
用户行为驱动的自组织网络资源配置研究
2015-05-30 10:48:04
中兴通讯技术 2015年1期
1 5G与用户行为
当前无线通信的业务量正在飙升。根据思科的预测,未来移动通信数据业务在2011年至2016年的年复合增长率将达到78%[1]。移动通信产业面临巨大的挑战:在未来10年中移动数据业务将有1 000倍的增加[2]。同时,随着智能终端的普及,海量设备连接和各类新业务、应用场景也不断涌现。下一代移动通信系统——5G需要满足这些需求和挑战。标准化组织IMT-2020起草了5G愿景白皮书[3],其中归纳了5G中的典型场景和关键参数指标以及可能采用的相应关键技术。白皮书中归纳的5G主要关键参数指标包括:更高传输速率(10 Gb/s)、更高频谱效率(5~15倍)、更高连接数密度(100万/km2)、更低时延(毫秒级)。
然而,现有的网络构架和资源分配方式并不能很好的应对这些挑战和实现白皮书中5G愿景。这些不足主要体现在以下两个方面。第一,现有异构无线资源管理对用户业务在时空范围动态分布的自适应能力不足。随着数据流量的增加,业务的潮汐效应变得更加明显[4-5]。一方面,由于特定原因造成的人群集中化导致区域化网络负荷过重、资源紧缺;另一方面,由于空闲的空载或零星负载的基站处理能力无法转移而形成资源浪费。第二,可管控的资源形态可拓性不足。传统无线蜂窝系统从时域、频域、码域、空域对资源进行描述(如时隙、子载波、码道、空域子信道),日益面临着资源耗竭的危机。因此需要探寻新的资源相关维度,对资源形态进行进一步的拓展。此外,5G网络下要求速率、容量的提升,导致小区的密集化,从而使干扰及能效问题变得不容忽视[6]。而根据当前网络状态被动式的资源管理方式和网络单元的密集化也使得信息共享代价变得高昂甚至难以承担。
如果将这些挑战聚焦在一起,我们能够发现用户及其行为是这些挑战的一个关键成因。一方面,丰富的移动互联网业务在填补用户大量碎片化时间的同时增强了用户交互和关联,延展了用户的多重身份(视频观众、新闻读者、广播听众、网站访客以及社交平台信息发布者/传播者),激发了用户间空前高涨的协同意愿(协同度)。结合用户智能终端能力的提升,移动用户行为之间的关联关系对现有移动通信网络通信资源形态的拓展具有重要潜力。另一方面,用户业务需求的个性化以及行为的随机性和差异性日益凸显[7-8],大量用户的行为也呈现出具有时空分布特性的群组特征。随着无线资源管理功能的增强,用户的行为特征为网络资源对用户需求的灵活适配以及网络资源利用效率的提升提供了指导性依据,可以作为网络资源配置中新的资源维度。因此,用户对网络的驱动作用不断提升。并且用户作为信息网络的核心组成部分,由其行为产生的需求是网络首先应当考虑满足的。如何利用用户行为对网络的驱动效应,使网络能够智能的调配资源以应对时空需求非均匀、周期性的用户业务需求,优化网络配置,是应对5G面临挑战可行方法之一。
