
结合主动学习和半监督学习的网络入侵检测算法
2015-07-18 11:22:36赵建华1
西华大学学报(自然科学版) 2015年6期
赵建华1,2,刘 宁
(1.商洛学院数学与计算机应用学院,陕西 商洛 726000; 2.西北工业大学计算机学院,陕西 西安 710072;3. 商洛学院经济与管理学院,陕西 商洛 726000)
·计算机软件理论、技术与应用·
结合主动学习和半监督学习的网络入侵检测算法
赵建华1,2,刘 宁3
(1.商洛学院数学与计算机应用学院,陕西 商洛 726000; 2.西北工业大学计算机学院,陕西 西安 710072;3. 商洛学院经济与管理学院,陕西 商洛 726000)
为提高网络入侵检测的分类效率,提出一种结合主动学习和半监督学习的入侵检测算法。结合入侵检测实际,对主动学习算法进行简化,用有标记样本训练生成2个分类器,实现对未标记样本的预测;将2个分类器预测不一致的未标记样本作为信息量丰富的样本,使用半监督学习算法进行标记;最后, 把新增加的新标记样本添加到主动学习和半监督学习的训练集中,训练各自分类器, 反复迭代直到未标记样本集为空, 并用最新的有标记样本集训练形成最终的分类器。使用KDD CUP 99数据集进行入侵检测实验,其结果表明,与SVM方法相比,其分类率提高了4.3%,且较好地缩减了问题规模。
主动学习;半监督学习;入侵检测
入侵检测(intrusion detection, ID)技术是继“防火墙”等传统安全保护措施后发展起来的新一代安全保障技术,被誉为继防火墙之后第2道网络安全防线[1]。作为一种主动的网络防御技术,入侵检测能够全面监控计算机网络或主机上的各种应用程序,对系统中多种入侵行为进行主动地识别和响应,有效地提高了网络的安全性[2-5]。
机器学习在入侵检测中的应用成为当前入侵检测的一个热点,它提高了检测率,降低了误报率。早期的基于机器学习的入侵检测算法大多是基于有监督机器学习的。它的主要缺点是无法有效地检测到未知攻击,而且要求训练集中的所有训练样本被标记为正常或异常[6-7]。基于无监督的网络入侵检测,误报率高,不能充分利用有标记入侵数据的类别信息[8]。
