
基于知识话题模型的文本蕴涵识别
2015-06-09 23:45:58盛雅琦冯文贺刘茂福
中文信息学报 2015年6期
任 函,盛雅琦,冯文贺,刘茂福
(1. 湖北工业大学 计算机学院,湖北 武汉 430068;2. 武汉大学 计算机学院,湖北 武汉 430072;3. 武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;4. 武汉大学 湖北省语言与智能信息处理研究基地,湖北 武汉 430072)
基于知识话题模型的文本蕴涵识别
任 函1,4,盛雅琦2,4,冯文贺2,4,刘茂福3,4
(1. 湖北工业大学 计算机学院,湖北 武汉 430068;2. 武汉大学 计算机学院,湖北 武汉 430072;3. 武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;4. 武汉大学 湖北省语言与智能信息处理研究基地,湖北 武汉 430072)
该文分析了现有基于分类策略的文本蕴涵识别方法的问题,并提出了一种基于知识话题模型的文本蕴涵分类识别方法。 其假设是: 文本可看作是语义关系的组合,这些语义关系构成若干话题;若即若文本T蕴涵假设H,说明 T 和 H 具有相似的话题分布,反之说明T 和 H 不具有相似的话题分布。基于此,我们将 T 和 H 的蕴涵识别问题转化为相关话题的生成过程,同时将文本推理知识融入到抽样过程,由此建立一个面向文本蕴涵识别的话题模型。实验结果表明基于知识话题模型在一定程度上改进了文本蕴涵识别系统的性能。
文本蕴涵识别;话题模型;蕴涵分类;推理知识
1 引言
文本蕴涵识别(Recognizing Textual Entailment)是一个判断文本之间推理关系的任务,定义为: 给定一个连贯文本T(Text)和一个假设H(Hypothesis),如果H的意义可以从T的意义中推断出来,那么就认为T蕴涵H(即H是T的推断)[1]。作为一个挑战任务,文本蕴涵识别能够广泛应用于各类自然语言处理应用,例如,自动问答系统、多文档自动摘要、信息抽取、信息检索、机器翻译及自然语言理解(NLU)领域中的机器阅读等[2-3]。
在RTE挑战任务中,文本蕴涵识别问题可以看作是一个标准的二分类问题[4],即将需要识别的“文本—假设”对利用分类器进行分类,若假设与某一句子之间存在蕴涵关系,则归为“蕴涵”(Entailment)类;若不存在蕴涵关系或无法判断两者是否存在蕴涵关系,则归为“不蕴涵”(No Entailment)类。然而,蕴涵和非蕴涵两个类都比较庞杂,实例间的相似性难以保证,它们的区别性特征就不容易确定,所以据此建立的分类器性能不太理想。为改进分类器的性能,可以采取两种方法。第一种方法是利用语义相似度特征(如谓词论元结构)评估蕴涵关系,其假设为: 语义结构重叠度越高,则T和H越有可能描述了相同的语义关系。然而这一假设仅考虑了局部语义关系是否一致,而缺乏总体语义关系的判断能力。并且现有语义分析方法仅能描述非常有限的语义关系(如谓词和相关论元的关系),使得蕴涵识别系统性能难以得到有效提升;第二种方法是引入合适的背景知识,利用这些知识描述从给定文本假设对中获得的推理关系,从而提高推理性能。然而,大多数分类方法的主要策略是相似度比较,难以有效利用外部知识识别可推理的关系。