本文从用户行为的角度出发,将用户行为作为网络自组织资源分配的考虑因素之一。第二部分从静态和动态两个方面介绍用户行为挖掘的方法。第三部分给出利用用户行为挖掘结果进行网络自组织资源分配的示例。最后在第四部分对全文进行总结。
2 用户行为挖掘
用户行为在一定程度上体现了用户的需求,基于对当前用户行为的分析与研究,可预测用户在未来一段时间内的行为,提前预知潜在的通信需求和规律,主动地完成无线资源配置。用户行为分为两种:一种是表示用户与用户之间关系的静态用户行为,另一种是用户动态行为。静态用户行为挖掘,注重用户组织关系的预测,而动态用户行为挖掘则注重用户轨迹的分析。
2.1 静态用户关系预测
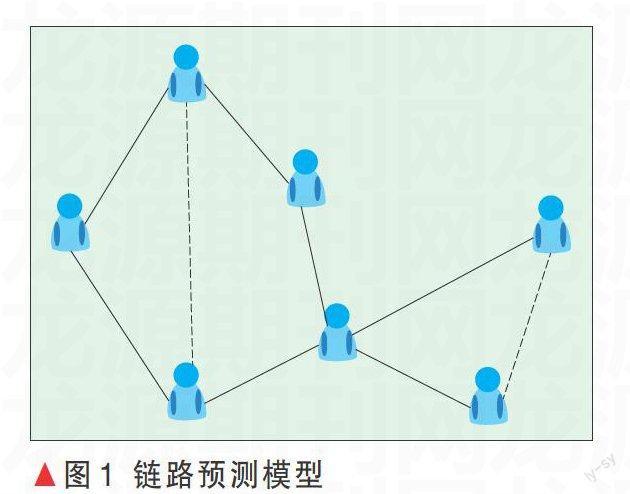
静态用户关系预测是指通过研究非直接关联的两个用户之间的相似性,估计这两个用户发生关联的可能性。目前基于复杂网络的链路预测模型可以有效地实现静态用户关系的预测。链路预测模型如图1所示,整个社交网络可映射为一个复杂网G (V,E ),其中节点集V[={v1,v2,…,vn}]对应于社交网络中的用户集,节点之间的连边集E[={e1,e2,…,em}]对应于用户之间的直接关系集。用户之间存在着串联的关系链,被称为复杂网络中的拓扑路径,用户之间发生联系的可能性取决于拓扑路径对用户之间相似性的传递能力。基于复杂网络的链路预测方法是通过研究用户端点之间拓扑路径对相似性传递的影响来实现预测模型的构建。
如果两个端点之间信息传递的能力越强,那么这两个端点越相似,未来两个端点发生直接关联的可能性就越大。为了数值化表示相似性,预测模型通过对拓扑路径的研究来估计端点之间的相似性S,S值越大两个端点发生连接的可能性越大。根据拓扑路径长度,链路预测算法可以分为:局部路径相似性算法,例如公共邻居算法(CN)、阿达米克阿达算法(AA)、资源分配算法(RA);全局路径相似性算法,如凯茨算法(Katz);半局部路径相似性算法,如本地路径(LP)、本地随机游走(LRW)、叠加随机游走(SRW)[9]。各算法的预测准确性可用受试者工作特征曲线下面积(AUC)度量指标进行衡量。虽然基于全局路径相似性的算法具有较好的预测准确性,但是复杂度高,实用性差。因此本文将重点讨论局部路径相似性算法和半局部路径相似性算法。通过对网络模型的研究,进一步提出优化算法,并在有代表性的几个实际网络上进行验证。代表性网络包括:美国航空网USAir、美国国家电网PG、蛋白质作用网Yeast、网络科学家合作网络NS、爵士乐手合作网Jazz、新陈代谢网络CE、脸书好友网络Slavko、电子邮电网络E-mail、传染病网络Infec、欧洲合作网ES、UC大学社交网络UcSocial、生物链网络FW和Small & Griffith以及Descendants引文网。
2.1.1 局部路径相似性算法
基于局部路径相似性算法仅研究长度为2的拓扑路径。研究两个端点公共邻居的属性,依据“朋友的朋友就是朋友”的原则,公共邻居越多则通过共同好友传递相似性的能力就越强,两个端点越相似。但是传统关系预测算法在不同用户关系网中缺乏适应性,尤其是对用户弱关系性能的差异呈现出较低的敏感性。因此本文在AA和RA算法的基础上,构建增强弱关系的预测模型,以实现更好的预测性能。
