
基于粗糙集的数据挖掘改进属性约简算法研究
2015-07-12 17:38:20卢秀芸
镇江高专学报 2015年1期
卢秀芸
(江苏联合职业技术学院镇江分院 信息工程系,江苏,镇江 212016)
基于粗糙集的数据挖掘改进属性约简算法研究
卢秀芸
(江苏联合职业技术学院镇江分院 信息工程系,江苏,镇江 212016)
研究基于粗糙集的属性约简算法在数据挖掘规则提取阶段的应用。数据挖掘中对属性进行约简时,经常采用粗糙集,再按照规则进行提取。考察差别矩阵的定义和信息系统比较复杂且核属性元素所占比例较少的情况,改进基于差别矩阵的属性约简算法,利用差别矩阵的结构建立一种新的选择属性的依据。
粗糙集;数据挖掘;属性约简;改进
数据挖掘是发现知识的核心步骤,主要作用是发现大量数据中的隐藏模式[1]。粗糙集理论是1982年由波兰科学家提出的一种新型的处理不确定和模糊知识的数学工具,其主要优点是提取知识时不靠人为的假设,全部由数据驱动。它使用数据本身的内部知识,在确定已经给定的问题近似域时,主要通过不可分辨类以及不可分辨的关系自动得到问题的内在规律。
1 粗糙集
粗糙集一般用于处理具有不确定性的知识和模糊知识。研究粗糙集,重点是在保持知识库分类能力的条件下,对知识库中的知识属性进行约简,推导需要研究知识的决策规则[2]。
设信息系统IS=(U,A,V,f),令R⊆A,若满足:
1)H(R)=H(A),
2)a∈R,H(a|R-a)>0,则称R是IS的约简[3-4]。知识的约简并不是唯一的。现在对具有不确定性知识进行处理的理论非常多。相对而言,粗糙集理论所依靠的仅仅是问题所提供的数据集合,不需要其他的先验知识,同时,还能和其他理论如模糊学和证据理论、概率与数理统计理论等互补。它在数据挖掘、决策分析、模式的分类和识别、人工智能等方面都有较成功的应用。
2 数据挖掘
2.1数据挖掘的概念
数据挖掘是将隐藏在大型信息系统或知识库中对人们的生活和工作具有一定潜在应用价值的知识信息提取的过程。图1显示了数据库知识发现的较完整的过程。

图1 数据库知识发现的过程
从图1可以看出,数据库通过数据的清洗和集成之后得到数据仓库。其主要工作是得到比较一致和完整的数据,去除数据库中的噪声数据及与挖掘主题无关的数据,利用统计学方法修补数据库中丢失的数据,同时把相关联的数据源组合在一起形成数据仓库。形成数据仓库之后,需要了解相关的背景知识和用户需求,提取与当前知识发现相关的数据,并根据发现任务对数据的格式进行转化[5]。数据挖掘是通过一定的算法搜索某种模式或知识,并通过可视化的技术提供给用户。
数据挖掘的主要任务是提取和分析存储在知识库中的业务知识,挖掘隐含在知识库中对人们正确决策起到一定辅助作用的信息,通过容易理解的方式反馈给用户。具有代表性又较成熟的数据挖掘技术主要有神经元网络技术、遗传算法、统计分析方法、模糊集方法、粗糙集方法等[6]。
2.2数据挖掘的过程
数据挖掘主要是分析和查询现场数据库或信息系统中的数据,找出这些数据之间的联系,辅助人们做出正确的决策规则。数据挖掘的过程主要包括数据处理、模型搜索、结果评估、输出最终结果、对最终结果进行解释等。
2.3基于粗糙集的数据挖掘模型
粗糙集在处理知识时具有一些独特的特征,已经成为数据挖掘技术中重要的基础理论之一。基于粗糙集的算法采用的信息表与关系数据库用来表达知识关系的数据模型相似,能够很容易地嵌入关系数据库的数据处理过程,而且采用粗糙集算法的知识简练,易于人们存储和理解。基于粗糙集理论的数据挖掘是指在处理对象决策表的数据时,通过粗糙集的属性约简算法对决策表中的知识进行约简,最终得到一定的规则[7]。
3 属性约简算法的改进研究
3.1改进算法的提出