半监督学习能够充分利用蕴含在无标记训练样本中的信息,在分类的正确性和有标记训练样本较少数目之间取得了较好的折中[9-10]。为解决入侵检测中有标记数据获取难度大的问题,不少研究者将半监督学习引入到入侵检测领域,通过半监督学习挖掘无标记样本的信息,扩充有标记样本的数目,训练分类器,实现对大量入侵数据的检测,取得了较好的分类效果[11-12];然而,由于网络入侵检测中数据流量大,对数据的实时处理要求较高,对分类器的处理能力要求也较高。如果对所有的未标记入侵数据都进行半监督学习和标记,费时费力,入侵检测性能将会大打折扣[8]。
为有效提高入侵检测性能和效率,本文将主动学习和半监督学习结合起来,提出一种结合主动学习和半监督学习的分类算法Active CV-S3VM,并将其应用到入侵检测领域。首先,Active CV-S3VM对主动学习算法进行简化,使用简化的主动学习选取信息含量高的无标记样本,这样仅仅对信息量高的无标记样本进行标记,提高主动学习效率,减少半监督学习工作量;接着,使用半监督学习算法对主动学习选取的无标记样本进行标记,挖掘无标记样本隐含信息;最后通过KDD CUP 99入侵检测数据集进行半监督分类实验,以证明该方案的有效性。
1 主动学习算法
在主动学习中,从候选样本集选取样本时,每次都是选择最有利于提高分类器性能的样本,提供给专家进行人工标记,并将这些标记好的样本以一定的方式加入到训练集中。选择样本的基本思路就是考虑不同样本对分类器的作用不同, 即信息量越丰富的样本,对分类界面的确定越重要[13]。
委员会投票选择算法(query by committee, QBC)是一种有效的主动学习方法。它首先根据已有的有标记数据集建立委员会,利用这个委员会对无标记样本进行标记预测、投票,然后选择投票最不一致的样本作为候选样本。投票最不一致的样本包含的信息量最丰富。这种方法不需要对预测的样本进行伪标记,也不需要在整个样本空间中进行检测。其学习速度快,能够使用较少的训练样本达到较好的分类精度[13-14]。
基于熵的主动学习方法中,利用熵来确定样本的不确定性, 熵越大, 分类的不确定就越大, 包含的信息就越丰富, 用户对熵最大的样本进行人工标记,然后添加到训练集。基于熵的主动学习样本选择策略[13]可表示为

(1)
式中:U表示无标记样本集;Y表示所有可能的类别标记的集合;P(yi|xi) 表示样本xi属于类别yi的概率。
通过熵来度量委员会中各成员投票的不一致性,可将委员会投票选择算法QBC分为2种:一种是基于投票熵(vote entropy,简称VE) 的方法来度量委员会投票差异性;一种是基于相对熵(又称KL散度,简称KLD)的方法来度量委员会投票差异性。
