
中国进出口许可证综合领先指数及其监测预警研究
2015-09-18 05:38:08唐宜红
中央财经大学学报 2015年4期
唐宜红 沈 琪 侯 佳
一、引言
对外贸易在我国经济中占有重要地位,如何找到适当的数量方法对我国对外贸易状况进行监测预警,是理论和实务界一直关注的问题。我国对部分重点商品实行进出口许可证管理制度。对于实行许可证管理的货物贸易,由于企业必须先按规定填报和申请许可证,才能进行实际进出口行为,因此许可证申领序列具有与生俱来的领先于实际进出口序列的优良特性,可以通过许可证申领序列构建我国商品进出口综合领先指数,进而对我国对外贸易进行监测预警。
本文利用商务部配额许可证事务局的许可证申领数据库,通过概率统计、计量经济学等数理方法,构建中国进出口许可证综合领先指数,并利用该指数对我国重点商品进出口状况进行监测预警,为个人、企业及政府决策提供科学参考。
通过构建领先指数对相应经济运行状况进行监测预警的思想,在国内外已有一些理论探讨和实际应用。 Frankel and Saravelos(2012)[1]讨论了领先指数对经济周期波动的解释能力。Onkal et al.(2011)[2]研究了样本分组结构对预测精度的影响。Rossi and Sekhposyan(2011)[3]评估了不同模型的预测效果。Heij et al.(2011)[4]从实证角度研究了利用领先指数对美国宏观经济进行预测的效果。Rossi and Sekhposyan(2010)[5]评估了各类通行的数理模型对美国产出及通胀的预测监测能力。美国最著名的领先指数是美国经济综合领先指数,由美国商务部经济分析局负责搜集一系列相关指标,并加权平均生成领先指数向社会发布。在中国,“消费者价格指数”和“生产者价格指数”是倍受关注的指数,贺力平等(2010)[6]对这两个指数进行了研究和探讨。另外,国家统计局每月公布我国“宏观经济景气指数”,其内容包括:预警指数、一致指数、先行指数(即领先指数)、滞后指数四项。微观方面,我国“义乌小商品指数”在样本抽样、指数加权等方面较为成功,已得到一定的市场认可。
本文将尝试利用中国进出口许可证数据库,借鉴国内外领先指数的构建方法,对我国许可证申领数据库进行系统的挖掘和建模,并充分利用许可证申领数据领先于对外贸易数据的特点,构造中国进出口许可证综合领先指数,为监测预警我国对外贸易情况提供一个全新的重要视角。
以下内容分为五部分。第一部分介绍商务部配额许可证事务局数据库基本特点;第二部分通过概率统计、多元回归等方法研究许可证申领数据序列对实际对外贸易数据的领先性规律;第三部分论述领先指数的构造方法并通过ARMA、VAR、Panel模型等方法进行监测预警;第四部分利用聚类分析法对分商品领先指数进行归类整合,构建中国进出口许可证综合领先指数;第五部分为结论。
二、许可证申领数据基本情况