本文提出一种基于知识话题模型的文本蕴涵识别模型。该模型的假设为: 若两个文本片断具有蕴涵关系,则它们必然拥有相同或相似的话题。我们利用话题模型评估文本片断之间的相关程度,以此作为判断文本片断是否具有蕴涵关系的一个依据。我们利用文本假设对建立LDA模型,并利用多种方法评估文档的话题概率分布的相似性。针对因蕴涵知识缺乏而导致的话题生成错误的问题,我们引入背景知识以改进抽样精度,提高生成话题的性能,从而提高文本语义相关度的评估性能。实验表明,在分别采用话题模型和知识话题模型以后,系统的准确率逐渐提高,说明话题模型与背景知识结合,能够有效改进系统的性能。
本文第二部分简要介绍文本蕴涵相关工作;第三部分介绍知识话题模型;第四部分介绍了基于话题模型的文本蕴涵识别及基于知识话题模型的文本蕴涵识别的实验;第五部分对全文工作进行总结和展望。
2 相关工作
现有的识别文本蕴涵方法主要可以分为三大类:
一、基于分类策略的文本蕴涵识别。该策略将文本蕴涵形式化为一个两类(蕴涵和不蕴涵)或三类(蕴涵、矛盾和未知)的分类问题。根据已标注的训练实例,学习其中的特征并建立分类器。该方法主要抽取蕴涵对(T-H 对)的词汇特征,如词汇对齐特征、基于同义词林语义相似度特征、反义词特征等;句法结构特征,如依存图对齐特征、谓词-论元结构特征等;然后用类似支持向量机分类器进行分类。如基于 FrameNet框架关系的文本蕴涵识别[5],识别矛盾文本[6],用支持向量机和字符串相似识别蕴涵[7],基于事件语义特征的中文文本蕴含识别[8],基于知网的文本推理[9]等。但就分类策略而言,其问题在于蕴涵和非蕴涵两个类都比较庞杂,实例间的相似性难以保证,它们的区别性特征就不容易确定,所以据此建立的分类器性能不太理想。
二、基于转换策略的文本蕴涵识别。主要根据蕴涵规则,或者编辑距离来判断文本蕴涵。如Kouylekov和Magnini[10]在任务RTE-1中应用编辑距离来识别文本蕴涵,Kouylekov[11]等人提出一个基于编辑距离识别文本蕴涵的开源框架Edit Distance Textual Entailment Suite(EDITS)。然而这些编辑操作难以体现语义层面的转换,因此对于比较复杂的语义蕴涵关系难以准确识别;另一类方法利用自动抽取的推理规则来识别文本蕴涵,如复述规则DIRT[12],全局学习蕴涵规则[13],两层模型学习上下文相关推理[14]等。然而,目前规则自动获取的性能还有待提高,其中一个重要的原因就是规则的歧义性。例如,对于推理模板r:“X 打 Y”,以下两条规则都蕴含于它。
r1: X 玩 Y
r2: X 买 Y
当X为“我”,Y为“球”时,r与r1具有推理关系;而当X为“我”,Y为“酱油”时,r与r2具有推理关系。显然,这两个模板所代表的意思完全不同。 出现该问题的原因是动作“打”具有多义性。该问题可以用以下两种方式解决: 一是对蕴涵规则标注更多语义信息,然而目前缺乏相关资源和研究;二是在进行推理时选择合适的规则,然而做到这点并不容易,因为推理规则大多数是句法的转换,不带有语义信息,因此我们很难去判断究竟应该选择哪条规则才能使转换后的意义保持一致。
