
Big-Data Processing Techniques and Their Challenges in Transport Domain
2015-10-11 01:37:50AftabAhmedChandioNikosTziritasandChengZhongXu
ZTE Communications 2015年1期
Aftab Ahmed Chandio,Nikos Tziritas,and Cheng-Zhong Xu,2
(1.Shenzhen Institutes of Advanced Technology,Chinese Academy of Sciences,Shenzhen 518055,China;2.Department of Electrical and Computer Engineering,Wayne State University,MI 48202,USA;3.Institute of Mathematics and Computer Science,University of Sindh,Jamshoro 70680,Pakistan)
Big-Data Processing Techniques and Their Challenges in Transport Domain
Aftab Ahmed Chandio1,3,Nikos Tziritas1,and Cheng-Zhong Xu1,2
(1.Shenzhen Institutes of Advanced Technology,Chinese Academy of Sciences,Shenzhen 518055,China;2.Department of Electrical and Computer Engineering,Wayne State University,MI 48202,USA;3.Institute of Mathematics and Computer Science,University of Sindh,Jamshoro 70680,Pakistan)
This paper describes the fundamentals of cloud computing and current big-data key technologies.We categorize big-data processing as batch-based,stream-based,graph-based,DAG-based,interactive-based,or visual-based according to the processing technique.We highlight the strengths and weaknesses of various big-data cloud processing techniques in order to help the big-data community select the appropriate processing technique.We also provide big data research challenges and future directions in aspect to transportation management systems.
big-data;cloud computing;transportation management systems;MapReduce;bulk synchronous parallel
1 Introduction
I n today's ICT era,data is more voluminous and multifarious and is being transferred with increasing speed.Some reasons for these trends are:scientific organizations are solving big problems related to highperformance computing workloads;various types of public services are emerging and being digitized;and new types of resources are being used.Mobile devices,global positioning system,computer logs,social media,sensors,and monitoring systems are all generating big data.Managing and mining such data to unlock useful information is a significant challenge[1]. Big data is huge and complex structured or unstructured data that is difficult to manage using traditional technologies such as database management system(DBMS).Call logs,financial transaction logs,social media analytics,intelligent transport services,location-based services,earth observation,medical imaging,and high-energy physics are all sources of big data. Fig.1 shows the results of a big-data survey conducted by Talend[2].The survey revealed that many common real-world applications deal with big data.
Real-time monitoring traffic system(RMTS)is one of the most interesting examples of a transportation monitoring system(TMS)[3].In such a system,information about vehicles,buildings,people,and roads are accessed to probe city dynamics.The data is often in the form of GPS location.Because of the real-time nature of data collected in a TMS,the amount ofdata can grow exponentially and exceed several dozen terabytes[4].For example,there are 14,000 taxis in Shenzhen. With a 30 s sampling rate,these taxis generate a 40 million GPS records in a day.This GPS data is often used by numerous transportation services for traffic flow analysis,route planning and hot route finder,geographical social networking,smart driving,and map matching[3]-[5].However,to extract and mine massive transportation data from a database comprising millions of GPS location records,TMS needs an effective,optimized,intelligent ICT infrastructure.

▲Figure 1.Which applications are driving big-data needs at your organization?(multiple responses,n=95)[2].
Cloud computing is one of the best potential solutions to dealing with big-data.Many big-data generators have been adapted to cloud computing.According to a survey by GigaS-paces[6],only 20%of IT professionals said their company had no plans to move their big data to the cloud,which indicatesthat most companies dealing with big data have turned to the cloud[4].Several TMS applications,such as cloud-agent-based urban transportation systems,MapReduce for traffic flow forecasting,and cloud-enabled intensive FCD computation framework[7],[8],have been significant in bringing forward the cloud computing paradigm.
Cloud computing integrates with computing infrastructures,e.g.,data centers and computing farms,and software frameworks,e.g.,Hadoop,MapReduce,HDFS,and storage systems to optimize and manage big data[1].Because of the importance and usability of cloud computing in daily life,the number of cloud resource providers has increased.Cloud resource providers offer a variety of services,including computation and storage,to customers at low cost and on a pay-per-use basis.
Currently,the cloud computing paradigm is still in its infancy and has to address several issues,such as energy efficiency and efficient resource use[9]-[11].Unfortunately,as big-data applications are driven into the cloud,the research issues for the cloud paradigm become more complicated.Hosting big-data applications in the cloud is still an open area of research.
In this paper,we describe the fundamentals of cloud computing,and we discuss current big-data technologies.We categorize key big-data technologies as batch-based,stream-based,graph-based,DAG-based,interactive-based,or visual-based. To the best of our knowledge,the Hadoop big-data techniques that fall into these categories have not been covered in the literature to date.In this survey,we highlight the strengths and weaknesses of various Hadoop-based big-data processing techniques in the cloud and in doing so,intend to help people within the big-data community select an appropriate processing technique.We discuss challenges in big-data research as well as future directions in big data related to transportation.
In section 2,we give an overview of cloud computing.In section 3,we give an overview of big data.In section 4,we introduce state-of-the-art big-data processing technologies.In section 5,we discuss big-data research directions and challenges. Section 6 concludes the paper.
2 Cloud Computing and Data-Processing Platforms
Cloud computing is being adapted to every kind of real-world application.Over the next two decades,cloud computing technologies will be crucial to innovation in education,government,healthcare,transportation,traffic control,media,Internet -based business,manufacturing,and media.Cloud computing is the collection of computing resources that can be accessed via a digital network such as wide-area network(WAN)or the Internet.These resources can be accessed using a computer,tablet,notebook,smart phone,GPS device,or some other device.Cloud servers provide and manage the applications and also store data remotely[12].