世界各国对本国对外贸易均进行一定的监管,进出口许可证制度是我国政府管理对外贸易活动的重要措施之一。企业申领许可证的行为领先于企业实际进出口行为,因此许可证管理制度为我国政府提供了提前判断我国对外贸易情况的数据信息,进而为政府监测预警我国进出口形势提供了数据支持。虽然我国只对部分进出口商品实行许可证管理,但是我国实行进出口许可证管理的货物在我国对外贸易中占有重要地位。商务部配额许可证事务局对商务部签发的每一张许可证的数据信息都有详细记录。具体包括:我国实行进出口许可证管理货物的进出口数量、价格、贸易方式、出口目的国、进口来源地、进出口商、发证时间等。另外,还可以从商务部配额许可证事务局数据库中查询到与每张许可证对应的商品清关情况,包括:清关数量、清关金额、清关时间等,即实际贸易情况。
2012年我国实行出口许可证管理的货物共计49种,实行自动进口许可证管理的非机电类货物共计28种。2012年我国实行出口许可证管理的货物发证金额为560.5亿美元,占我国同年出口总额的2.7%;2012年我国实行自动进口许可证管理的非机电类商品发证金额为6 773.0亿美元,占我国同年进口总额的37.3%。
2012年我国实行出口许可证管理的49种商品具体分为四类:一般(非活畜类)、配额(非活畜类)、招标、配额(活畜类),分别占我国同年出口许可证申领总额的83.3%、13.0%、2.6%、1.1%。2012年我国实行自动进口许可证管理的28种非机电类商品可分为四类:自动进口(目录三)、自动进口(目录一)、自动进口外资(一般产品)、自动进口外资(重工),分别占我国同年自动进口非机电类许可证申领总额的63.7%、31.9%、3.1%、1.3%。
2012年我国实行出口许可证管理的49种商品中,许可证发证金额居前十位的商品分别是:汽车(包括成套散件)及其底盘、摩托车(含全地形车)及其发动机和车架、部分金属及制品、柠檬酸、煤炭、冻鸡肉、稀土、石蜡、原油、冻猪肉。2012年我国实行自动进口许可证管理的28种非机电类商品中,许可证发证金额居前十位的商品分别是:原油、铁矿石、铜、煤、大豆、铜精矿、天然气、成品油、植物油、废铝。
上述许可证管理商品在我国对外贸易中占有重要地位,这些商品的对外贸易一旦出现过大波动,对我国整体经济发展往往也会产生一定影响。因此需要利用许可证制度来密切监测这些商品的进出口情况,对异常波动进行及时预警,从而为我国经济稳定发展保驾护航。
三、许可证申领数据的领先性
对于许可证管理的商品,由于企业必须首先申领许可证,然后才能进行实际进出口行为,因此许可证申领数据具有与生俱来的对我国相应对外贸易数据的领先性。本文将从两个视角定量研究许可证申领数据的领先性规律。第一个视角是概率统计的视角,通过考察企业在申领了许可证后清关时间的分布情况,研究许可证数据的领先性规律。第二个视角是计量经济学的视角,通过计量经济学方法研究许可证申领序列和实际进出口序列两者之间的计量关系。
(一)概率统计学视角
