
基于SVM和KNN的文本分类研究
2015-08-17 05:30:14张华鑫庞建刚
现代情报 2015年5期
张华鑫 庞建刚
(西南科技大学经济管理学院 ,四川 绵阳621000)
基于SVM和KNN的文本分类研究
张华鑫庞建刚
(西南科技大学经济管理学院 ,四川 绵阳621000)
本文在详细介绍文本自动分类流程的基础上 ,通过实验对SVM和KNN两种算法进行比较研究,实验结果表明 :SVM算法使用多项式核函数的分类准确性高于使用径向基核函数的分类准确性 ,且多项式核函数的分类准确性随着参数q的增大而提高;SVM采用多项式核函数进行分类的准确性普遍高于采用KNN的分类准确性;采用多项式核函数的SVM和KNN两种算法对短文本的召回率高于对长文本的召回率。
文本分类 ;KNN;支持向量机 ;核函数
将文本信息进行分类能够满足人们在海量数据中查找数据的需求,但是随着网络技术的高速发展与广泛应用,电子文本信息呈级数增长,用人工方式对文本进行分类将是一项繁重的工作,因此需要借助计算机对文本进行自动分类。20世纪50年代末,H.P.Lunhn首次在该领域提出将词频统计思想用于文本自动分类的研究。20世纪90年代以后,研究者将机器学习算法用于文本自动分类,主要的机器学习算法有决策树 (Decision Tree)、Rocchio算法、KNN算法和支持向量机 (Support Vector Machine,SVM)等。钱庆等[1]将KNN算法应用于医药卫生体制改革舆情监测系统中,构建了医药卫生体制改革主体模型,利用该模型能够有效提高医药卫生体制改革舆情监测系统主题信息自动获取、自动分类的效率,但是该模型在进行特征加权的时候采用的是TF-IDF方法,该方法的缺点在于低估了在一个类中频繁出现的词条,这样的词条能够代表这个类的文本特征的,应该赋予其较高的权重而不是与其他词语同等对待。牛强等[2]在Web文本分类中引入KNN算法,利用 χ2统计量作为特征选择评分函数,尽管该方法能够取得不错的分类效果 ,在一定程度上满足Web知识的需求,但是该方法在对类别差异不大的类别的识别能力较弱。张爱丽等[3]利用SVM算法构造多类别的识别器,该分类器能较好地把大类别分类问题,有效地转化为小类别识别问题的组合 ,降低错误识别率。上述研究都侧重于单一使用KNN算法或SVM算法 ,没有对两种算法进行横向比较 ,本文着重通过实验比较KNN和SVM两种算法在中文文本分类中的性能差异。
1 文本预处理
1.1中文分词
由于中文句子的词与词之间没有空格,因此在进行文本分类的时候首先需要把句子分割成词语。现有的中文分词算法主要分为四大类:基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词方法和基于语义的分词方法。
1.2文本表示
文本信息是非结构化数据,因此需要用数学模型把文本数据表示为计算机能够处理的形式。常用的文本表示模型有布尔逻辑、概率模型 ,向量空间模型。其中向量空间模型是应用较多且效果很好的模型。本文采用向量空间模型表示文本。向量空间模型的基本思想是将文本 di映射为空间中的一个特征向量V(di),V(di)={(ti1,wi1),(ti2,wi2),…,(tin,win)},其中 tik为文档di第k个特征项 ,wik为文档di第k个特征项对应的权重。本文采用TF-IDF方法作为特征加权的方法。TF-IDF方法的基本思想是:如果一个特征在特定的文本中出现的频率越高,说明它区分该文本内容属性的能力越强;如果一个特征在文本中出现的范围越广,即该特征等概率出现在各个类别中,说明该特征区分内容属性的能力越低。
TF-IDF权重计算公式如下:
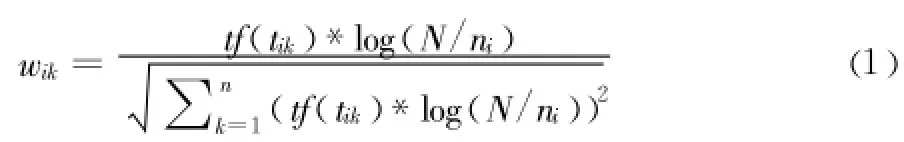
其中 ,tf(tik)表示特征项 tik出现在文档di中的频数 ,N为文本总数,ni为训练集中出现tik的文档数。
