
面向磁盘故障预测的机器学习方法比较*
2015-09-05 06:36蒋艳凰卢宇彤周恩强
计算机工程与科学 2015年12期
董 勇,蒋艳凰,卢宇彤,周恩强
(1.国防科学技术大学计算机学院,湖南 长沙410073;2.高性能计算国家重点实验室,湖南 长沙410073)
1 引言
数据是信息系统的核心,其可用性是保证信息系统正常运行的关键。存储系统负责保存数据,提供数据访问接口,是信息系统的主要组成部分之一,其可靠性一直是研究人员与工业界关注的焦点。到目前为止,磁盘仍然是存储系统的核心组成部分。磁盘能否提供稳定可靠的数据访问能力,直接影响整个存储系统的可靠性。本文基于磁盘的SMART数据,采用机器学习的方法预测磁盘故障,实现提高存储系统可靠性和可用性的目的。
磁盘是磁、电和机械的混合体,其固有结构决定了磁盘本身的可靠性不高。Schroeder B[1]的统计说明,磁盘故障导致系统失效的比例达18.1%~49.1%。现有的大规模存储系统往往包含数百甚至数千块磁盘,大大增加了磁盘出现故障的几率。传统的提高数据可靠性的方法主要是冗余磁盘阵列 RAID(Redundant Arrays of Inexpensive Disks)技术,通过采用数据冗余,容忍单个或多个磁盘的故障,并通过数据编码方式恢复错误数据。除了在磁盘层面通过数据冗余提高可靠性,还可以在系统层面通过数据副本技术提高数据的可靠性。Google的集群系统中文件系统GFS[2]通过采用随机副本技术来提高数据修复能力。Renesse R[3]等研究了链式副本技术和伪随机的分布方法,可以提高数据可靠性。
上述技术的主要出发点是“容忍”磁盘或者系统故障,当故障发生时,系统仍然能够提供数据访问服务,属于被动容错。在此基础上,出现了磁盘的主动容错技术。SMART(Self-Monitoring,A-nalysis and Reporting Technology)是典型的主动容错技术。该技术监控磁盘运行过程中的多项参数,包括磁盘的寻道错、奇偶校验错等信息。基于SMART的主动容错主要是采用阈值方法。厂商首先设定磁盘SMART属性阈值,当实际监测到的SMART属性值超过阈值则报警,提示磁盘即将故障,这种方法简单易行,但是预警准确率较低。目前对于磁盘的运行状态,研究结果表明,使用单一的或是简单的SMART属性值还不能准确地预测磁盘故障[4]。目前磁盘厂商采用的故障预测阈值判定方法,磁盘故障误报率为0.1%,而能够预测的磁盘故障仅有3%~10%[5]。
机器学习方法[6]基于大量数据,通过对数据的分析,从中发现蕴含的规律,实现“学习”的目的,从而提高系统本身的能力。在磁盘SMART数据的基础上,采用机器学习方法,实现对磁盘故障的预测,达到及时对故障磁盘进行处理,并增强存储系统可靠性的目的。
本文采用四种典型的机器学习方法:反向传播神经网络 BPNN(Back Propagation Neural Network)、决策树(Decision Tree)、支持向量机SVM(Supported Vector Machine)和贝叶斯方法(Naïve Bayes)实现对磁盘故障的预测。上述方法的实现源自 LibEDM[7]。本文所使用的数据集包含23 395个磁盘SMART信息[8]。通过对训练集和测试集的构建,上述四种机器学习方法可以获得较高的故障预测准确度,这些结果比现有的磁盘故障预测方法要好。
2 相关工作
