
微博用户的个性分类分析*
2015-07-10 01:24:10张岩峰陈长松左俐俐
计算机工程与科学 2015年2期
张岩峰,陈长松,杨 涛,左俐俐,丁 飞
(1.公安部第三研究所,上海 200031;2.中石化管理干部学院,北京 100021)
1 引言
近十年来,社交网络经历了爆炸性的增长,据统计,推特(Twitter)的用户数已超过5亿,一天的数据增量大约为7 TB;脸书(FaceBook)的用户数已超过10亿,一天的数据增量超过10 TB。截至2012年12月底,新浪微博注册用户已超5亿,日活跃用户数达到4 620万,用户每日发博量超过1亿条[1]。用户在这些社交网络上的活动,比如建立个人的资料、建立与他人的链接关系、发表个人观点、共享照片、推荐内容等,表露出大量关于该用户的情感、喜好等因素。
理解个体的个性并对其进行描述,发展系统的个性测试方法,以及将个性的归类应用到对职业发展、职业咨询、团队建议、婚姻教育等领域一直是心理学家研究的一项主题。传统的个性分析方法主要是采用问卷的方式,这种问卷形式易于控制,并且对被调查者所处的环境依赖性弱,但是并不足以完整展示一个人的个性,正如Barker G和Wright H F在文献[2]中提到的:只有对一个人日常的自然行为进行全面的分析,才能够真正了解一个人的特性。
过去的研究表明,人类不可避免地要在他们所经历过的虚拟和真实环境下遗留下与个性相关的行为和思想痕迹[3],比如日常的会话[4]、Facebook账号信息[5]以及用户的写作特性[6]等。微博用户经常用微博来记录他们日常的行为以及思想,有理由相信一个用户的微博数据,包括微博的用词、语法以及语用特征,以及发表分享的内容、账号信息、朋友的关系中包含了许多有关其个性的信息。
本文介绍了一个通过分析用户的微博数据,包括微博的文本数据和非文本数据,来对用户的个性进行分类分析的数据挖掘系统。本文的组织如下:第2节介绍了本文中采用的个性分类指标—迈尔斯-布里格斯个性分类指标;第3节介绍了对用户个性进行分类分析的系统结构;第4节是关于数据样本的采集方式;第5节描述了微博数据的特征提取;第6节主要是关于个性分类分析的机器学习模型;第7节分析了系统的分类分析结果,最后是结论以及将来进一步要做的工作。
2 迈尔斯-布里格斯个性分类指标
迈尔斯-布里格斯个性分类指标MBTI(Myers-Briggs Type Indicator)[7]是个性分类理论模型的一种,经过五十多年的发展,MBTI现已成为全球著名的个性测试之一,在教育界、雇员招聘及培训、领袖训练及个人发展等领域均有广泛的应用[8,9],据估计在中国的外资企业中,80%以上利用这种个性分类指标来辅助个人的职业规划发展。MBTI将人的个性用四个维度来表示,每个维度又通过一个对立面来呈现,使用户位于每一维度上的具体个性都可以归结为一个二值分类问题。这四个维度表征的个性方面以及其对立面如表1所示。
(1)EI维度。该维度用以表示个体心理能量的获得途径和与外界相互作用的程度,即个体的注意力是较多地指向于外部的客观环境还是内部的概念建构和思想观念,通过字母E(外倾)和I(内倾)表示。外倾型个体经常先行动后思考,而内倾型个体经常耽于思考而缺乏行动。
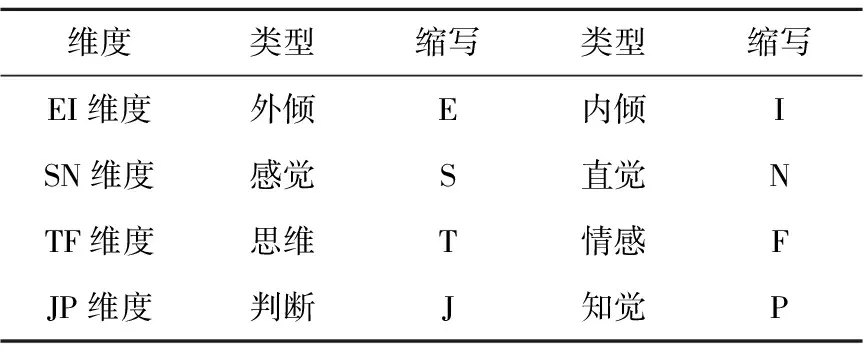
Table 1 MBTI personality indication
(2)SN维度。该维度又称之为非理性维度或知觉维度,表示个体在收集信息时注意的指向。即倾向于通过各种感官去注意现实的、直接的、实际的、可观察的事件,还是对事件将来的各种可能性和事件背后隐含的意义及符号和理论感兴趣,通过S(感觉)和N(直觉)表示。感觉型的个体被视为较具有实际意识,而直觉型个体被视为较有改革意识。
(3)TF维度。该维度又称之为理性维度或判断维度。该维度用于表示个体在作决定时采用的方法,是客观的逻辑推理还是主观的情感和价值,通过字母T(思维)和F(情感)表示。情感型的个体期望自己的情感与他人保持一致,其理性判断的依据是个人的价值观。而思维型的个体通过对情境作客观的、非个人的逻辑分析来做决定,他们注重因果关系并寻求事实的客观尺度,因此较少受个人感情的影响。
