
一种无线网络优化中挖掘LTE小区场景突变的方法研究
2015-07-03 09:43沈骜王西点徐晶王磊
电信工程技术与标准化 2015年5期
沈骜,王西点,徐晶,王磊
(中国移动通信集团设计院有限公司,北京 100080)
1 引言
为了提高网络资源利用率,需要对无线通信LTE小区进行场景划分。根据目前场景划分方法,小区场景一旦划分确认后,同一个场景中小区的无线参数,基本采用相同的配置方法,属性值保持一致,不会再对同一个场景中小区参数做过多调整。
而现网中,由于各种原因,LTE小区场景会发生突变。某些小区话务密度可能突然发生较大变化,或者频率资源突然变得紧张,各种突发原因导致网络质量受到影响,小区不再适用某一场景的配置,这种情况就是场景突变。
由于场景突变,原有场景配置不再适合小区现状,需要对小区场景进行调整。如果未及时对场景和小区相关属性进行调整,网络性能可能会受到严重影响,导致用户感知度下降。
随着LTE网络建设的开展,急需一种好的方法,能够及时发现小区场景的突变,通过调整小区场景,更好为LTE无线网络优化服务。
2 现有研究方法分析
2.1 现有方法的优劣势
现有方法中,小区场景划分一般在小区建设规划初期和网络优化前期就已经设定好,这种方法大多基于经验,故有一定的普遍性和适用价值,该方法在LTE建网初期可用于大部分小区,节省了一定的人力物力成本。
但随着网络建设的日趋完善和复杂,需要在多网间进行网络优化,比如LTE与2G、3G网络间互操作,CSFB等;同时,由于业务量,需求等的变化,小区所处的场景很有可能发生变化。如果不对其进行调整,将会严重影响网络性能与质量。
从现网来看,小区场景发生突变到最终出现严重网络质量问题是一个时间积累的过程,说明小区场景已经突变了一段时间,却没有及时做出场景调整。
2.2 现有方法的主要缺陷
传统发现小区场景突变的方法多依赖于专家的经验,难度较大。发现场景突变的技术和方法较少,一般是问题出现了一段时间,发生告警,严重网络问题或收到投诉后,才会由优化人员实施小区场景调整,重新划分场景。这种方法不及时,问题上报说明网络问题已经比较严重了,用户感知度已经受到较大影响。同时,这种方法治标不治本,处理问题处于被动,不是主动发现并及时解决问题。
造成这种问题的主要原因有两点。一是和场景突变相关的因素太多,包括各类指标,参数和相关属性等。比如测量性能,保持性,接入性等指标;最大重发次数,小区重选偏移等无线参数。单独分析某些指标或者参数,无法发现指标与参数间关联关系,无法获知小区场景突变的原因。即使发现了场景突变,也可能并不清楚是指标或者参数或者其他因素导致。二是数据的选择大多局限于一天内的某些特定指标或参数,未进行多维度对比分析,无法准确发现小区场景变化的原因,没有太多借鉴价值,不适合推广。已提出的利用数据挖掘算法发现小区场景突变的技术存在类似不足,其缺点主要集中在以下3点:
(1) 问题发现和解决效果滞后,场景突变一段时间后,小区网络质量受到影响时才进行场景调整。
(2) 受到人为影响,依赖优化人员的经验。如果优化人员经验不足,可能无法及时发现小区突变;或者对问题原因不清楚。
(3) 数据分析相关属性维度选取不充分,无法进行较精准的分析。进行数据挖掘分析时,一般针对当天数据,未能从多维度进行分析比较。同时,选取的属性单一,要么是指标,要么是参数。没有综合各类指标参数进行统一分析,属性维度选取不足。
还没有一种好的方法,能够及时发现小区场景的突变。
3 小区场景突变的方法研究