SMART技术源自IBM在1992年开发的预测故障分析技术 PFA(Predictive Failure Analysis)。该技术周期性测量磁盘的属性,并且在超过预定义的阈值后,向用户发送一个报警信息。工业界接受了PFA技术,并且在1994年形成了SMART标准,用于IDE/ATA和SCSI磁盘的可靠性预测。SMART的发展经历了三个阶段:(1)初始的SMART通过监控在线活动,提供对故障的预测;(2)后续版本通过增加自动的离线扫描来监控额外的操作,从而提供故障预测;(3)最后的SMART版本不仅监控磁盘的活动,而且增加了故障预防机制,尝试检测并修复扇区错误。SMART III通过空闲阶段“离线数据收集”测试所有的扇区,并确认磁盘的健康状况。作为行业标准,SMART规定了磁盘制造厂商应遵循的相关准则,目前几乎所有磁盘厂商均支持SMART技术。SMART信息保留在磁盘的系统保留区(Service Area)内,这个区域一般位于磁盘最前面几十个物理磁道,由厂商写入相关内部管理程序。基于SMART的阈值报警功能,简单易行,但是预警准确率较低。
在上述阈值方法的基础上,研究人员提出了多种基于统计方法和机器学习方法的磁盘故障主动预测技术。Hughes G F[9]在2002年提出了两个改进的SMART算法,采用统计假设测试方法,根据秩和检验(Rank Sum Test)对磁盘故障进行预测,提高故障预警的准确性,并降低误报率FAR(False Alarm Rate)。该算法在3 744个驱动器上进行实验,在0.2%误报率条件下,预测准确度提高3~4倍。Wang Yu等[10]在2013年提出基于MD(Mahalanobis Distance)磁盘检测方法。所选择的关键参数包括故障模式、机制和效果分析,以及最小冗余最大相关方法。该方法使用SMART数据集来评估所提方法的性能。实验结果表明,在FAR为0%的条件下,可以检测67%的磁盘故障,可以提供20个小时的数据备份时间。更进一步,Wang Yu[11]在2014年提出了对磁盘故障进行预测的两步统计方法。该方法主要包括两个步骤:异常检测和故障预测。使用MD将观测到的变量变成一维索引,使用Box-cox变换变成高斯变量。通过定义一个确切的阈值,检测出异常的disk。其次,采用一个基于滑动窗口的通用似然比来跟踪磁盘的异常变化情况。当在一个时间段内,如果异常出现足够多,则意味着磁盘将要出现故障。通过对模拟数据和实际数据的实验结果表明,在FAR为0%的条件下,该方法可以获得68%的故障检测率FDR(Failure Detection Rate)。MD将多变量数据转化为单变量数据,从而极大增强了计算效率。通过对关键特性子集使用基于规则的故障检测算法,增强了预测的准确性。Hamerly G等[12]使用两种贝叶斯方法来预测磁盘的故障:朴素贝叶斯子模型的混合和朴素贝叶斯分类器。前者使用期望最大化EM(Expectation-maximization)算法对数据进行训练。后者的优势在于简单,易于实现。通过针对1 936个磁盘SMART数据的实验表明,这两个方法比传统的基于阈值的SMART算法具有更高的准确性。Tan Y[13]和 Zhao Y[14]分别提出树扩张朴素贝叶斯方法 TAN(Tree Augmented Naïve Bayesian)和隐式马尔可夫模型 HMM(Hidden Markov Model)来进一步提高磁盘故障预测的FDR。其中,文献[13]的结果表明,当FAR为3%时,其FDR可以达到80%;但是当FAR为0%时,其FDR只能达到20%~30%。文献[14]的结果表明,当FAR为0%时,HMM方法的FDR为52%,但是当FAR增加时,并不能获得比TAN方法更好的FDR 值。