
现阶段我国DNA数据库发展的几个关键问题
2015-08-26 10:09:00刘冰
刑事技术 2015年4期
刘 冰
(公安部物证鉴定中心,北京 100038)
现阶段我国DNA数据库发展的几个关键问题
刘 冰
(公安部物证鉴定中心,北京 100038)
经过15年发展,我国DNA数据库集聚了3000万以上的STR数据,在超过100万起案件中发挥了作用。随着Y-STR、SNP等新遗传标记被引入法庭科学领域,对DNA数据库的应用已不仅仅满足于传统的直接匹配和简单亲缘关系检索。现阶段我国DNA数据库究竟该向何处发展,文章认为:(1)关于增加DNA数据库支持基因座数量的必要性已在法医遗传学领域达成共识,但常染色体STR基因座数量的增加必须以确定核心基因座为前提。(2)对于SNP等新型遗传标记的采用,DNA数据库应本着“善意期待”和“审慎观望”的态度,在数据库已经进入千万级容量的今天,采用SNP的可能性已经极低,未来能够对DNA数据库带来变革的,很可能是全基因组DNA测序。(3)复杂亲缘关系检索是DNA数据库人口覆盖率不足情况下的合理补充和必然选择,但应遵循严格的规则。(4)在没有通过严谨演绎推理构建起理论框架,特别是结果评价的数学模型之前,Y-STR数据库的应用还只是经验的而不是科学的。综上,作为千万级大容量DNA数据库,涉及发展方向、安全、稳定的根本性问题要慎重从事,用科学的方法思考、规划和推动工作的进行。
法医遗传学;DNA数据库;Y-STR数据库;核心基因座;SNP;个体识别;亲缘关系检索
DNA数据库(DNA database),是将分子遗传学技术、计算机网络信息传递技术和数据库管理技术相结合的,实现DNA信息数字化组织、存储、管理和检索的系统。目前,最为人们熟知的DNA数据库多为DNA序列数据库,如欧洲生物信息学研究所(European Bioinformatics Institute,EBI)的EMBLDNA数据库、美国国家生物技术信息中心(National Center for Biotechnology Information,NCBI)的GenBank、日本的DDBJ(DNA Data Bank of Japan)等,其数据信息主要来源于科研人员或大规模基因组测序计划,实现全球科学研究领域的资源共享。本文谈及的DNA数据库,特指法庭科学DNA数据库(Forensic DNA database),也可称作犯罪DNA数据库(Crime DNA database),主要用于为侦查破案、执法办案、诉讼活动、公共安全和社会管理提供DNA数据服务。
自90年代中期公安部提出“统一规划、统一标准、分步实施、滚动发展”的DNA数据库建设原则开始,从科学研究到实际应用,从区域性建设到全国性部署,我国的DNA数据库已有15年的历史[1-9]。10余年来,DNA数据库集聚了3000万以上的各类样本的短串联重复序列(short tandem repeat,STR)数据,在超过100万起的案件中发挥了作用,已经初步实现了跨时空多元化应用的建设目标,在精确打击犯罪中发挥了显著成效。近年来,Y染色体STR(Y-STR)、单核苷酸多态性(single nucleotide polymorphisms,SNP)、单细胞检验、高通量核酸测序等新的生物学技术不断被引入法庭科学领域,实践中对DNA数据库的应用也不仅满足于传统的基于直接匹配的个体识别和简单亲缘关系检索(指“父母-子女”三联体关系的检索)。那么现阶段我国DNA数据库究竟该向何处发展,是一个重要问题。本文试图从常染色体STR基因座的选择,新遗传标记与DNA数据库的关系,复杂亲缘关系检索以及Y-STR数据库建设等几个方面探讨千万级大容量DNA数据库建设应用中的关键问题,以期为今后我国DNA数据库的科学发展和应用提供参考和帮助。