本论文涉及的方法主要从数据挖掘角度来分析,通过获取不同场景下,包含不同维度属性的小区数据,筛选过滤出场景突变的小区数据集。分析确认是否由于某些性能指标或者参数原因而导致的小区场景突变,最终挖掘得到发生场景突变的小区。
3.1 步骤及流程
具体步骤为:
(1) 确定要分析的聚簇场景的目标属性及与该属性相关指标和参数。从相关平台上获取相关指标和参数的数据,得到无冗余的数据集合。
(2) 对数据进行聚簇分类。利用步骤(1)中获取的指标和参数数据,采用聚簇分类算法,对数据进行聚簇分类,得到不同的聚簇场景。
(3) 针对每一个聚簇场景进行排序,筛选。过滤不合格小区或者未发生场景突变的小区,得到可能发生场景突变的小区。
(4) 分析上一步骤中得到的小区,区分是否由于某个性能指标或者参数原因导致的小区场景突变,删除无法确认的情况。记录由于某指标或参数原因导致的场景突变情况,通知给相关人员调整小区场景配置。
3.2 确定目标属性及关联属性
首先确定要分析的聚簇场景的目标属性及与该属性相关指标和参数。从相关平台上获取相关指标和参数的数据,得到无冗余的数据集合。
3.2.1 目标属性确认
场景的划分一般针对某些属性,比如话务量,覆盖性,接入性,保持性等。首先选定要分析的目标属性,然后确定与该属性相关的指标和参数。筛选出与该属性关联度较大,影响较大的指标和参数。属性中还包括时间属性。
3.2.2 关联数据获取
获取与目标属性相关指标和参数的数据。连续一段时间内,每天定时从数据平台或OMC上,获取与目标属性相关的指标和参数的数据。提取无冗余的特征属性数据集合。通过ENODEBID+CELLID/ENODEBID+CELLID关联指标和参数。
3.3 场景划分及研究分析
假设要分析某个小区目标属性,通过步骤(1)中获取到的相关指标和参数等属性的数据。属性记为a,共获取y类属性,记为{a1, a2,…ay}。
假设选择X个小区进行分析,每个小区包含y类属性。数据选取样本天数为T天的小区相关数据,比如每天的数据选择小区某天的六忙时(具有代表性)。一共有X×T条数据记录,每条记录即一个小区某天的指标和参数,每天记录包含y类属性,每个小区均有T条数据记录。记为数据集Dorin。
采用算法进行聚簇分析,可将小区分为多个聚簇场景。通过聚簇分类,y类属性中具有相同或者相似值的小区被分配到某一个场景中。处理之后的数据集和处理前相比,增加了一列属性名为class,为标识该小区属于某类场景。场景记为Z,假设分为P类场景,每个场景的数据条数记为z1, z2,…zp。每个场景的数据条数可能均不同,即z1, z2,…zp的个数可能均不同,且z1+ z2+…+zp=X×T。
即

3.3.1 场景数据分析
将小区数据按照时间维度排序。循环遍历所有场景,检查每个场景中不同小区的数据条数是否相等;同一个小区的数据记录条数是否等于样本天数。
将所有小区按照聚簇分类后的场景进行排序,每一个场景中小区个数不尽相同。理论上,如果某小区在一段时间内未发生场景突变,其性能,参数没有变化,则若该小区某天的数据已经划分到某个聚簇场景中,那么该小区其他天的数据,经过聚簇分类后,也应该分配到该聚簇场景中。注意:ENODEBID+CELLID值不同的小区,定义为一个不同的小区,如果出现ENODEBID+CELLID相同的情况,为该小区在不同时间的数据记录。