许可证申领数据领先于实际进出口数据,这一点毋庸置疑。但是具体到单个重点商品,究竟许可证申领数据领先实际贸易数据多少天呢?这个问题没有明确的答案。在我国许可证管理的商品中,除个别商品外,大部分商品许可证的有效期为六个月。企业申领了许可证后,可以在有效期内的任意一天去清关。因此对于政府签发的每一张许可证,政府并不能明确知道企业究竟会在许可证有效期内的哪一天去进行实际进出口行为,即清关。清关时间的不确定性导致政府无法准确预测单张许可证的签发所产生的实际贸易的发生时间。
但是在统计学上,当样本量足够大时,可以通过考察大样本的概率密度函数特性来了解样本的整体情况。商务部配额许可证事务局掌握着全国所有的许可证申领信息,数据量庞大,更新速度快。因此我们可以利用概率密度函数从整体上把握许可证申领数据对实际贸易数据的领先性规律。本文首次利用概率密度函数研究我国重点进出口商品领先性特征,具有开创性。具体来说:将样本期内签发的某种商品的全部许可证按照“发证序列号”排序,对其中任意一张许可证,用“清关日期”减去“发证日期”得到一个新变量,将这个新变量命名为“间隔时间”。如果许可证的有效期为六个月,那么“间隔时间”这个变量的取值将在0到184之间。将“间隔时间”相同的许可证申领数据样本归为一类,将归入同一类样本的清关金额加总,可以得到该种商品在样本期内不同“间隔时间”的清关金额分布图。图1显示的是2012年部分商品在许可证有效期内不同“间隔时间”的清关金额。
以图1中的“汽车(包括成套散件)及其底盘”为例:图中横坐标为许可证发证日期与清关日期的时间间隔,纵坐标表示与相应时间间隔对应的清关金额。从“汽车(包括成套散件)及其底盘”清关情况分布图中可以发现:在许可证有效期(六个月)内,从签发许可证至实际清关,间隔时间为10天时清关金额最多。企业申领许可证之后,其清关行为主要集中在许可证申领后的第7天至第24天,申领许可证一个月之后的清关金额明显减少,申领许可证两个月之后的清关金额就很少了。“汽车(包括成套散件)及其底盘”的清关分布呈现出单峰、有偏的分布形状。
从图1展示的六种商品,例如汽车(包括成套散件)及其底盘、煤炭、活猪(对港澳地区)、活鸡(对港澳地区)、稀土、磷矿石的清关分布情况可以看出:不同商品的清关分布情况不尽相同。有些商品的清关分布是单峰的,有些是多峰的;有些商品的清关分布是近似对称的,有些是不对称的。也有个别商品的清关分布没有呈现出明显的统计规律。
利用图1所示的清关分布图,可以从概率统计角度了解企业在申领了许可证之后,清关行为的概率分布。具体说来:如果概率密度函数显示,某种商品的概率密度函数的峰值在第14天出现,这就意味着:如果该商品的进出口许可证发证金额出现了异常波动(异常大或者异常小),那么通常在14天后,该商品的实际进出口额也会出现相应的异常波动(异常大或者异常小)。
除了概率统计方法,还可以通过计量经济学回归方法研究许可证申领数据对实际贸易数据的领先性规律。
(二)计量经济学视角