Murray J F[15,16]比较了不同的机器学习方法,这些方法使用磁盘驱动器内部属性来预测磁盘的故障。在充满噪音和非参数化分布的数据中,检测小概率事件。基于多实例学习框架和贝叶斯分类器,文献[15]提出一个新的算法mi-NB(multiple-instance Naïve Bayes),具有较低的误报率和较好的性能。文献[16]将 mi-NB和SVM方法,unsupervised clustering和非参数化统计方法(rank-sum 和reverse arrangement)进行了比较。SVM、rank-sum和mi-NB算法比现有的基于阈值的方法性能要好,具有较低的误报率。在国内方面,Zhu Bing-peng等[17]基于 SMART 信息,采用BP(Back Propagation)神经网络模型和改进的支持向量机模型来预测磁盘故障。通过基于23 395个实际磁盘SMART数据的实验表明,BP神经网络模型在保持较低FAR的前提下,可以获得95%的FDR。华中科技大学刘景宁等[18]对RAID可靠性进行了研究,提出了一种采用SMART的RAID高可靠性方法。国防科学技术大学张超[19]提出了基于SMART信息的T2US(Time,Temperature,Utilization and S.M.A.R.T)算法预测磁盘故障,准确率达到52%,并在此基础上,构建了多级RAID结构,在一定程度上提高了RAID的可靠性和性能。国防科学技术大学胡维[20]提出基于智能预警和自修复的高可靠磁盘阵列,在磁盘故障预测中使用决策树算法和提升算法相结合的策略构建分类器,明显提高故障预测性能。
基于机器学习的磁盘故障预测方法都采用了磁盘的SMART属性。所有的机器学习方法都具有相类似的流程。首先,SMART数据被组织成包括特征值和一个分类标签的矢量。特征值是一个包括若干SMART属性的特征矢量,分类标签用于表征该磁盘是否是故障磁盘。特征矢量包括多个在不同的时间点采集的SMART属性。这些数据会被预先处理,以删除那些会导致过度拟合的属性。根据现有的训练数据集,故障预测方法根据特定的合适度测量进行迭代学习。不同的预测方法会采用不同的SMART属性,以及不同的学习策略。在故障预测过程中,除了FAR以及FDR外,用户还关心故障预测成功后,预留的数据处理时间窗口长度。一般来说,预测某磁盘即将出现故障,需要对该磁盘进行处理,包括数据迁移、磁盘替换等操作。这些操作应该在磁盘出现故障前完成。因此,如何在保证预测准确率的同时,提高预留时间窗口也是故障预测方法必须考虑的问题。
和现有的故障预测方法相比较,本文所使用的故障预测方法的不同之处在于:(1)上述相关工作中,对磁盘故障的预测主要使用一个方法,而本文使用了LibEDM内的多个机器学习方法,实现对磁盘故障的预测,并对不同方法的预测效果以及相关指标进行了对比。(2)和其他相关工作相比较,本文使用了23395个磁盘的实际SMART数据,整个数据量较大。
3 典型机器学习方法
机器学习方法通过对数据的处理,使得系统具有学习能力,从而发现蕴含的规律,提高系统能力。本文中使用了四种典型的机器学习方法,下面分别给出介绍。
3.1 反向传播神经网络BPNN