三、基于深度分析和语义推理策略的文本蕴含识别。这种方法主要是采用传统的逻辑推理、自然逻辑推理、本体推理或语义特征等获得推理知识。其难点在于大量知识往往难以有效获取,没有足够的知识,对于深度推理及分析来说是比较困难的。
3 知识话题模型
本文提出一种基于话题模型的文本蕴涵识别方法,其假设是: 文本可看作是语义关系的组合,这些语义关系构成若干话题。若T能推理出H,说明T和H具有相似的话题分布;反之说明T和H不具有相似的话题分布。基于此,我们将蕴涵识别问题转化为话题的生成过程,由此建立一个面向文本蕴涵识别的话题模型。
另一方面,简单话题模型无法处理词义、句法结构等知识,而文本蕴涵识别需要利用各种外部知识,如词义关系、推理规则等,因此,如何在模型中应用外部推理知识,就成为面向文本蕴涵识别的话题建模的一个重要问题。Rubin等将标签频率作为先验知识应用于话题模型,以改进多文档摘要的性能,并指出先验知识可以提高简单话题模型的性能[15];Chen 提出一种在多领域上进行话题建模的LTM模型,通过在不同领域中抽取各自的话题,对不同领域的话题进行融合,获得多领域之间的关联词汇对,并在Gibbs抽样过程中引入先验知识,来修正抽样结果[16]。受此启发,我们提出了一种基于知识话题模型的文本蕴涵识别方法,在Gibbs抽样过程中引入词义关系和推理规则,以改进抽样结果。
3.1 KLDA模型
知识话题模型(Knowledge-Based Topic Model, KBTM)利用先验知识指导话题建模,为话题生成提供了一种有监督的学习方法,能够在一定程度上改善话题生成的性能[17]。我们对标准LDA话题模型进行修改,称之为KLDA话题模型。其构建算法流程如算法1所示。
KLDA 模型算法流程描述如下: 首先对外部知识库进行知识挖掘,产生算法中所需要的先验知识,即得到一个基于外部知识的词汇关联矩阵E;其次,对于第i(∈[1,N])次 Gibbs 抽样(N为Gibbs抽样的迭代次数),计算在第i-1次Gibbs抽样后话题中的所有单词,得到每个话题中的所有单词;再用之前计算得到的先验知识对 Gibbs 抽样进行修正。
3.2 知识挖掘
文本蕴涵需要用到的外部知识,主要有外部的词语同义词、词语上下位关系、推理关系等。我们使用WordNet词典和蕴涵规则集DIRT计算词汇相关度,并建立词汇关联矩阵。算法描述如下所示。

知识挖掘算法的基本过程如下: 对于词汇表中的每对单词,通过外部资源计算词汇的语义相似度,更新相似度矩阵E。通过该算法,我们可以得到一个基于外部知识库的词义相似度矩阵。
首先给出两个单词的词语相关度的计算公式,定义如式(1)和(2)所示。
公式(1)表明,如果词w和w′相同,则它们的相似度为1,否则利用WordNet和DIRT计算两个词的相似度。若以上条件均不满足,则两个词的相似度为0。avg(Lin(w,w′),DIRT(w,w′))计算方法如式(2)所示。
公式(2)计算的是w,w′在WordNet和DIRT中的平均相似度,#n表示w,w′在知识库出现的个数,若w,w′出现在WordNet和DIRT中,则#n为2;若w,w′在WordNet出现,则#n取值为1;若w或w′未出现在任何资源中,则公式值为0。