基于差别矩阵的属性约简算法主要采用差别矩阵巧妙提出信息系统核的计算方法。但采用这种信息系统,要得到所有属性的约简,需要对信息系统条件属性集幂集中的元素进行依次遍历。基于差别函数的属性约简算法主要是在差别矩阵的算法基础上引入逻辑运算。这种算法需要先把差别矩阵中的每一个非空元素项转化为相应的析取式,再把全部析取式进行合取,得到一个具有多项的内析取外合取的范式,并通过一定的逻辑运算将内析取外合取的范式转换为内合取外析取范式[2]。这样,最终得到的范式合取项就是当前条件下属性集合的约简集。随后的基于差别函数的改进属性约简算法主要是对原始的属性约简算法进行一定的优化,其中主要的优化是在原始的基于差别函数的属性约简算法建立起范式之前增加1个操作步骤,即置空所有包含有核的元素项,在一定程度上减少逻辑运算的规模,提高算法的效率。如果需要处理的信息系统比较复杂,而且系统当中核属性的元素所占比例非常小时,那么基于差别函数以及基于差别矩阵的属性约简算法效率就非常低,需要利用差别矩阵建立一种效率高的算法[5]。本文主要是利用差别矩阵的结构建立一种新的选择属性的依据。在信息系统的差别矩阵中,元素项主要用来区别两个相应对象的条件属性。在差别矩阵中,某种条件属性出现的次数较多,说明这个条件属性能区分的对象个数较多,反之,说明这个条件属性能区分的对象个数较少,对于整个论域的分类能力影响较小;如果某一种属性没有出现过,说明这种属性不能用来区分任何对象,是冗余的,可以直接删除。可以把差别矩阵中某种属性出现的频率看成启发式信息,提出一种基于差别矩阵和属性选择的属性约简算法[8]。
3.2改进属性约简算法的分析
约简算法的流程图如图2所示。
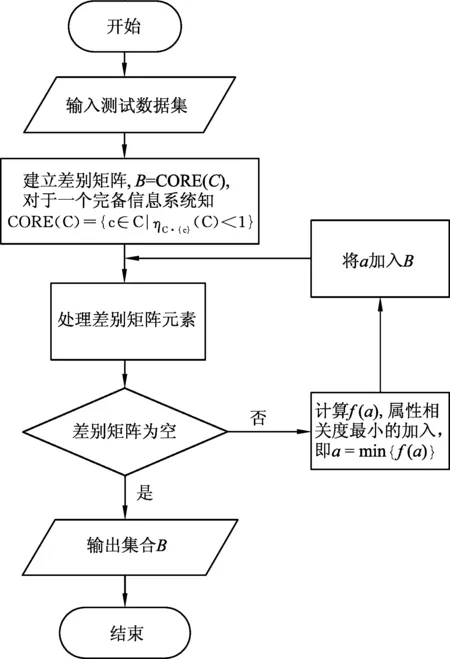
图2 约简算法流程图
如一信息系统IS=(U,A,V,f),其差别矩阵如图3所示。其中U有7个对象,如图4所示。
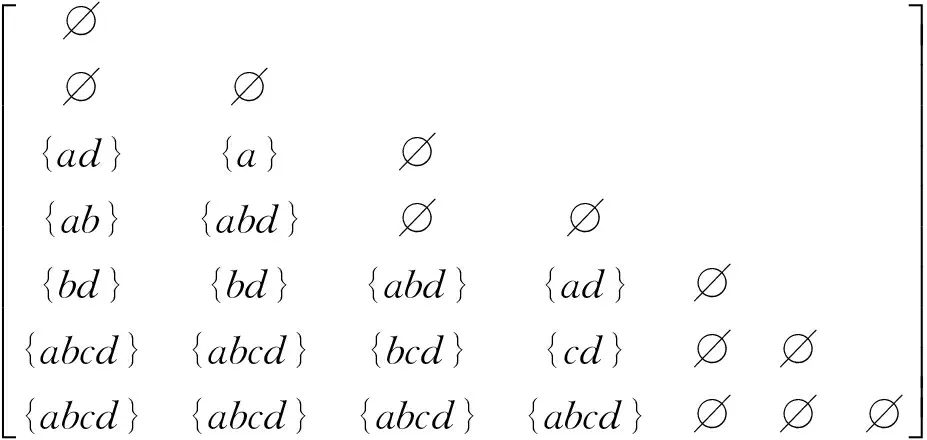
图3 差别矩阵
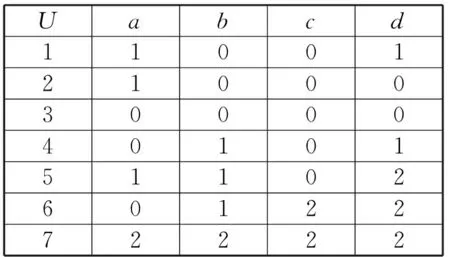
图4信息系统
根据相应的定义、法则,可以求出修改后的差别矩阵,如图5所示。

图5 修改后的差别矩阵
这种属性约简的算法是一种基于差别矩阵以及新的属性选择的算法,具有以下优点:
1) 属性约简更加明确。这种算法主要以属性在差别矩阵中出现的次数作为启发式的信号,同时以属性所在差别矩阵中的元素长短作为加权系数,能够有效避免当出现两个或两个以上属性在差别矩阵中出现次数一样时,采用任意的选择方式得到的属性约简中存在冗余属性的现象。
2) 提高算法的效率。和基于差别矩阵的算法相比较,这种改进后的属性约简算法可以不用对所有包含核属性元素进行依次判断,进而避免组合的问题。和基于差别函数的算法相比较,改进后的算法在时间上的优势更加明显。采用改进后的属性约简算法得到的属性约简往往是有最优解的。这种算法是一种启发式的算法。这种改进后的算法存在一定的不足,主要是空间的复杂度比较高。
4 结束语
粗糙集关于规则的提取、属性的约简及知识定义等方面的理论,让数据仓库方面的数据挖掘有了更深刻的理论基础。粗糙集理论在处理数据的时候较智能化,不需要对知识进行先验,就能从样本数据中挖掘出直接、简明及容易理解的规则。总之,在对操作机属性约简算法进行改进后,数据挖掘技术的应用领域会变得更多。
[1] 李丹.基于粗糙集的数据挖掘属性约简算法的研究[D].哈尔滨:哈尔滨工程大学,2008:1-3.
[2] 吴明旺.基于粗糙集的数据挖掘属性约简算法研究[D].成都:电子科技大学,2006:3-19.
[3] 赵永安.基于粗糙集的属性约简算法研究[D].呼和浩特:内蒙古大学,2008:29-42.
[4] 苗夺谦,陈玉明,王睿智,等.图表示下的知识约简[J].电子学报,2010(8):1952-1959.