但是该方法的缺陷在于如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,以此区别与其它类文档。本研究在计算特征项的时候引入条件概率 ,改进后TF-IDF公式如下:表示文档 d中出现特征项tik时该文档属于Ci的概率,从改进的公式可以看出如果某一个类 Ci中包含词条tik的文档数量大,而在其它类中包含词条 t的文档数量小的话,则 tik能够代表Ci类的特征,该公式赋予该特征较高的权重。
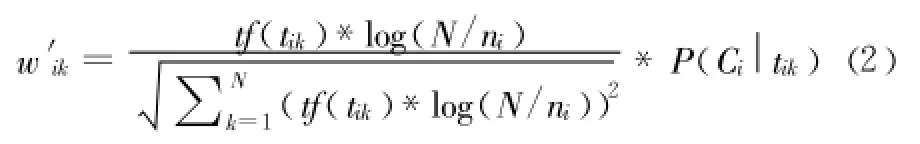
2 特征降维
一篇文档进行分词之后,特征项的维数一般在几万维以上,而大多数的特征项是冗余的或者不相关的,如何在保持分类准确率变化不大的前提下降低特征维数是文本分类研究的一个重点领域。常用的特征选择算法包括交互信息、χ2统计量、文档频率、几率比、信息增益、期望交叉熵等。
信息增益是一种有效的特征算法。Wang Bin等[4]通过实验比较了几率比、文档频率、信息增益3种特征选择算法 ,结果表明信息增益相比前两种算法能够提取最优特征子集。本文实验采用信息增益作为特征选择方法,现将信息增益定义如下:
定义1:信息增益 (IG,Information Gain)是某一特征在文本中出现前后的信息熵之差。计算公式如下所示:
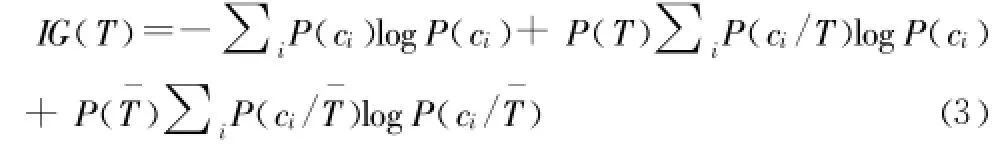
定义中 i表示类别总数,P(ci)表示类别 ci在所有文档中出现的概率,P(T)表示特征 T在文档中出现的概率,P(ci/T)表示当文档中包含特征 T时属于类别ci的概率,P(¯T)表示文档中不包含 T时的概率,P(ci/¯T)表示文档中不包含特征 T时属于类别ci的概率。
在进行特征选择时,一般设置一个阈值,剔除信息增益 (IG)的值小于阈值的特征项,保留大于阈值的特征值作为特征项。代六玲等[5]通过实验表明在保持准确率变化很小的前提下可以保留原始特征空间维数的10%~20% ,剔除80%~90%的特征项。
3 文本分类算法
3.1支持向量机
支持向量机 (Support Vector Machine,SVM)是Vapnik 于20世纪90年代提出一种基于统计学习理论的分类算法。因为SVM算法是建立在统计学习理论VC维理论和结构风险最小化原理基础上的一种新机器学习方法 ,该算法在解决小样本、非线性和高维模式识别问题中表现出许多特有的优势 ,并在很大程度上克服了 “维数灾难”和 “过学习”等问题,1998年,Joachims率先将Vapnik提出的支持向量机 (Support Vector Machine,SVM)引入到文本分类中,并取得了不错的效果。对于两分类情况,SVM的基本思想可以用图1来说明,空心点和实心点分别表示不同的类别,H为分割超平面,H1和 H2分别表示各类中离分割超平面最近且平行的平面。H1和 H2上的点被称作支持向量,H1和 H2之间的间距被称为分类间隔 (Margin)。最优分割超平面就是要求在正确分开不同类别的前提下 ,分类间隔最大 (Margin)。

图1 RR最优分割超平面简图
假设线性分类平面的形式为:

其中 w是分类权重向量,b是分类阈值。将判别函数进行归一化处理,使判别函数对于两类样本都满足,即
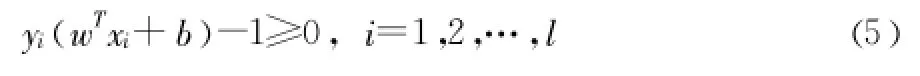
其中yi是样本的类别标记,xi是相应的样本。
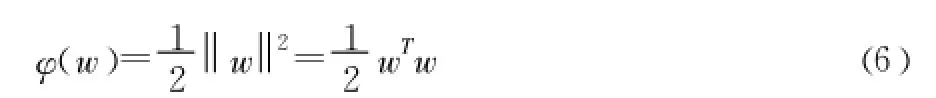
引入拉格朗日乘子 αi,根据Karush-Kuhn-Tucker (KKT)条件 ,上述问题可以转化为在约束条件 (7)下使泛函w(α)最大化,泛函 w(α)的表达式如 (8)所示。
