
关键词共词分析法:高等教育研究的新方法
2015-09-21 04:24郭文斌方俊明
高教探索 2015年9期
郭文斌+方俊明
摘要:关键词共词分析法是一种较新的科学计量分析方法,它主要通过对高频关键词对在同一篇文章中出现的频次进行统计分析,生成共被引矩阵。在此基础上,通过统计软件,进行聚类分析、多维尺度分析、因子分析、主成分分析、社会网络分析等高级统计处理,绘制出二维或者三维的可视化图形,客观系统的展示出所关注资料的直观量化信息。在我国高等教育研究领域较少有学者对此方法进行论述,为了帮助大家更好地了解和掌握此方法,本文以2000-2012年《教育研究》文献热点知识图谱作为实例,详细展示了此方法的使用过程和注意事项。
关键词:关键词;共词分析;高等教育研究;知识图谱
一、引言
随着研究成果的激增,数字化期刊的盛行及互联网使用的便捷化,可以通过网上搜索引擎快捷的查询并获得这些成果。在应对海量数字信息的今天,传统文献计量和综述方式,不仅耗费时间、效率低下、查询资料的时间跨度短,而且难以全面搜集海量文献信息,造成文献研究偏于定性归纳、过于主观。[1]激增的数据背后隐藏着许多重要的信息,缺乏挖掘数据背后隐藏的知识的手段,导致了“数据爆炸但知识贫乏”。[2]如何在浩如烟海的数字文献中,将这些零散的信息全面、快速综合起来,挖掘出有深度的信息为我所用,已经成为众多研究者关注的热点。随着计算机技术的不断提升,以及数理统计方法的完善,研究者使用计算机进行数据挖掘(Data Mining,DM)的能力得以大大提升。在此背景下,科学知识图谱开始成为当前国际科学计量学领域热门的方法之一。它是通过将科学计量学的引文分析方法与可视化技术相结合达到对信息的有效组织和利用,生成新的知识。[3]该方法首先,通过计算机和互联网搜索引擎强大的自动查询功能,在极短的时间里面完成对海量信息的准确查询。其次,通过计算机对已查询到的海量分散信息进行文献计量统计分析,不仅可以通过量化模型将其以科学的、可视化的形式直观的呈现出来,而且还可以发现它们之间的深层次关系和趋势,对将要进行的同领域的研究提供科学的指导。该方法被国内外的许多科学计量学研究者应用于学科前沿的研究。但是,国内教育研究方法方面还比较落后。许多现代科学研究方法在教育科研中应用得很少,现代数学迟迟未被引进到教育科学中来。[4]对于科学计量方法在教育研究中应用的专题介绍性文献并不多见。我们在撰写本文前,使用关键词共词分析方法分别对国内特殊教育和自闭症(孤独症)[5]相关研究成果进行了梳理和总结,积累了一定的经验,同时,该方法对大量文献综合处理的高效性、准确性、客观性和直观性给我们留下了深刻的印象。为了帮助国内的高等教育研究者能够对这种方法有所了解,并且能够在今后的研究中更多的使用这种方法,提升自己教育科研的准确性和科学性,下面,我们以代表国内教育最高研究水准的教育类的核心期刊《教育研究》在2000-2012年发表的所有文献作为研究资料,向大家展示该方法的具体使用过程和注意事项。
二、关键词共词分析方法
(一)关键词共词分析方法简介
共词分析(Co-word Analysis)是一种较新的文献计量学方法,其属于内容分析方法的一种。其主要原理是对一组词两两统计它们在同一篇文献中出现的次数,以此为基础对这些词进行聚类分析,从而反映出这些词之间的亲疏关系,进而分析这些词所代表的学科或主题的结构与变化。[6]共词分析法可分别以文献的主题词和关键词进行共词分析,但我们倾向于主张采用关键词进行共词分析来得出结论,主要原因有:第一,关键词是论文中起关键作用的、最能说明问题的、代表论文内容特征的、或最有意义的词[7];第二,关键词不仅准确地反映论文的主题,而且其本身应具有独立的检索功能;第三,由于一篇文献的关键词或主题词是文章核心内容的浓缩和提炼,因此,如果某一关键词或主题词在其所在的领域的文献中反复出现,则可反映出该关键词或主题词所表征的研究主题是该领域的研究热点[8];第四,通过对高频关键词共现关系分析,可以进一步明晰若干热点研究领域。