在基于投票熵VE的QBC算法中,通过计算无标记样本的投票熵来表示各个委员会的投票不一致性,投票熵越大,说明委员会成员的投票差异性越大,所包含的信息量越丰富,选取投票熵最大的样本交由专家进行标记。投票熵的计算可表示为

(2)
式中:D(e) 表示委员会成员对样本e的投票差异性;k表示委员会成员的数目;C表示样本的类别数目;V(c,e) 表示委员会成员对样本e的类别c投票的数目。
2 结合主动学习和半监督学习的网络入侵检测
2.1算法思想
本文对基于投票熵的主动学习进行简化,以提高分类效率。其思路是:通过有标记样本训练生成2个分类器;通过2个分类器实现对未标记样本进行预测,将预测不一致的样本选做熵最大的样本,即蕴含信息量最丰富的样本;将信息量最丰富的未标记样本提交给半监督学习算法进行标记,并将新增加的有标记样本添加到有标记样本集中,扩充有标记样本的数目;使用新的有标记集继续训练主动学习和半监督学习分类器。如此反复迭代,直到未标记样本集为空。
2.2算法步骤
算法主要包括3个部分:主动学习、半监督学习和入侵检测。入侵检测算法流程如图1所示,实线表示有标记样本的流向,虚线表示无标记样本的流向。在主动学习过程中,主要是用有标记样本集L训练生成2个分类器,用分类器1和分类器2分别对无标记样本进行预测,将2个分类器预测结果不一致的样本作为主动学习的结果。半监督学习主要使用基于交叉验证的半监督学习方法CV-S3VM[15],实现对主动学习选取的、信息量丰富的样本进行标记,并将标记生成的新样本添加到L中,扩充L。入侵检测主要使用KDD CUP 99数据集,通过半监督学习标记后的新标记样本集L训练分类器,实现对测试集的测试。详细步骤如下。
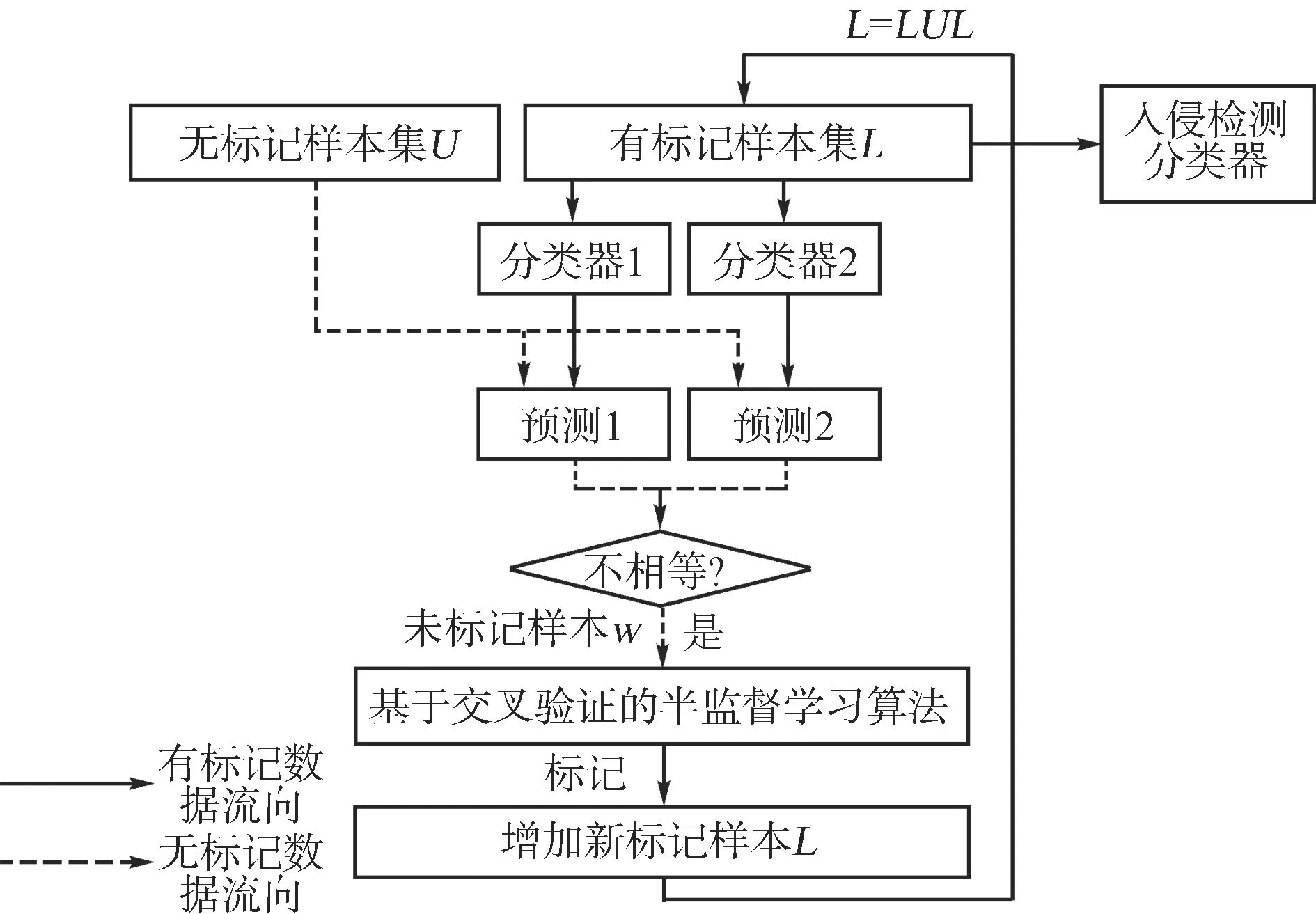
图1 基于主动学习和半监督学习的入侵检测
步骤1: 对网络数据进行归一化。
选取KDD CUP 99 数据集进行入侵检测实验,将数据集分为训练集和测试集。将训练集分为有标记数据集和无标记数据集。为便于统计测试的正确率,测试集全部选用有标记数据。为方便实现对数据的训练和测试,对样本中数据属性(离散值)进行数值化处理[12]。为取消各维数据间数量级差别,利用归一化函数对输入样本的特征值进行数据归一化处理,将其归一化到[0,1]之间。
步骤2: 标记集L和无标记集U的选取。
从有标记数据集中选取部分数据作为有标记集L,从步骤1归一化后的数据集中,选取部分数据形成无标记数据集U。
步骤3: 主动学习选取信息量大的样本。