1 常染色体STR基因座的合理选择
现阶段关于增加DNA数据库支持基因座数量的必要性,在法医遗传学领域已达成共识。DNA数据库常染色体STR基因座数量增加必须以确定核心基因座为前提。我国现有DNA数据库系统只支持24 个STR基因座,这既有技术和历史的局限,也有出于数据库比对效率的考量。因此问题的关键是如何权衡基因座数量与数据库比对效率间的关系。一方面,随着DNA数据库数据总量不断扩大,数据库基于直接匹配(direct match)的个体识别中出现无关个体随机匹配(random match)的可能性大大增加,亲缘关系检索的识别能力会大幅度降低[10],随着数据库容量的增长,增加基因座数量是必然趋势;另一方面,数据库比对算法、数据库间数据共享能力又要求样本间的基因座选择尽量的趋同。理想的状况是,数据库选取规定了一组足够多的基因座组合后,所有入库样本数据遵循这一规定。由于技术、历史、商业等诸多因素这一理想状态无法达成。但是确定核心基因座是DNA数据库健康发展的必然选择,英国、美国、欧洲就是研究制定核心基因座的先行者和受益者。
上世纪90年代,英国法庭科学服务部(Forensic Science Service,FSS)在世界上最先确定了第一代核心STR基因座(first generation multiplex,FGM),1994年发展了第二代核心STR基因座(second generation multiplex,SGM),1998年又研究确定了第三代核心STR基因座(third generation multiplex,TGM)与SGM配合使用,将个人识别能力提高到100亿分之一。1996年,FBI开展了一项为期18个月的专项研究,为美国联合DNA索引系统(Combined DNA Index System,CODIS)筛选核心STR基因座,22个DNA实验室共同参与此项研究。在对17个候选STR基因座进行比较测试后,1997年,正式确定了13个常染色体STR基因座为CODIS核心STR基因座,同时建立了一系列的测试方法、评估标准和基础人员信息数据库。德国国家DNA数据库建设起步于1998年,确定了8个常染色体STR基因座和1个性别基因座作为其核心STR基因座。此后,为加强与欧洲各国的在案件协查、失踪人口调查、DVI等方面的合作,英国与欧洲主要国家又将D2S1338、D19S433、FGA、TH01、VWA、D3S1358、D8S1179、D16S539、D18S51和D21S11等10个常染色体STR基因座确定为共有的核心STR基因座,以利于相互间的数据交换共享。近年,为有利于世界各国的国际合作和DNA数据交换,国际刑警组织也建立了DNA数据库,该 库 选 用 FGA、TH01、VWA、D3S1358、D8S1179、D18S51、D21S11等7个常染色体STR基因座作为其核心STR基因座。英、美、德等国核心STR基因座在其国家DNA数据库的建设中起到了重要的基础性作用,使国家DNA数据库在建设之初就走入规范化、科学化轨道。同时,核心STR基因座的确定也很好的引导了DNA检验试剂市场的发展,DNA检验试剂研发生产处于有序发展、良性竞争的轨道,用户、厂商双方得益。
