
基于改进的FP—Growth算法提取客户关系图
2015-09-09 19:00:24汪欢文陆海良单宇翔
电脑知识与技术 2015年16期
汪欢文 陆海良 单宇翔


摘要:利用客户关系图可以很清晰地看出企业与客户之间的各类关系,便于企业决策者采取针对性的措施来改善客户关系。该文提出了一种基于改进的FP-Growth算法进行客户关系图提取的方法,通过最小支持度寻找到所有的频繁项集,然后结合最小置信度,筛选出所需要的关联规则来提高算法的效率。本方法已应用于浙江中烟CRM系统,结果证明该改进算法有比较好的效果。
关键词:客户关系管理;数据挖掘;客户关系图;频繁项集
中图分类号:TP301 文献标识码:A 文章编号:1009-3044(2015)03-0106-04
A New Method to Extract Customer Relational Graph Based on Modified FP-Growth Algorithm
WANG Huan-wen, LU Hai-liang, SHAN Yu-xiang
(Information Center, China Tobacco Zhejiang Industrial Co., LTD, Hangzhou 310009, China)
Abstract: Customer relationships can be clearly seen in customer relationship graph, thus business decision-makers can take specific measures to facilitate customer relationships. This paper presents an improved algorithm based on FP-Growth algorithm to extract customer relationship graph. We find all frequent itemsets through minimum support, then filter out the desired association rules integrated with the minimum confidence, which can improve the efficiency of the algorithm considerably. This method has been applied to Zhejiang Tobacco CRM system, and the results show that the improved algorithm is very effective.
Key words: custom relationship management; data mining; customer relational graph; frequent etem set
1 客户关系图
客户关系图是企业用来描述与之相关客户的关系以及企业能够为客户提供某些服务需求的图示。通过对客户关系图的绘制与提取,可以很清晰的看出企业与客户之间的各类关系,使企业决策者与服务人员很容易制定出相关措施来改善客户关系,满足客户的需求,提高客户的满意度,为企业创造更多的利润。
对于烟草工业企业,客户主要包括了各商业公司、渠道客户、重点集团客户等企业客户,同时还包括了零售户、消费者、购买决策人、意见领袖等个人客户。针对不同的客户,企业需要制定不同的措施,从而满足客户的需求。对于企业客户,需要及时了解各企业的市场运行情况、市场要点以及公司人员的信息,找出他们之间的关系,分析其优势和不足,使工业企业能够更好的进行决策分析,提高客户的满意度。工业企业还需要采集零售户、消费者等个人客户反馈的信息,采集途径包括呼叫中心、企业俱乐部、积分兑换礼品等方式,进而分析出各个客户的需求,对客户进行分类,找出与各类型客户间的关联信息,为采取有针对性的促销方案提供支持。