由于网络数据流量较大,为提高入侵检测效率,对基于投票熵的主动学习算法进行改进,简化了主动学习过程。通过训练2个分类器,实现对未标记样本进行预测,选取2个分类器预测不一致的样本作为信息量大的未标记样本。其具体过程如下。
1) 生成2个分类器。将有标记样本集L分为2等份L1和L2,分别作为训练集训练SVM,生成2个分类器SVM1和SVM2。为了提高2个分类器SVM1和SVM2的差异性,在选取L1和L2的过程中,要保证在二者中各种类型样本的比例一致,2个训练集中的样本不重复,相似度小。
2) 选取信息量丰富的样本。使用SVM1和SVM2对U中的样本w分别进行预测。若二者相等,即认为该样本是信息量比较小的样本,进行丢弃处理;若不相等,即认为是信息量丰富的样本。
3) 结果处理。将选取的信息量丰富的样本作为主动学习选取的结果,交给交叉验证半监督分类算法CV-S3VM[15],对其进行标记。
步骤4: 使用交叉验证半监督学习算法CV-S3VM对无标记样本进行标记[15]。具体过程如下。
1) 假设对样本进行m分类(m≥2),对于从步骤3U中选取的无标记样本w,使用Mi(取值为1,2,…,m-1,m)分别对其进行伪标记,共形成m个分类假设。对任意一个分类假设,将(w,Mi)添加到有标记集L中,形成新的有标记集。
2) 对于每个新的有标记样本集L,将其分为k组。每次都将每组的子样本集做1次验证集,其余的K-1组子样本集作为训练集,得到k种数据模型。在这K种数据模型中,每次都使用训练集训练SVM,使用验证集进行验证,每种数据模型对应一个分类准确率。使用式(3)计算k个模型的分类准确率均值,并根据式(4)计算对应的误差率。
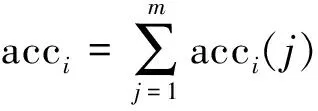
(3)
式中:acci表示使用伪标记Mi后的分类准确率;acci(j)表示第j个分类器的分类正确率。
ei=1-acci。
(4)
式中ei表示使用伪标记Mi后的误差。
选取使得误差率最小的标记Mx,将其作为w的最终标记,并将标记后的(w,Mx)添加到L中,扩充有标记集L。
步骤5: 反复迭代。
将新增加的标记样本添加到有标记样本集L中,形成新的有标记样本集,重复步骤3,反复迭代,直到未标记样本集U为空。
步骤6: 生成最终的半监督分类器。
使用最终的有标记样本集L训练SVM,生成最终的半监督分类器。
步骤7: 实现对网络数据的入侵检测。
使用步骤6生成的半监督分类器实现对网络数据的入侵检测。按照式(5)统计实验结果,求分类正确率,同时统计迭代次数。
