
贝叶斯融合方法集成的支持向量机预警国家助学贷款信用风险的研究
2015-10-14 05:32:29李运蒙石安安桂绕根涂英
五邑大学学报(自然科学版) 2015年2期
李运蒙,石安安,桂绕根,涂英
贝叶斯融合方法集成的支持向量机预警国家助学贷款信用风险的研究
李运蒙1,石安安1,桂绕根1,涂英2
(1.五邑大学 经济管理学院,广东 江门 529020;2.广发银行 江门分行,广东 江门 529000)
用贝叶斯方法将随机选用的多个不同类别的支持向量机集成为预警模型,通过银行实际助学贷款数据对模型进行测试和验证,结果表明该集成模型有更高的分类准确度,可以为银行助学贷款违约行为的预判提供重要的参考依据.
助学贷款;支持向量机;集成学习;风险预警;贝叶斯融合方法
国家助学贷款政策于1999年开始实施,2004年前后,在迎来首批还款高峰的同时也出现了大面积的违约现象,导致银行方面一度叫停了助学贷款[1-2]. 至此,助学贷款的高违约率问题成为了学者们关注和研究的焦点. 一些学者通过构建指标体系和模型来评价贷款学生的个人信用,并用于银行风险估计和预警[3-5]. 目前,定量实证研究的范例相对较少,且一般用的是单一模型,由于预警模型的准确率是银行方面最关心的问题,因此探索出更加准确的预警方法,尝试多模型集成的预警效果十分必要.
国际上一般认为,商业银行贷款风险预警可作为分类问题看待[6-7],即通过预警模型的测算和预估,将其分为正常贷款和违约贷款两类,或设置不同警限,将其分为多类. 研究表明,多模型集成方法能进一步提高分类精度[8-10]. 本文拟在充分研究国内外相关成果的基础上,根据前期构建的助学贷款预警指标体系[11-12],探讨多分类器集成预警模型的构建方法,并结合广发银行江门分行助学贷款实际数据进行实证检验,争取为银行防范和治理助学贷款违约提供有效的预警方法.
1 基于支持向量机的集成模型的构建
1.1 支持向量机分类模型
支持向量机(SVM)分类器的优点是精度高、泛化能力强,适合小样本等. SVM通过建立一个超平面作为决策曲面,使得不同类别样本之间的隔离边缘最大化,以此达到划分空间、实现分类的目的. 分类超平面的一般形式可写成:
利用拉格朗日优化方法把上述最优分类面问题转化为对偶问题,其存在唯一解,求解所得的最优分类函数为:
对于非线性问题,可以采用满足Mercer条件的内积核函数代替原空间中的内积,以避开非线性变换的具体形式,此时分类函数变为:
使用该分类函数对银行信用数据分类,可以判断贷款方的信用状况.
1.2 贝叶斯集成方法
多分类器组合是提高识别效果的有效途径,目前已有较多的分类器融合方法,其中贝叶斯法能充分利用每个分类器的先验知识对融合结果进行计算,且以每种分类器在每个类别上的分类准确率为融合依据,其预测结果更加合理,因而备受关注. 设分类器所分类的样本空间为,对的种类别(即,其中,称为的一个类),根据训练样本统计出的每个分类器的识别情况,建立混乱矩阵:
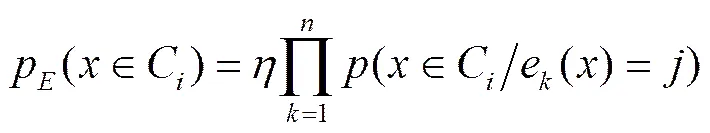
1.3 集成模型的实现
2)用测试样本计算分类器的分类精度,并从大到小排序,精度低于标准的排除,本文精度标准为83%.
3)构建优选分类器集合,先将最高精度的分类器加入,后面的分类器与集合中每个分类器的差异计算结果达到一定程度才加入其中,初始差异取0.5.
两两分类器差异计算方法为:
新分类器与分类器集合的差异(总差异)算法为:
4)构建集成模型,用测试样本测试其精度,满足要求则结束(分类准确率大于90%),否则调整子支持向量分类器的个数和初始差异标准,从1)开始执行. 子支持向量分类器个数和初始差异标准调整方法分别为:和.