设局部拓扑路径的中间节点为z,其度值为kz。kz越大,节点z的信息传输能力越弱,从而表现出强关系。否则kz表现出弱关系。假设待预测端点为x和y,其中x和y的邻居集合分别为[Γ(x)]和[Γ(y)]。
为了突出不同网络中弱关系的差异性,本文在AA和RA的基础上,添加自适应惩罚因子β以惩罚强关系突出弱关系,从而得到优化AA算法(OAA)和优化RA算法(ORA)预测算法[10]:
[SOAAxy=z∈Γx?Γylogkzβ] (1)
[SRAxy=z∈Γx?Γykzβ] (2)
将OAA和ORA算法在5个代表性网络中进行AUC性能仿真验证,结果如图2和表1所示。从仿真结果可以看出并非所有网络都在β=-1时取得最优。但通过调整β,可以准确地找到适合每个网络的最优β。在多数网络下OAA和ORA算法预测准确性优于传统的局部相似性算法CN、AA和RA。
2.1.2 半局部路径相似性算法
传统的基于半局部路径相似性算法在降低算法复杂度的同时具有较高的预测准确性。然而,传统半局部路径相似性算法忽略了不同路径组成节点的差异性,而且忽略了路径端点影响力中存在着冗余影响力的问题。
(1)路径异构性问题的研究
在传统半局部路径相似算法中,路径被建模成一条路由线路,两个端点之间的相似性取决于它们之间的路径条数。实际上,路径是由不同属性的节点组成的,应该在路径建模时考虑路径中间节点的属性,给予信息传输能力强的路径更高的权重。据此本文提出了在不同网络中突出路径中小度节点作用,削弱大度节点作用的Significant Path算法(有意义路径算法,简称SP算法)[11]。
设q表示任意一条连接节点x和y的路径,M(q)表示路径q去除端点之外所有中间节点组成的集合,vi表示路径q的任意一个中间节点,ki表示节点vi的度值,P2(vx,vy)和P3(vx,vy)分别表示端点x和y之间长度是2和3的路径集,α∈[0,1]是路径长度的惩罚因子,β是节点度惩罚因子。路径q的传输能力表示为:
[ζ(q)=vi∈M(q)kβi] (3)
由于长度大于3的路径在实际计算中复杂度大贡献小,因此模型仅考虑长度为2和3的路径。所以x和y之间异构路径相似性链路预测如下所示:
通过在12个网络中仿真计算算法的AUC性能,得到结果图3和与传统算法比较的结果如表2所示。可以看出,不论α取何值,AUC均在β<0时达到最优,并且最优曲线对应的α远小于1。SP算法突出了较短路径和强信息传递能力的路径,并且相比于传统算法,SP算法的预测准确性在大多数网络中都有明显的改进。
(2)控制端点冗余影响力问题的研究
传统算法在研究端点影响力对端点相似性的作用时,忽略了端点影响力实际存在的冗余问题。冗余影响力不利于准确发现节点的相似性,因此需要研究如何控制端点冗余影响力。研究方法主要有两种:通过惩罚无贡献冗余影响力增强预测的准确性和通过抽取有效影响力建模端点之间相似性。
