
云存储在web3D内容管理系统中的应用
2015-06-24 11:11陈晓波
电脑知识与技术 2015年2期
关键词:云存储
陈晓波
摘要:谷歌公司在2006年推出“Google101计划”,这才真正的有具体化的“云”的概念和相关理论,不少公司都相继推出了自己的云平台。面临未来素材库可能会到来的海量数据,利用云存储可以线性地扩展海量的非活动数据。该文首简述了云平台的基本架构,并对Hadoop分布式存储技术进行了介绍,然后设计了云存储针对小型文件的存储方案,最后进行总结,并对未来的改进提出了建议。
关键词:云存储;Hadoop;分布式存储
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(20015)02-0003-03
Abstract:Google launched "Google101 program" in 2006. This is when truly specific concept of the "cloud" and related theories appear.Many companies have launched their own cloud platform. Facing the possibility of upcoming massive data of the library,cloud storage can linearly extend inactive data mass. This paper firstly outlines the basic architecture of the cloud platform, and introduces Hadoop distributed storage technology , then a program for the cloud storage in small files is designed.Finally a summary and recommendations for future improvements are put forward.
Key words: cloud storage; Hadoop;distributed storage
目前随着移动设备和无线网络的迅速普及,在移动互联网上创建虚拟3D世界变得非常流行,已成为一个新兴数字媒体产业,并显现出巨大的市场潜力和光明的产业化前景。同样,为了推动这一产业的发展,那么集合大量的Web3D素材是极其有必要的。但是,由于Web3D素材的特性,不可避免的包含大量贴图,从而其数据大小不同于文字和普通的图片,级别普遍在十几兆到数十兆之间。随之而来的就是数据的存储和管理问题,存储方面,目前行业中的素材数量没有具体统计,但粗略估算在千万量级甚至以上。数据量庞大,以及数据传输效率的要求,云存储系统是最合适的解决方案。
1 云平台的基础架构
云计算涉及在现有网络上进行分布式计算,借此用户的程序或应用可以同时在一台或多台连接到这个网络的计算机上运行。一个或一组物理存在的计算机通过互联网(Internet)、内网(Intranet)、局域网(local area network)或者广域网(wide area network)连接到一起,作为一个整体以服务器的形式呈现给外界,这样的形式就是云计算的具体表现。任何有权限访问这个服务器的用户可以使用它的计算能力来运行应用、存储数据或者执行其他任务。
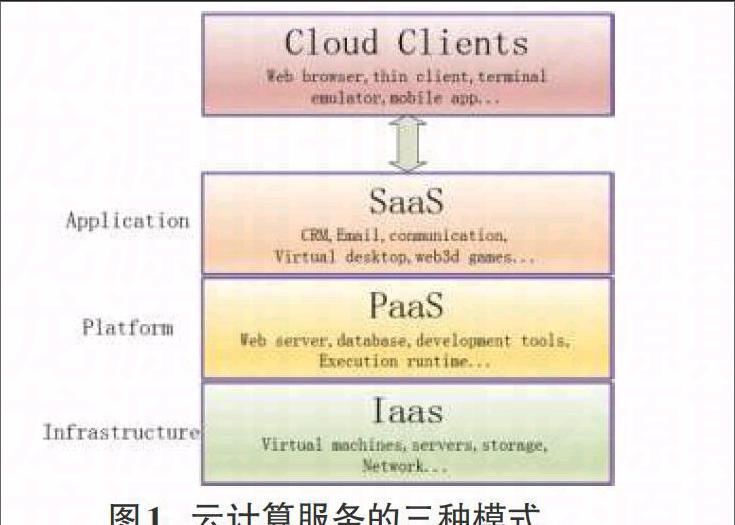
云计算服务的模式主要有三种:基础设施即服务(Infrastructure-as-a-Service, IaaS),平台即服务(Platform-as-a-Service,PaaS)和软件即服务(Software-as-a-Service,SaaS)。其逻辑上的关系见图1。
IaaS,基础设施即服务是最基本的云服务模型,主要功能是将计算机偏底层的资源作为服务提供给用户,其中主要是提供计算机服务,可以根据用户的性能需求进行相应的配置调整,如CPU核数,内存大小,硬盘容量等等。用户通过互联网从这些集群设备中去申请服务。
PaaS是把计算平台(Computing Platform)作为一种服务提供的商业模式。其中,计算平台主要包括操作系统,程序语言执行环境,数据库,Web服务器等平台级产品。
SaaS模型的服务是将应用软件作为服务提供给用户。在这个模型中,运行应用软件所需要的软硬件资源皆由SaaS的提供商管理、维护。