许可证发证数据序列对实际清关数据序列的领先性规律,还可以通过回归方法来研究。回归方法是一种相对比较稳健的计量方法,经典实用。利用回归研究许可证发证序列对实际进出口序列的领先性规律时,需要对不同商品分别建模。但现在很多软件(比如SAS)都支持对不同商品进行程序化批处理的回归计算,这无疑会增加计算效率。前人对许可证发证信息领先性规律的研究,往往停留在针对个别商品、个别行业的研究,且数据不具有权威性。本研究依托商务部配额许可证事务局的权威数据库,利用经典计量方法,系统分析和研究许可证签发信息对实际贸易的领先性规律,具有开创性。
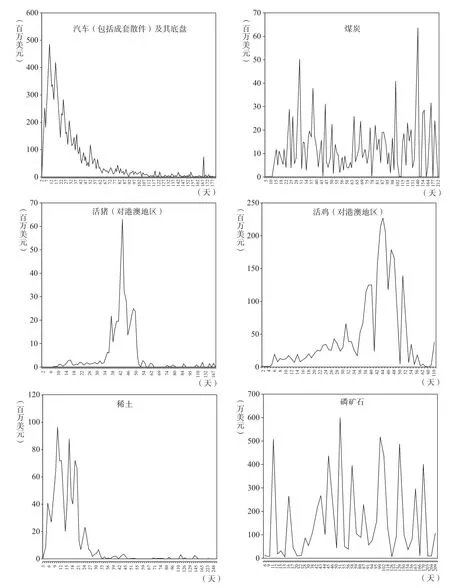
图1 2012年部分许可证管理商品的清关分布情况图
仍然以“汽车(包括成套散件)及其底盘”商品为例,构建多元回归模型。①建模频率是“周”。如果以“天”为频率建模,那么数据波动过于剧烈;如果以“月度”或者“季度”为频率建模,则精度不够。相较之下,以“周”为频率建模最合适。
在进行回归前,首先需要检验“汽车(包括成套散件)及其底盘”许可证发证金额、清关金额的平稳性,单位根检验结果如表1所示。

表1 “汽车(包括成套散件)及其底盘”许可证发证金额、清关金额的平稳性
从表1可以看出:发证金额序列和清关金额序列均平稳,满足进行OLS回归的条件。回归结果见表2。
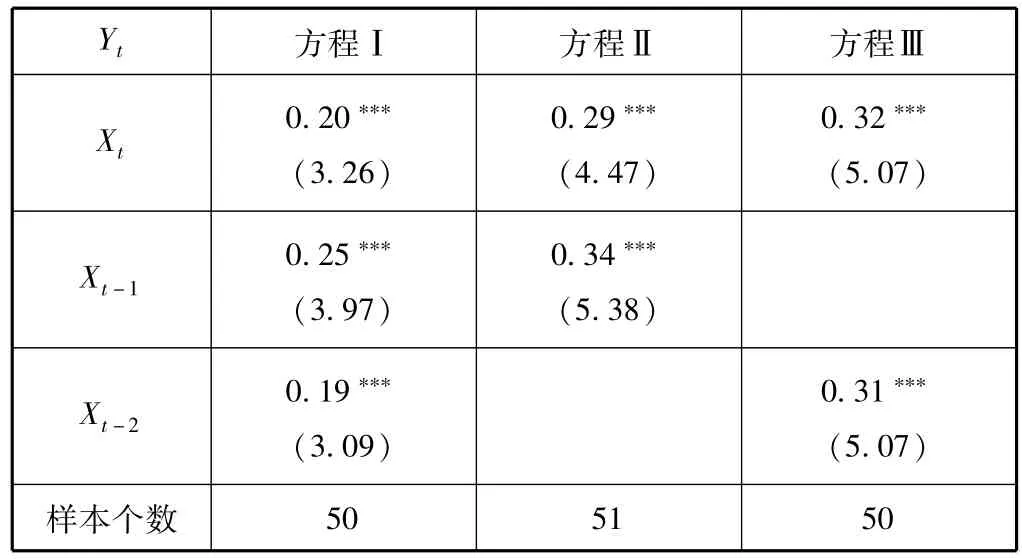
表2 许可证发证序列领先性特征的回归结果
在表2中:Yt表示“汽车(包括成套散件)及其底盘”实际出口序列;Xt表示“汽车(包括成套散件)及其底盘”许可证发证序列;Xt-1表示“汽车(包括成套散件)及其底盘”许可证发证滞后1周序列;Xt-2表示“汽车(包括成套散件)及其底盘”许可证发证滞后2周序列。表2中汇报了三个方程的回归结果。②无截距项回归。方程Ⅰ、方程Ⅱ和方程Ⅲ均能通过t检验、自相关检验和异方差检验。但方程Ⅰ的预测精度优于方程Ⅱ和方程Ⅲ。因此,最优的回归方程应该为方程Ⅰ。
许可证申领数据领先于实际进出口数据,不同商品的领先性规律不尽相同,可以通过概率统计、计量经济学方法研究这些规律。通过许可证申领序列可以构造我国进出口许可证领先指数并进行监测预警。
四、许可证领先指数及其监测预警
“希望有能力预测未来”是人类永恒追求的目标之一。经济学家们往往希望通过各类经济学模型来预测相关经济变量的未来走势,以未雨绸缪。但如何找到合适的领先指数,是经济学家们进行预测时需要解决的核心问题。许可证发证数据天然地领先于实际贸易数据,许可证发证数据是构建中国进出口领先指数的最佳选择。
实行进出口许可证管理的商品种类较多,这些商品的对外贸易规模差别较大。在许可证申领原始数据基础上,通过构建许可证领先指数,可以将数据标准化,从而更直观地把握数据的特点和规律,并利用许可证领先指数进行监测预警。
(一)许可证领先指数的构建
许可证领先指数采用月度定基指数形式。定基指数的计算公式为:

其中:Yt表示第t期发证金额(或数量);Y0表示基期发证金额(或数量)。