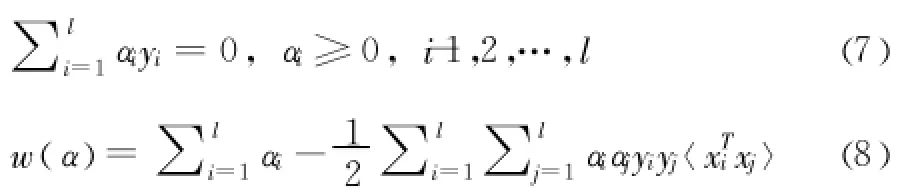
二次规划可以求得αi,将αi带入 (9)求得w

选择不为零的αi,带入 (10)中求得 b。

通过推导,决策函数变为以下式子
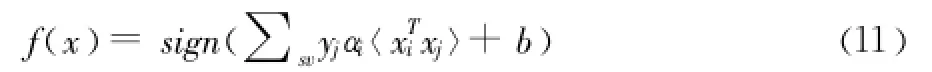
把测试样本带入 (11)中,如果f(x)=1则属于该类,否则不属于该类。
3.2KNN算法
KNN算法是Cover和Hart于1968年提出一种基于统计的学习方法。该算法的基本思想是先把文档用向量空间表示出来,当对一篇待分类文档进行分类时,将这篇文档与训练集中所有文档进行相似度计算,然后把计算结果按降序进行排列,选取结果靠前K篇文档,最后统计这 K篇文章所属的类别,将所属文章最多的类别作为待分类文档的类别。
本文采用夹角余弦计算文本之间的相似度,KNN算法计算步骤如下:
(1)在文本分类训练阶段,把训练集中的文本用向量空间模型表示为特征向量。
(2)将待分类样本 di表示成和训练集中文本一致的特征向量。
(3)根据夹角余弦公式计算待分类样本 di和每个训练集的距离 ,选择与待分类样本距离最近的 K个样本作为di的K个最近邻,余弦夹角公式如下所示:

其中 ,w1i、w2i分别为文档d1,d2向量中第 i个特征的权重值 ,Sim(d1,d2)的值越大说明两个文本的相似度程度越高。
(4)统计每个类别所属的文章数。
(5)将所属文章最多的类别作为待分类文档的类别
KNN算法的优点:该算法无须知道各个特征值的分布 ,并且该算法构建方法简单,易于实现。
KNN算法的缺点:因为该算法是懒惰的学习算法,对两个文本进行相似度计算的时候开销比较大 ,分类速度不是特别理想。
总体而言,KNN算法在文本分类领域得到广泛应用,并且KNN算法是目前众多文本分类算法中分类效果较理想的算法之一。
4 文本评估方法
本文使用准确率、查全率和综合考虑准确率和查全率的综合分类率F1作为文本分类性能的评价指标[6]。准确率是指在分类器判定属于类别 Ci中 ,确实属于类别 Ci的文档数所占比例,其公式表示如下:

查全率是指分类器正确分类的文本占原本属于类别 Ci的文档数的比例,其公式计算如下:

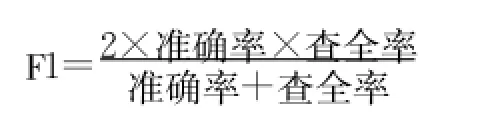
准确率和查全率反映了分类质量的两个不同指标,两者必须综合考虑,不可偏废,因此用综合分类率F1综合考虑准确率和查全率,其计算公式如下:
5 实验结果与分析
本实验使用Visual Studio 2013作为编程开发环境,采用ICTCLAS汉语分词系统进行分词,随机的从复旦中文语料库中选取Education、Agriculture、Economy、Politics 4类样本各120篇,其中60篇作为训练集、60篇作为测试集 ,4个类别的数据大小分别为70.8KB、706KB、825KB、1044KB,采用信息增益作为评分函数对文本进行特征选择。
SVM核函数分别采用多项式核函数和径向基核函数,多项式核函数的形式为K(x,xi)=[(x*xi)+1)]q,多项式核函数只有一个参数 q,当采用不同的 q时,文本分类的性能有所波动 ,另外随着参数 q的增加,其训练所需的时间也随之增加,本实验多项式的参数 q分别取为2、3、 4;径向基核函数的形式为径向基核函数中,也只有一个核参数 σ(在实验中我们取的值),σ所代表的是径向基的宽度 ,它反映了函数图像的宽度,σ越小,宽度越窄,函数越具有选择性,本实验 σ2取0.01、0.09、0.6。SVM分别使用多项式核函数和径向基核函数进行分类之后的结果如表1所示。KNN算法的 K值选择为8,KNN分类结果如表2所示。

表1 RRSVM分类结果
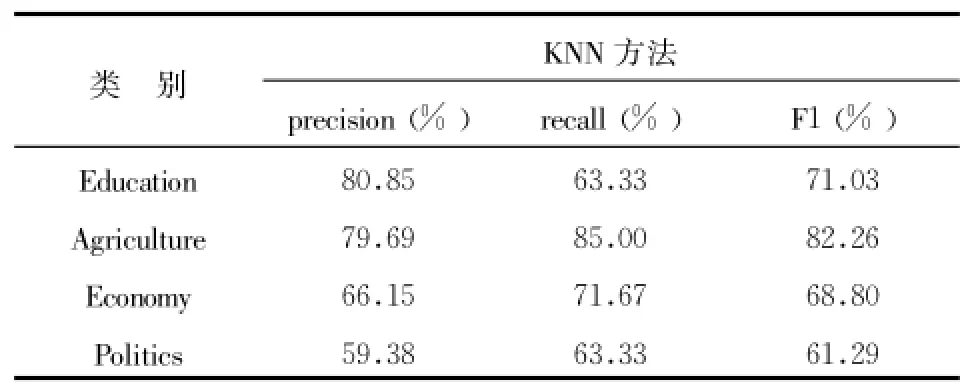
表2 RRKNN分类结果