(a)通过惩罚无贡献冗余影响力增强预测准确性
无贡献关系惩罚(NRP)算法[12]是通过惩罚大冗余影响力突出小冗余影响力以增强预测准确性。首先建模单条路径连通性,设vi表示路径中间节点,|E|表示网络连边集中的连边数,t表示所研究的最长路径长度,P(vi+1|vi)表示从节点vi到vi+1的转移概率,C(x,y)| jl表示长度为l的第j条路径中间节点总转移概率,则:
设N(l)表示长度为l的路径个数,相似性NRP算法的最终相似性模型为:
进一步考虑所有长度的贡献,NRP算法最终相似性模型为:
[SNRPxy=i=2tsimx,y|l] (7)
为了验证NRP算法的性能,本文在9个真实网络中进行了NRP的AUC性能实验以及与传统算法的比较实验,结果如图4和表3所示。可以看出最优值出现在β<1,即β-1<0,说明对无贡献大度进行惩罚可以明显改善预测准确性;相反取值β>0时性能会急剧下降,表明突出无贡献关系会降低预测准确性,并且NRP算法明显优于传统算法。说明通过惩罚端点无贡献关系即冗余影响力,可以极大改善链路预测的准确性。
(b)通过抽取有效影响力建模端点之间相似性
端点吸引节点与之发生关联主要依靠有效影响力。因此端点影响力建模可以采取直接抽取有效影响力的方式,如联合考虑有效影响力和强信息传播能力建模有效路径(EP)算法[13]。
通过添加指数参数
[Cx,y|l=j=1N(l)Cx,y|jlβ] (8)
接着将可达对端的路径条数建模为有效影响力。设|Pathslxy|表示在端点x和y之间长度为l的路径个数,进一步结合长度为2到t的路径总信息传输能力,得到端点x和y之间总的相似性预测模型为:
[SEPxyt=l=2tPathlxyCx,y|l] (9)
由于存在较长路径贡献小而代价大的问题,而对节点相似性贡献最多的路径长度是2和3,因此仅考虑长度为2和3的路径可以取得较好的预测效果。为了验证EP算法的预测准确性,本文利用15个网络仿真了不同β取值对预测准确性AUC的影响以及EP与传统算法性能的比较,如图5和表4所示。可以看出最优值出现在β>1的位置,并且EP算法AUC准确性要明显高于其他算法。综上说明通过考虑有效影响力和强信息传输能力可以有效增强链路预测的准确性。
2.2 动态用户行为分析
除了静态人类组织关系行为外,人类移动行为的研究和预测对无线资源调度和分配也非常重要。
目前对人类移动行为的研究和预测主要基于统计学和信息技术展开,分析结论表明[14]:人类活动包含两类,其一是时间和空间上的周期性活动,其二是同社交关系相关的随机跳跃活动。近距离活动多体现出时间和空间的周期重复特性,同社交关系关联不大。远距离活动受社交关系影响比较明显。研究表明社交关系可以解释10%~30%的人类活动,而周期性模式可以解释50%~70%的人类活动。