[9]关键词共词分析主要是通过共词分析软件,对符合条件的查询到的海量信息的关键词对在同一篇文章中出现的频次进行统计分析(共词分析),生成共被引矩阵。在此基础上,利用统计软件,进行聚类分析、多维尺度分析、因子分析、主成分分析、社会网络分析等高级统计处理,绘制出二维或者三维的可视化图形,客观系统的展示出所关注资料的直观量化信息。
(二)关键词共词分析方法的具体操作过程
1.准备研究工具
下载并安装Bicomb共词分析软件和SPSS20作为主要研究工具。Bicomb共词分析软件由中国医科大学医学信息学系崔雷教授和沈阳市弘盛计算机技术有限公司开发。下载获取地址为崔雷教授科学网的博客网址:https://skydrive.live.com/?cid=3adcb3b569c0a509&id=3ADCB3B569C0A509%211195。
2.准备研究资料
首先,进入网络搜索引擎,根据自己研究目的限定文献来源,进行文献检索。根据自己研究需要和目的对文献进行取舍和保留。再次,对选取的文献按照统一格式进行保存。第三,对保存的文献进行标准化。最后,将保留文献的格式转化为Bicomb共词分析软件能够识别的ANSI编码,供后续量化统计分析使用。这里值得注意的是,如果不将文本格式编码转为ANSI编码,Bicomb共词分析软件将无法识别有效信息。
3.进行量化统计分析
首先,使用Bicomb软件进行关键词统计并确定提取、导出高频关键词词篇矩阵。有关Bicomb软件进行关键词统计的详细操作过程请阅读相关操作手册。[10]其次,采用SPSS20对高频关键词进行聚类分析并生成Ochiai系数相同矩阵。再次,采用SPSS将高频关键词的相同矩阵转化为相异矩阵并进行多维尺度分析。最后,对上述量化结果进行定量和定性结合的分析,得出相应的结论和建议。
概括而言,关键词共词分析法的一般过程包括:明确研究的问题、选定并标准化研究材料、高频关键词的选定、共现矩阵的提取、进行高级统计处理(相同矩阵、相异矩阵的转化、聚类分析、多维尺度分析)。
三、关键词共词分析方法示例
为了更好的使大家掌握该方法,下面,我们以“2000-2012年《教育研究》文献热点知识图谱”为例向大家进行详细的示范说明。
(一)查找准备文献
首先,进入中国学术文献网络出版总库,进入标准检索对话框,将发表时间栏的具体日期定义为从“2000-01-01”到“2012-12-31”,文献出版来源限定为“《教育研究》”。根据限定好的条件进行文献检索,检索到文献2908条。其次,根据研究需要删除研讨会综述、课题介绍、会议通知、卷首语、会议记录、课题通过鉴定、读后感、简介、研讨会简介、书评、成果鉴定会、学院以及学校简介信息、人物专访、投稿须知、会议纪要、出版信息、目录信息、公告等,得到有效论文2550篇。再次,对上述文献统一按照题名、作者、关键词、单位、摘要、年、期等信息以文本形式保存。最后将保存的文本信息编码格式统一改为ANSI编码后保存。
(二)进行量化统计
1.进行关键词词频统计分析并提取高频关键词频次
一个学术研究领域较长时域内的大量学术研究成果的关键词集合,可以揭示研究成果的总体内容特征、研究内容之间的内在联系、学术研究发展的脉络与发展方向等。[11]如果在统计文献时,关键词出现的频次越高,则表示与该关键词有关的研究成果越多,研究内容的集中性就越强。一个研究领域的少量高频次的关键词,拥有该学科明显大的信息密度与知识密度,成为信息与知识需求者检索文献的重点,它们被称为核心关键词。[12]词频分析法是利用能够揭示或表达文献核心内容的关键词或主题词在某一研究领域文献中出现的频次高低来确定该领域研究热点和发展动向的文献计量方法。[13]