我国至今尚未开展此项工作。由于缺乏引导,各类常染色体STR检验试剂产品研发处于无序状况:在可检测基因座大幅度增加的同时,DNA数据库中样本共有常染色体STR基因座不增反降,由最初的13个降为不足11个(见表1),制约了DNA数据库在法庭科学领域的应用效能和发展、应用前景。应该看到,核心基因座的确定不单纯是一个技术性行为,需要考虑多方面因素,多方面参与,国外的经验也是如此。在诸多因素中,兼容性,特别是向下兼容是首先需要考虑的。随着新一版DNA数据库系统软件的应用,科学选择,合理调整,尽快确定中国人群常染色体核心STR基因座,出台配套标准规范,将DNA检验试剂的研发纳入科学有序的轨道,已经成为我国社会公共安全领域重要的基础性研究内容,具有关键的战略意义,这一项工作迫在眉睫。
2 新遗传标记与DNA数据库的关系
近年来,SNP、DNA芯片以及新一代核酸测序技术俨然成为法医遗传学的热点,特别是SNP,被认为是新一代遗传标记且终将取代STR。但对于新型遗传标记的采用,DNA数据库应本着“善意期待”和“审慎观望”的态度。事实上,DNA数据库[8]、常染色体STR检测试剂[11,12]、DNA芯片及SNP检测技术[13,14]在2001年均被列为国家“十五”科技攻关课题。10余年来,基于常染色体STR检测,我国已建成全世界最大的DNA数据库,而SNP检测技术作为热点反复被提及却仍未在法医遗传学领域形成大规模成熟应用,这一现象值得思考。一类遗传标记能否被DNA数据库采用,取决于诸多因素:对于遗传标记,(1)其技术解决方案必须成熟完整,涵盖检测平台、检测试剂、分析软件等因素,相关产品必须进入商业化生产阶段;(2)其常用标记选定、数据分析解读方式必须在业界达成共识,检测结果能够在实验室间通行使用;(3)其检测结果具有很高的实用价值,即普通技术人员可以用其来解决实际问题;(4)其检测成本能够为多数实验室接受。对于DNA数据库,(1)要考虑已有数据的价值保护;(2)要衡量引入新遗传标记带来的收益和数据迭代成本间的关系。英国、美国国家DNA数据库建设最初,所应用的DNA分型技术是单位点探针指纹图技术(single locus probe,SPL),当STR检测技术出现后,SPL技术很快被替代是因为:(1)STR检测技术方案成熟,商业化程度高;(2)STR检测应用规范,结果数字化程度高(国际法医遗传学会、FBI的DNA分析方法科学工作组制定了大量相关指导性文件[15]);(3)已有数据库数据规模还不大,技术迭代成本不高;(4)STR相对于SPL技术优势明显。
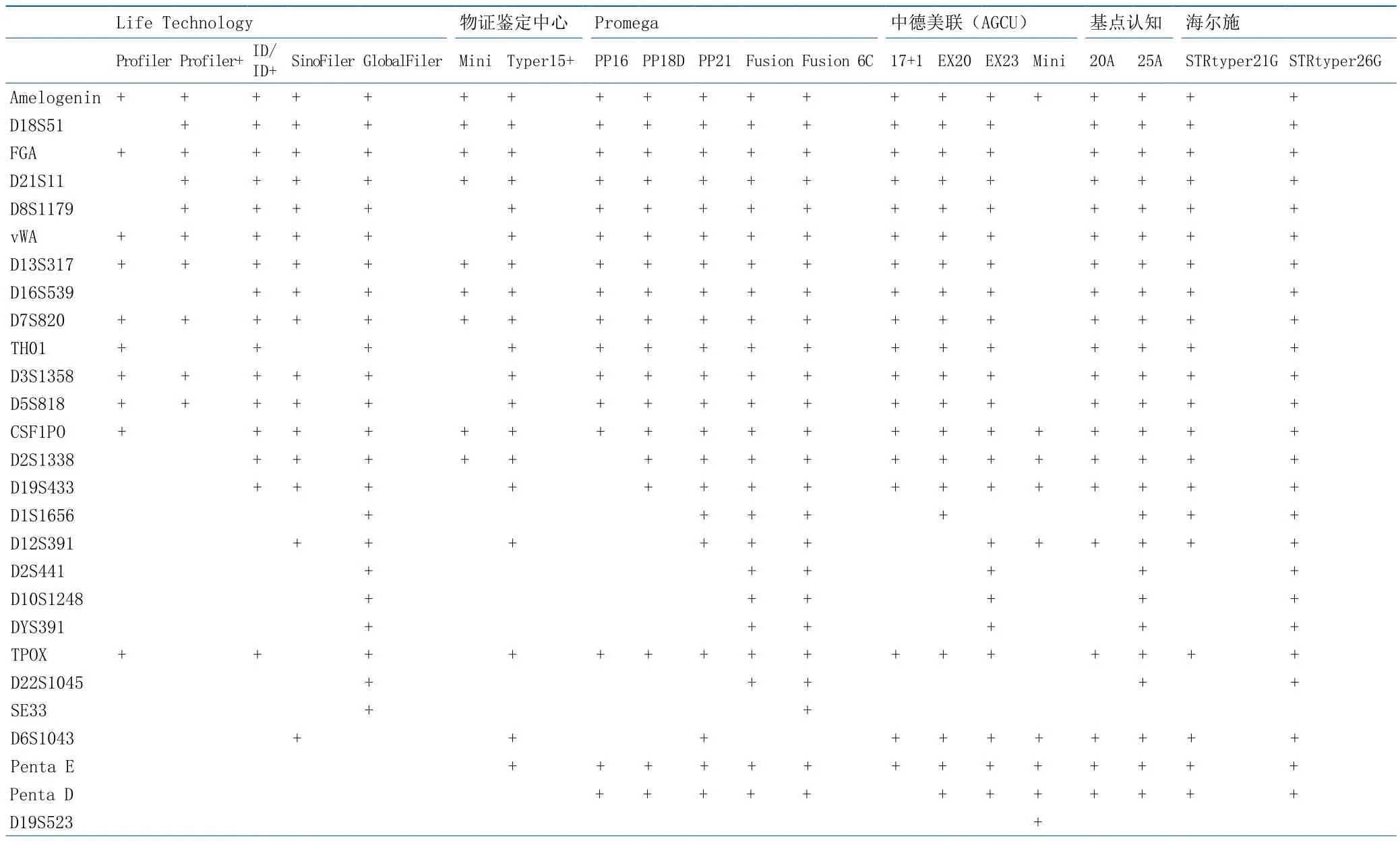
表1 国内部分常见常染色体STR检验试剂产品Table1 Common autosomal STR kits in Chinese market