Lin(w,w′)计算方法为: 若w和w′属于WordNet,则计算两个词语之间的Leacock-Chodorow相似度[18]。DIRT(w,w′)计算方法为: 若DIRT规则包含w和w′的关系,则认为两个词的DIRT相似度为1,否则为0。例如,对于buy和acquire,存在规则“XbuyY”→“XacquireY”,则认为两个词的DIRT相似度为1。
3.3 Gibbs抽样
KLDA模型中的Gibbs抽样过程利用外部先验知识修正LDA模型抽样的精度问题。其主要的思想是,在抽样过程中,每一个单词w的兴趣抽样分布与需要分配的话题中词语有关。我们可以通过比较单词w与话题中词语的相关度,来衡量单词w是否可以分配到话题桶中。
我们对标准Gibbs抽样公式[19]进行修改,引入先验外部知识,具体公式见式(3)。
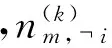

修改后的Gibbs抽样算法基本过程如下: 在每次抽样之前,计算每个主题中所包含的单词,即统计主题中词频计数大于0的所有词语。对于第m篇文档的第n个单词,把它分配到主题k的概率是由词频和外部知识共同决定的,即还受到该词与主题中所有词的相关度决定。然后重新对单词进行主题的划分。当迭代收敛后,输出模型的参数。
4 实验
文本设计了两个实验,一是基于LDA模型的文本蕴涵识别系统;二是基于KLDA的文本蕴涵识别系统,分别利用RTE-8数据集进行测试。
文本蕴涵识别系统框架采用我们在RTE-5中使用的系统[20]。系统首先对文本进行预处理,包括词根还原、词性标注、句法分析、语义分析和命名实体识别,然后基于预处理结果构建四类特征,包括字串特征、结构特征、语言学特征和基于LDA的语义相关度特征。其中,我们采用前三类特征中的部分特征作为本系统中的特征;同时,我们利用话题模型计算语义相关度特征。在学习阶段,文本-假设对利用这些特征生成特征向量,放入分类器进行学习。
4.1 任务及数据集介绍
实验选取RTE-8测评任务进行测试,RTE-8测评针对教育NLP领域中的学生答案进行分析,通过判断学生答案是否蕴涵标准答案来判别学生答案是否正确。它的测评主任务分为五分类(5-way task),三分类(3-way task)和二分类(2-way task)三个子任务。每个子任务的数据集,给出了一个问题Q(Question),和该问题的标准答案RA(Reference Answer)以及学生答案A(Answer),任务中把学生答案A当做T(Text),把问题的标准答案当做H(Hypothesis),然后对该蕴涵对(T,H)进行蕴涵判断。从而判断学生答案是否正确。本文主要做二分类任务。
本实验使用的数据集分两部分: 一是Beetle数据集,该数据集是从BEETLE II教育辅导系统中获取的标注语料,数据集包括高中电学知识;二是Science Entailments语料库(SciEntsBank),该语料库中包含了16个不同科学领域的知识,如物理学、生命科学等。提供三个测试集,第一个测试集为Unseen answers(UA)测试集,在该测试集中,提供的问题和标准答案与训练集相同,但学生答案不同;第二个测试集为Unseen questions (UQ)测试集,该测试集中问题、标准答案以及学生答案均与训练集不同,但和训练集处于同一领域范围;第三个测试集为Unseen domains (UD),测试集随机选取三个与训练集不同的领域,从选取的领域中获得问题、标准答案和学生答案。例1中的句子来自SciEntsBank语料库中的2-way训练集,其中SA1标记为correct,SA2,SA3标记为incorrect。