2 实证分析
2.1 预警指标选择
笔者在总结了国内助学贷款预警研究成果的基础上,与广发银行助学贷款工作人员多次讨论、筛选,构建如表1所示的助学贷款预警指标体系.
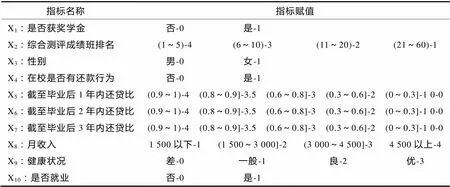
表1 国家助学贷款信用风险预警指标及其赋值
为使得模型学习效果更好,在不影响判别效果的情况下,应尽量缩小样本空间. 可通过将连续指标离散化(如对指标的处理)或对其他指标赋值的方法实现,如表中的赋值方法,(1~5)-4表示综合测评成绩班排名前5名,取值为4.
2.2 实验设计
1)数据收集和预处理
从银行得到的助学贷款样本有6 000多个,其中仅不足10%的为违约样本,另外还有一些样本因数据不全被剔除. 最终,从合格样本中随机抽取近3年的600个样本,其中违约和守约各一半. 将指标数值进行标准化处理,全部取值映射到[0,1]区间,输出结果设为0或1(0为违约,1为守约). 样本选取如表2所示.
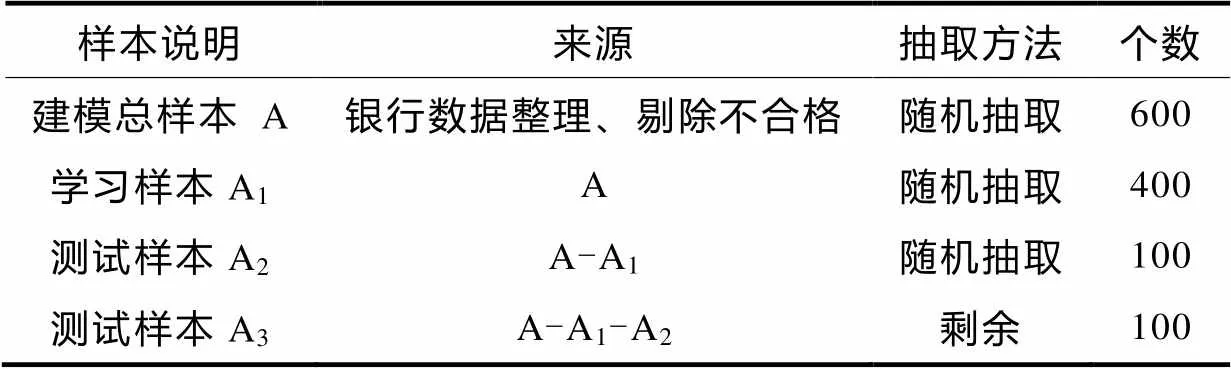
表2 样本选取方法及各个样本集
2)Bagging方法、支持向量机分类器和集成算法运用MATLAB7.6和LIBSVM3.12工具箱通过编程建立,参数随机选取.
3)从建模的600个样本中随机抽取400样本作为学习样本,采用Bagging方法从中随机抽取300个样本,分别训练5个支持向量机分类器,形成;将剩余的200个样本随机分成两组,即测试样本和,其中用于检验单个支持向量机分类器的分类精度,计算混乱矩阵,通过式(7)、式(8)选择差异大的分类器集合.
5)集成模型精度达到90%以上时算法结束,否则按前述方法调整,继续运算. 当调整次数超过100次时算法结束,分析样本问题或找其他原因.
2.3 分类结果
运用前述算法,最终得到3个有较大差异的子支持向量机分类器,集成模型先有精度最高的分类器、再分别加入和后融合而成. 表2中,集成模型可以使分类准确率达到92%,且集成模型第2类错误比第1类错误稍高. 预测准确率结果如表3所示.

表3 单个模型和集成模型的预测准确率
3 结论
本文前期调研中充分借鉴了学者们的研究成果,对类似指标进行了归并和删减,认真听取了银行从业人员对违约现象的评述,形成了符合实际特点的预警指标体系;研究采用搜索的方式寻找精度高、差异较大的分类器进行集成,能够实现构建子分类器的目的,解决了子分类器构建的方法问题. 因此,集成模型比子分类器有更高的判别精度,且第一类错误率较低,符合模型的算法思想.