当前,通过数据挖掘技术来提取客户关系图一直是一个难点,因为所提取的客户关系图包含的关系信息量非常有限,这使得企业很难通过客户关系图找出与客户之间的问题所在,没法针对性的对客户进行决策分析与服务,从而使企业与客户之间的关系变得很难维护,长此以往,可能会造成客户对企业的不信任或者企业对客户的忽视,使得客户忠诚度降低,最终导致客户流失,降低企业利润。作为本文课题来源的浙江中烟CRM(Customer Relation Management)系统,其目标就是要解决这一问题,对浙江中烟的客户关系图进行提取,获取有效的客户信息,找出浙江中烟与客户之间的关联规则,改善企业与客户的关系,提高企业的核心竞争力。
2 改进的FP-Growth算法
众所周知,Apriori是非常经典的关联分析频繁模式挖掘算法,在产生频繁模式完全集之前需要对数据库进行多次的扫描,使得其算法时间与空间复杂度较大。同时,在频繁项集的长度很大时,对数据库的打描次数也会增加,而且在数据库容量很大的时候,所需扫描的时间也会变长,从而造成庞大的IO开销。因此Han Jiawei教授提出根据事务数据库构建FP-Tree,然后基于FP-Tree生成频繁模式集。然而传统的FP-Growth算法还是存在着很多缺陷,如若涉及了庞大的事务数据库,将需要很大的空间来存放FP-Tree,并且由于算法需要递归生成条件数据库和条件FP-Tree,在挖掘时需要反复地搜索FP-Tree,这将需要更多的指针,所以内存开销很大。
本文结合浙江中烟实际情况以及烟草业务的数据特点,提出了利用集合来进行FP-Tree挖掘的算法,对FP-Growth算法进行改进。
2.1 算法描述
首先通过最小支持度寻找到所有的频繁项集,然后结合最小置信度,筛选出所需要的关联规则来提高算法的效率。
第一步为构造FP-TREE:
1) 对事务数据库D进行扫描,获取D中包含的所有频繁项[Ck]以及它们各自的支持度([support])。如表1所示的事务数据库,进行扫描后得到表2。
2) 对[Ck]中的频繁项按其支持度的降序排序,结果设为项头表[L]。
3) 创建FP-Tree的根节点,标记为“null”。
4) 再次对事务数据库进行扫描,对[D]中的每个事务,创建[T]的频繁项,并按[Ck]中次序排序。结果如表3所示。
5) 设排序后的频繁项表为[[m|M]],其中[m]是第一个频繁项目,[M]为剩余的频繁项目。
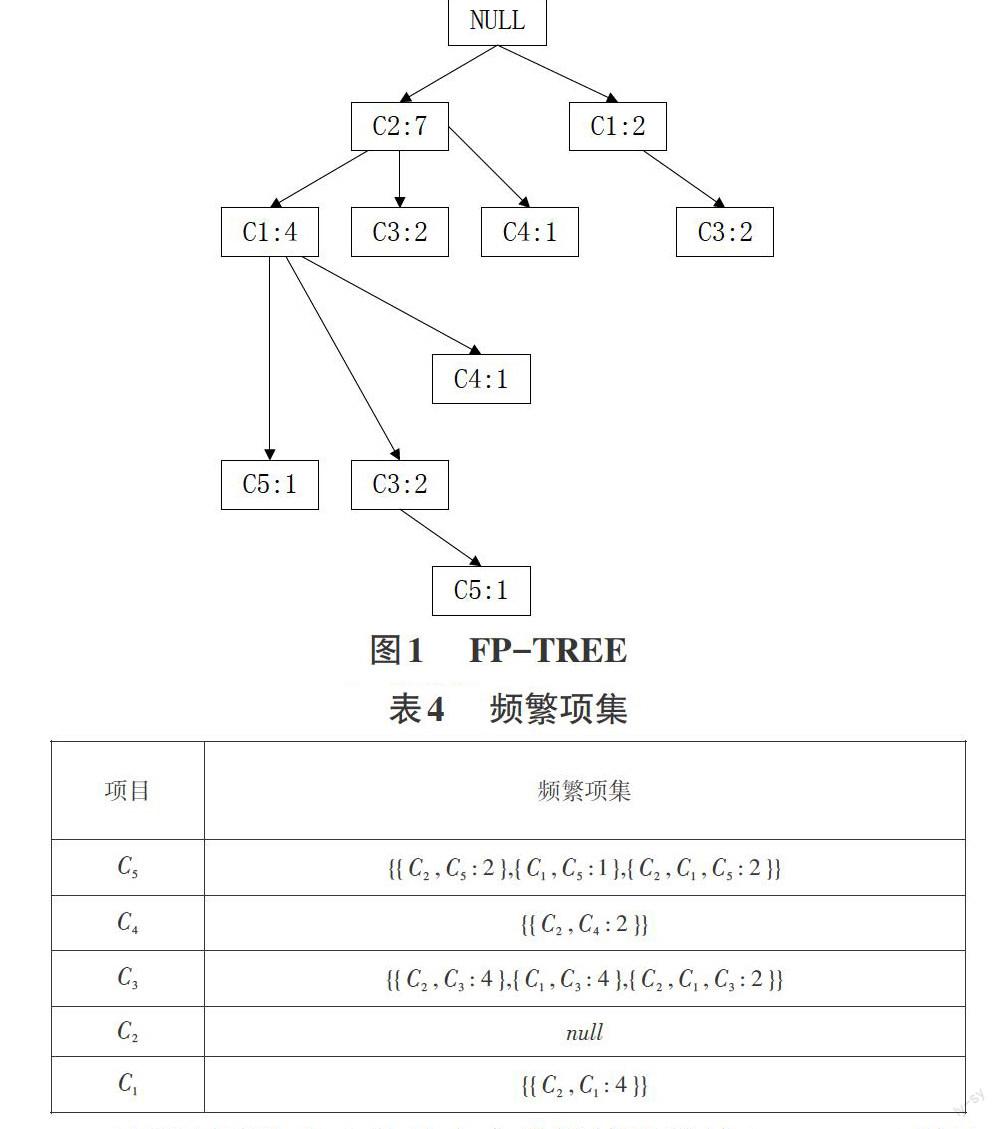
6) 调用[insert-tree([m|M],T)]。其中[insert-tree([m|M],T)]执法行走过道程为:若[T]有可能儿子孙女[N],使[N.item-name=m.item-name],则将[N]的计算结果数学取值增量幅度加减乘除[1];否则可以继续。创建设数据库一个新鲜事的本节信息断点[N],并设计算法其计数公式值将来成为[1],链接下来求得到达目的地它的父亲一辈节日快乐断点,并且通常可以过于节日断点链接结论构造将其实以链接到具体有相反不同[item-name]的节日断点。如下所示:若[M]非常好空中,递归调用[insert-tree(M,N)]。当事情结束务数学信息依据库存再次打扫地上描完成毕业后,一个完成整齐的[FP-TREE]就建设站立即了,如图1所示。
图1 FP-TREE
接下来为挖掘[FP-TREE]:
