
TMS320C6678高速串行接口的传输性能研究※
2015-09-12 06:43:00冯超张涛
单片机与嵌入式系统应用 2015年11期
冯超,张涛
(天津大学 电子信息工程学院,天津300072)
冯超(硕士),研究方向为多核DSP应用;张涛(副教授),研究方向为嵌入式系统研究与DSP应用。
引 言
本文以TMS320C6678EVM 板上三种高速串行接口的传输性能为切入点,研究其传输原理,以及造成理论带宽与实测带宽不一致的原因,分析了影响其传输带宽的因素,客观地对多种高速串行接口进行更为系统的研究。
1 高速串行接口
1.1 PCIe接口及其拓扑结构
PCI Express是继ISA、PCI之后的第三代I/O 总线互联技术,其接口已经成为时下主流的高速串行接口。TI是最早将该技术引入自身产品中的公司之一,在TI的技术文档中一般将该接口称为PCIe。PCIe具有低引脚数、高稳定性、高传输速率的特点。在最新的PCIe GEN 3标准中,每个通道单向理论数据传输速率可达8.0Gbps[4]。
1.2 SRIO接口及其传输方式
SRIO 支持在Direct I/O 模式和Message Passing模式下的数据传输。Direct I/O 模式的数据包必须包含向目标设备进行读写操作时对应的确切地址,而且此模式需要源设备保留目的设备的内存地址表。这些表建立后,RapidIO 的源控制器将会根据表中的数据计算目的地址,并将其插入到数据包格式头当中。RapidIO 的目的设备会在接收到包头后,将其中的目的地址提取出来,并将有效负载通过DMA 传输给内存。
1.3 HyperLink接口
HyperLink提供了一个高速、低延迟、低引脚数的通信接口,其扩展CBA 3.x(Common Bus Architecture 3.x)的传输协议,是TI KeyStone架构设备独有的高速接口,不具有工业规范,这也在很大程度上增强了该接口的灵活性,能够仿真当下所有外围接口的机制。
1.3.1 HyperLink传输原理
HyperLink在功能上可以分为两部分:一部分负责传输基于串/并行转换器SerDes(Serializer/Deserializer)的数字信号;另一部分负责传输基于LVMOS(Low Voltage Complementary Metal Oxide Semiconductor)的边带控制信号(sideband control signals)[8]。