神经网络是典型的机器学习方法,在模式分类、数据挖掘等领域获得卓有成效的应用。神经网络构建网络拓扑结构,通过确定学习规则、模拟人体神经元的工作过程。整个网络包括输入层、输出层和若干隐单元。不同的层次之间具有不同的网络权值,神经网络的学习问题就是网络权值的调整问题。网络权值确定后,对于给定的输入,通过整个网络的处理,得到最终的输出结果。反向传播神经网络使用误差反向传播学习算法,其网络结构包括三个不同的层面:感知层(输入层)、联想层(隐含层)和响应层(输出层)构成。其中,隐含层可以具有多个,为了获得较好的学习效果,其层内节点数通常不少于输入层和输出层的节点数。
在本文中,磁盘的SMART信息作为神经网络的输入,经过隐含层的处理后,由输出层给出最终结果,判断磁盘是否会出现故障。
3.2 决策树
决策树方法主要用于从一组已知的样本中归纳出分类知识,并且分类知识用决策树的方式表示出来。在决策树内部,每个节点对一个或者多个属性进行测试比较,并且根据比较结果来确定节点的分支。当执行完毕后,比较过程到达决策树的叶节点,该叶节点表示了此样本所属的类别,从而完成整个决策过程。决策树的使用相对简单,要求训练样本可以用属性向量表示即可。决策树方法执行的最终结果是给出一个样本的类别判断。通过对整个样本集执行本方法,实现对样本集的一个划分。
在本文中,磁盘的SMART信息作为一个属性向量输入到决策树中,并且由决策树在叶节点给出最终判断,该属性向量所对应的磁盘是否出现故障。
3.3 支持向量机
支持向量机是机器学习和数据挖掘领域的标准工具之一,集成了包括最大间隔超平面等多项技术,具有良好的性能。特征空间和核函数是支持向量机方法的重要概念。其中,核函数可以将非线性样本数据映射到高维空间,并且不增加参数个数,从而增加学习器的计算能力。通过这种映射,可以优化样本数据的表示,简化学习任务。经过核函数映射后的样本数据,构成了特征空间。通过使用核函数映射到特征空间后,原有的复杂的属性数据更便于处理,利于区分。
3.4 简单贝叶斯
贝叶斯方法通过对待考察变量的概率的观察,以及已经观测到的数据,基于相应理论进行推理,得到最优的决策。贝叶斯方法的基础是事件的概率,以及不同事件概率之间的关系,通过直接操作概率实现机器学习,同时为衡量多个假设的置信度提供了定量的方法。
简单贝叶斯方法是一种实用性很高的分类器,其基本原理在于,在使用贝叶斯公式时,采用如下原则确定多个属性的联合概率:假定目标属性之间相互独立,多个属性值的联合概率等于每个单独属性的概率乘积。通过这种简化,大大减少属性联合概率的计算量,不需要明确搜索假设空间。
4 实验结果
本文选用源于实际应用环境的23 395个磁盘的SMART数据,使用LibEDM中提供的四个机器学习算法实现,构建实验平台,对磁盘的故障状态进行预测。
4.1 实验环境
4.1.1 实验数据
本文所使用的SMART数据集源自实际运行的数据中心。整个数据集共包括23 395块磁盘,所有磁盘具有相同的型号。每个磁盘每隔1个小时进行一次取样。根据磁盘的运行情况,所有磁盘被划分为两类:故障和正常。在整个数据集中,故障磁盘共有433块,正常磁盘为22 962块。正常磁盘共包括了一个星期的数据。对于故障磁盘,采样数据的时间更长,最长为故障发生前20天。
根据SMART标准,每次获取的磁盘SMART信息中包含多项属性。但是,部分属性对于故障预测而言,是不具有实际意义的。因此,整个数据集记录了共10个SMART属性,如表1所示。
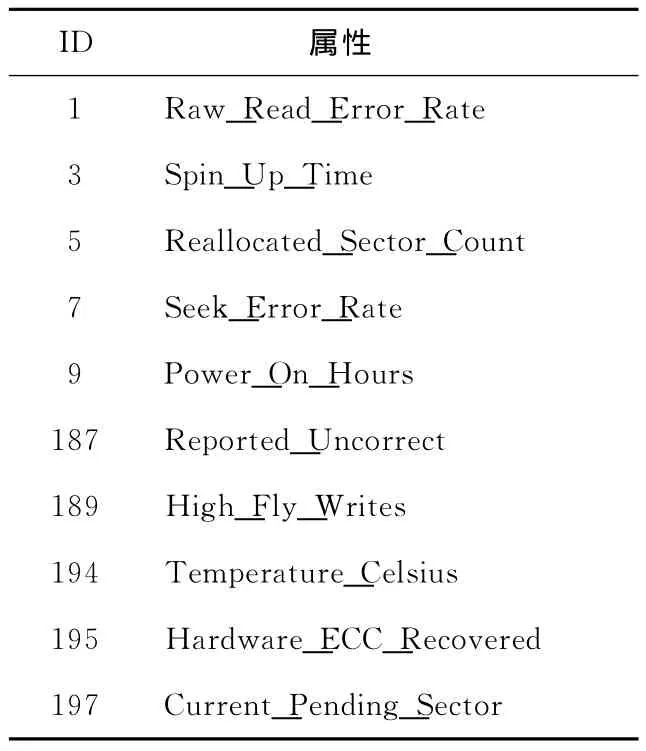
Table 1 SMART attributes表1 SMART属性