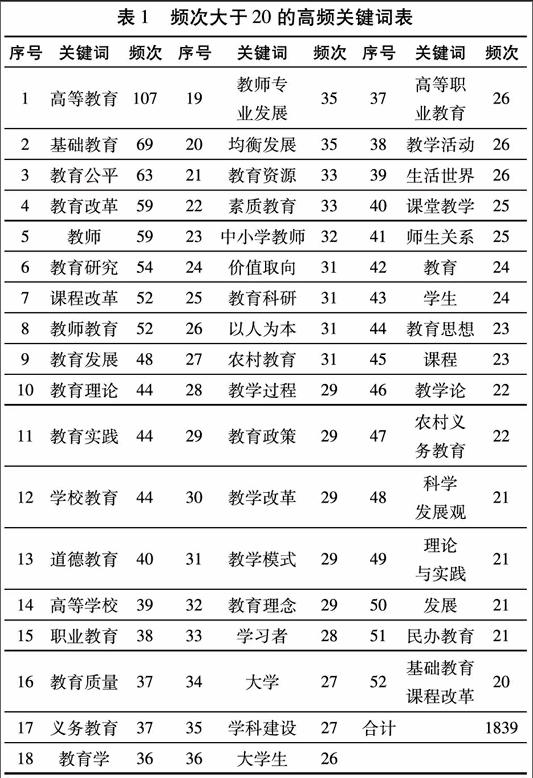
对2550篇文章中的15976个关键词进行词频统计分析,发现关键词出现的频次范围是1-107。为了减轻工作量,对关键词频次大于20的高频关键词进行提取,结果见表1。
从表1可以看出,频次大于等于20的有52个关键词,占关键词总数的3.25%,其出现的频次合计为1839次,词均35.37次,占关键词总频次(15976)的11.51%。这些高频关键词表述的研究内容,是2000-2012年《教育研究》发表文章的核心内容。从高频关键词分布顺序可看出,《教育研究》涉及的前10个研究热点依次为:高等教育(107)、基础教育(69)、教育公平(63)、教育改革(59)、教师(59)、教育研究(54)、课程改革(52)、教师教育(52)、教育发展(48)、教育理论(44)。这一统计结果,与2000-2009年八种教育学期刊文献前10位高频关键词(高等教育、课程改革、教育研究、教育改革、素质教育、教学改革、基础教育、课堂教学、教师、教育理论)对比,有7个高频关键词完全重合,排在第一位的高等教育和最后一位的教育理论在排序上完全吻合,其它5个仅在排列顺序上发生差异。这一结果不仅验证了本研究中统计方法的可信,而且还进一步说明相对于其它教育研究刊物,《教育研究》起着风向标的作用。
为深入挖掘这52个高频关键词的词频之间的关系以及它们背后隐藏的有效信息,还需要进一步采用关键词共现技术来进行深入的计量学研究。
2.生成高频关键词的相同和相异矩阵
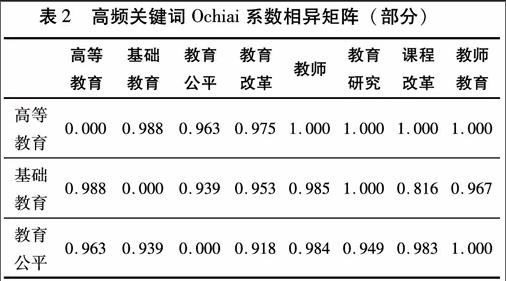
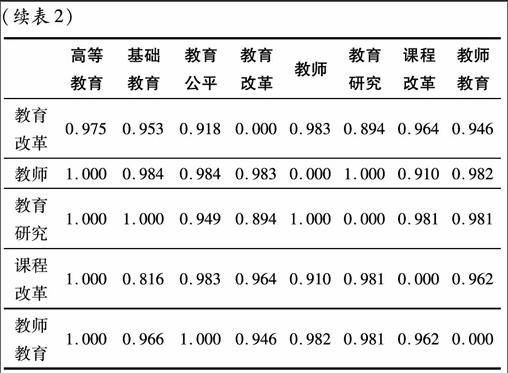
首先,生成高频关键词词篇矩阵。对各个高频关键词是否在其它论文中成对出现(出现为1,否则为0),利用Bicomb软件生成高频关键词词篇矩阵。词篇矩阵考察各高频关键词间的亲疏关系,词篇矩阵表示的是两目标之间的相似程度的矩阵,即两者数字越大表明两者关系越近,越小表明两者关系越远。[14]其次,生成高频关键词相似系数矩阵。以关键词词篇矩阵为基础,在SPSS20中进行相关分析,数据类型选择“binary”二元变量,相似系数选择“Ochiai”系数,构造出高频关键词相似系数矩阵。[15]相似矩阵中的数字表明数据间的相似性,数字的大小表明了相应的两个关键词之间的距离远近,其数值越接近1,表明关键词之间的距离越近、相似度越大;反之,数值越接近0,则表明关键词之间的距离越大、相似度越小。最后,生成高频关键词相异系数矩阵。为了消除由于关键词共现次数差异所带来的影响,根据相似系数矩阵,采用相异系数矩阵=1-相似系数矩阵,产生相异系数矩阵。相异系数矩阵中数字表明数据间的相异性,其含义与相似系数矩阵意义相反,数值越接近1,表明关键词之间的距离越大。相异系数矩阵结果见表2。
从表2可以看出,各关键词分别与高等教育距离由远及近的顺序依次为:教师(1.000)、教育研究(1.000)、课程改革(1.000)、教师教育(1.000)、基础教育(0.988)、教育改革(0.908)、教育公平(0.963)。这个结果说明,研究者在论及高等教育时,会更多的将其与教师、教育研究、课程改革与教师教育结合在一起讨论,而较少和基础教育、教育改革、教育公平结合起来。采用上述原理,综合表2中的关键词相异系数矩阵数据,可以初步得出的结论为:2000-2012年在《教育研究》发表的成果中,涉及到基础教育与课程改革的资料较少,大量研究主要以高等教育为探讨对象,关注高等教育中涉及的教师、教育研究、课程改革及教师教育等主要因素,对这些因素予以了更多的关注。出现这一结果的原因,一方面是《教育研究》从2004年开始增大了对“教师”这一关键词的关注,开辟了专栏。另一方面的原因是,2001年“教师教育”被国务院首次提出后,引起了多方面尤其是教育界对此问题的高度重视。