(4)JP维度。该维度用以描述个体的生活方式。即倾向于以一种较固定的方式生活还是以一种更自然的方式生活,通过字母J(判断)和P(知觉)表示。判断型个体倾向于以一种有序的、有计划的方式对其生活加以控制,他们期望看到问题被解决,习惯于并喜欢做决定。而知觉型个体偏好于知觉经验,他们不断地收集信息以使其生活保持弹性和自然。
根据人在MBTI的四个维度对立面上的偏好,可将所有人的个性分为16个种类,并取每个维度偏好上的字母来表示,比如内倾直觉思维知觉的个性类型以INTP表示,他的个性特点可以概括为对于自己感兴趣的任何事物都寻求找到合理的解释,喜欢理论性的和抽象的事物,热衷于思考而非社交活动,安静、内向、灵活、适应力强,对于自己感兴趣的领域有超凡的集中精力深度解决问题的能力。
MBTI的个性分析结果最主要的应用是反映个体相对稳定的职业倾向,有助于个体对自己的职业进行规划,每种个性类型都给出了常见的职业类型推荐,其他方面也助于提高个体对自己的认识,促进沟通,改善人际关系以及提高工作效率。
3 基于微博的用户个性分类分析系统结构
我们的目的在于使系统能够根据微博用户的微博文本和其他的微博特征,比如其在微博内的社交行为,自动分类该用户的MBTI的四个个性维度的归属。为了对微博用户的MBTI个性特征进行分类和测试,首先需要设计一组能够反映用户个性的微博特征——微博用户的个性特征空间。依据这一个性特征空间,每个微博用户的信息可以通过其包含的特征及数量来表示。当给定若干预先分类的微博用户(训练样本),个性分类模型(分类器)可以训练出来,并可利用其对MBTI个性未知的微博用户进行分类。
我们采用的面向微博用户的个性分类系统流程图如图1所示,该系统主要分为两大部分,第一部分是实现对个性模型的训练,第二部分利用训练的分类模型对新用户进行个性分类分析。其具体流程可以分为以下几个步骤:
(1)采集微博用户样本,其中包括微博用户的微博ID、微博名称以及该用户的MBTI的四维标识。
(2)获取微博用户的微博数据,包括微博用户的微博文本内容,也包括微博用户其他的非文本信息。
(3)对每个微博用户,自动完成特征提取,提取的特征包括文本特征,也包括非文本特征。对提取的特征最后还需要做规范化处理。
(4)建立和训练个性分类模型,涉及到选择合适的分类算法及其参数,以及对模型的交叉验证。
(5)对个性未知用户进行个性分类,即将训练的分类算法应用到MBTI值未知的微博用户。
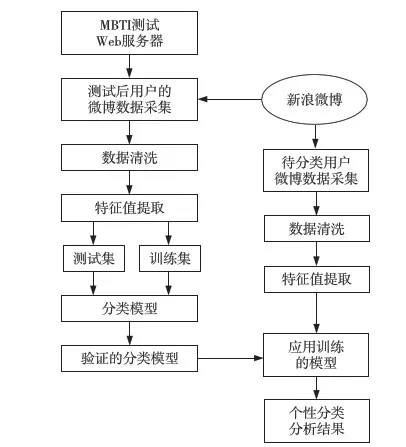
Figure 1 System flowchart of MBTI personality classification图1 MBTI个性分类的系统流程图
4 采集数据样本
为了采集微博用户的样本,我们建立一个用于进行个性测试的Web服务器,用户进入该Web服务器的主页面,可以看到48道选择题的MBTI个性测试题。当用户回答完48道题后,该Web服务器会根据用户的选择,计算用户的MBTI值并反馈给用户,同时会请求用户输入其微博账号。然后服务器的后台会通过新浪微博接口验证该账号是否存在,如果验证通过,服务器就会将该用户的MBTI值和相应的微博账号作为一个用户样本保留下来。部分样本及其格式如图2所示,其中第一列是样本用户的微博ID,第二列为样本用户的微博帐号,第三列是Web服务器根据测试题结果判定的样本用户的MBTI个性测试结果,最后一列是样本用户的测试时间。利用这一Web服务器,在三个月的时间内一共得到了900多个有效的微博用户样本。
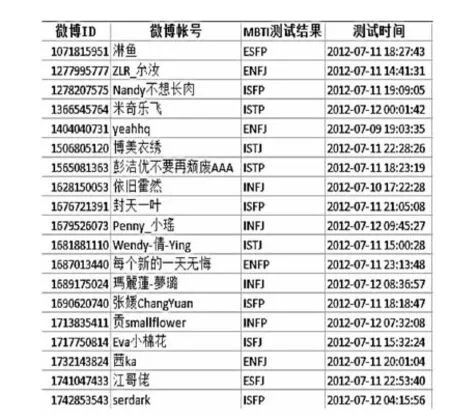
Figure 2 Example of collected micro-blog user samples图2 采集的微博用户样本示例