为了便于机器学习方法使用,数据集对每个属性值进行了归一化处理,将每个属性的取值设定在[-1,1]。在文献[16]中,除了使用上述10个值以外,还使用了两个属性的初始值、以及七个属性的变化率作为数据集的属性,并作为故障预测的输入。本文只选择上述10个属性,实际测试结果表明,即便在属性数量较少的条件下,通过合理配置数据训练集合,使用机器学习方法也能够获得更好的故障预测效果。
为了验证机器学习方法的正确性,将整个数据集划分为训练集和测试集。其中,训练集包含70%的正常磁盘和故障磁盘的SMART数据,测试集包括30%的正常磁盘和故障磁盘的SMART数据。测试数据集的构建采用如下方式:对于每个正常磁盘,随机选取SMART采样记录中的一条;对于故障磁盘,选择磁盘在出现故障前不同的时间窗口内的SMART采样记录。为了便于对比,和文献[16]一样,我们选择了四个不同的时间窗口,分别为12h、24h、48h和96h。之所以每个正常磁盘只选择一条SMART记录,原因在于需要保持训练集中不同采样类别之间的平衡。在整个数据集中,故障磁盘只有433块,在整个磁盘集合中的比例只有1.8%。尽管在训练集中,每个故障磁盘包括了整个时间窗口内的SMART数据,以12 h的窗口为例,故障磁盘的记录数量为3 636条。但是,对于正常磁盘而言,即便是只采用一条SMART记录,整个记录数量也有16 073条。这样,在整个训练集中,故障记录只占到18.4%。如果每个正常磁盘的记录选择多条,则故障记录在整个训练集中的比例会更低,将影响训练效果。后面的实验结果也将验证这一选择的正确性。
4.1.2 机器学习算法库
本文所使用的机器学习实现方法源自LibEDM。LibEDM是一个开源的机器学习算法库,由国防科技大学蒋艳凰等开发。它不仅包括多种经典机器学习方法,还包括集成学习、强化学习等方法的实现,以及多种数据统计工具。在算法实现的基础上,LibEDM提供了统一的访问接口,使得使用机器学习方法更加方便。
4.1.3 实验方法
基于LibEDM中的四个机器学习方法实现,以及磁盘SMART数据集,完成对磁盘故障的预测。LibEDM提供了每个算法的核心API,包括数据集的训练、数据集的测试等。具体实验方法如下:(1)首先,对原始SMART数据进行处理,构建符合要求的数据集;(2)通过API完成对数据集的初始化;(3)调用数据集训练API,完成对机器学习方法的训练;(4)调用测试API,完成对故障预测;(5)对预测效果进行统计分析,判断预测的正确性,并统计预测率、误报率、预测提前时间等各项指标。
4.2 实验结果
本节给出四个机器学习方法的故障预测结果,并对预测结果进行讨论。
4.2.1 实验结果说明
实验结果重点关注以下几个指标:
预测率Rp:实际故障磁盘中,被预测为出现故障的磁盘数量占所有故障磁盘的比。
误报率Rf:实际正常磁盘中,被预测为出现故障的磁盘数量占所有正常磁盘的比。
准确率Ra:预测状态正确的磁盘数量和全部磁盘数量的比。
提前时间Ta:对于故障磁盘而言,正确预测磁盘故障状态时间和磁盘实际故障时间之间的时间长度。
执行时间Te:指机器学习方法完成一项故障预测所需要的时间。
假定整个测试集中共有N个磁盘,其中正常磁盘No个,故障磁盘Nf个,满足No+Nf=N。在预测过程中,共有M个磁盘被预测为故障,其中实际故障磁盘数为Mf,实际正常磁盘数为Mo,满足Mo+Mf=M。在预测过程中,共有L个磁盘被预测为正常,其中实际故障磁盘数为Lf,实际正常磁盘数为Lo。则有以下关系成立:
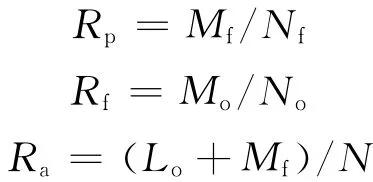