另外,就助学贷款预警问题研究过程中发现的问题,提出如下建议:
1)学校的信息记录问题. 部分院系对学生的在校表现记录保留时间较短,记录不规范、不统一,建议进一步完善学生信息管理系统,并参照银行意见进行必要的调整.
2)银行方面和高校学生管理部门应联合对违约率高的群体进行诚信教育,提高其还贷意愿.
3)政府、高校和银行方面应继续支持助学贷款问题的研究,使对国家、高校、银行、贫困学生都有益的助学贷款政策长期健康发展下去.
[1] 胡键. 违约率高银行叫停助学贷款[N]. 南方日报,2004-04-21.
[2] 郑天虹. 粤助学贷款:违约率6年升高10多倍[N]. 新华每日电讯,2009-12-11.
[3] 肖智,王明恺,谢林林. 基于支持向量机的大学生助学贷款个人信用评价[J]. 清华大学学报:自然科学版,2006, 46(S1): 1120-1124.
[4] 康英,薛惠锋,张哲. 基于GA-PHO遗传规划算法的国家助学贷款风险预警模型研究[J]. 宁夏大学学报:人文社会科学版,2008, 30(5): 135-138.
[5] 李鹏雁,谢晓晨. 基于层次分析方法的助学贷款风险评价[J]. 哈尔滨工业大学学报,2009, 41(12): 301-304.
[6] ALTMAN E I,HALDEMAN R C,NARAYANAN P. Zeta analysis: a new model to identify bankruptcy risk of corporations [J]. Journal of Banking and Finance, 1997, 1(1): 29-54.
[7] DAN M C, MARK G R. A comparative analysis of current credit risk models [J]. Journal of banking and Finance, 2000, 24(1): 59-117.
[8]LAM L, SUEN C Y. Optimal combining of pattern classifiers [J]. Pattern Recognition Letters, 1995, 16: 945-954.
[9] 孙洁,李辉. 企业财务困境的多分类器混合组合预测[J]. 系统工程理论与实践,2009, 29(2): 78-86.
[10] WINDEATT T. Diversity measures for multiple classifier system analysis and design [J]. Information Fusion, 2005, 6(1): 21-36.
[11] 李运蒙,桂绕根,涂英. 国家助学贷款信用风险预警指标体系的构建与应用[J]. 内蒙古大学学报:自然科学版,2012, 43(6): 651-657.
[12] 李运蒙,桂绕根,石安安. 基于支持向量机的助学贷款信用风险预警研究[J]. 五邑大学学报:自然科学版,2014, 28(1): 50-53.
[责任编辑:熊玉涛]
Early Warning of National Student Loans Credit Risk Based on Support Vector Machine Assembled by the Bayes Fusion Method
LIYun-meng1, SHIAn-an1, GUIRao-gen1, TUYing2
(1. School of Economics and Management, Wuyi University, Jiangmen 529020, China;2. Jiangmen Branch of Guangdong Development Bank, Jiangmen 529000, China)
Using the support vector machine (SVM) as the base classifier, an early warning model is established by assembling a number of different categories of support vector machines using the Bayes fusion method. Testing and verifying using the actual band loan data shows that the ensemble model has a higher accuracy in classification and can provide an important reference basis for banks to pre-judge students’ breach of loan contracts.
student loans; support vector machines; ensemble learning; risk early-warning; Bayes fusion method
1006-7302(2015)02-0044-05
F822.1;O211.61
A
2014-12-10
广东省哲学社会科学规划项目(GD11XGL20)
李运蒙(1964—),男,山东郓城人,副教授,硕士,研究方向为金融市场数据分析.
猜你喜欢
今日农业(2019年12期)2019-08-13 00:50:02
电子测试(2018年1期)2018-04-18 11:52:35
现代园艺(2017年22期)2018-01-19 05:07:01
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
火控雷达技术(2016年3期)2016-02-06 02:30:27
中国火炬(2015年10期)2015-07-25 09:51:18
中国火炬(2014年7期)2014-07-24 14:21:14
中国火炬(2014年2期)2014-07-24 14:17:00
小说月刊(2014年11期)2014-04-18 14:12:28