然后根据这些样本中的微博账号,系统从新浪微博中读取样本用户最新的200条微博,如果用户的微博数量不足200条,则所有的微博内容都将被读取过来。另外,还需要读取这些用户微博的状态(Statuses)信息,其中包括了该微博用户与其他用户的交互关系信息,比如:粉丝数、关注数、评论数等。
5 用户的微博特征集选择
一个用户的微博可以用两方面的特征来表征,一种是微博的文本中包含的文本特征,它代表了微博用户通过语言来表达自己的特征;另外一种是微博中包含的非文本的行为特征,它更多地表示了该用户与其他用户的交互信息,这两部分特征都有助于体现一个用户的个性特点。另外,一个用户转发的微博内容因为没有表达该用户的主观意愿,而被认为与该用户的个性无关,所以处理该用户的微博信息时,这部分转发别人的微博的文本内容首先被清洗掉。但是,该用户转发别人微博的数量是他与别的微博用户交互的一个重要衡量指标,这个信息是作为该用户微博的一个重要的非文本特征。概括起来,一个微博用户的非文本的行为特征包括:
(1)平均微博长度,即一个用户所有微博包含的字符数的均值。
(2)平均HashTag数量, 即微博中出现“#topic#”的平均数量,两个“#”之间的内容表示一个主题或者一个特定事件。
(3)平均链接数量, 微博中包含的超文本链接的数量,微博的浏览者可以通过点击该链接进入Internet的其他位置。
(4)平均提到其他微博用户的数量,微博中提到其他用户时,在用户名前加“@”来表示。
(5)该微博用户的跟随者(Follower)的数量,代表了对给定用户微博感兴趣的其他用户的数量。
(6)该微博用户跟随(Follow)别人的数量,表明引起该用户兴趣的其他微博用户的数量。
(7)该用户平均每天发表的微博数量,不包含日均转发别人微博的数量。
(8)该微博用户平均每天转发别人微博的数量。
(9)该微博用户平均每天回答别人微博的数量。
以上微博用户非文本方面的特征一部分可以通过该用户微博的状态(Status)信息获取,另外一部分需要根据该微博用户的微博属性通过统计计算得到。
文本语言是人类以他人能够理解的最普通和最可靠的用来表达内心想法和情绪的方式,为了提取微博文本中的特征,我们用中文语言查询和词频计算C-LIWC(Chinese-Linguistic Inquiry and Word Count)[10]词库来对微博的用词类别及频率特性进行统计。语言查询和词频计算LIWC(Linguistic Inquiry and Word Count)[7]是进行英文有关个性或情感分析时,应用广泛的一个文本分析工具。该工具从社会学和心理学的角度对语言的使用模式进行分类,其中包含了语法语用方面的用词分类,也包含了情绪、认知、社交、感知等的分类。例如个性外向的人相对于个性内向的人来讲,更有可能使用长充短的词,因为短而简练的词语中会表达更多的社交积极因素[4]。
C-LIWC[11]是台湾中央研究院在英文LIWC2007的基础上,通过翻译并结合中文语言语法特点整理加工而成的,其中包括中文语法特性30类、心理特性42类,共有72类,总计6 862个中文词,这六千多个词在中文最常用的1 000词中检测率为83.5%,最常用的2 000词中检测率为76.2%,因此对于常用的词语具有相当不错的检测率,图3是C-LIWC的中文词分类的例子,其中词后面的数字表示该词所属的类别,比如19表示否定词的类别,125代表感情词汇类别。

Figure 3 An example of C-LIWC categories for Chinese words图3 C-LIWC的中文词分类示例
中文处理相对于英文处理的一个重要不同在于需要进行分词,为了利用C-LIWC中的词语分类模式,我们先将C-LIWC中包含的中文词加入中科院的开源汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)的用户词典中;然后利用ICTCLAS对用户的微博进行分词并计算分完词后的C-LIWC每个类别的词频的数量。