对于实际存储系统而言,磁盘故障预测的主要目的在于在磁盘故障出现之前,提前对相关的磁盘进行处理,执行包括数据备份、数据迁移在内的各项措施,避免产生数据丢失。在上述指标中,提前时间Ta刻画了机器学习方法所产生的故障预测提前量,这个值越大,意味着留给用户采取措施的时间越长,完成数据可靠性操作的概率也就越大。
执行时间Te是机器学习方法完成一项故障预测的时间,刻画了该方法的执行效率,时间越短,效率越高。尽管在实际系统中,留给故障预测的时间可能会比较长,在上面的数据集中,每隔一个小时采样一次,意味着故障预测可以在这一个小时之内完成。但是,当系统规模很庞大时,大量的预测任务会给机器学习方法带来较大的压力。提高执行效率,依然具有其内在的现实意义。
4.2.2 预测率结果比较
预测率刻画了机器学习方法发现磁盘故障的能力。图1给出了四种方法在预测率的结果比较。其中,横坐标为时间窗口的大小,分别为12h、24h、48h、96h。时间窗口越大,意味着输入数据集中故障磁盘SMART数据越多。BPNN方法、决策树和贝叶斯方法在不同的时间窗口条件下,预测率保持相对稳定。其中,BPNN方法的预测率稳定在93%左右,贝叶斯方法的预测率稳定在96%左右,而决策树方法稳定在98%。对于支持向量机方法,随着时间窗口的增大,预测率由67%增加到97.3%。支持向量机方法的预测率对时间窗口大小变化所引发的输入数据集的变化比较敏感,当时间窗口增加大于24h后,预测率的结果趋于稳定。

Figure 1 Prediction rate comparison图1 预测率结果比较
4.2.3 误报率结果比较
误报率刻画了机器学习方法出现错误预测结果的可能性。图2给出了四种方法的误报率结果比较。误报率越低,证明方法的有效性越好。在四种方法中,支持向量机的效果最好,误报率最低值仅有0.05%,最高值也只有0.1%。决策树方法和简单贝叶斯方法的误报率比较稳定,分别稳定在0.3%和0.8%。相比而言,BPNN方法的误报率变化浮动较大,最低值为0.1%,最高值可以到1%。
4.2.4 准确率结果比较
准确率刻画了机器学习方法获得正确预测结果的能力,其值越高,则意味着方法的预测效果越好。图3给出了四种方法的准确率结果比较。从图3中可以看出,四种方法都保持了较高的预测准确率。除了简单贝叶斯方法,另外三种方法大都保持了99%以上的预测准确率。决策树方法的准确率较为稳定。当时间窗口大于24h后,支持向量机方法的预测准确率也稳定在99%以上。相比较而言,贝叶斯方法随着时间窗口的增加,预测准确率有所下降。BPNN方法在时间窗口大小为48h,最高准确率为99.5%;当时间窗口大小为96h,出现了最低准确率为97.4%。这些数据表明,上述四种预测方法具有较高的正确预测能力。
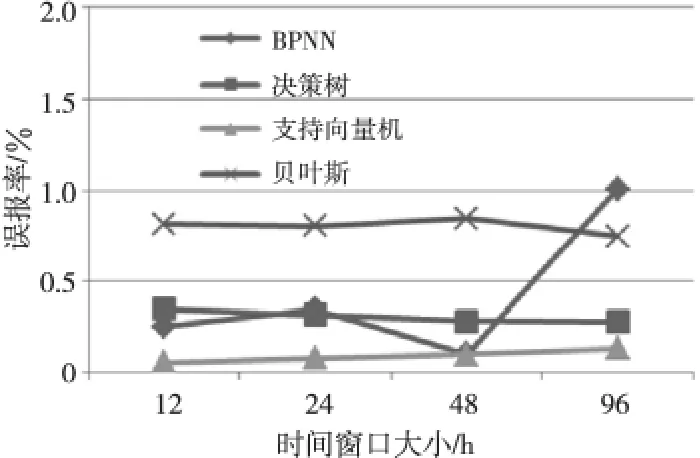
Figure 2 Comparison of false alarm rates图2 误报率结果比较

Figure 3 Comparison of accurate rates图3 准确率结果比较
4.2.5 提前时间比较
提前时间定义了机器学习方法在实际故障出现前,完成故障预测的时间提前量。这个值越大,表明用户有更充足的时间完成数据备份操作,数据的可靠性、可用性也就越高。图4给出了四种方法的提前时间比较。从图4中看出,除了BPNN方法外,其他三种方法都保持了相对稳定的提前时间。其中,支持向量机和贝叶斯方法的提前时间稳定在300h左右,决策树方法的提前时间稳定在290h。随着时间窗口的增加,BPNN方法的提前时间由270h逐步提升到300h。