依据从签到网站和移动终端获得的数据,研究者们绘制出了关于人群的行为模式。图6是在某城市中某一时刻人群在家中和工作单位的空间位置分布图以及一天中人们在家和工作单位的时间分布图,从图中可以看出明显的聚集性。图7显示的是在某城市中,从中午到午夜时刻,人群移动模式随时间变化的关系,可以看出具有明显的周期规律性,白天向工作地点聚集,夜晚向家的方向聚集。
除了在地理和空间位置维度表现出周期性短距离的人群移动行为外,还有受社交关系影响的非周期性长距离行为。人们有时候会因为探亲访友产生出一些非规律性的行为,这些行为大多是由社交关系引起的。根据人们移动行为模式规律建立模型,预测未来人们发生行为的时间和空间位置是非常有意义以及可行的。
研究者们提出了许多方法,具有代表性的是根据人们行为的周期性进行预测的周期移动模型(PMM),PMM和进一步考虑了社交关系的社交周期移动模型(PSMM)[14]。
利用对人类行为的预测来预测未来人群聚集发生的时间和空间位置,并引导无线通信资源的分配,能够极大地提升资源的利用率和用户满意度。
3 用户行为驱动的网络
资源配置
由用户构建的社交网络与实际通信设备部署网络之间并非一一对应的关系,因此在获取和预测用户行为特征之后需要结合实际应用场景,选取合适的预测特征和数据来完成实际通信设备网络部署的资源优化配置。
3.1 基于小区负载的覆盖容量自优化
对所提取的用户行为特征加以利用将有助于提升网络整体的承载能力。因此,可利用对个体用户时间、空间行为的周期性、区域性特征的分析及预测,获取群体用户在一定时间、空间范围的聚集行为。而群体用户的空间聚集行为将直接决定各小区的负载情况,然后基站便可结合各小区负载的差异性进行覆盖与容量的自优化调整。如图8所示,基站可通过对天线配置、发射功率等射频参数进行联合调整的方式,将潜在的业务轻载小区的无线资源通过射频参数调整的方式投射到业务热点区域,使网络资源对用户周期性、区域性业务需求具有灵活的空间流性匹配能力,动态完成对不同区域、不同需求的用户的流性适配,达到提升网络覆盖容量综合性能的目的。
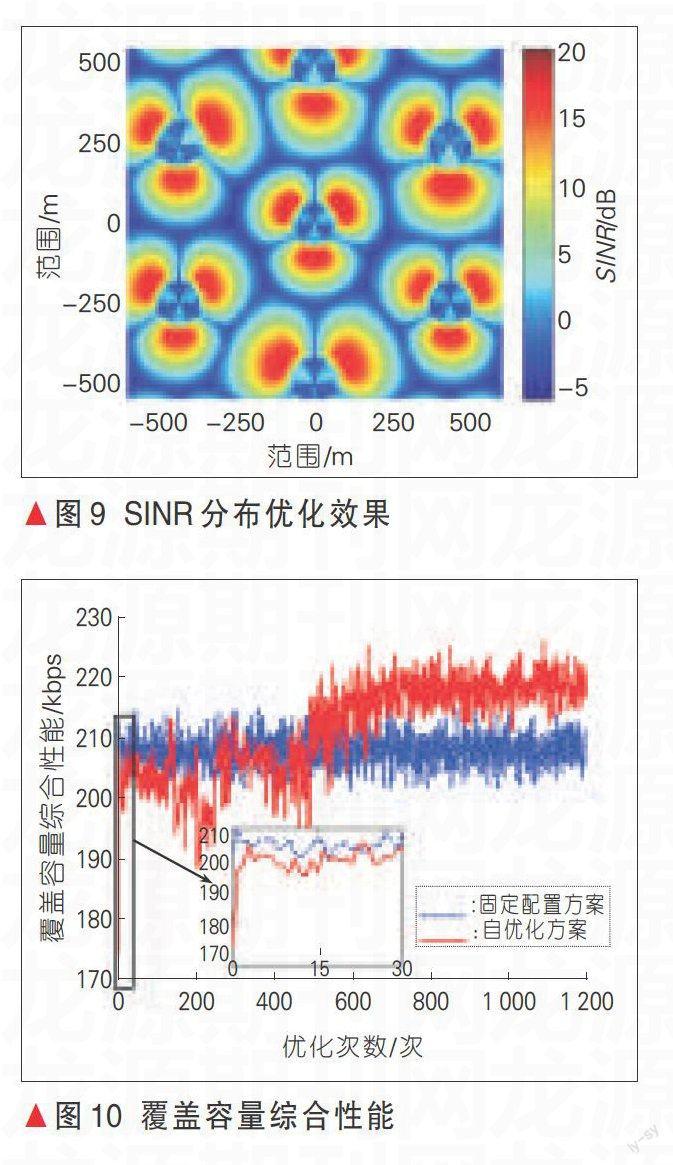
覆盖容量的优化过程需要考虑射频参数的调整对覆盖及容量性能的诸多方面影响。比如较小的天线仰角会扩大本小区覆盖范围而提升边缘用户的性能,但同时也会对邻区用户带来更大的干扰并影响邻区容量。因此,对覆盖容量的联合优化需要兼顾覆盖性能与容量性能、本小区性能与邻区性能的折衷。考虑到射频参数的调整与所达到的覆盖容量联合性能没有直接的映射关系,因此覆盖容量的联合优化更倾向于采用机器学习等人工智能方式。根据邻区潜在负载差异及覆盖容量综合性能情况完成对射频参数的自优化调整,并通过对优化经验的归纳总结,提升基站的自主优化决策能力。所实现的网络SINR分布性能及覆盖容量综合性能优化效果如图9、图10所示[15]。经过自优化,各小区的射频参数会由于负载的差异而有所不同,重载小区的覆盖范围较小,其边缘用户将移至覆盖范围扩大了的轻载小区接受服务。并且,基于小区负载的覆盖容量自优化方案性能相较于未考虑负载差异的优化方法得到了有效提升。