应该看到,无论是英国、美国还是我国DNA数据库,目前的情况与STR取代SPL技术时有显著不同:(1)由于数据库容量巨大,法医遗传学检测对STR检测技术已经形成“路径依赖”,这种依赖总体上看还处于良性循环的轨道,即随着数据库规模扩大,使用者的受益也在不断放大;(2)规模化后的DNA数据库对于变革呈天然的保守姿态,且数据规模越大,保守性越强烈,无论是从系统安全性还是数据价值保护,使用新遗传标记带来的益处相对于风险和代价来说微不足道;(3)SNP等新的遗传标记对于STR的优势尚未达到STR相对于SPL那样的显著。以我国DNA数据库为例,如果采用SNP技术,(1)结果不能兼容现有千万级STR数据,无法形成规模化效益;(2)尚没有一套成熟的商业化检测方案形成主导,不同的解决方案间数据无法兼容;(3)在个体识别、亲缘关系检索中SNP对于STR的优势没有显著到必须取而代之的地步;(4)SNP在表观遗传学、群体遗传学领域的应用还未进入成熟实用阶段;(5)也是最重要的,现有数据价值仅以经济价值衡量已近人民币十亿级,迭代成本无法承受。因此,如果在15年前DNA数据库技术起步,5年前数据库进入高速增长的节点SNP技术没有被引入的话,在数据库已经计入千万级容量的今天,采用SNP技术的可能性已经极低。而未来能够对DNA数据库带来变革的,很可能是全基因组DNA测序。
3 从数据特性看复杂亲缘关系检索
DNA数据库的主要优势和用途在于人的个体识别。目前,采用的个体识别方式包括完全匹配和亲缘关系检索,其中完全匹配是主要的应用方式。从应用模式看(见图1),在使用完全匹配方式时,DNA数据库较其他生物识别(如指纹、人脸、声纹等)数据库有着不同的特点:在由专业人员完成数据提取(即检验结果的分析)后,由于STR检测数字化程度高,结果清楚明了(一般为呈两组数字一对一的形式),非技术人员经简单培训也可使用。这与其他生物识别数据库恰恰相反。从数字分析来看,完全匹配是用户的主要使用模式(见表2)。
既然如此,为什么DNA数据库还要设定亲缘关系检索模式?从数据特性来看,DNA数据库数据已基本具有大数据的三个特性,即规模性(volume)、多样性(variety)和高速性(velocity)。其中,数据的规模性(volume)包含两个涵意:数据的绝对数量和对样本空间的覆盖程度。一般来说,数据对样本空间的覆盖程度与运算模型的复杂程度呈反比。当数据量大到覆盖整个样本空间时,对于样本的推断,不再强烈依赖于模型的比对。极端而简单的例子就是,当建立全民DNA数据库后,只使用完全匹配方式就可实现精确的个体识别(同卵双生和骨髓移植等特殊情况除外)。因此不难理解,由于人口覆盖率问题,现阶段亲缘关系检索模式还是DNA数据库个体识别一个必不可少的补充。从比对模式复杂度的角度,亲缘关系检索模式可以分为“简单”和“复杂”两种,前者主要指“父母-子女”三联体以及单亲遗传关系的检索;后者狭义上指同胞关系检索,广义上还包括“祖-孙”、父系以及母系等亲缘关系的检索。在使用遗传标记上,复杂亲缘关系检索模式已不仅仅局限于常染色体STR,还包括Y-STR和线粒体DNA。

图1 生物特征数据库的应用模式Fig.1 Applifcation pattern of biometric database