Cloud computing has been defined in numerous ways by different researchers and experts.The authors of[12]-[14]all have their own opinions of what constitutes cloud computing. NIST[13]defines cloud computing as“a model for enabling ubiquitous,convenient,on-demand network access to shared pool of configurable computing resources(e.g.,networks,servers,storage,applications,and services)that can be rapidly provisioned and released with minimal management effort or service provider interaction.”Cloud computing is not a new concept;it has been derived from several emerging trends and key technologies,including distributed,utility,and parallel computing[14].In the following sections,we describe the architecture and key technologies of cloud computing,which is classified in Fig.2.
2.1 Cloud Deployment Models
Cloud architecture can be explained from organizational and technical perspectives.From an organizational perspective,cloud architecture can be categorized as public,private or hybrid[15]according to deployment model.
A public cloud deployment model is used for the general public or a large group of industries.Examples are Google App Engine,Microsoft Windows Azure,IBM Smart Cloud,and Amazon EC2.A private cloud deployment model is used for an organization.Examples are Eucalyptus,Amazon VPC,VMware,and Microsoft ECI data center.A hybrid cloud deployment model is a mixture of two or more clouds(i.e.,public and private)for a unique domain.Examples are Windows Azure and VMware vCloud.
From a technical perspective,cloud architecture has three main service models:infrastructure as a service(IaaS),platform as a service(PaaS),and software as a service(SaaS)[16].
The first-layer IaaS provides access with an abstracted view of centrally located hardware,computers,mass storage,and networks.The most popular examples of IaaS are IBM IaaS,Amazon EC2,Eucalyptus,Nimbus,and Open Nebula.

▲Figure 2.Classification of cloud computing.
The PaaS layer is designed for developers rather than end-users.It is an environment in which the programmer can execute services.Examples of PaaS are Google AppEngine and Microsoft Azure.
The SaaS layer is designed for the end-user,who does not need to install any application software on their local computer.In short,SaaS provides software for rent and is sometimes called on-demand applications over the Internet.The most popular examples of SaaS are Google Maps,Google Docs,Microsoft Windows Live,and Salesforce.com.
2.2 Key Aspects of Cloud Architecture
2.2.1 Service Orientation
In cloud computing,service-oriented architecture(SOA)is a software architecture that defines how services are offered and used.Functions and messages in the SOA model are used by end-users,applications,and other services in cloud computing.In other words,the SOA determines the way services are designed,deployed,and managed.SOA services are flexible,scalable,and loosely coupled[17].In an SOA,services are interoperable,which means that distributed systems can communicate and exchange data with each another[17].
2.2.2 Virtualization
Virtualization involves creating an abstract,logical view of the physical resources,e.g.,servers,data storage disks,networks and software,in the cloud.These physical resources are pooled,managed,and utilized.Virtualization has many advantages in terms of resource usage,management,consolidation,energy consumption,space-saving,emergency planning,dynamic behavior,availability,and accessibility[18].Operating systems,platforms,storage devices,network devices,and software applications can all be virtualized.
2.2.3 Parallel Computing
The parallel computing paradigm in cloud computing is pivotal for solving large,complex computing problems.The current parallel-computing paradigms in cloud environments include MapReduce,bulk synchronous parallel(BSP),and directed acyclic graph(DAG).The jobs handled within these paradigms are computation requests from the end-user and may be split into several tasks.
MapReduce was introduced by Google to process mass data on a large cluster of low-end commodity machines[19].MapReduce is an emerging technique based on Hadoop.It is used to analyze big data and perform high-throughput computing. Hadoop[20]is an Apache project that provides a library for distributed and parallel processing.Each job is divided into several map and reduce tasks(Fig.3).MapReduce takes input data in the form of<key;value>pairs,which are distributed on computation nodes and then map-task produces intermediate<key;value>pairs to distribute them on computation nodes.Finally,the intermediated data is processed by reducetask to generate the final output<key;value>pairs.During this process,input and output data are stored in Hadoop distributed file system(HDFS),which creates multiple copies of the data as blocks for distribution on nodes.
Bulk Synchronous Parallel(BSP)computing paradigm was introduced by Valiant and Leslie in[21].A BSP algorithm[21],[22]generates a series of super-steps,each of which executes a user-defined function in parallel that performs computations asynchronously.At the end of every super-step,the BSP algorithm uses a synchronization barrier to synchronize computations within the system.Fig.4 shows a BSP program. The synchronization barrier is the state on which every superstep waits for other super-steps running in parallel.The BSP parallel paradigm is well suited to graph computation problems.In[22],BSP performs better than MapReduce for graph processing problems.Hama[23]and Pregel[24]are common technologies based on BSP graph-based processing for big-data analytics.
3 Big-Data

▲Figure 3.MapReduce framework.

▲Figure 4.Bulk synchronous parallel computing paradigm.
Big-data is a huge structured or unstructured data set that isdifficult to compute using a traditional DBMS.An increasing number of organizations are producing huge data sets,the size of which start at a few terabytes.For example,in the U.S.,Wal-Mart processes one million transactions an hour,which creates more than 2.5 PB of data[2].In the following sections,we discuss the characteristics and lifecycle of big data.
3.1 Characteristics
Big-data characteristics are often described using a multi-V model(Fig.5).Gartner proposed a 3V model of big data,but an additional dimension,veracity,is also important for data reliability and accuracy[15].
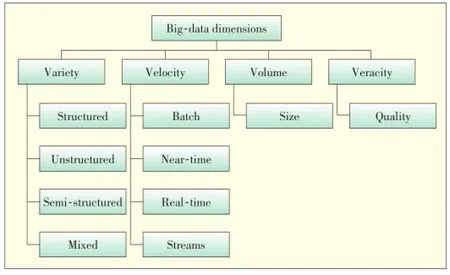
▲Figure 5.Classification of big-data.
3.1.1 Volume
Volume is a major dimension of big-data.Currently,the volume of data is increasing exponentially,from terabytes to petabytes and beyond.