通过提出以上所述的用户微博中的非文本特征和文本特征,每个微博用户经过特征提取可以通过一个81维的特征向量来表示。由于不同用户的微博数量不同,需要对不同用户特征值进行规范化计算,使所有的特征值处于0~1,式(1)是采用的规范化计算公式。
(1)
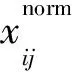
6 个性分类模型
为了对微博用户的个性进行分类,我们采用三种分类模型进行分类分析比较:提升决策树(Adaboost Decision Tree)、贝叶斯逻辑递归(Bayesian Logistic Regression)[12]和支持向量机(Support Vector Machine)[13]。针对每个分类模型和微博用户,采用了四个二项分类器来实现个性的分类。假设xi是训练样本集合中的一个微博用户特征值组合,且xi可以表示为d维向量:xi=[xi1,xi2,…,xid]T, yi∈{+1,-1}是具体的个性分类结果标注,分别对应MBTI个性分类模型的四个维度中的某一个个性标注结果,这三种分类模型可以概括如下。
6.1 提升决策树
决策树是基于信息增益测量形成的流程图式样的树结构分类方法,在许多领域得到广泛的应用[14]。在决策树中,每个特征表示为树的一个内部节点,每次分类测试表示为树的一个分支,分类的结果最后表示为树的终端节点。给定一组特征属性,从决策树的树根到终端节点的路径表示了分类的依据。在微博用户高可变特征的情况下,决策树会带来严重的过度拟合问题,为了克服这一现象,我们采纳提升技术-Adaboost作为决策树的组合学习方法。当Adaboost与决策树组合用于分类问题时,给定一个训练数据,求一个比较粗糙的分类器(即弱分类器)要比求一个精确的分类器(即强分类器)容易得多。提升方法就是从弱分类器出发,通过提高被错误分类的样本的权值,反复学习,得到一系列弱分类器,然后组合这些弱分类器,构成一个强分类器。提升决策树的基本步骤可以概括为:
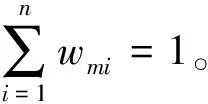
(2) 在后面的m=1,2,…,M次迭代过程中,使用具有权值分布Dm的训练数据集进行决策树学习,分别得到第m次递归的决策树弱分类模型Gm(x)→{+1,-1},并计算Gm(x)在训练数据集上的分类误差率和Gm(x)的系数,分别如式(2)和式(3)所示。
(2)
(3)
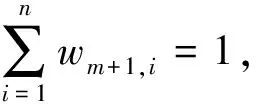
(4)
(5)
(4)当训练完M个基本的弱决策树分类器,进一步对其进行线性组合,形成式(6)所示最终的决策树分类器。
(6)
6.2 贝叶斯逻辑递归
逻辑递归是线性递归基础上的一种变化形式,适用于在一组独立的特征变量基础上进行分类预测,并且分类预测结果为二项输出。当给定一组特征的向量,逻辑递归模型通过式(7)对属于类yi的概率进行估计:
P(yi=+ 1|ω,xi) = ψ(ωTxi)
(7)
其中xi是训练样本集合D={(x1,y1)},(x2,y2)},…,(xn,yn)}中的一个微博用户特征值组合,式(7)中的逻辑链接函数通过式(8)表示:
(8)
公式(7)估计的概率通过与预先设定好的门限值进行比较来确定预报结果的所在类。例如,当P(yi=+ 1|ω,xi)>Threshold时,分类结果为y=+1,否则,y=-1,在本文中,该门限值设定为0.5。
为了克服逻辑递归可能引入的过度拟合问题,我们通过贝叶斯方法对ω提供一个均值为0、方差为σj的先验分布:
P(ωi|σj) =N(0,σj)
(9)
进一步设定σj的概率密度函数为式(10)所示的指数分布:
(10)
式(9)和式(10)经积分得到如式(11)所示的双指数(拉普拉斯)分布:
(11)
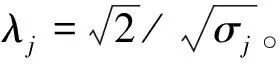
不失一般性,假设ω的元素相互独立,则ω的先验概率可以表示为:
(12)