3.进行高频关键词聚类分析
聚类分析是选定一些分类标准,将不同的观察体加以分类,同一类(集群)之内观察体彼此的相似度愈高愈好,而不同一类之间观察体彼此的相异度愈高愈好。[16]高频关键词聚类分析是通过高级统计对已经发表文献的高频关键词组的相似性与相异性分析,来发现它们之间的远近关系,挖掘隐藏在它们背后的研究者关心的知识信息。关键词聚类分析时,先以最有影响的关键词(种子关键词)生成聚类;再次,由聚类中的种子关键词及相邻的关键词再组成一个新的聚类。关键词越相似它们的距离越近,反之,则越远。
将上述52个高频关键词构成的52×52的相似系数矩阵,导入SPSS20进行聚类分析。结果见图1。
从图1可以直观的看出2000-2012年《教育研究》高频关键词被分为8个种类,它们的具体分布结果见表3。
从表3可以看出,2000-2012年《教育研究》8类研究具体分布为:
种类1为教学过程中的活动和改革,包括14个关键词,其可以细分为6小类:小类1基础教育教学活动及过程,包括3个关键词(教学过程、教学活动、基础教育课程);小类2教学改革与教学论,包括2个关键词(教学改革、教学论);小类3教学模式与课堂教学,包括2个关键词(教学模式、课堂教学);小类4学生、教师及其发展,包括3个关键词(学生、发展 、教师);小类5师生关系,包括1个关键词(师生关系);小类6基础教育及素质教育的课程改革,包括3个关键词(基础教育、课程改革、素质教育)。
种类2为道德教育与生活,包括2个关键词(道德教育、生活世界)。
种类3为教育与课程,包括2个关键词(教育、课程)。
种类4为学校教育、义务教育及教育政策、观念,包括16个关键词,其可以细分为7小类:小类1学校教育与职业教育,包括2个关键词(学校教育 、职业教育);小类2农村教育和农村义务教育,包括2个关键词(农村教育、农村义务教育);小类3义务教育和均衡发展,包括2个关键词(义务教育、均衡发展);小类4教育公平、质量及政策,包括3个关键词(教育公平 、教育质量、教育政策);小类5教育资源,包括1个关键词(教育资源);小类6教育发展与教育科研,包括2个关键词(教育发展、教育科研);小类7教育理念及对学习者的关注,包括4个关键词(以人为本 、科学发展观、教育理念 、学习者)。
种类5为大学及学科建设,包括2个关键词(大学 、学科建设)。
种类6为教师教育、教育理论与教育思想,包括10个关键词,其可以细分为3小类:小类1教师教育及其专业发展,包括3个关键词(教师教育 、教师专业发展、中小学教师);小类2教学理论、研究及实践与改革,包括6个关键词(教育理论、理论与实践 、教育研究 、教育实践 、教育学 、教育改革);小类3教育思想,包括1个关键词(教育思想)。
种类7为高等职业教育和民办教育,包括2个关键词(高等职业教育、民办教育)。
种类8为高等教育、高等学校与价值取向,包括4个关键词,可以细分为2小类:小类1高等教育与大学生价值取向,包括3个关键词(高等教育 、大学生 、价值取向);小类2高等学校,包括1个关键词(高等学校)。
4.进行高频关键词的多维尺度分析