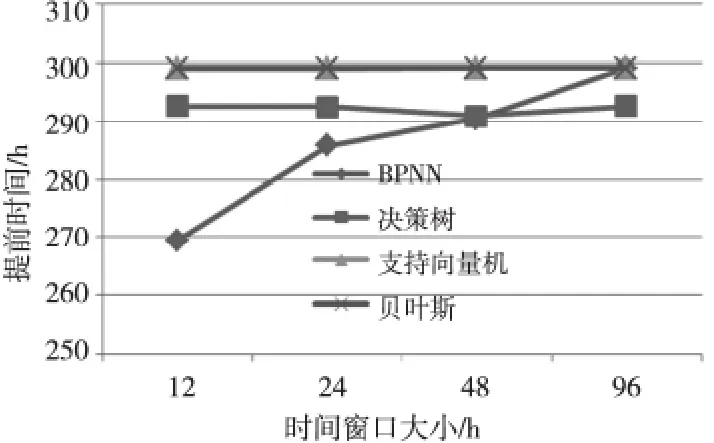
Figure 4 Comparison of the time ahead of schedule图4 提前时间比较
4.2.6 其他结果
除了上述四个指标,我们还对比了四种方法在对测试集进行预测时所需要的时间。图5给出了归一化处理后的时间对比结果。在四种方法中,决策树的预测时间最短,BPNN和简单贝叶斯的预测时间稍长,分别是决策树方法的2.8倍和1.3倍。支持向量机的预测时间最长,是决策树方法的715倍。从时间绝对值看,四种方法的执行时间都是可以接受的。

Figure 5 Comparison of prediction time图5 预测所需时间对比
在前文中,我们给出了训练集的构造方法,并说明,每个正常磁盘选择一条SMART信息,可以改善故障磁盘的SMART信息在整个训练集中的比例,从而改善预测效果。图6a和图6b分别给出了两种不同条件下、四种不同方法的预测率和准确率对比,它们的时间窗口大小均为12h。其中,Train-1表示在构造训练集数据时,每个正常磁盘选取一条SMART信息;Train-2表示构造训练集数据时,每个正常磁盘选取四条SMART信息。
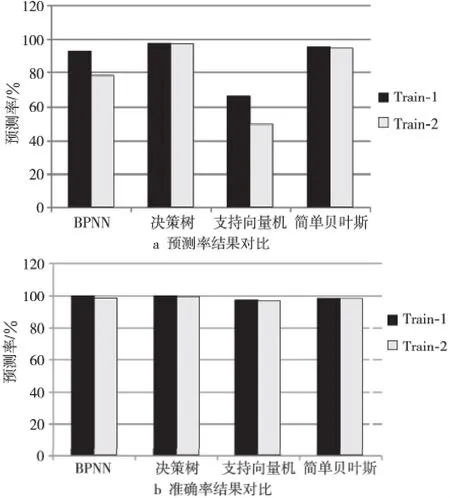
Figure 6 Prediction comparison under different constructions of training sets图6 不同训练集构造方法下的预测结果对比
从图6a可以看出,在两种条件下,决策树和简单贝叶斯方法的预测率没有出现大的变化,但是BPNN和支持向量机方法在选择Train-1时,预测率有明显改善,分别提高了15%和17%。从图6b可以看出,在两种条件下,预测的准确率并没有出现大的变化。
5 结束语
数据是信息系统的核心组成部分。作为保存数据的主要部件,提高磁盘的可靠性对信息系统具有重要意义。SMART数据描述了磁盘的多种属性,是磁盘管理的标准接口。基于SMART数据,采用机器学习方法对磁盘故障进行预测,可以有效预测可能出现的磁盘故障,有利于提高磁盘的可用性,并增强存储系统的可靠性。本文基于LibEDM,采用四种典型的机器学习方法,利用SMART数据,实现对磁盘的故障预测,并使用源自于实际系统的磁盘SMART信息进行故障预测验证。实验结果表明,使用机器学习方法可以有效预测磁盘故障。同时,对不同方法的实验结果进行了对比与分析。
[1] Schroeder B,Gibson G A.Disk failures in the real world:What does an MTTF of 1,000,000hours mean to you?[C]∥Proc of the 5th USENIX Conference on File and Storage Technologies,2007:286-299.
[2] Gobioff H,Ghemawat S T S.The Google file system[C]∥Proc of the 19th ACM Symposium on Operating Systems Principles(SOSP’03),2003:29-43.
[3] Van Renesse R,Schneider F B.Chain replication for supporting high throughout and availability[C]∥Proc of OSDI’04,2004:91-104.