在向外发送端,VBUSM 的从接口将地址和多种CBA事物进行打包,通过FIFO 的缓存buffer发送给发状态机(TxSM)模块。发状态机负责将256位的CBA 总线转换给外部串行接口,在这个过程中,需要通过PLS 模块对MAC传输数据进行编码。在向内接收端,PLS模块将收到的串口比特流进行同步、解码,然后交给收状态机(Rx-SM),完成与发送端相反的过程。
另外,HyperLink的边带信号提供了流控制和电源管理控制信息。HyperLink内部的状态机会自动管理流控制,减少电源功耗,这些操作不需要进行任何软件干预。流控制信号是通过RX 向TX 反馈,而电源管理是在TX端进行控制。
1.3.2 HyperLink编码机制
HyperLink的传输协议是基于packet,并支持多重读写和中断处理。协议支持1-lane和4-lanes模式,每一lane可以达到12.5Gbaud的速率。此外,相对于传统的8b10b接口传输编码机制,HyperLink在物理层使用了更为有效的编码机制,减少了编码的冗余。编码过程是在PLS模块中实现,使用GFP32/33编码标准,编码流程如图1所示。
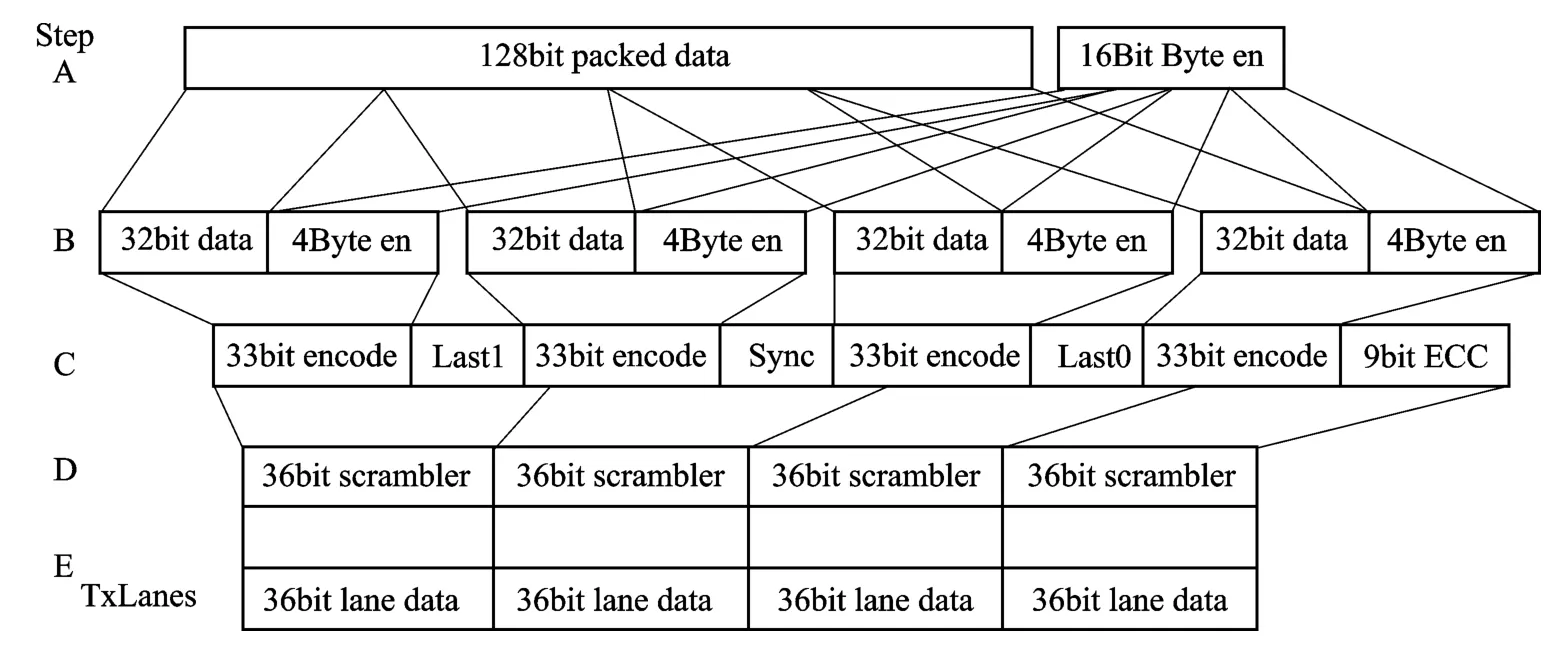
图1 HyperLink数据流编码流程
第1步:在FIFO 中取128位的数据与相应的使能位16位,拆分组合,每32 位数据与4 位使能位组合,总共144位的信息。
第2步:使用GFP规范将上一步中组合的36位编码为33位,生成总共132位信息。
第3 步:将上步中生成的4 部分数据附加上相关MAC的最后标志位、1 位同步位和9 位ECC,最后生成144位的信息。
第4步:将上一步中144位的信息拆分为4路36位的数据单元。
第5步:规整每一路的数据,删除重复数据模式以避免接收出错。
2 传输性能测试
2.1 TMS320C6678存储结构
TI C66x系列多核DSP结合了之前C64x+与C67x+的优点,同时支持定点与浮点操作。单核最高主频可达1.4GHz[9]。本文以TMS320C6678为代表,该芯片具有8个核,每个核内包括32KB L1P(Level-1program memory)、32 KB L1D(Level-1data memory)和512KB LL2(Local level-2 memory)存储区,这些存储区支持RAM 或被使能为Cache。核外有4 096KB MSM(multicore shared memory),该存储空间可被每个核访问,MSM 通常情况下被配置为全部SRAM,也可配置成为SL2(shared L2)。C6678片外接有64位1333MHz DDR3,最大支持扩展到8GB。