正确分类率=

(5)
2.3算法实现
算法的具体实现如图2所示,主要包括选取信息量丰富的未标记样本、用半监督学习算法对未标记样本进行标记和入侵检测3个部分。

图2 算法伪代码
3 实验与结果分析
实验平台选用PC进行,其中软硬件环境如下:CPU为Intel Core2 Duo 2.0GHz、内存2.0GB,安装Windows XP 操作系统和MATLAB R2009b软件。SVM选用台湾大学林智仁等开发的libsvm-mat-2.89-3。
采用KDD CUP 99数据集进行半监督分类实验。其中:无标记训练集由从KDD CUP 99的“10% KDD”数据集中随机抽取的500条正常数据和500 条攻击类型数据组成;有标记训练数据集是从KDD CUP 99 的“10% KDD”数据集中随机抽取36条数据组成;测试数据集由从KDD CUP 99 的“Corrected KDD”数据集中随机抽取的500条正常数据和500条攻击类型数据组成。
有标记数据中每个样本有41 个不同的属性(其中32个连续属性和9个离散属性)和1个攻击类型(可分为正常或异常,也可按照攻击类型进行细分);无标记集数据中,每个样本有41 个不同的属性。为了方便实现对数据的训练和测试,对样本中数据属性(离散值)进行数值化处理,具体的讲就是使用数字对其进行编号。比如将攻击类型分为正常数据和攻击数据,分别用0和1进行编号,对服务类型aol、auth、…、 whois等使用1、2、…、68等进行编号,对协议TCP、UDP、ICMP等分别用1、2、3等进行编号,以实现数值化[12,16-18]。
实验数据中,有标记样本训练集的组成如表1所示,Normal代表正常的数据,DOS、R2L、U2R和Probe分别代表异常数据。有标记样本训练集,作为分类器的初始化训练集。实验根据有标记样本集选取数目的不同分3类分别进行。
对于3类半监督分类实验数据集,分别使用普通的SVM方法(即训练集仅使用初始的有标记样本集)和Active CV-S3VM方法(本文提出的、结合主动学习和半监督学习的分类算法,使用主动学习缩减无标记样本规模,使用半监督学习挖掘无标记样本信息)进行入侵检测实验。每种实验各自进行3次,然后求平均值,每次实验按照式(5) 计算正确分类率。

表1 实验数据集

表2 实验结果
对比SVM和Active CV-S3VM2种分类方法的分类正确率和迭代次数,实验结果如表2所示。其中分类正确率通过图3进一步形象地反映出来。