3.1.2 Velocity
在绿色大豆种植过程中,应进行有效的病虫害防治。在疾病控制过程中,应强调两种疾病,即灰斑病和大豆菌核病。在疾病预防控制过程中应选择多菌灵混悬剂,及时使用施宝克来进行相应的疾病预防控制工作,只有这样才能取得较好的效果。在害虫防治过程中,应开展对大豆食肉昆虫、大豆蚜虫和大豆孢囊线虫的防治。
Velocity includes the speed of data creation,capturing,aggregation,processing,and streaming.Different types of big-data may need to be processed at different speeds[15].Velocity can be categorized as
·Batch.Data arrives and is processed at certain intervals. Many big-data applications process data in batches and have batch velocity.
·Near-time.The time between when data arrives and is processed is very small,close to real time.
·Real time.Data arrives and is processed in a continuous manner,which enables real-time analysis.
·Streaming.Similar to real-time,data arrives and is processed upon incoming data flows.
3.1.3 Variety
Variety is one of the most important characteristics of bigdata.Sources of big-data generate different forms of data.As new applications are developed,a new type of data format may be introduced.As the number of big-data forms grows,designing algorithms or logic for big-data mining and analysis becomes more challenging.Big data can be categorized as
·structured.Big-data in this form is very easy to input and analyze because there are several relational database management(RDBMS)tools that can store,query,and manage the data effectively.Structured big data comprises characters,numbers,floating points,and dates commonly used in customer relationship management systems.
·unstructured.Big-data in this form cannot be stored and managed using traditional RDBMS tools because it is not in a table(i.e.,according to a relational model).Unstructured big-data includes location information,photos,videos,audio,emails,sensors data,social media data,biological data,and PDFs that are totally amorphous and very difficult to store,analyze and mine.Social media websites and sensors are major sources of unstructured big data.Eighty to ninety percent of today's data in the world is unstructured social media data[26].HP Labs has estimated that by 2030 approximately 1 trillion sensors will be in use,monitoring phenomena such as energy consumption,cyberspace,and weather[26].
·semi-structured.Big-data in this form cannot be processed using traditional RDBMS tools.Semi-structured data is a type of structured data that is not organized in a table(i.e.,according to a relational model).
·mixed.Big-data may also be a mixture of the above forms of data.Mixed big-data requires complex data capture and processing.
3.1.4 Veracity
The veracity of big-data is the reliability,accuracy,understandability,and trustworthiness of data.In a recent report[27],it was found 40-60%of the time needed for big-data analysis was spent preparing the data so that it was as reliable and accurate as possible.In several big-data applications,controlling data quality and accuracy has proven to be a big challenge.
3.2 Big-Data Lifecycle
In this section,we describe the big data lifecycle and divide it into four major phases(Fig.6).
3.2.1 Big-Data Generation
The first phase of the big-data lifecycle involves generation of big-data.Specific sources generate a huge amount of multifarious data.that can be categorized as enterprise data,related to online trading,operation,and analysis data managed by RDBMS;Internet of Things(IoT),related to transport,agriculture,government,healthcare,and urbanization;and scientific,related to bio-medical,computational biology,astronomy,and telescope data[28].

▲Figure 6.Big-data lifecycle.
3.2.2 Big-Data Acquisition
Big-data acquisition is the second phase of the lifecycle and involves collection,pre-processing,and transmission of big-data.In this phase,raw data generated by different sources is collected and transmitted to the next stage of the big-data lifecycle.Log files,sensing,and packet capture library(i.e.,Libpcap)are common techniques for acquiring big-data.Because big-data has many forms,an efficient pre-processing and transmission mechanism is required to ensure the data's veracity. In particular,before data is sent to the next phase,it is filtered during the acquisition phase to remove redundant and useless data.Data integration,cleaning,and redundant elimination are major methods for big data pre-processing.In that way,new data layout with a meaningful data can save storage space and improve overall computing efficiency for big data processing.
3.2.3 Big-Data Storage
As big data has grown rapidly,the requirements on storage and management has also increased.Specifically,this phase is a responsible of data availability and reliability for big data analytics.Distributed file system(DFS)is commonly used to store big-data originating from large-scale,distributed,data-intensive applications.A variety of distributed file systems have been introduced recently.These include GFS,HDFS,TFS and FastTFS by Taobao,Microsoft Cosmos,and Facebook Haystack.NoSQL database is also commonly used for big data storage and management.NoSQL databases have three different storage models:key-value model,i.e.,Dynamo and Voldemort;document-oriented,i.e.,MongoDB,SimpleDB,and CouchDB;and column-oriented,i.e.,BigTable.
3.2.4 Big-Data Production
Big-data production is the last stage of the big-data lifecycle and includes big-data analysis approaches and techniques.Bigdata analysis is similar to traditional data analysis in that potentially useful data is extracted and analyzed to maximize the value of the data.Approaches to big-data analysis include cluster analysis,factor analysis,correlation analysis,regression analysis,and data mining algorithms such as k-mean,Naïve Bayes,a priori,and SVM.However,these methods cannot be used with big-data because of the massive size of data.If any of these methods are to be leveraged by big data analysis,they must be re-designed to make use of parallel computing techniques,which may be batch-based(i.e.,MapReduce-based),BSP-based,or stream-based.
4 Big-Data Processing
In this section,we explain big data processing approaches and techniques which are based on cloud environments.Firstly,we discuss about major analysis approaches used to analyze big data.Next,we explain five different categories of big data processing techniques in the next subsection.In Fig.7,it is depicted a complete big data framework.
4.1 Analyitic Approaches
Big-data analysis approaches are used to retrieve hidden information from big data.Currently,many big data analysis approaches follow basic analysis approaches.Big data analysis approaches include mathematical approaches and data mining approaches.Basically,an analysis approach chosen by a big data application is totally dependent on the nature of the application problem and its requirements.Particularly,different big data analysis approaches provide different outcomes.We categorize big data analysis approaches into two broad categories: mathematical approaches and data mining approaches[29].