例1
Question:You used several methods to separate and identify the substances in mock rocks. How did you separate the salt from the water?
RA:The water was evaporated, leaving the salt.
SA1:Let the water evaporate and the salt is left behind.
SA2:You just get water and the smashed mock rock and put the smashed rock and water together.
SA3:I do not know.
Beetle语料库中训练集、Unseen answers(UA)测试集、Unseen questions(UQ)测试集分别有3 941对、439对、819对文本,SciEntsBank语料库中训练集、Unseen answers(UA)测试集、Unseen questions(UQ)测试集、Unseen domains(UD)测试集分别有4 969对、540对、733对、4 562对文本。
4.2 实验结果
本文分别在SciEntsBank和Beetle数据集上做了实验,在SciEntsBank数据集上,把训练样本和测试样本总共10 804对文本对作为KLDA的数据集,同样在beetle数据集上,共有5 199对文本对作为KLDA的数据集。设定α的初始值为50除以主题数,β初始值为0.1,松弛变量η取值在0.1-0.9之间变化,取主题数k在20—100之间进行变化,迭代次数设为2 000,训练KLDA模型,最终分别得到了训练集和测试集文本T和假设H的主题分布;接着,分别计算训练集和测试集中文本T和假设H主题的KL距离;最后,把计算得到的KL距离值作为一维特征加入系统中训练。KLDA模型主题数对实验结果的影响如图1所示,图中展示的是在SciEntsBank数据集上的实验效果。从图1中可以看出,话题数对系统实验最终结果的影响并不是很大,分析原因,是由于本实验把主题相似度作为一个特征,与其他特征融合到系统中,所以主题数对结果影响并不会很大。
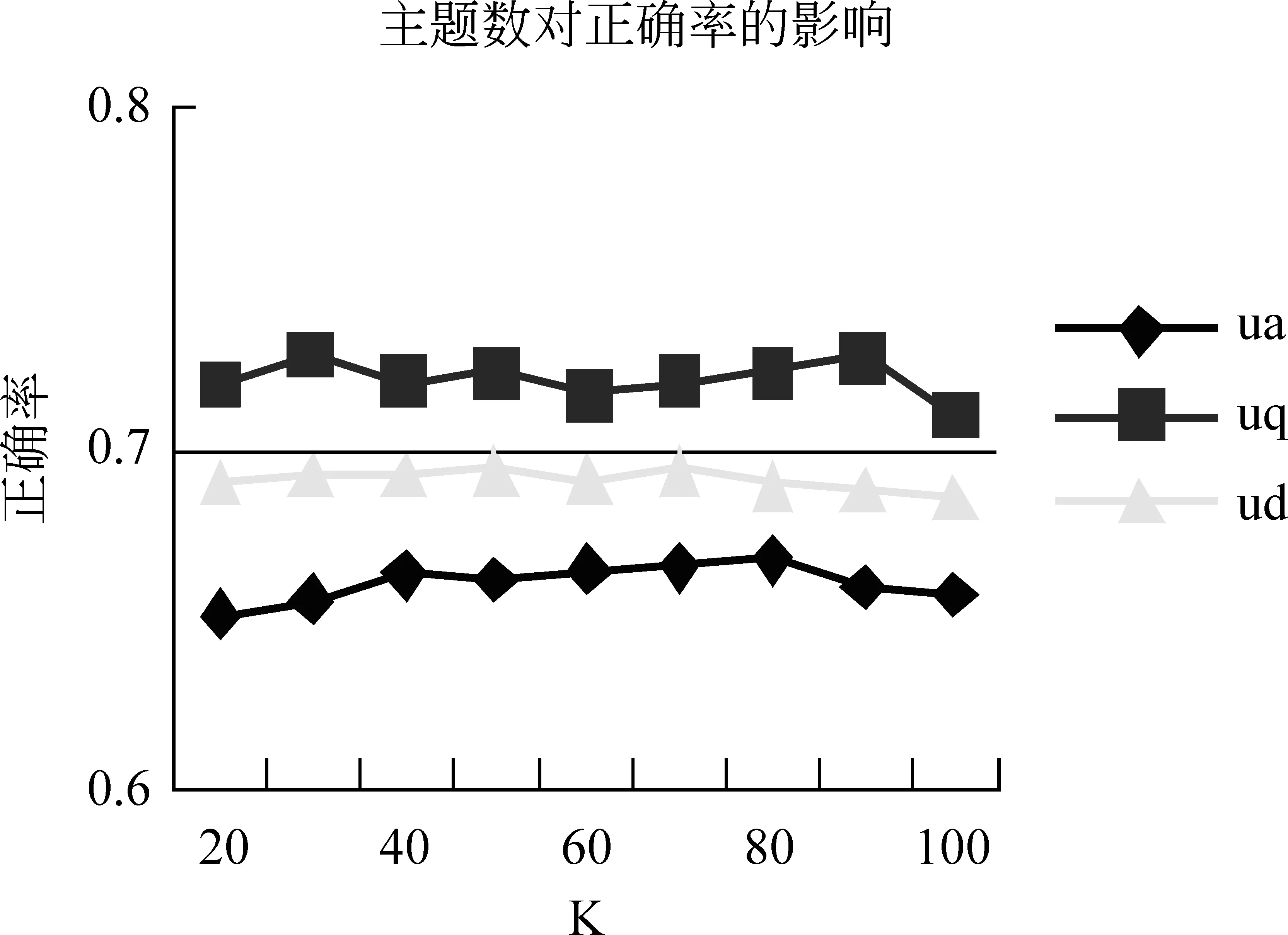
图1 主题数对正确率的影响
松弛变量η对实验结果的影响如图2所示。图中展示的是在主题数k=20的条件下,在SciEnts-Bank数据集上的实验效果。从图中可以看出,松弛变量η设的越大,也就是外部知识的权重越大,实验效果越好,这符合本文的实验预期。