通过表2可以看出,Active CV-S3VM使用主动学习对无标记样本进行筛选,仅选取信息量丰富的样本数目进行标记,这大大减少了半监督学习的工作量,需要进行样本标记的次数减少(表2中提到的迭代次数),从实验集中所需要的1 000次降低到4.33次,问题规模缩减到原来的0.433%,算法的工作效率得到了较好提高。
通过表2和图3可以看出, Active CV-S3VM使用半监督学习方法挖掘未标记样本的信息,对无标记数据进行标记,扩充了有标记样本的数据,用新的训练集训练生成分类器,其对应的分类率明显比SVM要高,平均提高了4.30%,且具有稳定性。 可见,主动学习能较好地降低网络数据规模,与半监督学习相结合,选取信息量高的数据进行标记,能较好地提高网络入侵检测性能。
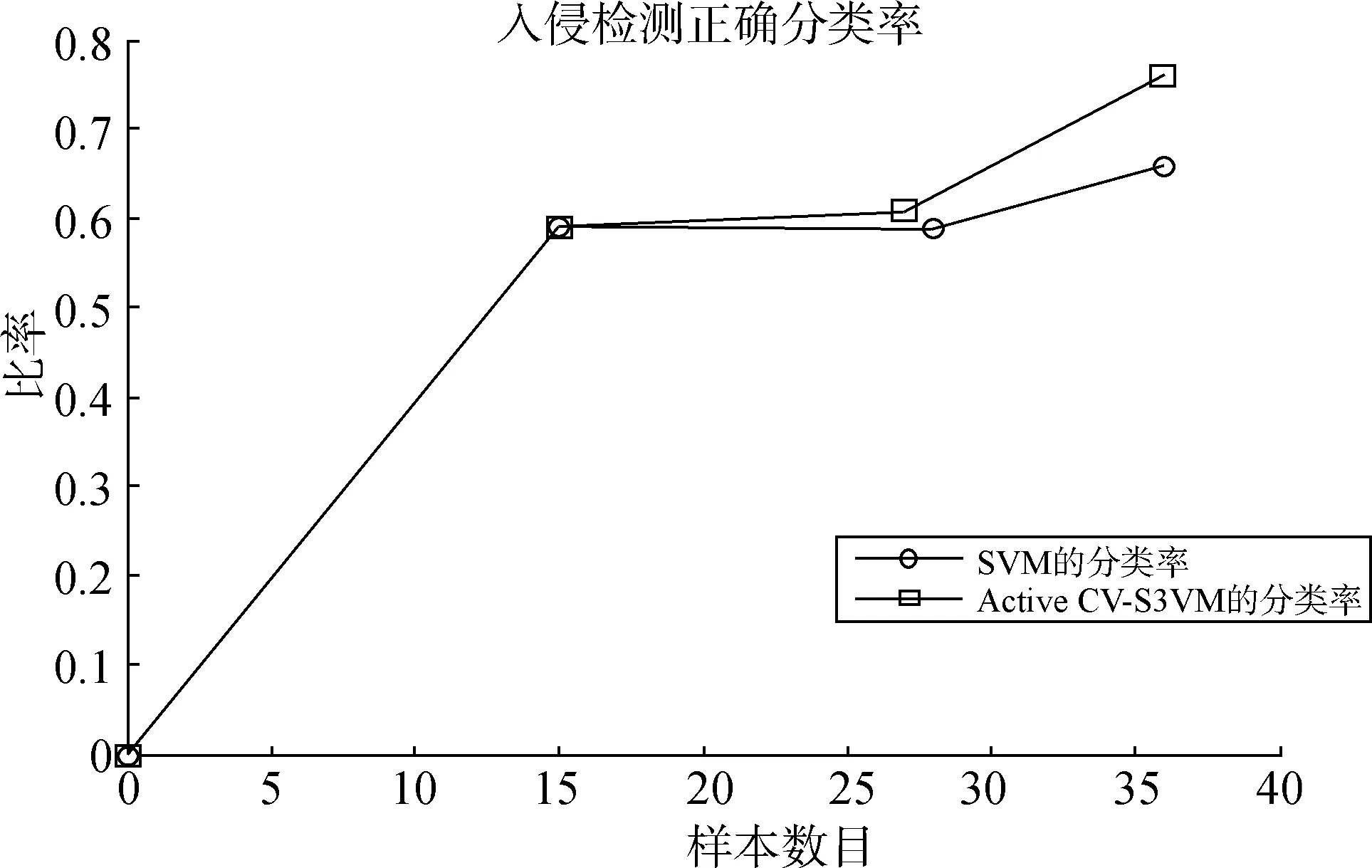
图3 入侵检测正确率对比图
4 结束语
本文对主动学习算法进行简化,将简化后的主动学习和半监督学习进行结合,并将其应用到网络入侵检测领域。通过KDD CUP 99数据集进行半监督入侵检测实验,其结果表明,该算法操作简单,能有效地缩减样本规模,提高分类率,有效地提高网络入侵检测性能。
[1]McHugh J, Christie A, Allen J. Defending Yourself:The Role of Intrusion Detection Systems[J]. Software, IEEE, 2000, 17(5): 42-51.
[2]蒋建春, 马恒太, 任党恩, 等. 网络安全入侵检测: 研究综述[J]. 软件学报, 2000, 11: 1460-1466.
[3]赵曦滨, 井然哲, 顾明. 基于粗糙集的自适应入侵检测算法[J]. 清华大学学报:自然科学版, 2008, 48(7): 1165-1168.
[4]彭宏,吴铁峰,张东娜.粗糙模糊模型及其在入侵检测中的应用[J].西华大学学报:自然科学版,2005,24(3):1-3.
[5]王翼,刘兴伟.基于免疫算法的入侵检测系统[J].西华大学学报:自然科学版,2006,25(5):48-50.
[6]黄艳秋. IA-SVM 算法在网络入侵检测中的研究[J]. 计算机仿真, 2011, 28(1): 182-185.
[7]夏战国, 万玲, 蔡世玉,等. 一种面向入侵检测的半监督聚类算法[J]. 山东大学学报:工学版,2012,42(6):1-6.