4.1.1 Mathematical Approaches

▲Figure 7.Big-data framework.
Mathematical analysis approaches for big data involve very basic mathematical functions including statistical analysis,factor analysis,and correlation analysis used in many fields(i.e.,engineering,physics,economics,healthcare,and biology).In statistical analysis,big data can be completely described,summarized,and concluded for its further analysis.Applicationsfor economic and healthcare widely use statistical analysis approach for big data analysis.In factor analysis,a relationship among many elements presented in big data is analyzed with only a few major factors.In such analysis,most important information can be revealed.Correlation analysis is a common mathematical approach used in several big data applications. Basically,with the help of correlation analysis,we can extract information about a strong and weak dependence relationship among many elements contained in big data.
4.1.2 Data-Mining Approaches
Data mining involves finding useful information from big-data sets and presenting it in a way that is clear and can aid decision-making.Some approaches to data mining in big-data applications include regression analysis,clustering analysis,association rule learning,classification,anomaly or outlier detection,and machine learning.
Regression analysis is used to find and analyze tendency and dependency between variables.For example,in CRM bigdata applications,different levels of customer satisfaction that affect customer loyalty can be determined through regression analysis.A prediction model can then be created to help make decisions on how to increase value for an organization.
Clustering analysis is used to identify different pieces of big data that have similar characteristics and understand differences and similarities between these pieces.In CRM,cluster analysis is used to identify groups of customers who have similar purchasing habits and predict similar products.
Association rule learning is used to discover interesting relationships between different variables and uncover hidden patterns in big-data.A business can use patterns and interdependencies between different variables to recommend new products based on products that were retrieved together.This helps a business increase its conversion rate.
Classification analysis is used to identify a set of clusters in data comprising different types of data.It is similar to clustering analysis.Anomaly(outlier)detection is a data-mining technique for detecting data with unmatched patterns and unexpected behavior.Detected data has to be analyzed because it may indicate fraud or risk within an organization.
4.2 Cloud-Based Big-Data Processing Techniques
Cloud-based Hadoop is used for processing in a growing number of big-data applications[20],each of which has a different platform and focus.For example,some big-data applications require batch processing and others require real-time processing.Here,we give a taxonomy of cloud-based big-data processing techniques(Fig.8).
4.2.1 Batch
Big-data batch processing is a MapReduce-based parallel computing paradigm of cloud computing(section 0).There are several tools and techniques are based on batch processing and run on top of Hadoop.These include Mahout[30],Pentaho[31],Skytree[32],Karmasphere[33],Datameer[34],Cloudera[35],Apache Hive,and Google Tenzing.
Mahout[30]was introduced by Apache and takes a scalable,parallel approach to mining big-data.It is used in largescale data-analysis applications.Google,IBM,Amazon,Facebook,and Yahoo have all used Mahout in their projects.Mahout uses clustering analysis,pattern analysis,dimension reduction,classification,and regression.
Skytree[32]is a general-purpose server with machine learning and advanced analytics for processing huge datasets at high speed.It has easy commands for users.Machine learning tasks in Skytree server include anomaly or outlier detections,clustering analysis,regression,classification,dimensions reductions,density estimation,and similarity search.Because its main focus is real-time analytics,it enables optimized implementation of machine-learning tasks on both structured and unstructured big data.
Pentaho[31]is a big-data software platform for generating business reports.It is enables data capturing,integration,exploration,and visualization for business users.With business analytics,the user can make data-based decisions and increase profitability.Pentaho uses Hadoop for data storage and management and provides a set of plugins to communicate with a document-oriented model of NoSQL databases(i.e.,MongoDB)and Cassandra database.
Karmasphere[33]is a platform for business big-data analysis.It is based on Hadoop.With Karmasphere,a program can be efficiently designed for big-data analytics and self-service access.Karmasphere is capable of big-data ingestion,reporting,visualization,and iterative analysis in order to gain business insight.It can process structured and unstructured big data on Hadoop embedded with Hive.
Datameer[34]provides a business integration PaaS,called Datameer Analytic Solution(DAS),which is based on Hadoop and is used to analyze a large volume of business data.DAS includes an analytics engine,data source integration,and data visualization.DAS services are deployed in other Hadoop distributions,such as Cloudera,Yahoo!,Amazon,IBM BigInsights,MR,and GreenplumHD.Because the main objective of Datameer is data integration,data can be imported from structured data sources,such as Oracle,MySQL,IBM,HBase,and Cassandra,as well as from unstructured sources,such as log files,LinkedIn,Twitter,and Facebook.
Cloudera[35]provides Hadoop solutions such as batch processing,interactive search,and interactive SQL.Cloudera is an Apache Hadoop distribution system called CDH that supports MR,Pig,Flume,and Hive.Cloudera also supports embedded plugins with Teradata,Oracle,and Neteza.
4.2.2 Stream

▲Figure 8.Big-data computing models.
Stream-based processing techniques are used to compute continuous flows of data(data streams).Real-time processing overcomes the limitations of batch-based processing.Projects that use stream processing include Storm[36],S4[37],SQLStream[38],Splunk,Kafka,SAP Hana,Infochimps,and BigInsights.
Storm[36]is a fault-tolerant,scalable,distributed system that provides an open-source and real-time computation environment.In contrast to batch processing,Storm reliably processes unbounded and limitless streaming data in real-time. Real-time analytics,online machine learning,interactive operating system,and distributed remote procedure call(RPC)are all implemented in Storm project.This project allows the programmer to create and operate an easy setup and process more than a million of tuples per second.Storm comprises different topologies for different Storm tasks created and submitted by a programmer in any programming language.Because Storm works through graph-based computation,it has nodes,i.e.,spouts and bolts,in the topology.Each of these nodes contains a processing logic and processes in parallel.A source of streams is called a spout,and a bolt computes input and output streams.A Storm cluster system is managed by Apache Zoo-Keeper.