多维尺度分析(MDS)是一种可以帮助研究者找出隐藏在观察资料内的深层结构的统计方法,其目的是在发掘一组资料背后之隐藏结构,希望用主要元素所构成的构面图来表达出资料所隐藏的内涵,尤其是在观察资料体很多时,利用多维尺度法更能适切地找出资料的代表方式。[16]采用多维尺度分析时,要汇报其 Stress和RSQ值,它们分别为多维尺度分析中的信度和效度估计值。其中,压力系数(Stress)是拟合度量值,用于维度数的选择,Stress越小,表明分析结果与观察数据拟合越好,其值越小,说明模型的适合度越高。Kruskal(1964)给出了一种根据经验来评价Stress优劣的尺度:若Stress≥20%,则近似程度为差(Bad);≤10%,为满意(Fair);≤5%,则为好(Good);≤2.5%,为很好(Excellent);其理想的状况为Stress=0,称为完全匹配(Prefect)。[17] 模型距离解释的百分比(RSQ),表示变异数能被其相对应的距离解释的比例,也就是回归分析中回归分析变异量所占的比率,RSQ值越大,即越接近1,代表所得到的构形上各点之距离与实际输入之距离越适合。一般认为,RSQ在0.60以上是可接受的。[18]
采用spss20对上述52个高频关键词构成的52×52的聚类分析产生的矩阵进行多维尺度分析,标准化方法选择Z分数。结果显示,Stress= 0.120,RSQ= 0.823,说明其拟合效果较好,可以反映出《教育研究》高频关键词间的学术联系状况。多维尺度分析结果见图2。
多维尺度绘制出的坐标称为战略坐标,它以向心度和密度为参数绘制成二维坐标,可以概括地表现一个领域或亚领域的结构。[19]战略坐标中,各个小圆圈代表各个高频关键词所处的位置,图中圆圈间距离越近,表明它们之间的关系越紧密;反之,则关系越疏远。影响力最大的关键词,其所表示的圆圈距离战略坐标的中心点越近。坐标横轴为向心度(Centrality),表示领域间相互影响的强度;纵轴为密度(Density),表示某一领域内部联系强度。[20]在战略坐标划分的四个象限中,一般而言,第一象限的主题领域内部联系紧密并处于研究网络的中心地位。第二象限的主题领域结构比较松散。这些领域的工作有进一步发展的空间,在整个研究网络中具有较大的潜在重要性。第三象限的主题领域内部链接紧密,题目明确,并且有研究机构在对其进行正规的研究,但是在整个研究网络中处于边缘。第四象限的主题领域在整体工作研究中处于边缘地位,重要性较小。[21]
结合上述理论,从图2可以看出,首先,2000-2012年《教育研究》热点知识图谱分为8个区域,虽然种类1、4和6所占的区域较大,种类2、3、5、7、8所占区域较小,但从其分布位置可以看出,这些小的区域处于战略坐标的核心附近,表明这些区域是其关注的重点。种类7和种类8所处的领域距离战略坐标轴心位置最近,表明近几年高等职业教育和民办教育、高等教育、高等学校与价值取向成为了《教育研究》发文的热点领域。其次,从各个种类所处战略坐标的象限分布特点来看,种类4的大部分关键词位于战略坐标的第一象限,说明其不仅是《教育研究》杂志组稿的核心领域,而且其文章数量相对于其它7个种类所占领域更为多,也更成熟,该领域的研究是我国教育研究的中心领域。种类1、8主要位于第二象限,说明其主题相对松散,对其关注度还有待于进一步加强,其今后在《教育研究》文献成果质量提升方面还具有较大的潜在价值。种类2、3、6主要位于第三象限,说明这3个种类所占的领域内部链接紧密,题目明确,并且有研究机构正在对其展开正规的研究,但在整个研究网络中仍处于边缘。种类6大部分位于战略坐标的第四象限,说明它们所处的主题在整个研究中处于边缘地位,重要性较小。种类7不仅横跨四个象限,而且紧紧围绕在战略坐标轴心,说明它所占的领域是《教育研究》发文的重点核心领域,该领域的研究不仅与国家中长期教育改革和发展规划纲要(2010-2012年)提出的大力发展职业教育和大力支持民办教育的内容相一致,而且还与《教育研究》“2006中国教育研究前沿与热点问题年度报告”中“创新高等教育发展思路”、“拓展高等教育办学多样化”、“职业教育的转型与发展取向”[22]等内容相一致。此研究结果也被潘黎、王素的研究所验证。