根据贝叶斯理论,则ω的后验概率可以通过式(13)表示:
L(ω)=P(ω|D)∝P(D|ω)P(ω)=
(13)
两边取对数并忽略其中的归一化常数,得到:
(14)
通过式(14),ω可以通过最小化-l(ω)获得。因为-l(ω)是凸函数,ω可以通过各种优化算法获得。在我们的实现中采用了一种一维优化算法——CLG方法[13],在一次循环中更新所有的ωj(j=1,2,…,d),当更新ωj时,先对所有ωk(j≠k)进行固定,然后经多次循环直到ω收敛。
6.3 支持向量机(SVM)
支持向量机[15]同时能够支持线性或者非线性分类,并能够处理高维输入。在给定训练样本集合时,当作为一个线性分类器,如果输入的两个类是线性可分的,SVM通过搜索最优的线性分离超平面来实现分类的最优化,即通过式(15)的优化问题计算得到最优的加权向量ω*:
且yi(ω·xi-b)≥1
(15)
对于线性不可分的情况,SVM通过引入松弛变量ξ来建立软分界,而这时的目标函数需要增加一个函数来补偿非零值的ξi,如果该补偿函数是线性的,优化问题就变成如式(16)所示:
且yi(ω*·φ(xi)-b)≤1-ξi,ξi≥0
(16)
其中,C是分错项的惩罚因子。另外,还需要用核函数将特征空间X映射到高维空间φ(X),然后在这高维空间内,SVM搜索计算最大边距分离超平面。应用最广泛的核函数包括线性、多项式、径向基函数和S函数(Sigmoid函数),在对微博用户进行个性分类分析时,我们发现当核函数采用径向基函数时,能够输出比较优良的分类性能,如式(17)所示。
(17)
7 实验结果分析
对于MBTI的四维个性问题,我们采用的相应的输出分类标注,如表2所示,然后利用上面所述的分类分析模型,在开源的数据挖掘软件Weka(WaikatoEnvironmentforKnowledgeAnalysis)[15]中采用如图4所示的10倍交叉验证流程来对分类模型的性能进行评测分析。

Table 2 Classification result indicationof different MBTI personality dimension
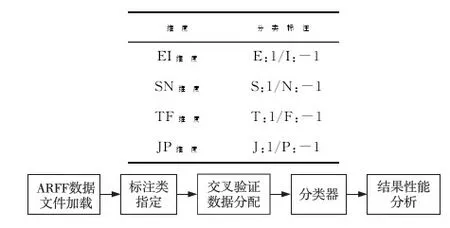
Figure 4 Cross-validation flowchart for personality classification prediction图4 个性分类的交叉验证流程
图4的交叉验证流程的各部分功能包括加载含有微博特征的ARFF数据文档,指定数据中的类标注项,实现数据的训练集和验证集的分配,采用SVM或贝叶斯逻辑递归构建的分类器模型,以及最后的分类性能结果输出和分析模块。
交叉验证的结果如图5和图6所示。图5表示不同样本数量对三种分类器的性能影响情况,随着微博用户样本数量的增加,三种分类器的性能都有所提高,而样本数量对提升决策树的影响要高于其他两种分类方法,而且支持向量机的分类效果在不同样本数量等级上,都要优于提升决策树和贝叶斯逻辑递归。
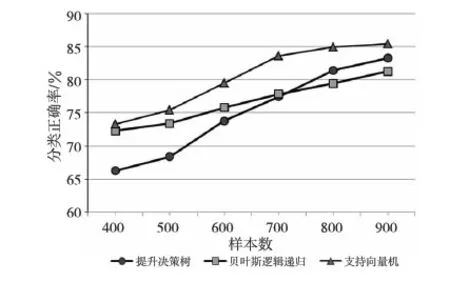
Figure 5 Influence of sample number on two classification models图5 样本数量对两种分类模型性能的影响
图6表示采用900个微博用户样本,分别采用这三种分类器模型在四个个性维度上的分类正确度结果。从图6中可以看出,支持向量机在MBTI四个个性维度上的分类正确率都要优于贝叶斯逻辑递归和提升决策树的分类模型。另外,对于不同的MBTI个性维度输出结果,TF维度上的个性分类结果最准确,三种分类器的分类准确度都超过85%;其次是EI维度和JP维度,前者的支持向量机和提升决策树的分类准确度都超过85%,而贝叶斯逻辑递归的分类准确度也趋近于85%;分类结果最差的是SN维度,三种分类器的分类准确度都在75%~80%。这种不同维度的分类准确率的差异主要来自于不同维度表达的个性角度不同,通过微博的特征,尤其是通过微博的文本特征所能够表征的清晰度不同。