In 2010,Yahoo!introduced S4[37],and Apache included it as an Incubator project in 2011.S4 is a platform that facilitates fault-tolerant,distributed,pluggable,scalable computing. It is designed to process large-scale continuous streams of data.Because its core library is written in Java,a programmer can easily develop applications in S4,which supports cluster management and is robust,scalable,and decentralized.It is used to process large-scale data streams.Analogous to Storm,S4 can also manage the cluster by using Apache ZooKeeper.Yahoo!has deployed S4 for computing thousands of search queries.
SQLStream[38]is a platform for processing large-scale unbound streaming data in real-time with the support of automatic,intelligent operations.Specifically,SQLStream is used to discover interesting patterns in unstructured data.The platform responds quite rapidly because the streaming data is processed in memory.Server 3.0 is a recently released version of SQLStream and is used for real-time big-data analytics and management.
Splunk[39]is a platform for analyzing real-time streams of machine-generated big data.Senthub,Amazon,and Heroku have all used a Splunk big-data intelligent platform to monitor and analyze their data via a web interface.Splunk can be used with structured or unstructured machine-generated log files.
Kafka[40]has been developed for LinkedIn.Kafka is a stream processing tool for managing large-scale streaming and messaging data and processing it using in-memory techniques. Kafka generates an ad hoc solution to the problems created by two different types of data,i.e.,operational and activity,belonging to a website.Service logs,CPU/IO usage,and request times are examples of operational data that describes the performance of servers.Activity data,on the other hand,describes the actions of different online users'actions.These actions include clicking a list,scrolling through webpage content,searching keywords,or copying content.Kafka is used in several organizations.
SAP Hana[41]is a stream processing tool that also processes streaming data in-memory.SAP Hana is used for real-time business processes,sentiment data processing,and predictive analysis.It provides three real-time analytics:operational reporting,predictive and text analysis,and data warehousing. SAP Hana can also work with interactive demographic applications and social media.
Infochimps[42]cloud suite covers several cloud IaaS services,categorized as:
·cloud streams:real time analytics for multiple data sources,·cloud queries:query capability for NewSQL and NoSQL(i. e.,Apache Cassandra,HBase,MySQL,and MongoDB)
·cloud Hadoop:analysis of massive amount of data in HDFS.
Infochimps platform is suitable for both private and public
clouds.It can also control STORM,Kafka,Pig,and Hive.
BigInsights[43]is used in the Infosphere platform introduced by IBM.BigInsights manages and integrates information within Hadoop environment for big-data analytics.BigInsights leverages InfosphereStreams,a stream-based tool of the IBM Infosphere.BigInsights is used for real-time analytics on largescale data streams.JAQL,Pig,Hive(for querying),Apache Lucene(for text mining),and Apache Oozie(job orchestration)are supported by BigInsights.
4.2.3 Graph
Graph-based big-data processing techniques work according to the BSP parallel computing paradigm of cloud computing(section 0).Several big-data applications are better suited to graph-based processing over batch processing[22].Hama[23],Pregel[24],and Giraph[44]are common useful graph processing techniques for big-data analytics.
Hama[23]is a complete programming model introduced by Apache.It was inspired by BSP parallel computing paradigm running on the top of Hadoop.Hama is written in Java.Massive scientific computations,including matrix algorithms,graph functions,and network computation algorithms,can be easily implemented through Hama[23].In Hama architecture,a graph is distributed over all the computational nodes,and the vertices are assumed to reside in the main memory during computation.The Hama architecture three main components:BSPMaster,groom servers,and ZooKeeper.BSPMaster maintains the status of groom servers,super-steps,and job progress.A groom server performs BSP tasks assigned by the BSPMaster,and the synchronization barrier is managed efficiently by the Zookeeper component.
Pregel[24]is a graph computational model for efficiently processing billions of vertices connected through trillions of edges.A Pregel program comprises sequences of iterations.In each of these iterations,a vertex may receipt messages,update state or dispatch messages.In this model,a problem is approached through the BSP processing model.
Apache Giraph[44]is an iterative graph-processing system built for high scalability.It is widely used within Facebook to analyze and process the social graph generated by users and their connections.Giraph originates from Pregel and is inspired by the BSP distributed computation model.Features of Giraph include master computation,out-of-core computation,and edge-oriented input.
4.2.4 DAG
Dryad[25]is a scalable parallel and distributed programming model based on dataflow graph processing.Similar to the MR programming model,a Dryad program can be executed in a distributed way on a cluster of multiprocessor or multicore computing nodes.Dryad computes a job in a directed-graph computation manner,wherein each vertex denotes a computational vertex,and an edge denotes a communication channel. This model can generate and dynamically update the job graph and schedule the processes on the resources.Microsoft Server 2005 Integration Services(SSIS)and Dryad-LINQ are built on Dryad.
4.2.5 Interactive
Tableau[45]sits between users and big-data applications by using an interactive mechanism for large-scale data processing.Tableau comprises three different tools:Tableau Desktop,Tableau Server,and Tableau Public.Tableau Desktop visualizes and normalizes data in different ways.Tableau Server offers browser-based analytics called a business intelligence system. Tableau Public is used for interactive visuals.Tableau uses the Hadoop environment and Hive to process queries.
Google Dremel[46]is an interactive analysis system proposed by Google and used for processing nested data.Dremel is a scalable system that complements batch processing tools such as MapReduce.This system is capable of scaling to thousands of processing units.It can process petabytes of data and respond to thousands of users.Dremel can also query very large tables.