基期的计算和轮换原则是:以年份为0或5结束的年份为基期年,将该年度12个月的平均发证数量(或金额)进行算术平均后得到的数值定义为基期发证数量(或金额)。基期每五年轮换一次。具体说来:2011年至2015年的数据,以2010年为基期年,以2010年12个月的算术平均发证数量(或金额)为基期发证数量(或金额);2016年进行基期轮换,基期年轮换为2015年;2021年再次进行基期轮换,基期年轮换为2020年,以此类推。
由于许可证发证数量和金额对我国实际进出口贸易具有领先性,因此通过许可证领先指数可以对我国相应商品的进出口情况进行监测预警。
(二)许可证领先指数的监测预警
由于许可证申领序列领先于实际对外贸易序列,因此当许可证申领序列出现异常波动时,很可能预示着实际贸易序列也将产生异常波动。因此可以通过甄别许可证申领序列的异常波动,对实际贸易情况进行监测预警。
利用许可证领先指数进行监测预警的具体步骤是:(1)对许可证申领序列进行计量建模,根据模型结果构建预警区间。(2)对当期许可证申领量值进行监测。如果当期许可证申领量值处于异常预警区间,则发出相应预警信号。(3)对发出预警信号的商品,利用本文第三部分研究的许可证申领数据对实际贸易数据的领先性规律,预警出该商品未来实际贸易的异常波动情况。
通过数理模型甄别许可证申领序列的异常波动时,可以采用自回归滑动平均(ARMA)模型、多元回归(Regression)模型、向量自回归(VAR)模型、面板数据(Panel)模型等。通过比照参考不同模型的预警结果,以保证预警监测结果的稳健性。不同模型原理的异同见表3。具体说来,自回归移动平均模型是分析预测时间序列的常用工具;多元回归模型预设解释变量和被解释变量,解释变量为因果关系中的“因”,通常外生(解释变量内生性问题可以通过工具变量解决),被解释变量为因果关系中的“果”,为内生。向量自回归模型不预设因果关系,各变量组成向量的形式平等进入模型;面板数据模型可用来研究分国别许可证发证相关序列,同时考虑到时间序列和横截面两个维度。表3中的模型均可以作为甄别我国进出口异常波动的备选模型,但在实际工作中,选择哪种模型则需要根据不同模型的预测精度来综合考察。

表3 不同预警监测模型原理的异同
在利用数理模型构建预警区间时,通过构造对应不同置信度的置信带来设定预警区级别。具体说来:将置信度为α(α通常设定为80%)所对应的置信区间的上下界设定为预警区间的次上界线和次下界线;将置信度为β(β通常设定为90%或95%)所对应的置信区间的上下界设定为预警区间的上界线和下界线。根据国际惯例,以不同颜色划分不同预警级别。在上界线以上的区域称为红色预警区,表示许可证申领值异常大;在次上界线和上界线之间的区域称为黄色预警区,表示许可证申领值较大;在次上界线和次下界线之间的区域称为绿色区域,表示许可证申领值没有发现显著异常;在次下界线和下界线之间的区域称为浅蓝色预警区,表示许可证申领值较小;在下界线以下的区域称为深蓝色预警区,表示许可证申领值异常小。
在实际工作中,许可证领先指数的构建是一项系统工程,需要融合国际贸易理论知识、计量经济学和统计学方法、计算程序批处理以及界面展示等多方面资源。本文试图从国际贸易理论以及计量统计学层面为中国进出口许可证领先指数的构建提供理论框架和模型甄选,并为下一步的工作指明方向。
