
一种可信的Web服务推荐方法
2015-10-09 06:13袁东维
软件导刊 2015年9期
关键词:服务

摘 要:为实现对可信Web 服务的推荐,提出基于用户及相似用户使用经验的Web服务信任模型,该模型一方面定义用户自身服务使用经验为直接信任度;另一方面,依据相似用户使用经验定义推荐信任度。采用TOPK算法,选出与用户最相似的K个最近邻,根据直接信任度与间接信任度预测出服务性能后进行服务推荐。模拟实验结果表明,该方法能有效进行Web服务推荐。
关键词关键词:Web 服务;直接信任度;推荐信任度
DOIDOI:10.11907/rjdk.151605
中图分类号:TP301
文献标识码:A 文章编号文章编号:16727800(2015)009003903
0 引言
Web服务技术屏蔽了不同平台间的差异,在基于P2P技术的电子商务等自组织中显示出了巨大优势,因为使用该技术可将自组织系统使用者变为Web服务提供者和使用者[ 1 ],这必将极大方便用户使用。然而开放、动态、自治的环境,使服务在使用时面临可信问题。
针对功能属性基本相同的服务,传统服务选择方案是针对QoS属性值分别赋予不同权重,进行简单相加,最后将分数最高的服务返回用户。为加强对服务运行风险因素的评估,人际网络中的信任概念被引入计算机系统[ 2 ]。文献[ 3 ]提出了一种基于分布式结构的信任评估框架,主要以用户反馈及声誉作为信任模型,这种信任模型考虑到用户自身使用经验;文献[ 4 ]提出了一种基于信任的服务选择方法。但以上方法都没有考虑动态环境下服务对不同用户的性能差异问题,也无法甄别、排除不诚信用户的影响。
推荐系统是实现信息过滤的重要手段,本文借鉴推荐算法思想改进信任模型,提出一种在P2P环境下的可信Web服务推荐方法,该方法的重点:①注重用户自身服务使用经验,使服务选择结果更加符合用户需求;②使用TOPK算法对用户进行甄别,只有和用户服务使用经验相类似的K个用户才有资格向其他用户推荐服务,一定程度上排除不诚信用户在服务选择上的消极影响。在此基础上,提出一种可信的Web服务推荐方法,通过用户及最近邻的使用经验来预测服务性能,并进行推荐,保障服务可靠性。
1 推荐数据获取
推荐算法是一种实现信息过滤的重要手段,在电子商务等领域中有比较广泛的应用,其主要思想是基于相似用户的选择预来测目标用户的选择。在利用推荐算法推荐服务前,首先要确定用什么数据进行服务推荐。
本文主要通过可信性即服务的信任度进行度量。信任度一般与QoS属性(如可靠性、价格、可用性等)密切联系,本文延用这一思路定义服务信任度,但在具体衡量时发现,有的QoS属性是相互关联,如价格和可靠性,价格高的服务相对而言可靠性要高,价格低的服务相对而言可靠性较差;若不考虑价格因素,有的QoS属性是相互抑制,如易用性与安全性。如果只笼统给出一个综合评价结果,很难界定服务最后的性能。所以本文对QoS属性描述采用四元组reqk={lk,,uk,wk,Tk},其中Lk,uk分别指用户对于属性qk能接受的上下限,wk代表用户对该属性的偏好程度,Tk表示该属性类型,包括区间型、文字描述型和门限型,标准化方法同文献[ 6 ]。
用户在调用完服务后会对服务进行满意度反馈,满意度通过分值来体现,分值被分为10级,即1-10级,从极度不满意到十分满意,其标准化方法=用户打分级别/10。
2 可信度评估方法
在P2P环境下,Web服务执行受路由状况、网络状况及硬件设备等因素的影响,服务的平均QoS值对各用户借鉴度并不高,对用户而言,其更相信自己及与自己状况相似用户的服务体验。本文从这一角度出发,定义Web服务的直接信任度和推荐信任度。
2.1 直接信任度
服务请求者自身的服务体验对其服务选择具有决定性影响,用户一般都不会再次选择使自己感到不愉快的服务。直接信任度是服务请求者自己调用服务后生成的反馈评价,是服务请求者与服务间历史交互后所产生的QoS属性值的综合反映 [5]。用户u与服务si历史上共进行了N次交易,其中成功交易L次,那么一次成功的交易,所获得信任度为:
当服务没有被用户调用过时,用服务提供者发布服务QoS值进行预测。
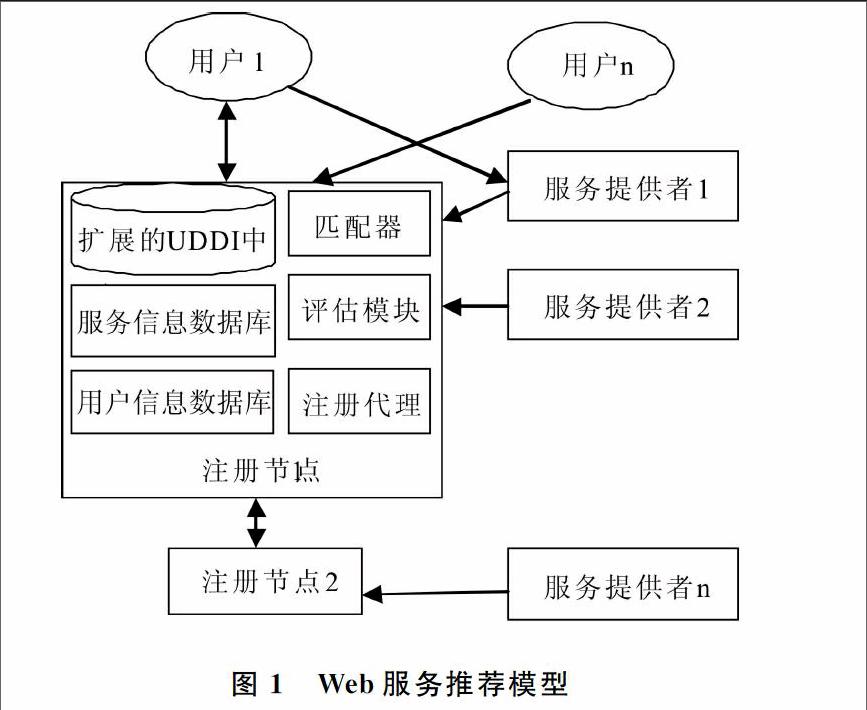
3 一种可信的Web服务推荐模型
定义服务直接信任度与推荐信任度后,本文提出一种在P2P环境下的可信Web服务推荐模型,如图1所示。主要包含3种角色:服务提供者、用户和注册节点,其作用如下:
①服务提供者:在注册节点中实名注册、并发布服务信息。在P2P环境下,服务提供者可选择使用多个注册节点发布服务信息;
②用户:服务需求者。在P2P环境下用户必须在注册节点中实名注册,并且在调用服务后向注册节点反馈其服务使用评价;