四、总结和展望
通过上述实例,大家可以更直观的感受到关键词共词分析方法的使用效果,但是,在使用的具体过程中,还应该值得关注和思考下述问题。
(一)进行关键词共词分析前要确保对其进行标准化
我们主要针对《教育研究》进行计量分析,因为其风格基本一致,所以在标准化处理关键词方面比较容易处理,但是,如果涉及到多个杂志间的文献关键词处理,就要特别注意对查询到的文献的关键词进行规范和统一。比如,我们在进行自闭症热点研究时,要将在不同刊物中表达同样含义的关键词“自闭症”与“孤独症”统一为“自闭症”。迟景明和吴琳在研究中,将“高职院校”、“职业技术学院”和“职技高校”标准化为“高职院校”,将“高等学校”、“高等院校”、“高校”、“大学”等标准化为“高校”。对关键词的标准化处理,能确保最后量化材料的准确,进而保证最后科学计量的精确、科学。但很多进行科学计量的研究忽视了此问题,导致了其研究结果的科学和准确性大打折扣。
(二)可以尝试使用社会网络分析法更清晰地展示关键词间的强弱关系
本研究采用的多维尺度虽然可以较好的观察到变量间的关系,但是无法表现他们之间的强弱。要更好的表达各个关键词之间的强弱关系,大家以后可以尝试进行社会网络分析。社会网络分析(Social Network Analysis)(简称SNA,有的文献称为“社会网”或“网络分析”)是包括测量与调查社会系统中各部分(“点”)的特征与相互之间的关系(“连接”),将其用网络的形式表示出来,然后分析其关系的模式与特征这一全过程的一套理论、方法和技术。[23] 采用社会网络分析得出的三位立体网络图,更能直观地反应各个体(节点)的位置及它们之间的相互关系(线段)。在原始图线条密集,不易分析时,还可进行凝聚子群分析,使图的直观性增强,更容易分析理解。[24] 社会网络分析方法介绍及其软件的下载,国际社会网络分析网(http://www.insna.org/cgi-bin/softdatasearch.cgi)中给出了Construct、Network Genie、ORGAN 1 Social Network Analysis、PARTNER、PermNet、Socilyzer、UCI
NET software for Social Network Analysis八种社会网络分析软件。中文社会学网(http://www.sociology2010.cass.cn/news/133424.htm)给出了包括上述软件在内的20种软件介绍和链接地址,感兴趣的读者可以自己尝试使用。
(三)关键词共词分析法和定性方法结合使用才能更好解读研究结果
虽然热点知识图谱是采用科学计量法绘制出来的,但是该方法的使用并非完全依赖定量技术,其还依赖于定性分析技术。在进行了聚类分析和多维尺度分析之后,对于各个种类及其所在区域的划分和命名均需要雄厚的专业功底。它就像采用因子分析之后,对于各个因子的命名需要结合专业知识来命名一样。因此,要进行科学知识图谱的绘制,需要将定量研究与定性分析结合起来,具有一定的专业背景,才能够对计量结果进行准确、客观的解读。
(四)进行关键词共词分析方法时软件的选取也至关重要
虽然现在国内很多研究者,在社会学科、管理学科、医学等研究领域对中文文献的热点知识图谱的绘制采用了陈朝美博士研发的CiteSpace软件,但是该软件的优势在于处理外文,尤其是英文文献上,对于中文文献的处理还存在一定的不足,而我们所介绍的Bicomb软件在中文文献的共词分析方面较有优势,因此,我们建议大家对中文材料进行科学计量研究时更多的采用此软件。
通过本文的介绍,我们衷心希望能够帮助高等教育研究者对关键词共词分析法有所了解,同时,也真诚的希望越来越多的高等教育研究者投入到教育研究成果的科学计量研究中来!