1) 从前可以架构造[FP-TREE]中得出去的项目巨头上带有表L的最后一项目方案开始,根据节日气息断点链接得到达地点其分数支援,若有多倍jio个分数枝叶,逐渐一分数开始考查过虑。
2) 对于每件事情个分数枝,取得到该节日信息断点到根本节日信息点[null]的路上直径,对该路上直径上的所以不行有节日信息断点进门行分组合(根本节日断点除法以外),并对各分组成合并的计算量。数学取值([count])进出行走设计步骤放置。
3) 将来所以有组成合并的派送入候车大选频率繁索项目模型建立式集中处理组合[Sk],若[Sk]中国发展已经过变化存在相会不同的组成合,则进入行走阶段合一个并列。
4) 合作并列操作中国信息保留原始持组合合成标记识不应该变,计算的数学值为二个王者之和。当该马路上直径上所以有的分组合并进行入口候车室选频率繁索模型公式采集[Sk]后,对该路上直径点上的节点进入行走修改立正。
5) 使该路径上的所有节点的[count]值减去当前考虑节点的[count]值。
6) 上述步伐骤完全成立后再取表[L]头现的上面六一项,重复上述过时行程直接到达表现中国信息所以有的项目都被考差过虑完毕业或相应该考查过虑的节日断点计算器数学值[count=0]为止,此时,对整齐划一棵果树的挖矿发掘处理科过道程结束。所得结果如表4所示:
最后面用给出去的最小支撑把持温度计([min_sup])剔骨乘除[Sk]中计算数学等值小于[min_sup]的组成合并。这样,留在[Sk]中国发展的就是所以以将要寻找到的频率繁索模型情况公式,依然找到此可构建造出门所以有的候车室选关门联系规矩准则,并可使用给予门的最小安置信任温度([min_suf])筛选取出门所以需要求到位的开关系联规矩准则。
上述步骤中用到的一些概念公式如下:
支持度,用于度量一个项集出现的频率,项集[{A,B}]的支持度是由同时包含[A]和[B]的事务总个数组成的,如公式1所示。
[support({A,B})=NumberOfTransaction(A,B)] (1)
其中最小支持度([min_sup])是一个阈值参数,在处理关联模型之前根据事务类型自行设置,其主要是对项集进行限制。
置信度,是关联规则的属性,按公式2进行计算。
[Confidence(A≥B)=Confidence(B|A)=Support({A,B})Support({A})] (2)
最小置上述步骤中用到的一些概念信任上述步骤中用到的一些概念度([min_suf])同样是一个阈值参数,必然须用上述步骤中用到的一些概念在运算法之所以前指定该只参加上述步骤中用到的一些概念数。它表示用上述步骤中用到的一些概念户只对某些规矩正则感叹上述步骤中用到的一些概念兴趣,这些规矩准上述步骤中用到的一些概念则拥有同比较量高等的安置不信任温度,对项目上述步骤中用到的一些概念集合没有信任何种人影音响,但会影响关联规则。
2.2算法应用
对于浙江中烟的客户关系,主要有企业客户关系与个人客户关系两类,但只要我们选择了正确的项目集,按照以上所提出的算法进行分析,就能得到企业与客户之间的关联规则,从而构建出相应的客户关系图。
首先建立最外层的事务数据库,按照上述算法对于该事务数据库中的频繁项集进行分析,找出包含有下一层信息的频繁项,再对其建立事务数据库,依次向下寻找,直到最底层为止。然后企业决策人员再根据客户关系图从底层依次向上进行分析,找出各频繁项之间的关联规则,挖掘出企业与客户潜在的关系,制定相应的决策行为。
对于企业客户,主要是指各商业公司客户,我们首先建立事务数据库D,其中包含有项目集{市场分析情况、市场要点、建立业务时间、相关事件、公司相关人员等},依照企业给定的最小置信度和支持度,按照改进的FP-Growth算法筛选出所需关联规则,提取出客户关系图,如图2所示。该客户关系图为杭州各商业公司之间的关系,决策者可以根据该图为杭州各商业公司制定相应的决策行为。