以“稀土许可证发证数量指数序列”为例,样本为2008—2012年月度稀土许可证发证数量指数序列。由于ARMA模型要求被研究的时间序列为平稳序列。因此首先要对“稀土发证数量指数序列”进行平稳性检验。检验结果为平稳。然后需要确定AR以及MA的滞后阶数。稀土发证数量指数序列的自相关系数呈现2阶拖尾,偏自相关系数呈现1阶拖尾。因此,根据检验结果确定采用ARMA(2,1)模型。模型计算结果为:
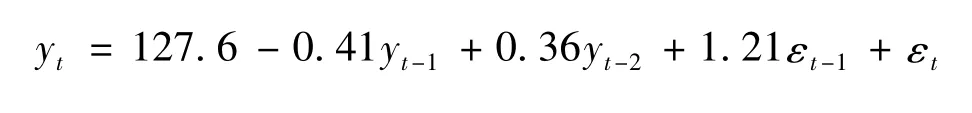
其中:yt表示稀土许可证发证数量指数序列,yt-1和yt-2为相应滞后序列,εt为随机扰动项,εt-1为相应滞后序列。
通过ARMA模型的估计结果,可以根据不同置信度(分别为80%和95%),构建发证指数序列预测值相应的置信区间并进行监测预警。预警结果参见图2。其中:黑色实线表示稀土发证数量指数实际值。不同颜色阴影区表示不同预警区间。监测预警的步骤是:首先建立起可靠的计量模型。然后当得到第t期许可证发证数据后,根据模型计算出预警区间。进而根据第t期许可证发证数据所在的预警区间,得出预警信号:正常、较大、较小、异常大或异常小。
图2显示的是稀土许可证发证数量指数序列及其相应的监测预警区间。从图2中可以看出,“稀土许可证发证数量指数序列”的部分样本点正处在异常期间内。
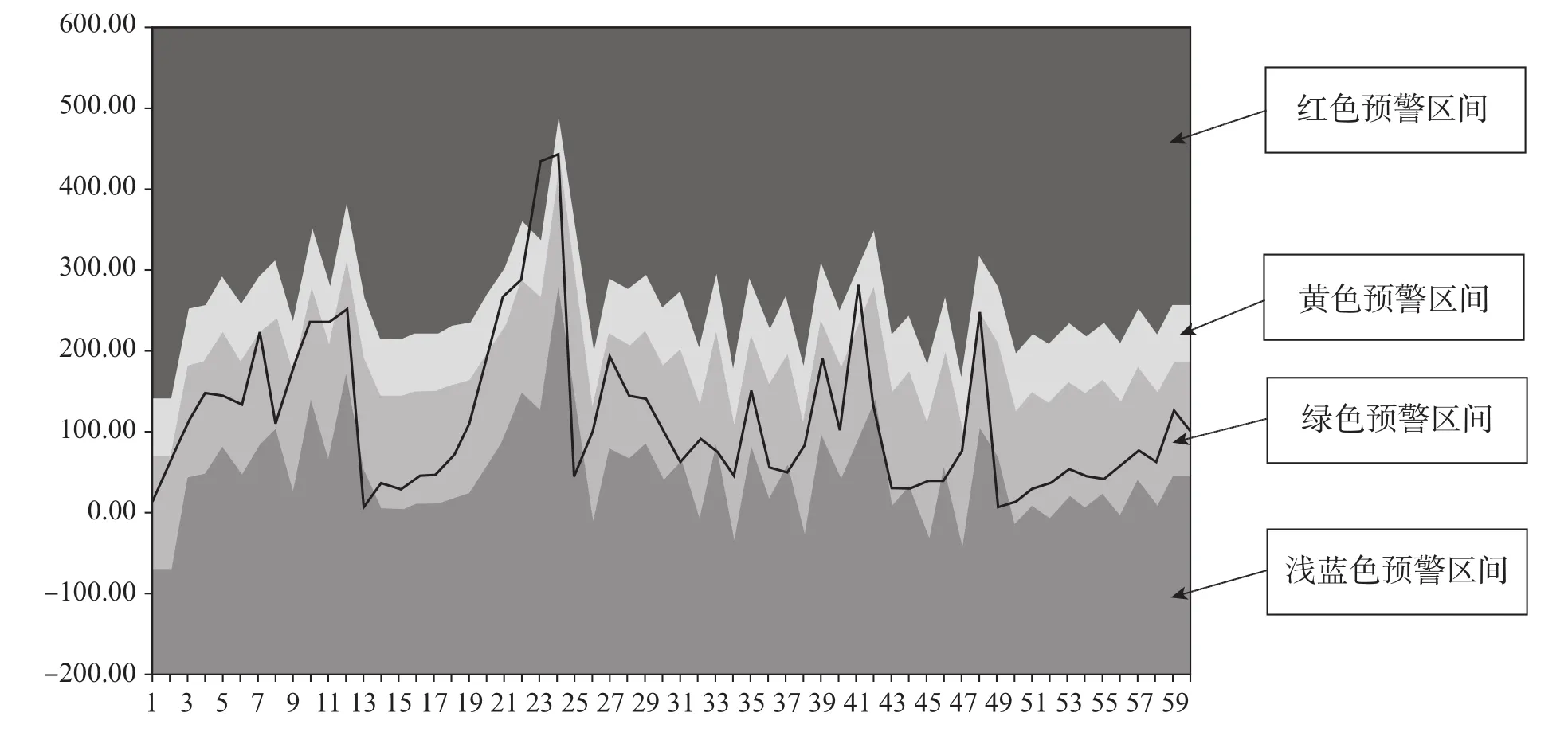
图2 稀土ARMA监测预警结果
在多元回归模型中,以发证序列为被解释变量,其他外生变量为解释变量建模。以“汽车(包括成套散件)及其底盘”(下文中简称“汽车”)为例,被解释变量为2008—2012年汽车月度发证金额,用Yt表示。解释变量为美国GDP(表征国外对中国汽车出口的需求),用 USGDPt表示;以及中国 GDP(表征中国国内需求)①GDP数据通常为季度数据,通过代数线性插值将季度数据变为月度数据。,用CNGDPt表示。得到的回归结果为:

在向量自回归模型中,用2008—2012年月度Yt、USGDPt、CNGDPt序列以及它们的滞后序列建模,得到的结果为:

其中:USGDPt-1,USGDPt-2分别表示美国GDP滞后1期、滞后2期序列;CNGDPt-1,CNGDPt-2分别表示中国GDP滞后1期、滞后2期序列。
在面板数据模型中,包含横截面和时间序列两个维度。被解释变量Yit表示2008—2012年中国“汽车(包括成套散件)及其底盘”出口分国别发证金额序列。其中下标t表示时间,下标i表示国别的年度数据。解释变量 GDPit表示2008—2012年中国“汽车(包括成套散件)及其底盘”出口目的国GDP。根据Hausman检验区分固定效应(FE)和随机效应(RE),根据模型的效果,RE更好一些。模型计量结果为:
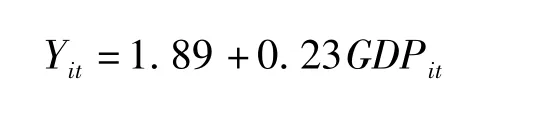
