
巴蜀中医药古籍医案数据挖掘系统构建及应用
2015-09-19 20:49聂佳任玉兰江蓉星许霞
中国中医药图书情报 2015年4期
聂佳 任玉兰 江蓉星 许霞


摘要:中医药古籍是中医药传承发展宝贵的知识财富,巴蜀中医药古籍特色突出。承载医家丰富理论和临床经验的医案,是知识发现不可或缺的研究对象。构建基于关联规则方法分析的巴蜀中医药古籍医案数据挖掘系统,不仅能深入研究巴蜀中医药学术流派的特色,亦能为中医药古籍数据挖掘系统开发和应用提供有效的支持。
关键词:巴蜀;中医药;古籍;医案;数据挖掘系统;构建
巴蜀地区独特的地理和文化环境,造就了一批在传统中医药方面卓有成就的名医大家,如北宋的唐慎微、清代的齐秉慧等,尤其在中医诊疗、方药方面特色突出,给后人留下了宝贵的医案记录,为祖国的医药事业继承和发展作出了不朽的贡献。本研究基于所收集1063部巴蜀中医药古籍中医案的特点,利用现代计算机技术,构建数据挖掘系统,旨在深层次发现巴蜀历代医家辨证论治的知识信息,发扬巴蜀中医药文化。
1.数据挖掘系统构建
1.1总体思路
数据挖掘能从大量的、不完全的、有噪声的、模糊的、随机的数据集中提取有效的、新颖的、潜在有用的知识和规律,具有处理海量模糊性、非线性数据及知识发现的优势。本研究以中医药古籍资源的分析利用和知识发现为目的,在试验相关数据挖掘技术特点和适用性基础上,结合巴蜀中医药名家诊治思路和特点,探索性地建立了基于关联规则的辨证施治、用药规律挖掘模型,并验证了其可行性,建立符合中医临床规律的数据分析方法,建造巴蜀中医药古籍数据挖掘的计算机模型。
1.2主要构建步骤
构建步骤共两部分。第一部分先明确研究需要,定义研究数据,将原始数据通过数据转换、加工等数据预处理方式,抽取正确可靠的数据,构建多维的数据仓库挖掘模型;第二部分即根据不同的查询条件进行数据挖掘,根据研究需要,选用恰当的数据挖掘算法,计算出满足条件的模式集合,以数据条形式表达出来,调整参数进行模式筛选,通过挖掘前台系统向导进行数据挖掘操作,将数据挖据信息以关联规则形式展现给用户,总过程如图1所示。
1.2.1数据的转换和加工 从数据源中抽取的数据不一定完全满足目的库的要求,例如数据格式的不一致、数据输入错误、数据不完整等,因此有必要对抽取出的数据进行数据转换和加工,包括数据过滤、数据清洗、数据替换、数据计算、数据验证、数据加解密、数据合并、数据拆分等。本研究根据抽取数据的特点进行数据转换和加工研究,主要包括数据清洗、噪音处理、数据规范。
1.2.1.1缺失值的处理 在中医处方信息中,有时会出现期望有数据的地方却没有数据的情况,如对临床决策有重要价值的药量等数据的缺失。针对数据的特点和对决策意义的不同,采用不同的缺失值填充算法,补充缺失数据。如针对树脂类数据,缺失值采用平均值填充法。
1.2.1.2噪音数据的处理 主要指针对一词多义、多词一义、词义模糊、词义交叉或涵盖等噪音数据进行处理。处理方法主要是根据《中华人民共和国药典》《中医诊断术语标准》《中医证候鉴别诊断学》《中医症状鉴别诊断学》《中药学》《方剂学》等标准进行删除或规范处理。
1.2.1.3药物名称的规范处理 针对处方中对药物的描述存在大量异药同名、同药异名等现象,本研究采用改进的编辑距离算法,对数学名称进行自动化、智能化的规范处理。规范处理过程通过两级数据规范实现。