由表1可知采用不同的核函数对于支持向量机的分类效果影响非常明显,当使用多项式核函数时最高的分类准确率达到89.83%,最高的召回率达到91.67%,而采用径向基函数时最高的分类准确率仅为65.71%,最高的召回率为86.67%,并且可以从表中明显看出 ,支持向量机使用径向基函数进行分类的效果非常不明显,达不到人们预期的效果。因此当选择支持向量机作为分类算法时,采用什么样的核函数,核函数选择什么样的参数对于分类至关重要。
由表1、表2的实验结果可见,当SVM选择多项式作为核函数时,查全率、准确率、F1三个评价指标普遍高于采用传统KNN分类之后的结果。
笔者分析可能有以下几个原因:(1)支持向量机算法能够将数据映射到高维空间,当数据映射到高维空间之后 ,就可以对原始空间不能线性分类的样本进行分类,这就降低了样本被误分的概率 ;(2)本实验没有选择合适数量的训练样本数量,因为如果训练样本过小,在测试阶段出现的特征词将不会出现在训练阶段选择的特征项当中 ,但是如果训练样本过大,将会出现 “过学习”的现象,因此后期将会对样本数量对两种算法分类性能的影响进一步深入研究;(3)越靠近训练样本的测试样本应该给予较重的权重 ,但是本实验采用传统的KNN算法,该算法给予前K个最近邻同样的权重 ,因此有必要对前 K个最近邻样本赋予不同的权重 ,且前 K个最近邻样本的权重进随着距离的增大单调递减。
传统观念认为小类别的信息量无法与大类别抗衡,其信息容易淹没在大类别中 ,导致小类别文档被大量误分,通过本实验结果可以发现在准确率相差不大的前提下,采用多项式核函数的SVM算法和KNN算法对于数据量最小的Education(70.8KB)分类的召回率和F1两个指标均高于对数据量最大的Politics(1 044KB)进行分类之后的召回率和F1。通过查看训练集和测试集的原始文本,Education类别的文档长度普遍少于其他3个类别。很有可能是长文本包含了大量与类别无关的信息 ,从而导致类别相关的词语被无关信息所淹没,而在进行短文本编辑的时候,作者会选择与类别最相关的词进行写作,因此在进行分类的时候 ,短文本的分类准确率高于长文本。
7 结 语
本文通过对SVM和KNN算法进行文本分类性能比较研究,核函数是影响SVM分类效果的一个重要因素,当SVM选择多项式作为核函数时,分类的准确度优于KNN分类算法,同时本实验发现两种算法对短文本的分类准确率均高于对长文本的分类准确率。针对研究存在的不足,后期准备在以下3个方面进行改进:(1)针对常用的径向基核函数和多项式核函数各自存在的优缺点,将二者结合构造新的核函数,并尝试构建适合文本分类的核函数;(2)对KNN的算法的前 K个近邻赋予不同的权重;(3)研究如何克服类别样本数据量分布不均匀对分类准确率的影响。
[1]钱庆,安新颖 ,代涛.主体追踪在医药卫生体制改革舆情监测系统中的应用 [J].图书情报工作 ,2011,55(16):46-49.
[2]牛强,王志晓 .基于KNN的Web文本分类的研究 [J].计算机应用与软件 ,2007,24(10):210-211.
[3]张爱丽 ,刘广利 ,刘长宇 .基于SVM的多类文本分类研究[J].情报杂志 ,2004,(9):6-10.
[4]Wang Bin,JonesG JF,Pan Wen Feng.Using online Linear classifier to filter span emails[J].Pattern Analysis&Application,2006,(9):339-351.
[5]代六玲,黄河燕,陈肇雄 .中文文本分类中特征抽取方法的比较研究 [J].中文信息学报,2004,18(1):26-32.
[6]胡涛,刘怀亮 .中文文本分类中一种基于语义的特征降维方法[J].现代情报 ,2011,31(11):46-50.