[8]李永忠, 胡翰. 基于主动学习的半监督聚类入侵检测算法[J]. 江苏科技大学学报: 自然科学版, 2010, 24(2): 160-163.
[9]陆悠,李伟,罗军舟,等. 一种基于选择性协同学习的网络用户异常行为检测方法[J].计算机学报,2014,37(1):28-41.
[10]Li M, Zhou Z H. Improve Computer-aided Diagnosis with Machine Learning Techniques using Undiagnosed Samples[J]. Systems, Man and Cybernetics, Part A: Systems and Humans, IEEE Transactions on, 2007, 37(6): 1088-1098.
[11]PACHGHARE V K, KHATAVKAR V K,KULKARNIP. Performance Anaysis of Semi-supervised Intrusion Detection System[J]. International Journal of Computer Applications,2011,NSC(4):15-19.
[12]赵建华. 半监督学习在网络入侵分类中的应用研究[J]. 计算机应用研究, 2014, 31(6): 1874-1876.
[13]赵悦,穆志纯. 基QBC 的主动学习研究及其应用[J].计算机工程,2006,32(24):23-25.
[14]Melville P, Mooney R J. Diverse Ensembles for Active Learning[C]//Proceedings of the 21st International Conference on Machine Learning. New York:ACM Press,2004:584-591.
[15]赵建华. 一种基于交叉验证思想的半监督分类方法[J].西南科技大学学报:自然科学版,2014,29(1):34-38.
[16]赵建华, 李伟华. 有监督SOM神经网络在入侵检测中的应用[J]. 计算机工程, 2012, 38 (12): 110-111.
[17]阳时来, 杨雅辉, 沈晴霓, 等. 一种基于半监督 GHSOM 的入侵检测方法[J]. 计算机研究与发展, 2013, 50(11): 2375-2382.
[18]钱燕燕, 李永忠, 余西亚. 基于多标记与半监督学习的入侵检测方法研究[J]. 计算机科学, 2015, 42(2): 134-136.
(编校:饶莉)
NetworkIntrusionDetectionAlgorithmBasedonActiveLearningandSemi-supervisedLearning
ZHAO Jian-hua1,2,Liu Ning3
(1.SchoolofMathematicsandComputerApplication,ShangluoUniversity,Shangluo726000China;2.CollegeofComputer,NorthwesternPolytechnicalUniversity,Xi’an710072China;3.FacultyofEconomicsandManagement,ShangluoUniversity,Shangluo726000China)
In order to improve the classification performance of network intrusion detection, a kind of intrusion detection algorithm is proposed based on active learning and semi-supervised. The active learning algorithm was simplified, and two classifiers were trained with labeled samples to predict the unlabeled sample. The unlabeled samples that were predicted differently by the two classifiers were considered as rich information samples, and were labeled using a semi-supervised learning algorithm and were added to the training set of active learning and semi supervised learning to train classifier. The iteration was repeated until the unlabeled set was empty. The final classifier was trained and generated by the newest labeled training set. The experiment was carried out on KDD CUP 99 data set. The results show that the classification rate increased by 4.3% and the problem scale was reduced greatly .
active learning; semi-supervised learning; intrusion detection
2015-04-23
陕西省自然科学基础研究计划资助项目(2015JM6347);商洛学院博士启动基金项目(14SKY026)。
赵建华(1982—),男,副教授,博士,主要研究方向为半监督学习、网络安全。E-mail:zhaojh2009@aliyun.com
TP181; TP393.08
:A
:1673-159X(2015)06-0053-05
10.3969/j.issn.1673-159X.2015.06.011
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
西南交通大学学报(2018年5期)2018-11-08 10:59:16
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
电子测试(2018年1期)2018-04-18 11:52:35
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
新闻传播(2016年11期)2016-07-10 12:04:01
计算机工程(2015年4期)2015-07-05 08:29:20