1.2.1.4症状名称的规范 中医古籍文献对症状的描述常存在不规范性,多表现为症状名称不标准以及症状表述的模糊性。为了使系统可以正确处理对症状的描述,本研究根据症状规范采用改进的编辑距离算法,对症状进行自动化、智能化的规范处理。规范过程与药物规范一致。
1.2.2数据仓库的实施 构建巴蜀中医药古籍数据仓库的目标数据库由药物表、症状表、疾病表等构成。数据库中各表根据情况向下细化到不能分解的原数据。各表之间的数据可以借助外键建立联系,从而形成一个庞大的中医体系结构。
1.2.3建造数据挖掘模型 为了从多个维度、不同概念层次对药物运用规律进行渐进分析,本项目基于中医数据存在复杂冠词,结合关联规则建立了症候关联、药物配伍等挖掘模型。
1.2.4数据挖掘 运用多维关联规则分析在不同维度下症状、证候、药物的频次和支持度,提取中医某一疾病的多发症状、证候及治疗所需常用药物;运用关联规则分析的频繁项集分析中医医案中症状与证候、药物与药物等的配伍规律,计算症状、证候、药物项集的支持度和置信度,提取常用二元或者多元症状、证候、药物配伍;采用多维关联规则挖掘算法分析中医辨证思路、处方选药规律,分析不同年代、出处、文献类型等条件下辨证论治规律。
2.应用示范
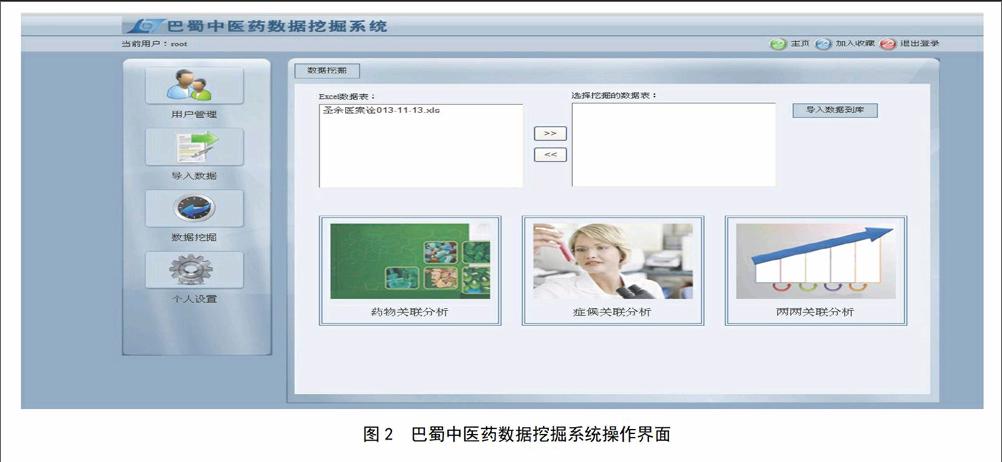
2.1功能界面操作
用户通过用户名和密码登录巴蜀中医药数据挖掘系统,进入数据挖掘操作界面,见图2。首先选择“导入数据”选项,在目标文件中选择准备数据挖掘的源数据,导入数据挖掘系统,然后根据研究需要,分别选择药物关联、症候关联(症状与证候关联)等选项,实现疾病与药物、病因与症状等之间的关联规则分析,达到数据挖掘的目的。
2.2药物关联分析展示
以《圣余医案》为例,导入所要进行数据挖掘的源数据,点击“药物关联分析”按钮,在病名下拉选项中选择“咳嗽”,在药物复选框中选中“全部药物”,在支持度和置信度选项中选择0.5,点击“数据挖掘分析”按钮,显示出如下结果。见表1。
从表1中可以看出,在《圣余医案》中治疗咳嗽所用的药物配伍组合,支持度和置信度>50%的共有12条数据。其中,半夏与白术组合的支持度为78.95%,置信度为100.00%。说明该书记载咳嗽病医案中,半夏和白术同时出现的频率为78.95%;而当半夏或白术二者其中一味出现时,另一味中药出现的概率为100.00%。可见,在《圣余医案》中,医家治疗咳嗽时,半夏与白术是常用药对,而且其单味药使用频率也是最高,均为15。半夏燥湿化痰、降逆止呕,白术健脾益气、燥湿利水,二者伍用倍增镇咳化痰之功。
3.体会
本研究引进现代计算机技术,针对巴蜀中医药古籍医案,探索性地构建基于关联规则方法分析的数据挖掘系统,以期为中医药古籍数据挖掘系统的开发和应用提供有效的支持。关联规则是中医药领域数据挖掘研究常用的方法,对于蕴含丰富的理论知识和实践经验的中医药古籍而言,应尝试不同的方法,多角度发现知识。将数据挖掘技术应用于不同种类的中医药古籍,将是下一步研究工作的重点。
猜你喜欢
现代艺术(2022年1期)2022-02-07
现代艺术(2022年1期)2022-02-07
现代艺术(2022年1期)2022-02-07
文史杂志(2021年1期)2021-01-06
布达拉(2020年3期)2020-04-13
出版人(2019年11期)2019-12-19
科学导报(2018年44期)2018-05-14
风湿病与关节炎(2016年12期)2017-01-14
风湿病与关节炎(2016年12期)2017-01-14
中国实用医药(2016年11期)2016-05-04