3.2 基于设备直通协作多播的数据
分发策略
蜂窝网络所产生的大部分流量是流行内容的下载,例如视频、音频或移动应用程序。鉴于大多数用户行为具有这种共性下载的特点,如果基站把这种具有相同业务请求的用户数据卸载到设备直通(D2D)网络,那么就可以有效缓解蜂窝网络基础设施的负担,提高频谱效率以及用户满意度,并在一定程度上解决无线通信系统频谱资源匮乏的问题。由于大多数用户行为具有共性以及流动性,并且用户间的社交关系也体现出了用户间的协同意愿,那么把用户之间相同的数据请求通过基站多播方式实现数据分发,就可以极大的提高整个系统的资源利用率。
由于D2D协作多播系统是由独立的蜂窝用户组成,用户间的连接关系时断时续。而在现实生活中,人们的社交关系相对稳定,因此利用数据挖掘获得的用户社交关系可帮助蜂窝网络建立可靠的D2D传输链路,如图11所示。
根据用户节点i和j的历史关系信息,用[ωi,j∈[0,1]]表示两节点间的紧密度。[ωi,j]越大表示节点i和j间将在未来有更多的连接机会。该度量指标描述了邻居关系并作为数据分发中协作节点选择的依据。
构建社交网络邻居图G (V,E ),其中V[={v1,v2,…,vn}] 为社交网络中的节点,每一条边
最终我们以网络吞吐量最大化为目标,优化问题可表示为:
[s.t. xi,j=0,1,i∈M,j∈N] (11)
[jxi,j=1,i∈M] (12)
[ li,j≤R] (13)
其中[Ci,j=log2(1+PDl-αi,jgi,jN0)],[PD]表示簇头节点的发射功率;li,j表示多播传输距离(li,j≤R);gi,j表示服从指数分布的路径损耗;(11)式表示若用户j属于簇i,则xi,j=1,否则xi,j=0;(12)式表示用户j只能同时属于一个簇;(13)式表示簇的最大半径为R。
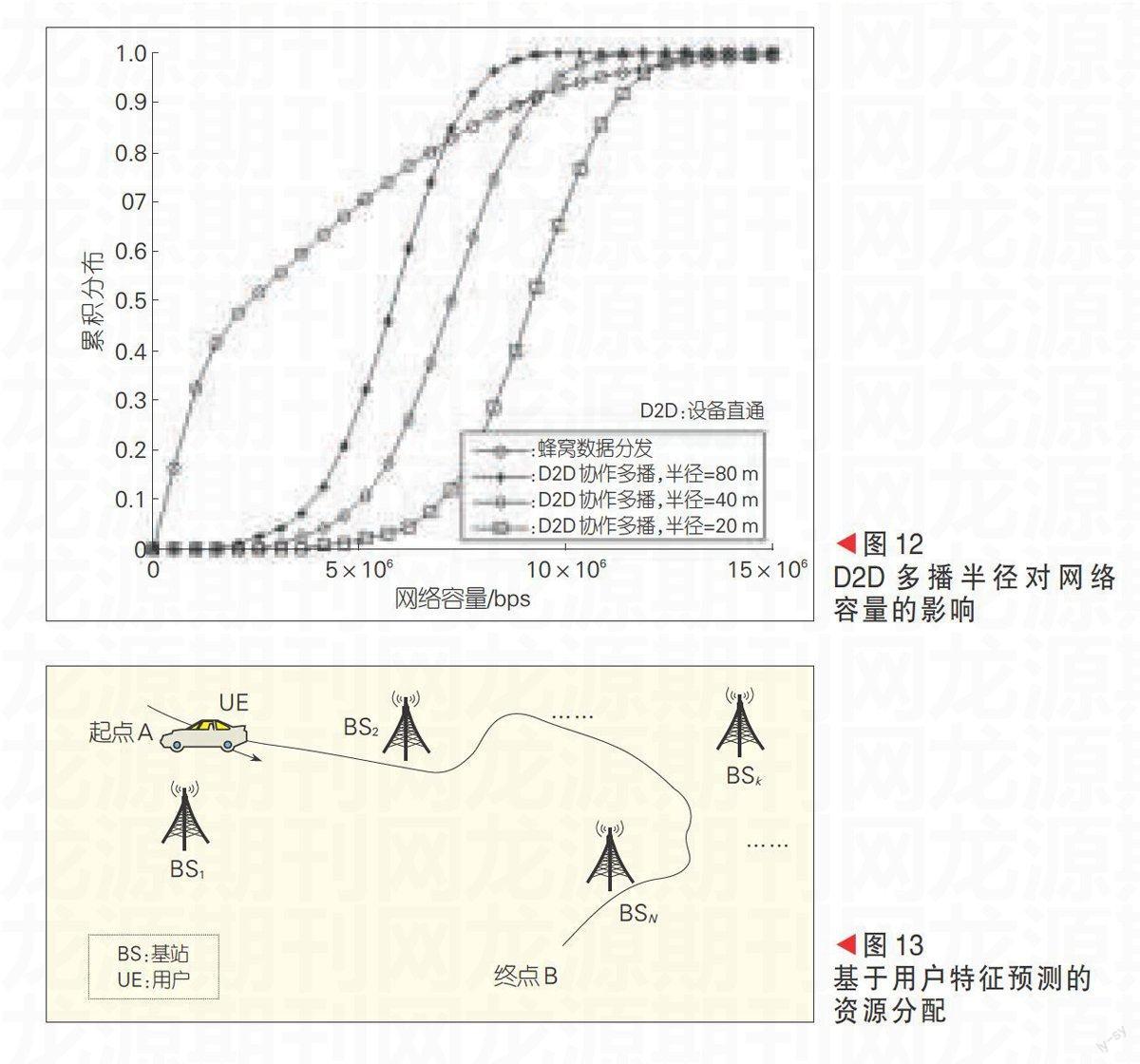
D2D协作多播网络容量增益如图12所示。该图比较了传统蜂窝数据分发与不同多播半径情况下的平均网络容量累计分布函数(CDF)曲线。由图可知,D2D协作多播算法所达到的网络容量要优于传统蜂窝数据分发算法,并且随着多播半径R逐渐减小,D2D簇内多播速率增加。
3.3 个性用户业务服务资源配置
在通过预测获取用户个性化特征之后可以根据提取出的潜在业务发起位置及业务需求等个性化特征进行资源的提前预配置。
基于用户特征预测的资源分配如图13所示。用户(UE)经常由A出发到B,并在B点被动的接收一定量的数据(例如B为展览馆,UE为一个管理员,需要接收一定的解说信息,而解说信息会定期更新)。由于UE经常往返于A和B,在网络侧长期的历史信息搜集统计中,可以通过用户关系预测得出UE从A到B之间最常接入的基站集合。根据UE在这些基站中所上报的信道质量历史信道信息,可以预测出UE在经过这些基站时的平均信息速率。同时根据UE的导航信息,可以获知UE在从A到B中所需的平均时间。由于B点接收信息较大,如果等用户A到达B点再更新信息的话,会带来较多的等待时延。