云平台是用来提供各种云计算服务的平台。用户可以在云平台上购买、使用云计算服务,方便用户组合使用云计算服务以达成用户的目标。国外较为知名并具有代表性的有谷歌的云计算平台(Google Cloud Platform),IBM的“智慧云”计算平台(SmartCloud)和Amazon的弹性计算云(Elastic Compute Cloud)。国内也开始推出自己的云平台,比较大的有百度云平台和阿里云平台,为客户提供各类云服务。
2 分布式存储系统Hadoop介绍
Hadoop作为分布式存储系统的典范,是一个能够对大量数据进行分布式处理的软件框架,具有高容错性和高扩展性等优点,允许用户将Hadoop部署到价格低廉的服务器上,实现了将一项任务分发到由多台机器组成的集群上,并有一系列的高容错机制支撑。在具体实现时,开发人员直接搭建,实现整个云平台的管理,而又不需要知道内部机制,这种智能化便捷化的分布式集群对开发人员技术的要求门槛较低。
Hadoop与GoogleGFS几乎一致,因为Hadoop就是根据GFS创造的,包含HDFS、MapReduce、HBase。
2.1 HDFS
HDFS最上层是一个NameNode,下面有许多DataNode,关系像Master和slave一样,所以有时候也称NameNode为Master,DataNode为slave。NameNode对管理文件系统的元数据进行管理。DataNode中存储实际的文件数据。客户端和NameNode进行通信,获取到文件的元数据后,然后直接和DataNode进行文件的I/O操作。
HDFS最常见的部署方法就是将NameNode部署在一台专门的服务器上,在集群中的其他机器上运行一个或多个DataNode;同时也可以在NameNode所在的服务器上运行一个或多个DataNode。采用一个NameNode使整个系统的架构非常简单。
NameNode中会记录HDFS中元数据的变化,采用的是EditLog形式记录。NameNode中使用FsImage来存储文件系统的命名空间,命名空间包括文件与块之间的映射,文件本身的属性等。EditLog和FsImage都存储在Namenode上。
HDFS中为了维持系统的稳定性,还设立了第二个NameNode节点,称作Secondary NameNode节点,它会辅助NameNode处理FsImage和EditLog。NameNode启动时会将EditLog和FsImge合并,而Secondary NameNode会周期性地从NameNode上去复制这些FsImage和EditLog到临时目录中,合并生成新的FsImage后再重新上传到 NameNode,这样当NameNode宕机后,Secondary NameNode还可以继续工作,所保存的FsImage信息还存在。
2.2 HBase
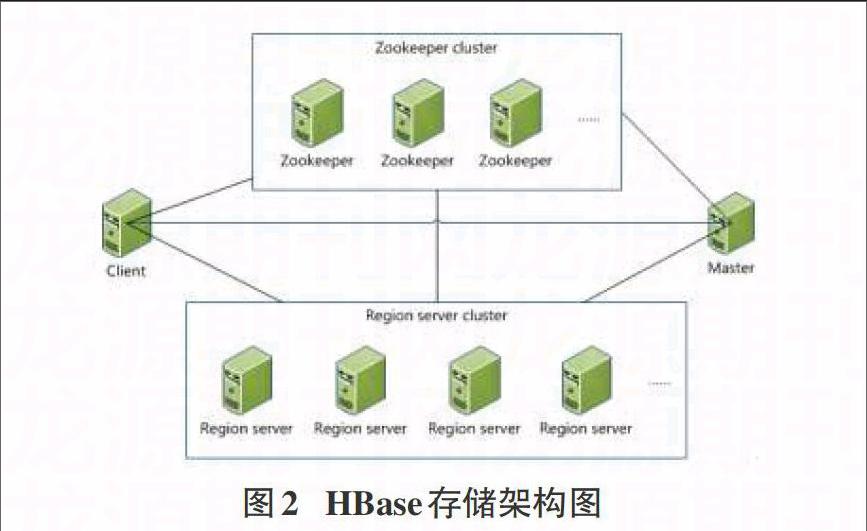
HBase系统在架构层面由一个Master和多个RegionServer组成。如图2所示。
其中,每个RegionServer对应集群中的一个节点,一个RegionServer负责管理多个Region。一张表上有很多数据,每个Region只是一张表上的部分数据,所以在HBase中的一张表可能会需要很多个Region来存储其数据。HBase在对Region进行管理的过程中,会给针对每一个Region划定一个范围,也就是Row Key的一个区间,在这个特定的区间内的数据就交给特定的Region,这样能够保证负载相对均衡,能够分摊到各个节点之上,这也是分布式的特点。此外,HBase也会自动地调节Region所在的位置。如果一个RegionServer变得比较活跃,使用的比较频繁,HBase会把 Region转移到不是很忙的节点,如此集群环境可以被合理使用。
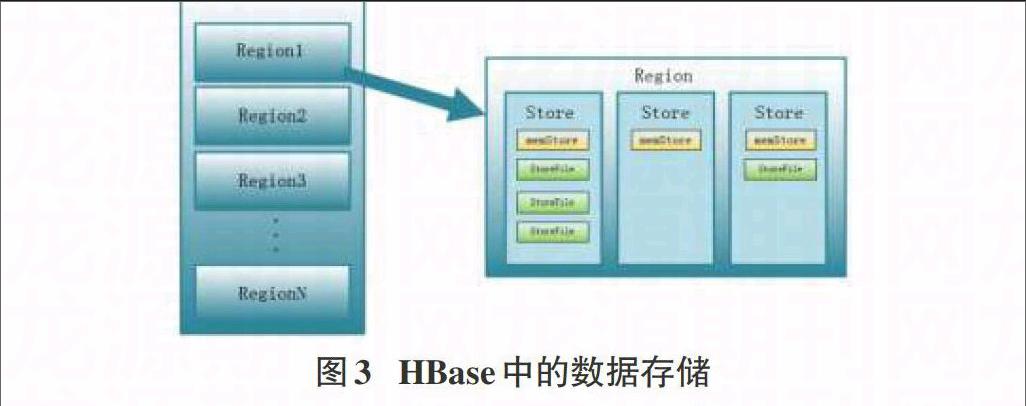
Table在行的方向上划分成多个Region,Region是按照空间来划分的,最初建立Table时,Table内的Region数量只有一个,随着系统的投入使用,Table内开始被不断的插入数据,Region内会不断的存入数据,当数据量达到某个特定的阀值,Region就会等分,变成两个Region。Table是面向列的数据库,行数会不断的增加,HRegion数量也会不断增多。在HBase中,分布式存储的最小单元是HRegion,但是一个HRegion内又有一个或多个store构成。如图3所示:
3 基于HBase的Web3D素材存储设计
3.1 存储系统的整体设计