如果某个小区在场景设定后,性能指标,参数等属性没有发生变化,则该小区在T天内的每一条数据理应属于同一个场景。即一旦发现某个小区在T天数据中的某一天的数据属于某个聚簇场景,则该小区在其他T-1天理论上应该属于同一个场景,在该场景中应该有某小区的T条数据记录。假设小区属于第i类场景(1≤i≤P),该场景中小区数据条数为Zi,则Zi= T×Ri,Ri为不重复的小区个数(以每个场景中,不重复的ENODEBID+CELLID记为一个不重复小区),且 Ri理论上应为整数,Zi为T的整数倍。
但检查实际情况,Zi却不是T的整数倍。大部分小区,相同ENODEBID+CELLID的小区,均能在i类场景的Zi条数据中找到该小区的T条数据;少部分小区无法找到T条数据,有的可能只能找到一天的数据记录,原因就是小区聚簇场景可能发生了突变。
3.3.2 场景数据筛选
循环遍历场景,获得所有场景中,数据条数小于样本天数的小区数据集。
针对P类场景中每一个聚簇场景,循环遍历每一个场景,按照同一个ENODEBID+CELLID的小区进行排序,针对每个ENODEBID+CELLID相同的小区,找出其数据条数少于T条的小区。如场景i中,数据条数为Zi,有Ri个不重复小区。最终找到Ri-Si个数据条数等于T的小区。Si个数据条数少于T的小区,这些小区共有数据条数为。公式为:

根据上述公式,获取每个场景中的(1≤i≤P),得到P个基于聚簇场景的新的数据集,该数据集与初始X×T条数据集相比,多了一列聚簇场景属性。同时,对于每一个聚簇场景,少了(Ri-Si)×T条小区数据,只有条数据,对应Si个小区。
则经过筛选排序之后的数据集,记为Dfilter。共有数据条数为

该数据集为小区场景突变数据集,每个小区在T天内的数据可能属于2个或多个class场景。不同class属性的值不相同。
3.3.3 场景数据过滤
利用ENODEBID+CELLID进行过滤后,每个不同ENODEBID+CELLID的小区理论上也应该有T条数据,只是属于不同的聚簇,其class属性的值不一样。但检查Dfilter数据集,仍然有部分小区的数据条数小于T。这是由于在采集样本时间范围内,小区首次入网或者在数据采集时间范围内,发生退网情况;或者某天数据没有上报。这种外在因素导致的数据条数少于T的情况,没有参考价值,需要删除这类小区。剩下的所有小区,每个小区均有T条数据记录。对应T天的数据。最终得到数据集,记为Dfinal。
此时可对剩下的数据进行分析挖掘。
3.4 场景突变判定
3.4.1 场景挖掘分析
计算每个小区的每一列属性在所有样本中的标准差;计算每个属性与其标准差的偏差,获取偏差较大,且符合判别标准的属性所对应小区当天的数据记录。
利用Dfinal,按照ENODEBID+CELLID进行排序。对于同ENODEBID+CELLID,但属于不同场景的小区,查找每一条数据的聚簇场景class。
对于同一个小区,假设某个小区的T天数据分到m个聚簇场景中(1 m个场景中,有的场景可能只有一条数据,有的场景可能有多条数据。 针对小区y个属性中的每一个属性,取T天的值。针对每一个属性在不同天内的不同值,比如每一行的第一列属性作为一组;同理,每一行的第二列属性作为一组,每一行第y列属性也作为一组。分别计算每个属性组的标准差,标准差公式为: (j为天数,1≤j≤T ;n为属性标识, 1≤n≤y,表示属性n在这一组中的算术平均值) 如果出现不符合上述判断的情况,表明针对属性n,该小区第j天的值与其他天相比,波动较大。获取所有不符合上述公式判决的,属性n的该小区第j天数据{。假设有T′天。 一般的,如果某个属性n的值变化范围不大,则基本都符合上述公式判决。