Apache Drill[47]is also an interactive analysis system designed for processing nested data similar Google Dremel.It has the flexibility to support different queries and different data sources and formats.A Drill system can scale up to more than ten thousand servers that process petabytes of data(i.e.,trillions of records)in seconds.Likely Dremel,Drill stores data in HDFS and performs batch analysis using a MapReduce tool.
4.2.6 Visual
Talend Open Studio[48]is specially designed for visual bigdata analysis.Talend Open Studio has user's graphical platform that is completely open source software developed in Apache Hadoop.In this platform,programmer can easily build a program for Big Data problem without writing its Java code. Specifically,Talend Open Studio provides facilities of dragging and dropping icons for building up user's task in Big Data problem.It offers Really Simple Syndication(RSS)feed that may be collected by its components.
5 Big-Data Research Directions and Challenges
In this section,we highlight research directions and challenges in relation to big-data in transportation management systems,which is one of the emerging generators of big-data.In TMS,moving objects such as GPS-embedded taxis and buses generate GPS location data that exponentially increases the volume of big-data.Location data is required in numerous transportation services,such as map matching,to deal with the uncertainty of trajectories,visualize transport data,analyze traffic flow,mine driving patterns,and give smart driving directions. It is also used for crowd sourcing and geographical social net-working.However,to handle and manage the big-data associated with these transportation services,which produce a massive number of GPS records,TMS needs an optimized,intelligent ICT infrastructure.Here,we describe major transportation services that require further research in terms of big-data management.
5.1 Map Matching
GPS location data are sometimes affected by two typical problems
1)Due to the limitations of positioning devices,moving objects mostly generate noisy and imprecise GPS location data that is called the measurement error.This leads uncertainty in acquiring original locations of the object.
2)Moving objects continuously update their location at discrete time intervals,which may lead to sampling error.The low sampling rate and long intervals between updates may reduce energy consumption and communication bandwidth at the expense of increasing the uncertainty of the actual location.On the contrary,the high-sampling-rate greatly increases the amount of extraneous data.
Therefore,map matching in TMS is used to accurately align the observed GPS locations on a road network in a form of a digital map[5].Map matching from massive historical GPS location records is performed to predict a driver's destination,suggest the shortest route,and mine certain traffic patterns. However,[5]suggests that map matching is most accurate because of transition probability,which incorporates the shortest path between two consecutive observed GPS location points. On the other hand,the execution of the shortest path queries(SPQs)in the map-matching service involves high computational cost,which makes map-matching unaffordable for real-time processing[5].Moreover,extraneous data(i.e.,in case of a vehicle that stops many times,moves slowly,is trapped in a traffic jam,waits for traffic lights,and moves on a highway link)incurs an extra number of SPQs.The approaches in[49]and[50]are introduced to execute the SPQs by pre-computing the shortest path distances and splitting a road network into small portions so that the required portion can be loaded in the memory[49].Due to the sequential execution of the SPQs,these approaches incur high pre-computation and storage costs[50].
To map match the huge number of moving objects with tremendous GPS location records(i.e.,big data)there is a dire need to execute the SPQs in a computationally efficient environment.The SPQs can be implemented in graph-based big data processing paradigms(i.e.,see Section 0)on a large cluster of low-end commodity machines.Consequently,pre-computations of the SPQs on a large cluster of low-end commodity machines benefits low wall-clock-time and storage cost.
5.2 Visualizing Transportation Data
Visualizing transportation data is crucial in TMS to present raw data and compute results generated by data-mining[3]. Such presentation of data reveals hidden knowledge which helps in decision making to solve a problem in the system.In this service,transportation data can be viewed from different perspectives to detect and describe patterns,trends,and relationships in data.Moreover,it provides an interactive way to present the multiple types of data in TMS called exploratory visualization for purpose of investigation.Exploratory visualization can help to detect the relevant patterns,trends,and relations,which can grow new questions that can cause to view the visualized data in more details[3].
Visualizing the massive amount of transportation data i.e.,big data conveys a huge amount of information cannot be better visualized and presented in simple and traditional visualization tools.This service can be more challengeable when it visualizes multimodal data that leads to high dimensions of views such as social,temporal,and spatial[3].In big data research,visualizing the tremendous transportation data is an open issue and needing a large concern on new techniques of big data management.
6 Conclusions
In this paper,we have described cloud computing and key big-data technologies.We categorized big-data key technologies as batch-based,stream-based,graph-based,DAG-based,interactive-based,or visual-based.In this survey,we have discussed the strengths of various Hadoop-based big-data cloud processing techniques that help the big-data community select an appropriate processing technique.Moreover,we have highlighted research directions and challenges in big data in the transportation domain.
[1]B.D.Martino,R.Aversa,G.Cretella,et al.,“Big data(lost)in the cloud,”International Journal of Big Data Intelligence,vol.1,no.1,pp.3-17,2014.doi: 10.1504/IJBDI.2014.063840.
[2]Talend.(2013).How Big Is Big Data Adoption?[Online].Available:http://www. talend.com
[3]Y.Zheng,L.Capra,O.Wolfson,et al.,“Urban computing:concepts,methodologies,and applications,”ACM Transaction on Intelligent Systems and Technology,vol.5,no.3,article no.38,Sept.2014.doi:10.1145/2629592.
[4]A.A.Chandio,F.Zhang,and T.D.Memon,“Study on LBS for characterization and analysis of big data benchmarks,”Mehran University Research Journal of Engineering and Technology,vol.33,no.4,pp.432-440,Oct.2014.
[5]Y.Lou,C.Zhang,Y.Zheng,et al.,“Map-matching for low-sampling-rate GPS trajectories,”in 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems.Seattle,USA,2009,pp.352-361.doi:10.1145/ 1653771.1653820.