2.2 Cache对HyperLink性能影响
HyperLink速率配置为10Gbps,DDR3配置为64位位宽,1333MHz读写速率。传输块大小为64KB,传输带宽的计算是由传输总的字节数除以传输所用时间获得。由表1可知,Cache被使能后,DSP 核通过HyperLink进行读操作的性能大为提升。对于读操作时间的计算,本地的DSP核必须等到对端将信息反馈过来才认为结束。
从图2中可以看出,在使能不同Cache的情况下,DSP 核通过HyperLink 传输数据的带宽与所传输数据块大小的关系。图中数据为本地LL2 访问远端DDR3所得。传输的数据块较大时,三种情况的传输性能均下降。
在使能L1D Cache后,HyperLink的传输性能有很大的提升,当L1DCache、L2Cache全部使能后反而遏制了HyperLink的传输性能。这是因为L2 是write-allocate Cache,使能L2Cache后每次进行写操作,HyperLink都会先从将要写入的存储区域读取128字节的数据到L2Cache,然后在L2Cache中修改数据,最后在Cache冲突时写回到原来的存储区域,或在使用EDMA的情况下人为地写回原存储区域。此过程在一定程度上降低了HyperLink的传输性能。
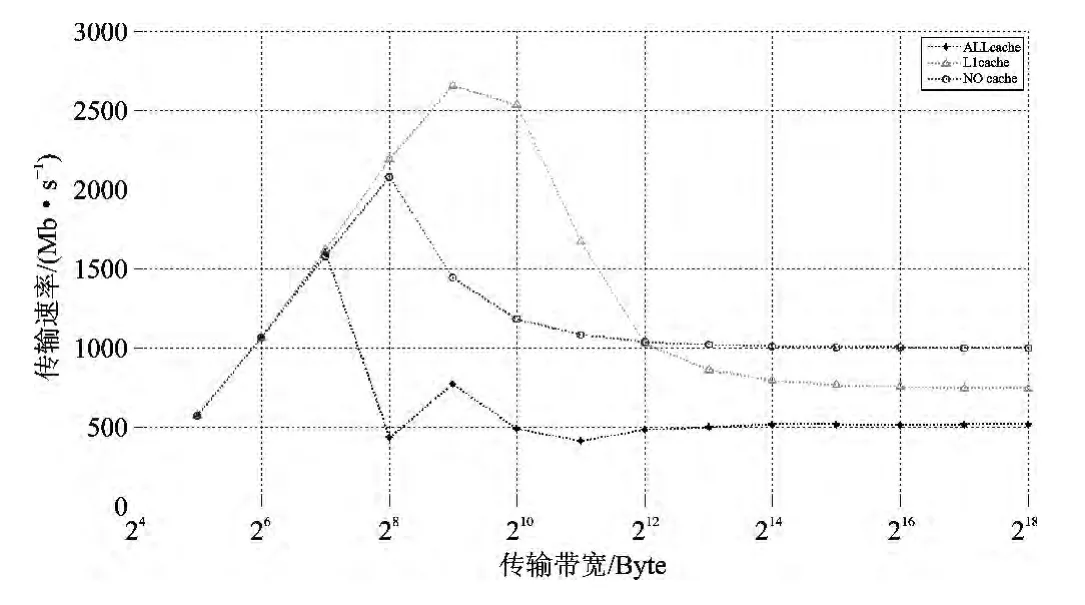
图2 HyperLink在使能不同Cache情况下的传输带宽
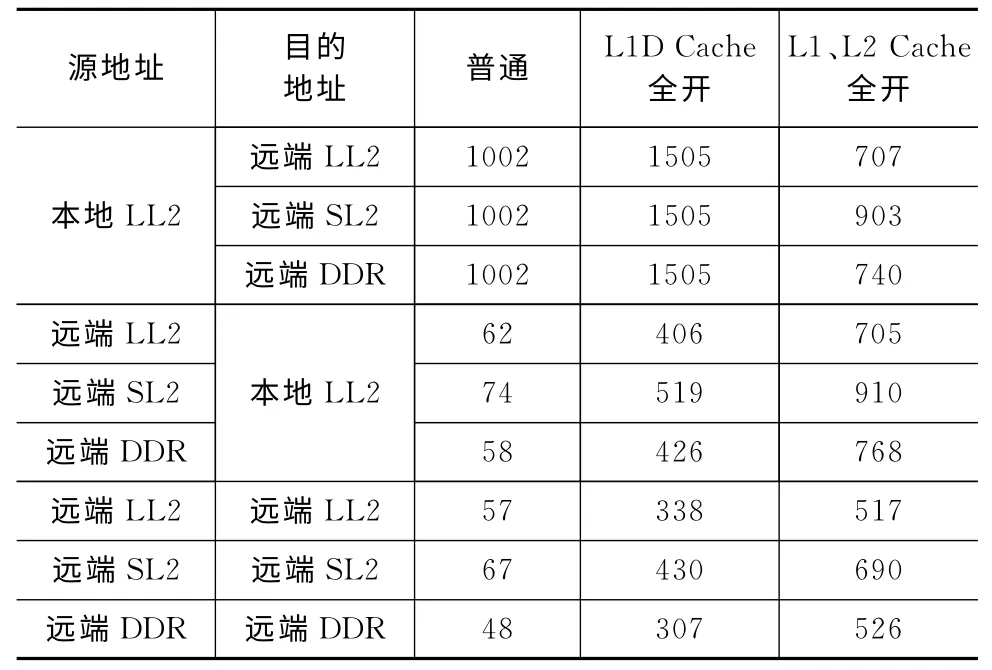
表1 DSP核通过HyperLink实现数据传输带宽(MB/s)
2.3 PCIe性能测试
在PCIe速率配置为5Gbps、DDR3配置为64bit位宽、读写速率为1333 MHz的情况下,进行传输带宽的实测。传输的数据块大小为64KB,传输带宽的计算是通过总的传输字节数除以传输所用时间获得。由于在映射为远端的PCIe空间在仅使能L1DCache的情况下,连续的多个写操作可能被合并成一个操作,所以表2仅对普通情况下和L1D、L2Cache全部被使能情况下PCIe在不同类型存储空间上的传输带宽进行了统计。