如果某个属性在一段时间内,变化差异大,则可能有T′天的数据不符合上述判决。 3.4.2 场景突变判定 获取波动变化最大的属性,若其对应当天的小区数据在某个场景中唯一,则判决其为小区场景突变。 由于不同的聚簇方法采用的算法不同,产生的聚簇场景也不同。可能出现某个小区不同时间天内,部分属性值变化较大或者波动差异较大,却没有发生聚簇突变,仍然属于同一个场景的情况。需要对这种情况进行区分。 对于3.4.1结果中波动变化较大的属性,可能出现 天波动都比较大的情况。针对属性n,对于所有不符合3.4.1中判决公式的数据,取max(。 计算值最大时所对应的j值以及相应的聚簇场景class值。 检查第j天所属场景,若只有一条数据,即该小区的其余T-1条数据分布在其余m-1个场景中。则可认为,由于该属性an在第j天发生大的波动变化,导致某小区第j天的数据发生场景突变。且突变很有可能和该属性关联性相关。可将结果通知网优人员,查明该属性突变的原因,进行现网数据的分析和调整。 图1 小区聚簇分类 图2 小区数据筛选过滤 截取了某省部分小区3天的数据,主要包括标示和部分指标,性能相关属性,利用聚簇分类进行场景划分之后的情况如图1所示。 图中最右边为聚簇类,从图中可以看出,聚簇分类后,出现了同一个小区不同天内划分在不同场景的情况。筛选某一个聚簇类,比如cluster58,筛选结果如图2所示。 从图2中可知,该类下具有两个小区,一个CELLID为10762,它在不同天内都属于cluster58,另外一个CELLID为61016,在该簇下只有一条记录,故该小区可能发生场景突变。检查该小区数据条数是否缺失,如图3所示。 从图3中可知,该小区的数据条数是完整的。利用本章3.3与3.4节的场景突变判定方法,该场景cluster58下的小区,CELLID为61016的小区发生了场景突变。从图中标绿色部分可以看出,该场景下小区的部分指标和性能属性值在之后的时间发生较大偏离。如果仍然按照之前的场景划分方式设置参数值,很有可能导致该小区覆盖区域的指标和性能较差,从而影响用户感知。建议对该小区重新划分场景并设置相关参数值。 本论文提出了一种方法,通过获取包含不同维度属性的小区数据,筛选过滤出场景突变的小区数据集。分析确认是否由于某些性能指标或者参数原因而导致的小区场景突变,最终挖掘得到发生场景突变的小区。 图3 小区场景突变判定 本论文的方法不依赖于网优人员的经验,能够快速定位发生场景突变的小区,网优人员可以及时调整小区所属场景。同时,该方法具有通用性,不论按照何种方式划分场景,只要发生突变,均可利用该方法判决突变小区。 后续将更多需要围绕现网数据开展大量的验证和实践工作,更好的指导现网LTE优化工作。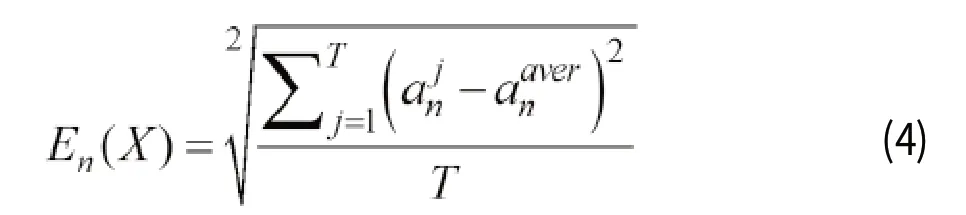



3.5 场景突变示例
4 总结

猜你喜欢
数学物理学报(2022年5期)2022-10-09
民用飞机设计与研究(2020年4期)2021-01-21
计算机应用(2018年12期)2019-01-08
商周刊(2018年26期)2018-12-29
电子制作(2018年18期)2018-11-14
数学小灵通(1-2年级)(2017年12期)2018-01-23
山东工业技术(2016年15期)2016-12-01
非公有制企业党建(2016年1期)2016-07-19
开心素质教育(2016年2期)2016-04-20
读写算·小学低年级(2015年4期)2015-12-04