由于素材本身数据的属性,比如名称、别名、文件类型等,这些信息存储在MySQL中,同时为素材分配一个ID,在HBase存储这个ID信息和一些简单的关系稀疏的文件属性。如图4所示:
3.2 小型素材文件在HDFS上的存储
系统素材文件[19]本身存储在由HBase管理的HDFS中,而HDFS是专门为了大数据存储而设计的,针对Web3D素材普遍是小文件的情况,就采用将素材文件进行合并,形成一个个大文件,然后将这些大文件存储到HDFS中的做法实现小文件的存储。
将素材文件合并后,我们不仅仅是存储进系统,平台本身还需要随时查询这些小文件,所以我们必须建立素材小文件与合并后的块的对应关系。我们在文件名中标注合并后的大块的ID以及块内的偏移量加上文件块内的长度来标记这个文件。
假设素材文件大小为2M,默认的一个块的大小为64M。首先Master会在集群内找到一个空余剩余超过2M的块。假设块的ID为1234,且已经存储了32M的数据,块内的偏移量是通过页来记录的,一页的大小为16k,那么目前32x1024/16=2048,那么素材存储的位置就是从2049开始的,并且2M大小的数据占空间为128页,那么该素材文件标记为(1234,2049,128)。
但是HDFS中的Master部分并没有关于文件和块的映射关系,我们需要在Master中设计这样的查询功能,新系统的架构图如图4所示:
当客户端想要读取某个素材文件时,首先从NameNode中的查询模块,从而获得素材文件与块之间的映射信息。
4 结束语
本文部署了Hadoop集群作为系统的分布式云存储平台,将用户的资料等结构化数据存储在MySQL中,并在MySQL中存储部分关联性强的素材元数据,并且指定ID。将素材本身存入Hadoop集群中,通过小文件打包的形式,改善了Hadoop集群中不适合存储小文件的情况。但是关于系统文件打包机制,存储后的删除问题,仅仅从MySQL中删除了素材文件的源信息,实际的文件还部分残留在系统中,这一点应该对文件与块的关系上继续深化研究下去。
参考文献:
[1] Bhardwaj Sushil, Leena Jain, Sandeep Jain. Cloud computing: A study of infrastructure as a service (IAAS)[J]. International Journal of engineering and information Technology, 2010(2.1): 60-63.
[2] Vaquero, Luis M. A break in the clouds: towards a cloud definition[J]. ACM SIGCOMM Computer Communication Review, 2008,39(1): 50-55.
[3] Cloud, Amazon Elastic Compute. Amazon web services[J]. Retrieved November, 2011(9): 2011.
[4] 黄贤立. NoSQL非关系型数据库的发展及应用初探[J]. 福建电脑, 2010(7): 30.
[5] 黄晓云. 基于HDFS的云存储服务系统研究[D]. 大连: 大连海事大学. 2010.
[6] 余思, 桂小林, 黄汝维. 一种提高云存储中小文件存储效率的方法[J]. 西安交通大学学报:自然科学版, 2011(6): 59-63.
[7] MACKEY G, SEHRI S, WANG Jua. Improving metadata management for small files in HDFS[C]. 2010.
[8] 肖桐. 应用于海量数据处理分析的云计算平台搭建研究[D]. 天津: 天津科技大学, 2013.
[9] Vora M N.Hadoop-HBase for large-scale data[J]. Computer Science and Network Technology(ICCSNT), 2011(1).
[10] Lars George. HBase: The Definitive Guide[M]. O'Reilly Media, 2011.
猜你喜欢
电脑知识与技术(2016年27期)2016-12-15
出版广角(2016年14期)2016-12-13
出版广角(2016年14期)2016-12-13
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年25期)2016-11-16
科学与财富(2016年28期)2016-10-14