[4] Pinheiro E,Weber W-D,Andr L,et al.Failure trends in a large disk drive population [C]∥Proc of the 5th USENIX Conference on File and Storage Technologies,2007:1.
[5] Murray J F,Hughes G F,Kreutz-Delgado K.Machine learning methods for predicting failures in hard drives:A multipleinstance application [J].Journal of Machine Learning Research,2005,6(1):783-816.
[6] Jiang Yan-huang,Zhao Qiang-li.Machine learning techniques[M].Beijing:Publishing House of Electronics Industry,2009.(in Chinese)
[7] LibEDM[EB/OL]. [2015-03-13].https://github.com/Qiangli-Zhao/LibEDM.
[8] http://pan.baidu.com/share/link?shareid=189977&uk=4278294944.
[9] Hughes G F,Murray J F,Kreutz-Delgado K,et al.Improved disk drive failure warnings[J].IEEE Transactions on Reliability,2002,51(3):350-357.
[10] Wang Yu,Miao Qiang,Ma E W M,et al.Online anomaly detection for hard disk drives based on mahalanobis distance[J].IEEE Transactions on Reliability,2013,62(1):136-145.
[11] Wang Yu,Ma E W M,Tommy W S Chow,et al.A two-step parametric method for failure prediction in hard disk drives[J].IEEE Transactions on Industrial Informatics,2014,10(1):419-430.
[12] Hamerly G,Elkan C.Bayesian approaches to failure prediction for disk drives[C]∥Proc of the 18th International Conference on Machine Learning(ICML),2001:202-209.
[13] Tan Y,Gu X.On predictability of system anomalies in real world[C]∥Proc of the 18th Annual IEEE/ACM International Symposium on Modeling,Analysis Simulation of Computer and Telecommunication System,2010:1.
[14] Zhao Y,Liu X,Gan S,et al.Predicting disk failure with HMM-and HSMM-based approaches[C]∥Proc of the 10th International Conference on Data Mining,2010:390-404.
[15] Murray J F,Hughes G F,Kreutz-Delgado K.Machine learning methods for predicting failures in hard drives:A multiple instance application[J].Journal of Machine Learning Research,2005,6(1):783-816.
[16] Murray J F,Hughes G F,Kreutz-Delgado K.Hard drive failure prediction using non-parametric statistical methods[C]∥Proc of the ICANN/ICONIP,2003:1.
[17] Zhu Bing-peng,Wang Gang,Liu Xiao-guang,et al.Proactive drive failure prediction for large scale storage systems[C]∥Proc of IEEE Conference on Massive Data Storage Systems and Technologies,2013:1-5.
[18] Liu Jing-ning,Rao Guo-lin,Feng Dan.A S.M.A.R.T-based method for keeping RAID data’s high dependability[J].Computer Engineering & Science,2007,29(5):21-23.(in Chinese)
[19] Zhang Chao.Research of self-healing technique on high performance disk array[D].Changsha:Natioanl University of Defense Technology,2008.(in Chinese)
[20] Hu Wei.Research of high reliable disk array technology based on intelligent failure prediction and self-healing[D].Changsha:Natioanl University of Defense Technology,2010.(in Chinese)
附中文参考文献:
[6] 蒋艳凰,赵强利.机器学习方法[M].北京:电子工业出版社,2009.
[18] 刘景宁,饶国林,冯丹.一种基于S.M.A.R.T的保障RAID数据高可靠性的方法[J].计算机工程与科学,2007,29(5):21-23.
[19] 张超.高性能磁盘阵列自修复技术研究[D].长沙:国防科学技术大学,2008.
[20] 胡维.基于智能预警和自修复的高可靠磁盘阵列关键技术研究[D].长沙:国防科学技术大学,2010.
猜你喜欢
电脑爱好者(2019年2期)2019-10-30
成都信息工程大学学报(2019年3期)2019-09-25
网络安全和信息化(2018年2期)2018-11-09
电子制作(2018年16期)2018-09-26
数理化解题研究(2017年4期)2017-05-04
网络安全和信息化(2017年3期)2017-03-10
网络安全和信息化(2016年8期)2016-11-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
铁道通信信号(2016年6期)2016-06-01
电子器件(2015年5期)2015-12-29