系统整体实验测评结果如表1~表3所示。基准系统baseline在sys-lda基础上去掉了话题模型特征。各表中SoftCardinality-run1、ETS-run1和CU-run1展示的是参赛队伍前三名的结果,Mean显示的是全部参赛队伍平均性能,Lexical overlap baseline显示的是RTE-8中基于词汇重叠的基准系统。
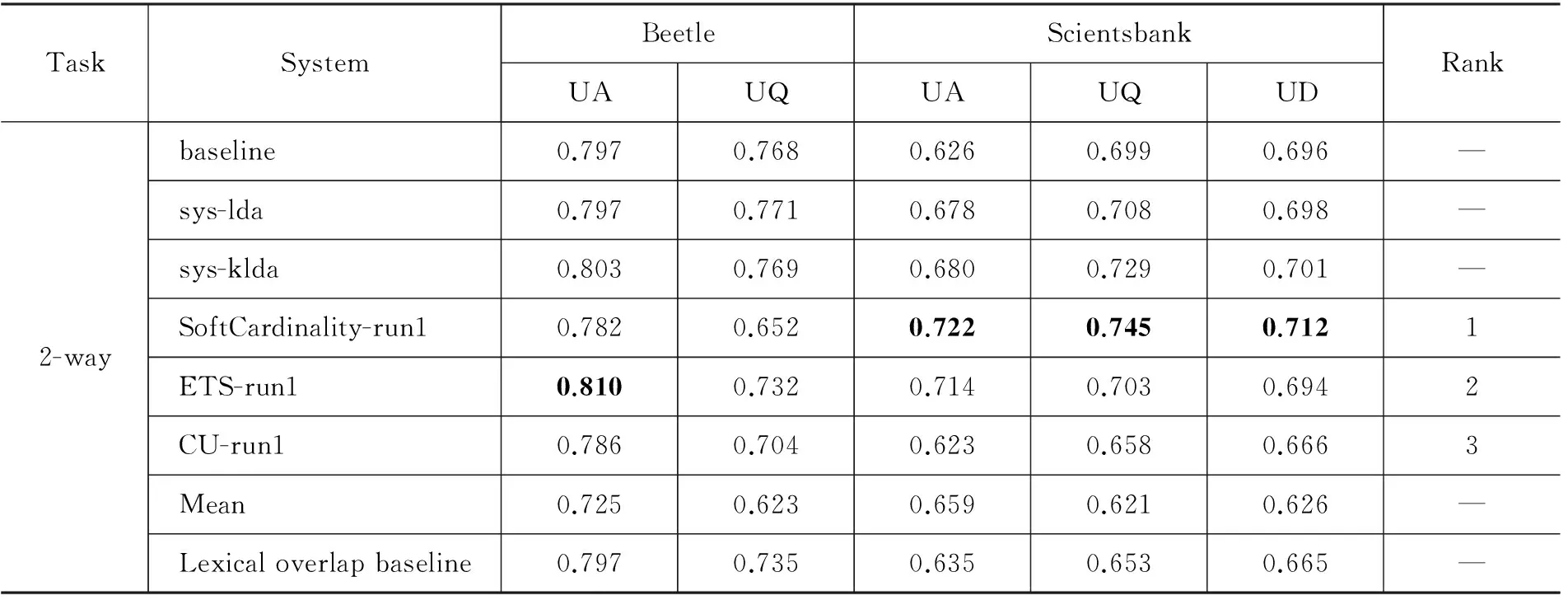
表2 系统加权F1评测
从表1可以看出基于KLDA的文本蕴涵识别系统在Beetle和ScientsBank数据集上,总体正确率达到71.4%,在所有参赛队伍中排名第二,尤其是在Beetle的UA数据集上,正确率达到了80.2%,在所有参赛队伍中排名第二;在Beetle的UQ数据集上sys-klda系统正确率比第一名队伍高出1%,说明知识话题模型的部分性能优于RTE-8最优参赛队伍的系统性能。
基于话题模型的系统在Beetle和SciEntsBank数据集上的总体正确率分别高于基准系统0.8%和0.8%,两个数据集的总体宏平均和加权宏平均也有所提高,说明基于话题模型的特征能够提供有效的相关性度量,从而改进文本蕴涵系统的识别性能。另一方面,基于知识话题模型的系统在Beetle和SciEntsBank数据集上的总体正确率分别高于基于话题模型的系统0.8%和0.4%,两个数据集的总体宏平均和加权宏平均也有所提高,说明外部推理知识能够有效提高话题模型的准确率。还有一方面,在分别采用话题模型和知识话题模型以后,系统的准确率逐渐提高,说明话题模型与现有特征相结合,能够稳步提高系统的性能。

表3 系统宏平均评测
5 总结
本文提出一个基于知识话题模型的文本蕴涵识别系统。该模型通过话题模型建立词汇相关性评估特征,用于改进基于分类的文本蕴涵识别系统的性能。为改进话题模型构建缺乏知识指导的问题,本文提出通过在抽样过程中引入文本蕴涵所需的背景知识,来修正抽样的结果的方法,以提高话题生成的精度。实验表明,知识话题模型能够有效改进基于分类的文本蕴涵识别系统的性能。
本文引入了外部推理和词义知识,在一定程度上对话题模型的产生起到修正作用。但是该模型的时间复杂度较高,如何减少时间复杂度是今后研究的一个要点;其次,如何在引入更多的外部知识,如语义结构变换规则,以进一步提高话题生成性能,也是今后研究的另一个主要问题。
[1] Dagan I, Glickman O, Magnini B. The PASCAL recognising textual entailment challenge[C]//Proceedings of the Machine Learning Challenges, Evaluating Predictive Uncertainty, Visual Object Classification, and Recognising Tectual Entailment. Springer Berlin Heidelberg, 2006: 177-190.
[2] Androutsopoulos I, Malakasiotis P. A Survey of Paraphrasing and Textul Entailment Methods[J]. Journal of Artificial Intelligence Research, 2010, 38(1): 135-187.