多元回归模型、向量自回归模型、面板数据模型的监测预警原理与自回归移动平均模型类似,不再赘述。不同模型得到的监测结果相互印证,相互补充,以提高监测预警结果的准确性和稳健性。
在监测预警中应该包含哪些模型以及模型的权重,需要根据模型在监测预警中的实际效果进行设定和调整。一个成熟的监测预警系统通常需要计算机批处理数据、进行批量模型计算和结果输出。本文的研究主要是探索和测算,下一步要尝试进行批处理。批处理可能会丧失一定灵活性,因此在批处理时需要为用户保留一定的灵活性和开放性。灵活性是当某个或者某些商品的监测预警结果需要被特别关注时,系统能允许用户进行针对个别商品或者小类商品的操作;开放性是指系统需要保留增减序列、变量、监测预警模型的渠道。
五、许可证综合领先指数及其监测预警
进出口许可证领先指数建立在单商品基础上,可以通过聚类分析等方法,构造进出口许可证综合领先指数,并进行相应的监测预警。
聚类分析(cluster analysis)也叫分类分析(classification analysis)或数值分类(numerical taxonomy),是一组将研究对象分为相对同质群组(clusters)的统计分析技术。聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
k均值聚类是最著名的划分聚类算法,简洁和效率使得它成为所有聚类算法中最广泛使用的方法。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数把数据分入k个聚类中。
如果指定将自动进口商品分为六类,则聚类的结果见表4。

表4 聚类分析结果(分为六类)
如果指定将自动进口商品分为五类,则聚类的结 果见表5。

表5 聚类分析结果(分为五类)
如果指定将自动进口商品分为四类,则聚类的结 果见表6。

表6 聚类分析结果(分为四类)
可以根据聚类分析的结果和实践经验,对商品进行分类和加总,构建综合领先指数。具体说来,如果商品X1,X2,…,XK被分为一组,那么取商品X1,X2,…,XK在基期年度的许可证发证金额w1,w2,…,wK为权重,对同组商品的发证数量(或金额)指数进行加权平均,从而得到许可证综合领先数量(或金额)指数。在指数构建实践中,“权重的确定”一直是困扰学者们的难题。如果把权重设为外生常数,那么随着时间的推移,情况发生变化,固定不变的权重对现实的模拟精度会降低。因此通常需要使用动态权重。权重的动态调整规则是需要进一步思考的课题。
与分商品领先指数的监测预警类似,可以利用模型对综合领先指数进行监测预警。
分商品许可证领先指数及其监测预警有利于个人、企业及政府对单个重点商品的贸易情况进行预判以及制定相应对策。许可证综合领先指数及其监测预警有利于不同指数使用者对相应整体情况的预测并可供相关决策时参考。
六、结论
对经济运行进行监测预警是经济研究中的一个重要内容,对外贸易在我国经济中占有十分重要的地位,对我国对外贸易进行监测预警显得尤为必要。配额许可证事务局管理着全国许可证申领数据库。许可证申领数据领先于我国对外贸易数据,利用许可证数据库可以有效地对我国对外贸易情况进行监测预警,提高许可证管理的效率。本文主要结论如下:
(1)许可证数据库具有构建许可证综合领先指数并进行监测预警的数据基础。数据库信息具有大样本特性,使得统计分析具有渐近无偏性。我国实行进出口许可证制度管理的商品通常在我国对外贸易中占有重要地位。这些商品之间的替代互补关系以及与我国相应经济部门的关系,都可以在这个数据库中得到体现。商务部配额许可证事务局掌握的这一独特数据库,是构建我国进出口综合领先指数并进行监测预警的宝贵资源。
(2)许可证申领数据对我国对外贸易具有领先性,但不同商品的领先规律不同。许可证数据具有对我国贸易数据的天然的、与生俱来的领先性。笔者通过概率统计分析、计量经济分析等方法对这种领先性进行了系统的研究。研究表明,我国实施进出口许可证管理的商品,许可证发证金额(数量)对相应的对外贸易额(量)具有领先性,但不同商品的领先规律不同。具体说来,领先时间的长短、领先峰值的个数及分布不尽相同。许可证申领数据的确可以作为监测预警相应对外贸易情况的有利数据序列。
(3)可以运用数理方法对许可证申领数据进行建模并进行监测预警。根据国际通行的监测预警管理,预警通常分为五个级别,并以不同颜色加以区分。本文中,笔者通过ARMA模型等对许可证发证序列进行监测预警,以不同的置信度所对应的置信区间构建预警区间,具体说来,将预警信号分为红色、黄色、绿色、浅蓝色、深蓝色五种。
(4)本文采用聚类分析法对商品进行了组合。同组商品的许可证领先指数可以加权平均得到综合领先指数。但是由于不同商品许可证序列的领先性规律不尽相同,因此建立在单个商品上的商品指数的预警监测功能要优于综合指数。对单一大类商品许可证领先指数的构建以及监测预警结果比较稳健。
对外贸易在我国经济中占有重要的地位。对重点商品对外贸易情况的监测预警将有利于个人、企业,特别是有利于政府相关职能部门进行科学决策。本文利用商务部配额许可证事务局许可证申领数据,采用概率统计和计量经济学等数理方法,探索性地提出了构建“中国许可证综合领先指数”的方法并进行了相应监测预警研究,具有一定的开创性。
猜你喜欢
中国化肥信息(2022年8期)2022-11-30 06:20:00
中国化肥信息(2022年4期)2022-06-07 06:34:34
趣味(数学)(2022年3期)2022-06-02 02:32:50
中国核电(2021年3期)2021-08-13 08:56:00
进出口经理人(2020年11期)2020-11-24 02:51:00
中国化肥信息(2020年6期)2020-11-20 07:59:56
进出口经理人(2020年10期)2020-11-17 08:26:22
汽车观察(2018年10期)2018-11-06 07:05:28
环境保护与循环经济(2017年4期)2017-03-03 17:50:30
中国卫生(2015年7期)2015-11-08 11:09:56