③注册节点:注册节点在扩展UDDI中心存储服务注册信息。接受用户服务请求后,通过匹配器匹配得到满足用户功能需求的服务组,然后评估模块查询服务、用户信息数据库,计算用户直接、间接信任度后,根据预测QOS值向用户推荐服务。
当用户调用该服务后向注册节点反馈评价信息,这些评价信息将被存储在注册节点上的服务信息数据库中,该用户调用信息也会被存储在用户信息数据库中。具体流程如下:
①根据用户u的服务请求,在扩展的UDDI中心进行基于功能的服务匹配,得到一组满足功能属性的服务列表S{s1,s2,……sn};
②检查用户信息数据库,查询用户u和服务列表S中所有服务的直接信任度;
③根据式(3)计算其它各用户对用户u的推荐信任度,选择其中和u相似性最大的K个用户为用户u最近邻;
④检查列表S中所有服务和的历史交易信息,根据式(4)直接预测各服务对于用户U的QOS值,并将QoS值最大的服务反馈给用户;
⑤用户u调用服务,交易结束后,用户向注册节点反馈本次服务运行状况,注册节点更新服务信息数据库和用户信息数据库。
图1 Web服务推荐模型
4 模拟实验与结果分析
模拟实验在WinXP上使用Matlab7.0和Mysql5.0实现,模拟实现携程网上预订酒店服务,实验中QOS属性值包括可靠性、响应时间、价格、用户满意度。实验参数主要包括服务数200、客户数100。将本文方法与基于服务QOS均值进行预测,与文献[ 5 ]方法进行比较。
首先进行测试,随着调用次数增加,服务调用成功率变化状况。从图2(a)中可以看出当调用次数较少时,以上3种方法调用成功率比较接近;当调用次数增加时,本文方法逐渐显示出优势,成功率较高。
当有不诚信客户时,再次测试,服务调用成功率发生
变化。实验中,每个用户各调用服务50次,其中不诚信用
户数量在不断变化。从图2(b)中可以看出,当存在不诚信客户时,服务调用成功率整体稍有下降;当调用次数增加时,由于本文方法只取和自己最相似的K个用户计算推荐信任度,因此在一定程度上避免了不诚信客户的影响,成功率相对比较稳定。
图2 实验结果
5 结语
本文通过引入推荐系统思想提出信任模型,利用相似用户选择预测服务的性能。首先定义直接信任度和推荐信任度,并在此基础上提出一种可信的Web服务推荐方法,该方法在对服务QOS预测中充分考虑了用户及相似用户的使用经验,因而提高了服务选择精确度。在后续研究中,将继续对服务选择作进一步研究,以增强服务预测准确性、提高服务选择效率。
参考文献参考文献:
[ 1 ] 陈卫国,李敏强,赵庆展.基于P2P环境下的Web服务信任模型研究[ J ].计算机科学,2015,42(1):113118.
[ 2 ] BETH T,BORCHERDING M,KLEIN B.Valuation of trust in open network[C].Proceedings of the European Sysposium on Research in Security (ESORICS).Brighton,1994:38
[ 3 ] GALIZIA S,GUGLIOTTA A,DOMINGUE J .A trust based methodology for web service selection[ C ]// International conference on semantic computing,2007:193200.
[ 4 ] MANIKRAO U S,PRABHAKAR T VDynamic selection of web services with recommendation system[ C ].IEEE Computer Society,Washington:342352.
[ 5 ] 袁东维.一种基于QOS的信任增强的服务选择方法[ J ].软件导刊,2014,13(5):3436.
[ 6 ] 贺兴亚,王海艳,杨文彬.一种QOS可信增强的服务选择方法[ J ].武汉大学学报(理学版),2013,59(5):443448.
责任编辑(责任编辑:孙 娟)
猜你喜欢
杭州金融研修学院学报(2022年5期)2022-06-15
今日农业(2019年14期)2019-09-18
今日农业(2019年12期)2019-08-15
今日农业(2019年11期)2019-08-13
今日农业(2019年13期)2019-08-12
今日农业(2019年10期)2019-01-04
今日农业(2019年15期)2019-01-03
今日农业(2019年16期)2019-01-03
铜仁学院学报(2018年4期)2018-06-13
商周刊(2017年9期)2017-08-22