聚集算法在计算数据中心的应用。仿真结果表明,与常规数据分配方法相比,改进后的基于动态数据聚集算法的数据分配方法,数据分配准确率可达到98.2%,相比常规方法有效地提升了结果的准确率。
动态数据聚集算法;数据分配;计算数据中心;仿真研究
随着当前计算机软硬件升级,人们对数据获取能力的要求也越来越高。基于计算机数据中心数据分配中,在数据中心网络技术基础上,由于数据节点可自由移动,这样将会降低数据分配进度,从而降低系统性能,导致计算机数据中心网络维护开销过高;故此,在计算机数据中心数据分配中,应该改进传统静态数据流数据方法,实现动态数据聚集,减少信息冗余,提升数据计算效率及安全性。
1 动态数据聚集算法
动态数据聚集算法中,聚类是数据挖掘中一类重要的问题,在许多领域有其应用之处。聚类的定义就是给定一个有诸多数据元素组成的集合,文中将其分为不同的组(类、簇),使得组内的元素尽可能相似,不同组之间的元素尽可能不同[1]。在动态数据聚集算法中,其数据流具有以下特点:数据实时达到,数据到达次序独立,不受系统控制;数据量较大,不能预知其大小;单次扫描,数据一经处理,除非特意保存,否则不能再次被处理。由于计算机数据中心数据流的特点,要求数据压缩表达;并可迅速、增量地处理新到达的数据,要求该算法可快速、清晰地识别离群点。
2 应用动态数据聚集算法的优势
计算机数据中心应用的动态聚类算法,应该具备可伸缩性,动态聚类算法还要具有处理不同类型的数据属性的能力,能够发现数据中心数据分配中的任意形状聚类,对于输入参数的领域知识具备弱依赖性,且对于动态聚类算法中或数据中心的输入记录顺序也不敏感,具有处理计算数据中心高维数据能力,具备处理数据中心数据噪声能力[2]。对计算数据中心可能的各种数据组合,均可满足其估算聚类结果质量。同时,对于一个对象Oi,也可被另外的对象代替;对于在数据中心一次迭代中产生的最佳对象集合,也可成为下次数据迭代中的中心点。且在计算数据中心数据聚集以及节点聚集后,可动态分配计算数据中心数据,降低部分区域的工作负荷及能耗。在计算数据中心数据动态聚集后,可提高计算数据中心资源的利用率,提升计算数据中心硬件设备运行稳定性。
3 应用动态数据聚集算法实现
对动态聚类算法中的数据流,在每一个时刻,动态聚类算法的在线部分连续第读入一个新的记录,将多维的数据放置到对应多维空间中的离散密度网格,在第一个gap时间内产生了初始簇[3]。然后,算法周期性地移除松散的网格及调整簇。由于不可能保留原始数据,D-Stream将多维数据空间分为较多密度网格,然后由这些网格形成簇。如图1所示。
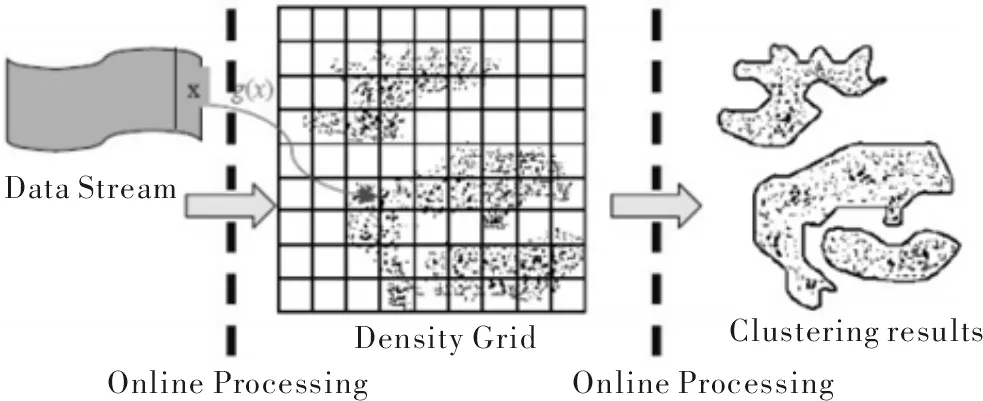
图1 动态聚类算法网格
文本中,假设输入的数据有d维。并在计算机数据中心空间中定义数据
S=S1×S2×…×Sd
(1)
在动态数据聚集中,可将d维的空间S划分成密度网格。假设对于每一维,其空间是Si,i=1,…,d被分为pi个部分。
Si=Si,1∪Si,2∪…∪Si,Pi
(2)
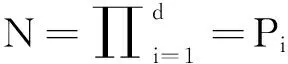
g=(j1,j2,…,jd)
(3)
一个数据记录X=(x1,x2,…,xd)可映射到下面一个密度网格
g(x)=(j1,j2,…,jd)whereXi∈Si,ji
(4)
根据网格密度变动,更新网格密度,当一个新的计算机中心数据到网格,接收记录数据记录,设一个网格g在时刻tn接收到一个新的数据记录,假设g接收到最后的数据记录是在时刻tl(tn>tl),则g的密度可按下面的方式更新。
计算数据中心动态数据聚集算法的实现中,其最基本的计算思想是,在聚集数据的最中心对象,对n个对象给予k个划分区域;并且此代表对象也可以被称为是中心点,而其他的对象为非代表对象[4],反复使用非代表对象替换代表对象,从而动态找出数据中心更好的中心点,改进数据中心聚类质量。
4 动态数据聚集算法仿真
4.1 仿真试验环境搭建
对于计算数据中心动态数据聚集算法,针对动态数据聚集算法实施仿真试验,在一个台PC上进行,用VC++6.0以及Matlab图形接口实现了动态聚类算法仿真[5]。研究其算法性能及结果准确性,数据中心将10个节点存放于一个机架上。环境参数如表1所示。

表1 环境参数表
在动态数据聚集算法仿真试验中,可设置Cm=3.0,Cl=0.8,λ=0.998,以及β=0.3。使用两个测试集[6]。第一个就是测试数据集,也是一个真实的数据集合KDD CUP-99,其包含由MIT林肯实验室收集的网络入侵数据流。也使用人工数据集测试动态聚类算法的伸缩性。这个人工数据集包含的数据数量从35~85 kB不等,簇的数目设定为4,维度的数目范围从2~40[7]。在动态数据聚集算法仿真试验中,将数据集的所有属性规格化为[0,1]。每个维度被均匀地分为多个数据段,每个段的长度为len。
4.2 仿真结果评估