[5] 洪雪飞.基于粗糙集的数据挖掘算法的研究与应用[D].北京:北京交通大学,2008:22-45.
[6] ZHANG Z, YU D Y, LI P G, et al. An improved reduction algorithm based on the degree of attribute discernibility[J].High Technology Letters,2007,13(3):244-248.
[7] 崔洪晶.基于粗糙集的属性约简算法研究[D].哈尔滨:哈尔滨工程大学,2007:1-5.
[8] 吴尚智.基于粗糙集理论的属性约简算法研究[D].兰州:西北师范大学,2006:17-27.
〔责任编辑: 卢 蕊〕
Researchontheimprovedalgorithmforattributereductioninroughsetbasedondatamining
LU Xiu-yun
(Information Engineering Department, Zhenjiang Higher Vocational Technical School, Zhenjiang 212016, China)
Application of rule extraction algorithm of attribute reduction based on Rough Set Theory is studied in data mining. The data mining of attribute reduction is often based on rough set, and then it is done in accordance with the rules extraction. Based on the investigation to the relevant definition of discernibility matrix, the information system is more complex and nuclear property element accounts for a small proportion. The algorithm of attribute reduction based on discernibility matrix is improved by using the discernibility matrix structure to establish the basis for a new selection property.
rough set; data mining; attribute reduction; improvement
2014-05-28
卢秀芸(1982—),女,江苏镇江人,讲师,硕士,主要从事数据库研究。
TP274
: A
:1008-8148(2015)01-0055-03
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
大众投资指南(2021年35期)2021-02-16 01:06:26
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
电力与能源(2017年6期)2017-05-14 06:19:37
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
信息通信技术(2015年6期)2015-12-26 01:16:46
四川师范大学学报(自然科学版)(2015年1期)2015-02-28 14:07:21