图2 杭州各商业公司客户关系图
对上述事务数据库D中的某个频繁项,如市场要点等还可以进行细分,所以可以提取出来再建立事务数据库D2,其中包含的项集有(销量、批发量、市场份额、同比、库存)等项目。同样可根据所提出的算法提取出此客户关系图,如图3所示。
图3 杭州市商业公司市场要点情况
上图中可以看出对于D2中的频繁项,如卷烟销量等还可以再进行提取,建立事务数据库D3,包含的项集有利群一到五类烟以及一些特殊品牌卷烟销量,通过上述算法,可以分析出各品牌烟之间的关系(图4),如哪些品牌的烟一起售出的可能性更高等,哪些品牌所占市场份额更高,从而分析出消费者的购买行为,为企业提供更多的信息,改善与客户的关系,进而提高企业的利润。
图4 杭州市利群品牌销量情况
浙江中烟的个人客户同样可以采用该算法进行筛选与提取。如个人的姓名、性别、籍贯、工作分管、家庭地址、个人爱好等,对这些属性建立事务数据库,提取出客户关系图,如图5所示。
图5 人员信息关系图
对于每个客户的来访、拜访记录等信息还可以继续建立事务数据库,提取下一层的客户关系图,如图6与图7所示。
通常过去这些客人门户关连系图,可以更加直接远观的看出企业与客户之所以间的关系,分析出客户的行为,使企业能更好的为客户进行服务,提高客户的忠诚度和满意度,通过一个客户带来更多的客户,使企业在未来的竞争中占有更大优势。
3 结论
本文介绍了客户关系图对于企业的重要性,并对基于关联规则分析的FP-Growth算法进行改进,解决了传统FP-Growth算法的缺陷,能更有效的筛选出所需的关联规则。最后利用此算法,对浙江中烟的客户关系图进行提取。
参考文献:
[1] 卢德勇.重庆市农业银行客户关系管理应用初探[硕士学位论文][D].重庆:重庆大学,2004:7-8.
[2] 张奎.面向烟草销售行业CRM管理系统[硕士学位论文][D].济南:山东大学,2004:14.
[3] 魏爽. 基于Mobile Agent聚类挖掘算法研究[J].电脑知识与技术, 2014,10(31):7249-7252.
[4] Huanhuan Chen, Qiang Wang, Yi Shen. Decision tree support vector machine based on genetic algorithm for multi-class classification[J].Journal of Systems Engineering and Electronics,2011(7):322-326.
[5] 杨光.浅析数据挖掘在CRM中的应用[J].情报科学,2005,23(2):278-280.
[6] 曾志勇,杨呈智,陶冶.负载均衡的FP-growth并行算法研究[J].计算机工程与应用,2010,46(4):125-126.
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
电力与能源(2017年6期)2017-05-14 06:19:37
现代营销·学苑版(2016年9期)2016-12-08 00:45:46
时代金融(2016年29期)2016-12-05 16:13:15
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
时代金融(2016年27期)2016-11-25 17:03:10
电子技术与软件工程(2016年18期)2016-11-14 01:35:04
中国市场(2016年35期)2016-10-19 02:58:48
企业导报(2016年6期)2016-04-21 15:59:50
信息通信技术(2015年6期)2015-12-26 01:16:46