虽然使用DNA数据库进行复杂亲缘关系检索早就有尝试并有成功的案例,如英国的Craig Harman案、Jeffery Gafoor案和美国的Grim Sleeper案等,但DNA数据库应用领域对待这一方式始终持谨慎、保守的态度。这是由于:(1)条件苛刻,需要有高的前置概率和附加检索条件;(2)假阳性(false positives)和假阴性(false negatives)率高,结果指向性很差;(3)结果的筛查需要大量的调查工作;(4)存在道德诸如隐私权方面的争议。如在美国,根据联邦法律,FBI被禁止在CODIS中开展亲缘关系查询;仅加利福尼亚州、科罗拉多州、得克萨斯州、弗吉尼亚州4个州允许使用亲缘关系查询,而马里兰州、哥伦比亚特区则禁止利用DNA数据库进行亲缘关系检索。在我国,复杂亲缘关系检索的需求逐年增长,但是实际上复杂亲缘关系检索并不适用于我国,这是因为:(1)此类检索适用于封闭的小区域,低流动性人群,我国DNA数据库中多数数据来自于流动人口;(2)此类检索对于基因座数量有较高要求,目前DNA数据库中基因座数量偏低,特别是共有基因座数仅有11个。尽管如此,开展复杂亲缘关系检索是我国DNA数据库应用在一个较长时期内的合理补充和必然选择,原因客观上是需求推动,主观上是实现数据库效益的最大化。但此项业务的展开应遵循严格的规则,技术上:(1)源样本必须来自单一个体(或分型可被准确区分),每个基因座不超过两个等位基因;(2)非混合样本;(3)DNA分型无误,无等位基因丢失,无错判。程序上:(1)只限于最重大案件;(2)已无其它的线索和信息供案件调查使用;(3)用于比对的现场物证经分析确定来源于犯罪嫌疑人;(4)对于嫌疑人来源的地区要有严格的预判;(5)必须有其他非DNA信息作为辅助筛选的因素。

表2 我国DNA数据库两种比对结果的比较(2010~2014)Table2 Comparison of 2 kinds of results analysed in China national DNA database(2010~2014)
4 Y-STR数据库建设涉及的关键问题
数据库的复杂亲缘关系检索中,存在一类特殊的类型即单倍型(haplotype)检索,主要指应用Y-STR和线粒体DNA进行的父系和母系遗传关系检索。这类特殊遗传关系的特点是遗传规律清晰,在隔代和远亲属的亲缘关系判断中有优势;缺点是需要建立专门数据库,数据研判中要特殊考量突变的因素,必须与其他方法结合使用才能达到个体识别。如前所述,由于DNA人口覆盖率低,DNA现有的完全匹配和亲缘关系检索不能完全满足侦查破案的现实需求,近年来Y-STR数据库的建设被越来越多的地方提上日程并付诸实施。客观的说,Y-STR数据库的建设确有其迫切性。家系资料的搜集是Y-STR数据库建立的必要条件。在我国完整的多代家系基本只存在于农村。据统计,在1990年到2010年的20年时间里,我国的行政村数量由于城镇化和村庄兼并等原因,从100多万个锐减到64万多个,每年减少1.8万个村落,每天减少约50个[16]。因此,随着村落的消亡,Y-STR数据库建立的基础也将逐渐消失。但是,Y-STR数据库的特殊性所带来的问题也必须引起关注。
4.1 人员样品采集可能涉及法律、社会等诸多问题
DNA数据库的样本的采集,立法先行是国外的惯例。英国1984年制定的《警察与刑事证据法》,1994年的《刑事审判与公共秩序法》,1995年的《样本提取条例》,为英国国家DNA数据库的样品采集提供了法律依据。美国国会1994年通过的《联邦DNA鉴定法》,授权FBI建立国家DNA数据库;自1989年起,各州又先后通过了相关立法。我国关于DNA数据库没有专门立法,关于数据库中人员样品的采集目前往往援引《中华人民共和国刑事诉讼法》(2012 年3月14日第二次修正)第一百三十条的规定。但是,Y-STR数据库人员样品采集的特点是:(1)地理空间相对封闭;(2)涉及人员范围广;(3)需同时搜集家系资料;(4)被采集人多数不在第一百三十条的规定覆盖范围。上述特点决定,样品采集的过程必然产生社会影响,在公民法制意识日益增强的当今社会,DNA数据库的法律支持问题日益引起关注[17,18],稍有措施方式不当极易形成社会不稳定因素。