对于TF维度,表达的是做决定时依赖的是感情还是逻辑,文本中表达情感和因果的词汇的多寡直接决定了该维度个性的分类清晰度,也就决定了个性分类的准确度,所以分类的准确度较高。而对于SN维度,主要表达了人类认识世界的方式,即人如何处理接收的外界知识,属于对外界的信息的吸收方式,不容易通过文本和语言表达出来,因此分类的准确度最低。EI和JP维度都包含了一些人与外界的交互,以及个人态度的表达,但又不能向FT维度那样清晰地通过文本表征,因此它们的分类准确度要低于FT维度,而高于SN维度。
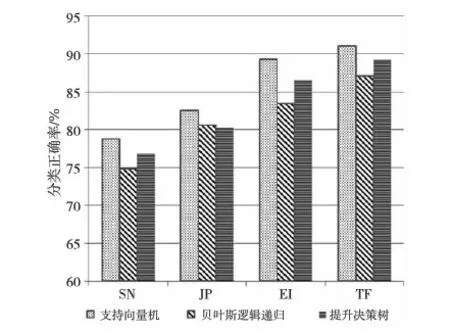
Figure 6 Performance of two classification models on different MBTI dimensions图6 两种分类器在MBTI不同维度上的性能结果
8 结束语
迈尔斯-布里格斯个性分类指标(MBTI)作为重要的个性理论分类模型,已成为重要的个人职业规划发展的辅助工具。论文在传统MBTI基于测试题的个性测评基础上,提出了通过分析微博用户的微博数据——包括文本数据和非文本数据,利用机器学习中的分类分析模型实现用户的MBTI的个性分类分析方法。实验结果表明,采用上述的微博特征和分类算法可以实现理想的个性分析准确度。微博用户样本的数量会对个性分类模型的性能产生影响,其中对提升决策树模型的影响最大,另外由于MBTI的不同维度表示的个性角度不同,通过微博信息表露出的强弱也有差异,带来分类分析模型在不同MBTI维度上的性能差异。当然用户的个性特征和其在社交网络上的行为及留下的文字之间的关联还需要从心理学上进一步分析;另外,用户内容的语义、线上行为与线下实际本体的关联还需要我们做大量的研究工作。
[1] Business war between Weibo and Weixin is started[EB/OL].[2013-08-06].http://news.sina.com.cn/o/2013-08-06/150927877611.shtml.(in Chinese)
[2] Barker G, Wright H F. One boy’s day:A specimen record of behavior [M]. New York:Harper and Brothers Publishers, 1966.
[3] Gosling S D, Ko S J,Mannarelli T. et al. A room with a cue:Personality judgments based on offices and bedrooms [J]. Journal of Personality and Social Psychology, 2002, 82(3):379-398.
[4] Mehl M R, Gosling S D, Pennebaker J W. Personality in its natural habitat:Manifestations and implicit folk theories of personality in daily life [J]. Journal of Personality and Social Psychology, 2006, 90(5):862-877.
[5] Golbeck J, Robles C, Turner K. Predicting personality with social media [C]∥Proc of the 29th ACM Conference on Human Factors in Computing Systems (CHI), 2011:253-262.