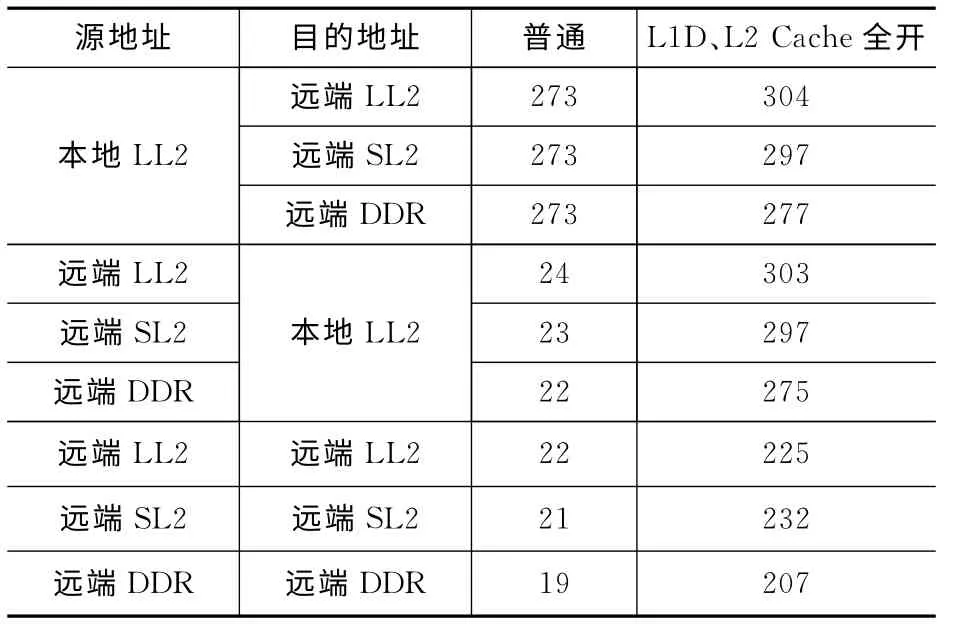
表2 DSP核通过PCIe实现数据传输带宽(MB/s)
上述实验对PCIe传输较大数据块的性能进行了测试。表2中数据为DSP核通过PCIe在本地LL2分别与远端LL2、SL2和DDR3建立映射的实测带宽。由数据可知,在普通情况下,PCIe传输在访问远端LL2、SL2 和DDR3的传输性能没有明显差异,在使能Cache 后,对DDR3的访问速度会稍慢一些。
图3 是在L1D Cache、L2Cache全被使能和不使能Cache的情况下分别测得的PCIe传输数据带宽与所传输数据块大小的关系。可以看出,Cache被使能后反而在一定程度上遏制了PCIe的传输性能,此现象同HyperLink一致。在64字节时传输速率达到峰值,超过128KB后不能保证数据的正确传输,这与电气特性有关。另外,在传输数据块为128字节时,两种情况的传输性能有明显的差异,这与C66x系列DSP本身的Cache结构有关。
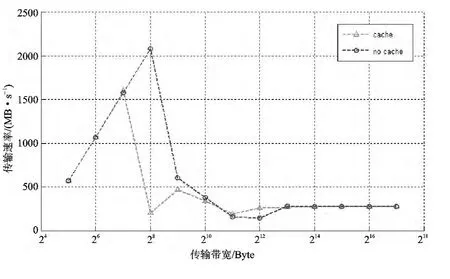
图3 本地LL2访问远端DDR3带宽
2.4 SRIO性能测试
在SRIO速率配置为5Gbps时,DDR3配置为64bit宽,读写速率为1 333MHz的情况下,进行传输带宽的实测。传输的数据块大小为32KB,图4分别描述了Direct I/O模式下SWRITE、NWRITE、NWRITE_R和NREAD四种传输方式下的传输带宽。图中9组数据分别是单端口模式下配置为4路时,DSP核通过SRIO从本地LL2、SL2和DDR3分别访问远端LL2、SL2和DDR3所得的传输带宽。
由图4可知,在Direct I/O 模式下,写操作的传输速率要高于读操作的传输速率,但是有反馈的写操作耗时最长,且本地LL2与SL2要比DDR3访问远端存储设备的速率高。
表3中数据为在SRIO 在多端口模式下,配置为不同方式下实测的传输带宽。
由于SRIO 本身具备硬件纠错功能,当检测到数据传输错误后会自动重传,造成带宽的损耗,另外,背板的硬件电气特性也会直接影响到实测的带宽,这些因素均会造成实测带宽与理论带宽的差距。
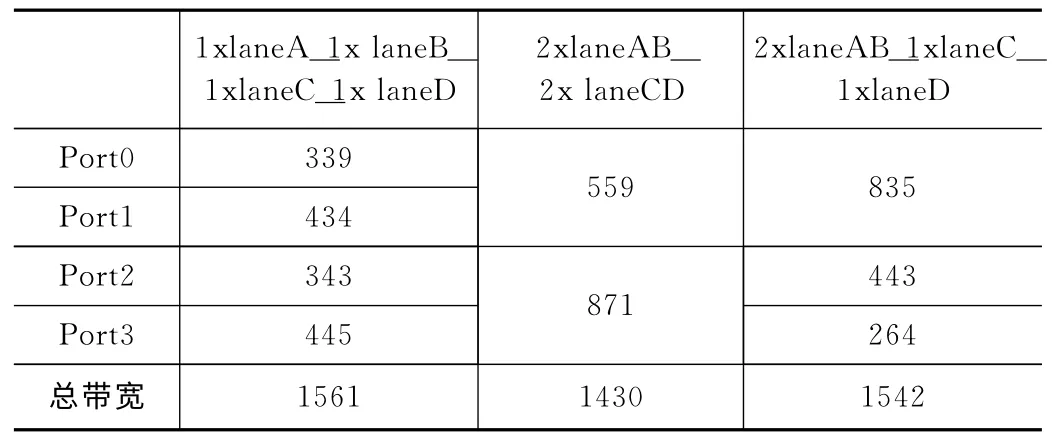
表3 多端口不同配置方式实测带宽(MB/s)
3 三种接口性能比较