[3] Dagan I, Dolan B. Recognizing textual entailment: Rational, evaluation and approaches[J]. Natural Language Engineering, 2009, 15(4): i-xvii.
[4] O Dzikovska M, D Nielsen R, Brew C, et al. SemEval-2013 Task 7: The Joint Student Response Analysis and 8th Recognizing Textual Entailment Challenge[C]//Proceedings of Second Joint Conference on Lexical and Computational Semantics. 2013: 263-274.
[5] 张鹏,李国臣,李茹等. 基于FrameNet框架关系的文本蕴含识别[J]. 中文信息学报,2012,26(2): 46-50.
[6] De Marneffe M C, Rafferty A N, Manning C D. Finding Contradictions in Text[C]//Proceedings of the ACL. 2008, 8: 1039-1047.
[7] Malakasiotis P, Androutsopoulos I. Learning textual entailment using SVMs and string similarity measures[C]//Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing. Association for Computational Linguistics, 2007: 42-47.
[8] 刘茂福,李妍,姬东鸿.基于事件语义特征的中文文本蕴含识别[J]. 中文信息学报,2013,27(5): 129-136.
[9] 石晶,戴国忠.基于知网的文本推理[J]. 中文信息学报,2006,20(1): 76-84.
[10] Kouylekov M, Magnini B. Recognizing textual entailment with tree edit distance algorithms[C]//Proceedings of the First Challenge Workshop Recognising Textual Entailment. 2005: 17-20.
[11] Kouylekov M, Negri M. An open-source package for recognizing textual entailment[C]//Proceedings of the ACL 2010 System Demonstrations. Association for Computational Linguistics, 2010: 42-47.