[6] Peng F, Schuurmans D, Keselj V. Automated authorship attribution with character level language models [C]∥Proc of the 10th Conference of the European Chapter of the Association for Computational Linguistics, 2003:1.
[7] Myers-briggs type indicator[EB/OL].[2013-08-06].http://en.wikipedia.org/wiki/Myers-Briggs_Type_Indicator.
[8] Cohen Y,Ornoy H,Keren B.MBTI personality types of project managers and their success:A field survey [J]. Project Management Journal, 2013, 44(7):78-87.
[9] Chang Luo. The application of MBTI theory in hiring sales staffs [C]∥Proc of the 19th International Conference on Industrial Engineering and Engineering Management, 2013:703-709.
[10] LIWC:linguistic inquiry and word count[EB/OL].[2013-08-06].http://www.liwc.net/liwcdescription.php.
[11] C-LIWC [EB/OL]. [2013-08-10]. https://sites.google.com/site/taiwanliwc/home.
[12] Barber D. Bayesian reasoning and machine learning [M]. Cambridge:Cambridge University Press,2012.
[13] Genkin A, Lewis D. Large-scale Bayesian logistic regression for text categorization [J].Technometrics, 2006, 49(3):291-304.
[14] Safavian R, Landgrebe D. A survey of decision tree classifier methodology [J]. IEEE Transactions on Systems, Man and Cybernetics, 1991, 3(5):660-674.
[15] Cortes C, Vapnik V. Support-vector network[J]. Machine Learning, 1995, 20(3):273-297.
[16] Weka 3:Data mining software in Java.[EB/OL].[2013-08-01].http://www.cs.waikato.ac.nz/ml/weka/.
附中文参考文献:
[1] 微博微信商业大战烽烟起[EB/OL].[2013-08-06].http://news.sina.com.cn/o/2013-08-06/150927877611.shtml.
猜你喜欢
中华诗词(2019年7期)2019-11-25 01:43:00
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
灯与照明(2016年4期)2016-06-05 09:01:45
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:24
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