上文对TI KeyStone架构设备中主要的三种高速串行接口分别进行实际测试,并分析了影响其传输性能的因素,下面将对三种接口进行对比。三种接口的各种参数表中数据略——编者注。
HyperLink可以配置为1路或4路,但是仅适用于设备点对点的拓扑结构。PCIe虽然可配置为1路或2路,但其单端口的特性以及PCIe协议规定其树状拓扑结构,需要SW 才能扩展RC,这对于搭建多核多芯片的系统增加了软件调度的复杂程度,也在一定程度上限制其系统扩展中的应用。相对于以上SRIO 比较灵活,既可以配置为单端口,又可以配置为多端口。

图4 SRIO 在不同类型存储空间传输带宽
DSP核通过三种高速串行接口在不同数据块大小情况下,在本地LL2与远端DDR3实现数据传输所得出的实测带宽趋势曲线图略——编者注。
SRIO 的传输速率随着数据块的增大,一直呈现上升趋势。在较高带宽的情况下,硬件自身硬件电气特性导致的误码成为限制带宽的瓶颈,HyperLink和PCIe接口的带宽变化趋势基本保持一致。在传输的数据块较小时,传输开销成为限制传输带宽的主要因素。HyperLink 和PCIe两接口在传输的数据块大小为128字节时均达到较高的传输速率,这与C66x系列DSP本身的Cache结构有关。C66x系列DSP 的L2Cache line为128 字节,Cache控制器每次都是以Cache line为单位操作[10],因此在数据128字节对齐的情况下Cache的读写能够达到较好的效果,而Cache Misses造成曲线在达到较高值后迅速降低。
HyperLink与PCIe相比,在传输速率上具有一定优势,但是在系统的扩展方面,PCIe更为适合。这两种高速串行接口在传输较小数据块时都具有较高的带宽,相对而言,SRIO 以其灵活的端口特性和拓扑结构,在系统的扩展方面具有优势,并适合对较大的数据块进行搬移。
结 语
本文研究了TMS320C6678EVM 板上三种高速串行接口的传输性能,对影响其带宽的因素进行了分析,并结合三种接口的传输特性,讨论了其在高性能系统扩展中的优缺点,为高速串行接口的研究和应用提供一定的参考。
编者注:本文为期刊缩略版,全文见本刊网站www.mesnet.com.cn。
[1]刘德保,汪安民,韩道文.八核浮点型DSP 的双千兆网接口设计[J].单片机与嵌入式系统应用,2014,14(1):54-56.