4.2 社会学意义家系不等同于遗传学意义家系
家系是Y-STR数据库数据组织的骨架,也是检索结果转化应用的路径。这里的家系指的是遗传学意义的家系,即客观反应血亲关系的家系。通过走访采集到的家系,可以称之为社会学意义上的家系,反应的是现有社会组织框架下家庭单位内部以及之间成员的表象关系。人们心目中常识性的认为Y-STR可作为姓氏基因帮助寻根问祖,是建立在二者吻合的前提下。从大量现实情况来看,由于非婚生、领养等现象的存在,二者目前往往不能等同。某一男性是否为其父的亲生子,事实往往由生母掌握(有时甚至生母也不能掌握),通过走访或资料采集完全无法获得。也就意味着,在初始阶段,作为Y-STR数据库基础的家系信息在可信度上就存在巨大不确定性,这一缺陷即使后期通过技术也是很难修正的。因此由此造成的结果误导也是不可预知的,甚至可以激进的认为Y-STR的应用带有很强的博弈属性。
4.3 对Y-STR数据库的评价更多是经验而非科学的
演绎推理的逻辑形式对于理性的重要意义在于,它对人的思维保持严密性、一贯性,有着不可替代的校正作用。因此Y-STR应用的科学性必须通过演绎推理来证实。但目前,国内关于Y-STR数据库应用的效果评价多基于归纳推理,且基本上均采用不完全归纳推理的方式,或通过成功的案例来证明Y-STR数据库应用的价值,或通过局部的数据分析来引导出断言式结论。这其中存在两个问题:(1)对归纳推理而言真实的前提未必会导出真实的结论,大卫·休谟说过:“运用归纳法的正当性永远不可能从理性上被证明”;(2)出于趋利原则,此类文章中很少存在不利的反证。实际上,现阶段Y-STR的应用带有显著的不可证伪性(两个个体Y-STR分型相同不能得出来自同一家系的必然结论,分型不同也不能得出必然否定的结论),其科学性无法成立。因此,在没有通过严谨的演绎推理构建起Y-STR数据库的理论框架,特别是结果评价的数学模型之前,它的应用还只是经验的而不是科学的,而且很难确定这种经验对于他人是否具有实际价值。
4.4 家系信息的搜集、存储和使用存在风险隐患
对于存储常染色体STR的DNA数据库,因基因座仅存在于DNA的非编码区域,不包含类似遗传学易患病体质的医学信息,并不如一些观点[17-19]所担心的那样会涉及触及个体的遗传学隐私。但Y-STR数据库中涉及到的家系信息则完全属于隐私范畴,特别如上文提及的非婚生现象,如果泄露将对地方的社会、家庭关系产生巨大的冲击。Y-STR数据库建立涉及环节、人员众多,从搜集、整理、存储、应用,主观故意和客观疏忽均可能导致泄露、误用和滥用等。河南省在Y-STR数据库建设中就对这一问题进行了严肃的思考并进行了有益的尝试[20]。
4.5 数据库均衡发展要综合考虑成本与效益问题