[12] Lin D, Pantel P. Discovery of inference rules for question-answering[J]. Natural Language Engineering, 2001, 7(4): 343-360.
[13] Berant J, Dagan I, Goldberger J. Global learning of typed entailment rules[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011: 610-619.
[14] Melamud O, Berant J, Dagan I, et al. A Two Level Model for Context Sensitive Inference Rules[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. 2013:1331-1340.
[15] T N Rubin, A Chambers, P Smyth, et al. Statistical topic models for multi-label document classification[M]. Arxiv preprint arXiv, 2011:1107.2462.
[16] Chen Z, Liu B. Topic Modeling using Topics from Many Domains, Lifelong Learning and Big Data[C]//Proceedings of the 31st International Conference on Machine Learning (ICML-14). 2014: 703-711.
[17] Chang J, Boyd-Graber J, Chong W, et al. Reading Tea Leaves: How Humans Interpret Topic Models[C]//Proceedings of the 23rh Annual Conference on Neural Information Processing Systems. Vancouver, Canada.2009.
[18] Leacock C, Chodorow M. Combing Local Context and WordNet Similarity for Word Sense Identification[C]//Proceedings of the Electronic Lexical Database, MIT Press, 1998:265-283.
[19] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. The Journal of machine Learning research, 2003, 3: 993-1022.
[20] Ren H, Ji D, Wan J. WHU at TAC 2009: A Tri-categorization Approach to Textual Entailment Recognition[C]//Proceedings of the Fifth PASCAL Challenges Workshop on Recognizing Textual Entailment. Gaithersburg, Maryland, USA, 2009.
Recognizing Textual Entailment Based on Knowledge Topic Models
REN Han1,4,SHENG Yaqi2,4,FENG Wenhe2,4,LIU Maofu3,4
(1. School of Computer Science, Hubei University of Technology, Wuhan, Hubei 430068, China; 2. School of Computer Science, Wuhan University, Wuhan, Hubei 430072, China; 3. College of Computer Science and Technology, Wuhan University of Science and Technology, Wuhan, Hubei 430065, China; 4. Hubei Research Base of Language and Intelligence Information Processing, Wuhan University, Wuhan, Hubei 430072, China)
This paper analyzes the defects in current entailment recognition approaches based on classification strategy and proposes a novel approach to recognizing textual entailment based on a knowledge topic model. The assumption in this approach is, if two texts have an entailment relation, they should share a same or similar topic distribution. The approach builds an LDA model to estimate semantic similarities between each text and hypothesis, which provides the evidences for judging entailment relation. We also employ three knowledge bases to improve the precision of Gibbs sampling. Experiments show that knowledge topic model improves the performance of textual entailment recognition systems.
recognizing textual entailment; topic model; entailment classification;inference knowledge

任函(1980—),博士,主要研究领域为自然语言处理。E-mail:hanren@whu.edu.cn盛雅琦(1991—),通信作者,硕士,主要研究领域为自然语言处理。E-mail:shmilysyq@whu.edu.cn冯文贺(1976—),博士,博士后(在站),主要研究领域为理论语言学、计算语言学。E-mail:wenhefeng@gmail.com
1003-0077(2015)06-0119-08
2015-06-05 定稿日期: 2015-08-05
国家自然科学基金(61402341,61173062,61373108);国家社会科学基金重大项目(11&ZD189);中国博士后科学基金(2013M540594)
TP391
A
猜你喜欢
当代陕西(2021年18期)2021-11-27 09:01:36
开放教育研究(2020年2期)2020-03-31 01:54:14
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
作文大王·低年级(2019年4期)2019-05-13 01:44:10
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
高校应用数学学报A辑(2016年4期)2016-07-10 01:23:54
现代语文(2016年21期)2016-05-25 13:13:44
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:43
大连民族大学学报(2015年2期)2015-02-27 08:28:11