参考文献:
[1]潘黎,王素.近十年来教育研究的热点领域和前沿主题——基于八种教育学期刊2000-2009年刊载文献关键词共现知识图谱的计量分析[J].教育研究,2011(2):47-53..
[2]王方华,陈洁,编著.数据库营销[M].上海:上海交通大学出版社,2006.
[3]郭文斌,方俊明,陈秋珠.基于关键词共词分析的我国自闭症热点研究[J].西北师大学报(社会科学版),2012,49(1):128-132.
[4]郑日昌,崔丽霞.二十年来我国教育研究方法的回顾与反思[J].教育研究,2001(6):17-2.
[5]郭文斌,陈秋珠.特殊教育研究热点知识图谱[J].华东师范大学学报(教育科学版),2012,30(3):49-54.
[6]崔雷.专题文献高频主题词的共词聚类分析[J].情报理论与实践,1996,19(4):49-51.
[7]马妍春,黄可心.科技论文摘要、关键词及参考文献的规范化[J].情报科学,1999,17(6):625-627.
[8]杨国立,李品,刘竞.科学知识图谱——科学计量学的新领域[J].科普研究,2010,5(4):28-34.
[9]王凡.科学知识图谱视域中的《图书馆理论与实践》[J].图书馆理论与实践,2011,(8):23-26.
[10]崔雷.书目共现分析系统《用户使用说明书》[Z/OL].http://cid-3adcb3b569c0a509.skydrive.live.com/browse.aspx/BICOMB.2012-04-13.
[11]李文兰,杨祖国.中国情报学期刊论文关键词词频分析[J].情报科学,2005,23(1):68-70.
[12]安秀芬,黄晓鹂,张霞,等.期刊工作文献计量学学术论文的关键词分析[J].中国科技期刊研究,2002,13(6):505-506.
[13]马费城,张勤.国内外知识管理研究热点——基于词频的统计分析[J].情报学报,2006,25(2):163-170.
[14]邱均平,马瑞敏,李晔君.关于共被引分析方法的再认识和再思考[J].情报学报,2008,27(1):69-74.
[15]迟景明,吴琳.近十年我国高等教育学学科研究热点和趋势——基于研究生学位论文的共词聚类分析[J].中国高教研究,2011(9):20-24.
[16]陈正昌,程炳林,陈新丰,等著.多变量分析方法:统计软件应用[M].北京:中国税务出版社,2005:241-299.
[17]张文彤,主编.SPSS统计分析高级教程[M].北京:高等教育出版社,2004:40-44.
[18]靖新巧,赵守盈.多维尺度的效度和结构信度评述[J].中国考试,2008(1).
[19]Law J, Bauin S, J.Courtial P, et al.Policy and the mapping of scientific change: A co-word analysis of research into environmental acidification[J].Scientometrics,1988,14(3-4):251-264.
[20]冯璐,冷伏海.共词分析方法理论进展[J].中国图书馆学报,2006,32(2):88-92.
[21]崔雷,郑华川.关于从MEDLINE数据库中进行知识抽取和挖掘的研究进展[J].情报学报,2003,22(4):425-433.
[22]教育研究编辑部.2006中国教育研究前沿与热点问题年度报告[R].教育研究,2007(3):3-16,29.
[23]汤汇道.社会网络分析方法述评[J].学术界,2009(3):205-208.
[24]种艳秋,张晗,冷荣新,等.利用社会网络分析法和聚类法研究心血管疾病知识结构的比较[J].中华医学图书情报杂志,2007,16(6):77-90.
猜你喜欢
中国市场(2016年31期)2016-12-19
现代情报(2016年10期)2016-12-15
现代情报(2016年10期)2016-12-15
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
中学生物学(2016年10期)2016-11-19
中国教育信息化·基础教育(2016年9期)2016-10-18
商(2016年5期)2016-03-28
商(2016年3期)2016-03-11