为此,一种新的解决思路是利用上述预测信息,让UE在B点需要的数据,在预测的中途基站中进行预传输,从而达到提升用户体验质量的效果。具体分析如下。通过与UE的导航系统的信息交互,以及用户习惯的预测,可以预测用户的行进路线如图中的曲线表示。用户途径的基站集合表示为N[={1,2,…,k,…,N}]。由于用户到达终点B时要下载总量为D比特的本地的业务,在预测到用户行进的轨迹和相关路径的基站分布之后,可以在UE的行进途中,提前将B点的业务分散在沿路路径中的每个基站来完成,以达到节省通信时延的目的。假设进入第[i]([i∈]N) 基站服务范围内的UE历史平均速率为[ci]b/s,单个UE在行进路径中进入到离开第[i]个基站的历史平均耗时为[τi],那么第[i]个基站可承担的最大平均数据是[Ci=ciτi]比特。假定D分配到第i个基站上应承担的数据量为xi,那么使得这N个基站组成的系统能效最大化问题可表述为:
[P1:maxxDi=1Nxipici] (14)
[s.t. i=1Nxi≥D 0≤xi≤Ci,?i∈N] (15)
其中[x=x1,x2,....,xN∈?1×N]为数据分配向量,pi为第i个基站的发射功率。P1可用线性优化方案给出最优解。与传统的资源分配相比,基于预测的资源分配可以有效缓解B点处的通信业务压力。提前配置考虑了节能、基站负载等因素,极大的优化了网络的整体性能。同时这种预测提前通信也大大减少了用户等待时间,提升了用户体验质量。
4 结束语
本文从用户行为对网络的驱动特性出发,提出了通过将用户行为作为自组织网络资源管理考虑的因素来弥补当前网络不足的方法。文章对动态和静态用户行为特征的提取进行了分析,选取了典型的自组织网络资源分配场景,给出了这些场景下应用用户群体行为特征和个性行为特征进行网络资源优化配置的方法。然而由于用户行为的复杂特性,当前对用户行为的挖掘还比较粗糙。同时由于人类的社交网络与自组织网络的物理资源网络并非一一对应的关系,在利用用户行为特征进行网络资源配置时需要根据具体的场景,选取合适的用户行为分析模型,提取相应的关键参数,从而实现对网络资源的高效配置。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
数学物理学报(2022年2期)2022-04-26 14:08:34
河北画报(2020年8期)2020-10-27 02:54:20
中学生数理化·教与学(2019年8期)2019-09-18 15:08:40
数学物理学报(2017年1期)2017-06-05 09:12:28
探索科学(2017年4期)2017-05-04 04:09:47
中国交通信息化(2016年8期)2016-06-06 03:56:25
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:52
移动通信(2015年17期)2015-08-24 08:13:10