[2]乐亮,胡善清,龙腾.新一代多核DSP-TMS320C6678 的PCIE 接口驱动设计[C]//第六届全国信号和智能信息处理与应用学术会议论文集,张家界,2012.
[3]周佩,周维超,王凯凯.TMS320C6678多核DSP 并行访问存储器性能的研究[J].微型机与应用,2014,33(13):20-24.
[4]PCI-SIG PCI.Express Base Specification Revision 3.0,2010.
[5]Texas Instruments.Peripheral Component Interconnect Express(PCIe)for KeyStone Devices User Guide,2013.
[6]Texas Instruments.Serial RapidIO(SRIO)for KeyStone Devices User Guide,2012.
[7]RapidIO.RapidIO Interconnect Specification Revision 3.1,2014.
[8]Texas Instruments.HyperLink for KeyStone Devices User Guide,2013.
[9]Texas Instruments.TMS320C6678 Multicore Fixed and Floating-Point Digital Signal Processor Data Manual,2014.
[10]TI.TMS320C66xDSP.Cache User Guide,2010.
猜你喜欢
河北北方学院学报(自然科学版)(2021年11期)2021-12-28 04:31:26
通信电源技术(2021年3期)2021-06-02 23:46:02
科学家(2021年24期)2021-04-25 13:25:34
汽车实用技术(2019年6期)2019-04-11 02:53:30
网络安全和信息化(2017年6期)2017-11-23 08:36:18
黑龙江电力(2017年1期)2017-05-17 04:25:16
CHIP新电脑(2016年9期)2016-09-21 10:31:09
发明与创新·大科技(2015年9期)2015-05-30 10:48:04
电脑迷(2015年6期)2015-05-30 08:52:42
职业·中旬(2015年4期)2015-05-30 05:54:49