建设Y-STR数据库的目的是弥补现阶段DNA数据库人口覆盖率不足短板,不能舍本逐末。一个地方在常规DNA数据库数量未达到规模效益点,增长进入良性循环的时候,规模性的启动Y-STR数据库建设,其成本和效益的综合比是很低的。这是由于:(1)应用范围不同,Y-STR数据库应用以农村等低人口流动地区为主,常染色体STR适用于所有地区和人群;(2)经济成本不同,目前单个样本检验成本Y-STR约是常染色体STR的2倍;(3)Y-STR数据库可以解决本人、近亲属不在时的比对问题,但这些问题随着常染色体STR数据库人口覆盖率提升可以大幅度缓解;(4)Y-STR数据库前期建设的人力投入和后期应用的侦查成本远远高于常染色体STR。
从近年来各国特别是我国法庭科学DNA数据库建设应用的实际上看,一方面,对DNA数据库的功能要求呈现多警种、多部门、多角度、多领域以及综合化、复杂化的趋势,DNA数据库除服务于刑事侦查工作外,在其他警种和处置重大公共安全事件和重大灾害事故中有着越来越广泛的应用。另一方面,对DNA数据库信息进行深度挖掘,综合应用复杂亲缘关系比对(包括单亲、双亲、兄弟、姐妹等)和案(事)件、人员背景等非遗传信息,为疑难案件提供侦破线索已成为DNA检验技术和DNA数据库应用的一个新的热点和重点。由此看来,随着技术发展和实践的深入,DNA数据库在打击犯罪、公安社会管理创新、国家安全、公共安全、灾难事故处置、医疗卫生、经济、军事等各个领域还将发挥更突出的作用。但越是如此,对于DNA数据库的建设越要慎重从事,特别是涉及发展方向、安全、稳定的根本性问题,应以科学的方法来思考、规划和推动工作的进行。
[1] 张国臣,刘冰,陈松,等.实验性犯罪数据库的设计 [J].刑事技术,2000(1):44-45.
[2] 杜志淳,李莉,林源,等.中国“罪犯DNA数据库”STR基因座研究 [J].中国法医学杂志,2000,15(2):65-68.
[3] 李莉,柳燕,林源,等.国内外“DNA数据库”遗传学标志的比较研究 [J].中国司法鉴定,2001(2):25-27.
[4] 胡兰,陈松,张国臣.国家法庭科学DNA数据库建设势在必行 [J].刑事技术,2003(6):3-5.
[5] 焦章平,唐晖,刘雅诚,等.建立法医DNA数据库的初步探讨 [J].中国法医学杂志,2003,18(1):58-59.
[6] 姜先华,李军,刘峰.法庭科学DNA数据库的建设和应用 [J].中国法医学杂志,2004,19(1):61-62.
[7] 侯一平,王保捷,丛斌,等.中国法医学会物证专业委员会法医DNA分析的若干建议 [J].中国法医学杂志,2006,21(5):257-259.
[8] 姜先华.中国法庭科学DNA数据库 [J].中国法医学杂志,2006,21(5):260-262.
[9] 刘冰.基于数据库数据分析的DNA证据作用评价 [J].刑事技术,2015,40(3):199-203.
[10] 葛建业,严江伟,Budowle B,等.关于法庭科学DNA数据库若干问题的探讨 [J].中国法医学杂志,2011,26(3):252-255.
[11] 李红.DNA检验试剂有望国产化 [N].科技日报,2004-12-06.
[12] 王莉莉,苏雪峰.国产DNA试剂盒:实现从无到有的突破.创新学习的新思路 [N].人民公安报,2010-02-01(7).
[13] 朱淳良.国家十五重点科技攻关项目“法医学DNA芯片技术研究”课题通过专家验收 [J].中国司法鉴定,2014(3):60.
[14] 朱淳良,周云飞.解读“生命天书”的攻坚战——攻克“法医学DNA芯片技术研究”课题专访 [J].中国司法鉴定,2014(4):58-60.