评估计算数据中心的动态聚类质量与效率,其与传统计算数据中心的算法进行比较。提高算法时间、空间效率,对于计算中心高速的数据流不损失聚类质量,有独特的优势,准确地识别实时数据流,并实施演化行为。计算数据中心动态聚类算法与传统数据分配算法相比,数据准确性得到提升,为98.2%,常规数据分配准确率83.6%,有明显优势(P<0.05)。计算数据中心动态聚类算法的应用,可提升计算数据中心系统稳定性。
5 结束语
综上所述,在目前计算数据中心,设计动态数据聚集算法,通过仿真实验进行验证分析,表明动态数据聚集算法,能够保障计算数据中心的服务质量,提高计算机设备稳定性,还可以提升计算机数据中心服务质量,可在不同时段动态分配数据使用,实现有效的聚集数据分配模式,从而确保系统计算存储节点可以轮流运转,提升计算机数据中心区域温控设备精度,充分利用计算数据中心资源,满足用户的实际服务需求,降低计算数据中心系统动态数据分配能耗。
[1] 亓开元,韩燕波,赵卓峰,等.支持高并发数据流处理的MapReduce中间结果缓存[J].计算机研究与发展,2013,50(1):111-121.
[2] 王立,乐嘉锦.基于度量波动时间框架的流立方体研究[J].计算机应用与软件,2011(3):169-172.
[3] 侯东风,刘青宝,张维明,等.一种适应性的流式数据聚集计算方法[J].计算机科学,2010,37(3):152-155,169.
[4] 刘青宝,侯东风.基于查询索引树的多维连续查询计算方法[J].信息工程大学学报,2012,13(1):100-104,114.
[5] 陈伟,陈璟,孙俊,等.一种量子行为粒子群优化动态聚类算法[J].计算机应用研究,2011(7):2432-2435.
[6] 侯东风.流式数据多维建模与查询关键技术研究[D].长沙:国防科学技术大学,2010.
[7] 刘青宝.模糊、动态多维数据建模理论与方法研究[D].长沙:国防科学技术大学,2010.
Algorithm for Dynamic Data Aggregation and its Simulation
SU Jiaorao
(Department of Information,Military General Hospital of Beijing PL,Beijing 100700,China)
The dynamic data distribution algorithm used by the computing data center has the disadvantages of strong limitations,complex formulas,and low algorithm running efficiency.This paper proposes an algorithm for dynamic data aggregation,which is further improved on the basis of the actual situation of the computing data center.Its application in the computing data center is analyzed.Simulation results show that the improved data distribution method based on the dynamic data aggregation algorithm can achieve a data distribution accuracy rate of as high as 98.2%,as compared with the conventional data distribution accuracy rate of 83.6%.
dynamic data aggregation algorithm;data distribution;computing data center;simulation research
2015- 03- 19
苏娇娆(1976—),女,工程师。研究方向:计算机通信与网络。E-mail:Sjrr881@sohu.com
10.16180/j.cnki.issn1007-7820.2015.05.009
TP301.6
A
1007-7820(2015)05-030-03
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
建材发展导向(2021年7期)2021-07-16
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
西藏艺术研究(2019年1期)2019-09-04
计算机测量与控制(2018年1期)2018-02-05
中华老年口腔医学杂志(2016年3期)2017-01-15
西北工业大学学报(2015年3期)2015-12-14
中国交通信息化(2015年3期)2015-06-05
浙江大学学报(工学版)(2015年1期)2015-03-01