[6]GigaSpaces.(2013).Big Data Survey[Online].Available:http://www.gigaspaces. com
[7]Q.Li,T.Zhang,and Y.Yu,“Using cloud computing to process intensive floating car data for urban traffic surveillance,”International Journal of Geographical Information Science,vol.25,no.8,pp.1303-1322,Aug.2011.doi:10.1080/ 13658816.2011.577746.
[8]Z.Li,C.Chen,and K.Wang,“Cloud computing for agent-based urban transportation systems,”IEEE Intelligent Systems,vol.26,no.1,pp.73-79,2011.doi: 10.1109/MIS.2011.10.
[9]A.A.Chandio,K.Bilal,N.Tziritas,et al.,“A comparative study on resource allocation and energy efficient job scheduling strategies in large-scale parallel computing systems,”Cluster Computing,vol.17,no.4,pp.1349-1367,Dec. 2014.doi:10.1007/s10586-014-0384-x.
[10]C.-Z.Xu,J.Rao,and X.Bu,“URL:a unified reinforcement learning approach for autonomic cloud management,”Journal of Parallel and Distributed Computing,vol.72,no.2,pp.95-105,Feb.2012.doi:10.1016/j.jpdc.2011.10.003.
[11]A.A.Chandio,C.-Z.Xu,N.Tziritas,et al.,“A comparative study of job scheduling strategies in large-scale parallel computational systems,”in 12th IEEE International Conference on Trust,Security and Privacy in Computing and Communications,Melbourne,Australia,2013,pp.949-957.doi:10.1109/Trust-Com.2013.116.
[12]A.A.Chandio,I.A.Korejo,Z.U.A.Khuhro,et al.,“Clouds based smart video transcoding system,”Sindh University Research Journal(Science Series),vol. 45,no.1,pp.123-130,2013.
[13]P.M.Mell and T.Grance,“The NIST definition of cloud computing,”National Institute of Standards and Technology,Gaithersburg,USA,Tech.Rep.SP 800-145,Sept.2011.
[14]D.Hilley,“Cloud computing:A taxonomy of platform and infrastructure-level offerings,”Georgia Institute of Technology,Tech.Rep.GIT-CERCS-09-13,2009.
[15]M.D.Assunção,R.N.Calheiros,S.Bianchi,et al.,“Big data computing and clouds:trends and future directions,”Journal of Parallel and Distributed Computing,Aug.2014.doi:10.1016/j.jpdc.2014.08.003.
[16]I.A.T.Hashem,I.Yaqoob,N.B.Anuar,et al.,“The rise of“big data”on cloud computing:review and open research issues,”Information Systems,vol. 47,pp.98-115,Jan.2015.doi:10.1016/j.is.2014.07.006.
[17]R.Buyya,C.S.Yeo,S.Venugopal,et al.,“Cloud computing and emerging IT platforms:Vision,hype,and reality for delivering computing as the 5th utility,”Future Generation Computer Systems,vol.25,no.6,pp.599-616,Jun.2009. doi:10.1016/j.future.2008.12.001.
[18]C.Baun,M.Kunze,J.Nimis,et al.,Cloud Computing:Web-Based Dynamic IT Services,New York City,USA:Springer,2011.
[19]J.Dean,and S.Ghemawat,“MapReduce:simplified data processing on large clusters,”Communications of the ACM,vol.51,no.1,pp.107-113,Jan.2008. doi:10.1145/1327452.1327492.
[20]Apache.(2012).Apache Hadoop Project[Online]Available:http://www.hadoop. apache.org
[21]L.G.Valiant,“A bridging model for parallel computation,”Communications of the ACM,vol.33,no.8,pp.103-111,1990.doi:10.1145/79173.79181.
[22]T.Kajdanowicz,P.Kazienko,and W.Indyk,“Parallel processing of large graphs,”Future Generation Computer Systems,vol.32,pp.324-337,Mar. 2014.doi:10.1016/j.future.2013.08.007
[23]S.Seo,E.J.Yoon,J.Kim,et al.,“Hama:an efficient matrix computation with the mapreduce framework,”in IEEE Second International Conference on Cloud Computing Technology and Science,Indianapolis,USA,2010,pp.721-726. doi:10.1109/CloudCom.2010.17.
[24]G.Malewicz,M.H.Austern,A.J.C Bik,et al.,“Pregel:a system for largescale graph processing,”in ACM SIGMOD International Conference on Management of Data,Indianapolis,USA,2010,pp.135-146.doi:10.1145/ 1807167.1807184.
[25]M.Isard,M.Budiu,Y.Yu,et al.,“Dryad:distributed data-parallel programs from sequential building blocks,”in EuroSys'07,Lisboa,Portugal,2007.
[26]StateTech.(2013).Breaking down big data by volume,velocity and variety:a new perspective on big data for state and local governments.Business Intelligence[Online].Available:http://www.statetechmagazine.com/article/2013/06/ breaking-down-big-data-volume-velocity-and-variety
[27]Paxata,“Ventana research:easing the pain of data preparation,”Ventana Research,Feb.2014.
[28]M.Chen,S.Mao,and Y.Liu,“Big data:a survey,”Mobile Networks and Applications,vol.19,no.2,pp.171-209,2014.doi:10.1007/s11036-013-0489-0.
[29]C.L.P.Chen and C.-Y.Zhang,“Data-intensive applications,challenges,techniques and technologies:a survey on big data,”Information Sciences,vol.275,pp.314-347,Aug.2014.doi:10.1016/j.ins.2014.01.015.
[30]Apache.(2013).Apache Mahout[Online].Available:http://mahout.apache.org/
[31]Pentaho.(2013).Pentaho Big Data Analytics[Online].Available:http://www. pentaho.com/product/big-data-analytics
[32]Skytree.(2013).Skytree The Machine Learning Company[Online].Available: http://www.skytree.net/
[33]Karmasphere.(2012).FICO Big Data Analyzer[Online]Available:http://www. karmasphere.com/
[34]Datameer.(2013).Datameer[Online].Available:http://www.datameer.com/
[35]Cloudera.(2013).Cloudera[Online].Available:http://www.cloudera.com/
[36]Apache.(2012).Apache Storm Project[Online].Available:http://www.stormproject.net
[37]L.Neumeyer,B.Robbins,A.Nair,et al.,“S4:distributed stream computing platform,”in IEEE International Conference on Data Mining Workshops,Sydney,Australia,2010,pp.170-177.doi:10.1109/ICDMW.2010.172.