[15] 刘烁,刘冰,王彦斌,等.国外法庭科学DNA实验室的质量保证和质量控制现状 [J].刑事技术,2013(3):3-8.
[16] 李培林.从“农民的终结”到“村落的终结”[J].传承,2012(15):84-85.
[17] 瓮怡洁.法庭科学DNA数据库的风险与法律规制 [J].环球法律评论,2012(3):37-53.
[18] 陈学权.刑事程序法视野中的法庭科学DNA数据库 [J].中国刑事法杂志,2007(6):52-61.
[19] 邱格屏.刑事DNA数据库的基因隐私权分析 [J].法学评论,2008,23(2):37-43.
[20] 杨玉章.Y-STR DNA数据库建设及应用 [J].河南警察学院学报,2013,22(5):47-53.
引用本文格式:刘冰.现阶段我国DNA数据库发展的几个关键问题 [J].刑事技术, 2015,40(4):318-323.
Several Key Issues for China National DNA Database Development
LIU Bing
(Institute of Forensic Science, Ministry of Public Security, Beijing 100038, China)
ABATRACT: China national DNA database has a history of 15 years and has kept more than 30 million short tandem repeat (STR) profles, generating over 1.5 million matches assisting in more than 1 million investigations.In recent years, Y chromosome STR (Y-STR), single nucleotide polymorphism (SNP), single cell testing, and high throughput DNA sequencing technology have been continuously introduced in forensic science.Currently, the DNA database could only allow the traditional direct match and simple mode of familial searching for personal identifcation, far behind the high-tech assays which is expected.How to utilize these new technologies to develop new stratedgies for China national DNA database? How to further develop China DNA database and maximize its effciency? This paper discusses the development in the light of 4 issues.First of all, the core loci of database need to be set prior to increasing the number of autosomal STR loci, even though there is a consensus on the quantity change.As for the new genetic markers, such as SNP, the attitude of “good will of expectation” should be in line with “prudent wait-and-see”, since there is few possibility to use SNP commonly in a database with ten-million profles.It is more likely that the genome-wide analysis will bring the great change to the DNA database in the future.Still, the special familial searching is a supplementation and inevitable choice for DNA database in case of a low coverage of the population.But this searching has to follow strict rule.Finally, Y-STR database development is objective and urgent, but it must be cautious as personnel sample collection might be involving legal, social and other problems; the pedigree in sociological term may not equal to genetic one; positive evaluations of Y-STR database should be also built on deductive method; a balanced development of database should be considered of both costs and benefts.Therefore, without a theoretical framework constructed with rigorous deduction, especially prior to the mathematical model of evaluation, Y-STR database is only a matter of empirical, rather than scientifc, letting alone the diffculty to assess the value of such experience for others.In conclusion, as a DNA database with ten-millions profles, any change related to fundamental issues concerned with development, security or stability must be dealt with comprehensively and scientifcally.
forensic genetics; DNA database; Y-STR database; core loci; SNP; personal identifcation; familial searching
DF795.2
B
1008-3650(2015)04-0318-06
10.16467/j.1008-3650.2015.04.015
中央级公益性科研院所基本科研业务费项目(No.2013JB019)
刘 冰(1974—),男,黑龙江齐齐哈尔人,副主任法医师,研究方向为法医遗传学。 E-mail: liubing@cifs.gov.cn
2015-05-20
猜你喜欢
作物学报(2022年2期)2022-11-06 12:11:02
中国现代中药(2021年9期)2021-11-16 07:43:32
科学之谜(2019年3期)2019-03-28 10:29:44
天然产物研究与开发(2018年10期)2018-11-06 07:43:46
科学之谜(2018年8期)2018-09-29 11:06:46
广东农业科学(2017年5期)2017-08-29 10:37:26
恋爱婚姻家庭·养生版(2016年9期)2016-09-07 11:25:01
法医学杂志(2015年4期)2016-01-06 12:36:40
法医学杂志(2015年4期)2016-01-06 12:36:38
食管疾病(2015年3期)2015-12-05 01:45:11