[7]张小艳,宋丽平.论文本分类中特征选择方法 [J].现代情报 ,2009,29(3):131-133.
[8]Cortes C,Vapnik V.Support-Vector Networks[J].Machine Learning,1995,(20):273-297.
[9]卜凡军 ,钱雪忠 .基于向量投影的KNN文本分类算法 [J].计算机工程与设计 ,2009,30(21):4939-4941.
[10]赵辉.论文本分类中特征选择方法[J].现代情报 ,2013,33(10):70-74.
[11]Sebastiani F.Machine learning in automated text categorization[J]. ACM Computing Surveys,2002,34(1):1-47.
[12]侯汉清.分类法的发展趋势简论 [M].北京 :中国人民大学出版社,1981.
[13]G.Salton.Introduction to Modern Information Retrieval.McGraw-Hill,1983.
(本文责任编辑:孙国雷)
Research on Text Classification Based on SVM and KNN
Zhang Huaxin Pang Jiangang
(College of Economy and Management,Southwest University of Science and Technoloy,Mianyang 621000,China)
This papermade a comparison between SVM and KNN on text classification after illustrating the procedures in text classification.The experimental results showed that the accuracy of SVM by using Polynomial kernel function is higher than thatby using Radial Basis function,besides,theaccuracy of the former increaseswhen the parameterq getsbigger;theaccuracy of SVM by using Polynomial kernel function isgenerally higher than thatby using KNN;the accuracy of SVM and KNN both have higher recallof short text than long text.
text-classification;KNN;SVM;kernel-function
张华鑫 (1991-),男,情报学硕士研究生,研究方向:数据挖掘、竞争情报。
10.3969/j.issn.1008-0821.2015.05.014
TP301.6
A
1008-0821(2015)05-0073-05
2014-12-02
本文系四川省社科基金项目 “产业技术创新战略联盟知识共享机制研究”(批准号 :SC13E012)和四川省教育厅项目 “众包式网络社区大众协同创新项目”(批准号:12SB0258)研究成果之一。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
信息安全研究(2016年4期)2016-12-01 06:06:54
新校长(2016年8期)2016-01-10 06:43:59
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