[38]SQLstrean.(2012).SQLstream s-Server[Online].Available:http://www.sqlstream.com/blaze/s-server/
[39]Splunk.(2012).Storm Splunk[Online]Available:https://www.splunkstorm.com/
[40]A.Auradkar,C.Botev,S.Das,et al.,“Data infrastructure at Linkedin,”in 28th International Conference on Data Engineering,Washington,USA,2012,pp. 1370-1381.doi:10.1109/ICDE.2012.147.
[41]S.Kraft,G.Casale,A.Jula,et al.,“WIQ:work-intensive query scheduling for in -memory database systems,”in IEEE 5th International Conference on Cloud Computing,Honolulu,USA,2012,pp.33-40.doi:10.1109/CLOUD.2012.120.
[42]Infochimps.(2013).Infochimps[Online].Available:http://www.infochimps.com
[43]IBM.(2013).IBM Infosphere BigInsights[Online].Available:http://www-01. ibm.com/software/data/infosphere/biginsights/
[44]Apache.(2011).Apache Giraph[Online].Available:http://giraph.apache.org/
[45]Tableau.(2013).Tableau[Online].Available:http://www.tableausoftware.com/
[46]S.Melnik,A.Gubarev,J.J.Long,et al.,“Dremel:interactive analysis of webscale datasets,”Proceedings of the VLDB Endowment,vol.3,no.1,pp.330-339,2010.
[47]Apache.(2013).Apache drill[Online].Available:https://www.mapr.com/products/apache-drill
[48]Talend.(2009).Talend Open Studio[Online].Available:https://www.talend. com/
[49]S.Tiwari and S.Kaushik,Databases in Networked Information Systems:Scalable Method for k Optimal Meeting Points(k-OMP)Computation in the Road Network Databases,New York City,USA:Springer,2013,pp.277-292.
[50]J.R.Thomsen,M.L.Yiu,and C.S.Jensen,“Effective caching of shortest paths for location-based services,”in Proc.2012 ACM SIGMOD International Conference on Management of Data,Scottsdale,USA,pp.313-324.doi: 10.1145/2213836.2213872.
Manuscript received:2015-01-26
Biographies
Aftab Ahmed Chandio(aftabac@siat.ac.cn)is a doctoral student at Shenzhen Institutes of Advanced Technology,Chinese Academy of Sciences.He is also a lecturer at the Institute of Mathematics and Computer Science,University of Sindh,Pakistan.His research interests include cloud computing,big data,parallel and distributed systems,scheduling,energy optimization,workload characterization,and mapmatching strategies for GPS trajectories.
Nikos Tziritas(nikolaos@siat.ac.cn)received his PhD degree from the University of Thessaly,Greece,in 2011.He is currently a postdoctoral researcher at the Shenzhen Institutes of Advanced Technology,Chinese Academy of Sciences.He researches scheduling,load-balancing and replication in CDNs as well as energy optimization and resource management in WSNs and cloud computing systems
Cheng-Zhong Xu(cz.xu@siat.ac.cn)received his PhD degree from the University of Hong Kong in 1993.He is currently a tenured professor at Wayne State University and director of the Institute of Advanced Computing and Data Engineering,Shenzhen Institutes of Advanced Technology,Chinese Academy of Sciences.His research interests include parallel and distributed systems and cloud computing.He has published more than 200 papers in journals and conference proceedings.He was nominated for Best Paper at 2013 IEEE High Performance Computer Architecture(HPCA)and 2013 ACM High Performance Distributed Computing(HPDC).He serves on a number of journal editorial boards,including IEEE Transactions on Computers,IEEE Transactions on Parallel and Distributed Systems,IEEE Transactions on Cloud Computing,Journal of Parallel and Distributed Computing and China Science Information Sciences.He was a recipient of the Faculty Research Award,Career Development Chair Award,and the President's Award for Excellence in Teaching of WSU.He was also a recipient of the“Outstanding Overseas Scholar”award of NSFC.
This work was supported in part by the National Basic Research Program(973 Program,No.2015CB352400),NSFC under grant U1401258 and U.S NSF under grant CCF-1016966.
猜你喜欢
海洋与湖沼(2022年6期)2022-11-25 05:29:56
暨南大学学报(自然科学与医学版)(2022年3期)2022-06-16 01:45:52
现代畜牧科技(2021年2期)2021-03-19 07:48:10
四川蚕业(2021年3期)2021-02-12 02:38:52
国外医药(抗生素分册)(2019年2期)2019-05-23 03:09:56
浙江大学学报(农业与生命科学版)(2017年1期)2017-04-17 07:05:02
海洋学报(2017年4期)2017-04-13 05:17:04
蚕桑通报(2015年1期)2015-12-23 10:14:28
保健与生活(2014年5期)2014-04-29 00:44:03
作物研究(2014年6期)2014-03-01 03:39:09

- ZTE Communications的其它文章
- Utility-Based Joint Scheduling Approach Supporting Multiple Services for CoMP-SUMIMO in LTE-A System
- Interference-Cancellation Scheme for Multilayer Cellular Systems
- An Optimal Lifetime Utility Routing for 5G and Energy-Harvesting Wireless Networks
- Energy-Efficient Large-Scale Antenna Systems with Hybrid Digital-Analog Beamforming Structure
- Signal Processing Techniques for 5G:An Overview
- 5G:Vision,Scenarios and Enabling Technologies