
关于结合层次聚类和K—means算法进行聚类的研究
2015-05-30 15:14:38孔令凯向毅梁松
科技创新与应用 2015年25期
孔令凯 向毅 梁松

摘 要:为了解决进行K-means聚类时类数的自动选择和Hierarchical聚类在处理大量高维数据时时间效率低的问题,在K-means聚类算法的基础上结合Hierarchical聚类算法,提出了一种基于集体智慧编程方法的用于处理大量数据时动态选取K值的聚类模型。实验结果表明该算法比K-means聚类具有更好的聚类效果,同时解决了Hierarchical聚类方法时间效率低的问题。本模型通过K-means聚类生成适量的类簇,再利用Hierarchical聚类对这些类再进行聚类,最后经过剪枝得到合适的聚类结果,以此实现动态选取K值。
关键词:K-means聚类;Hierarchical聚类;降维;剪枝
引言
K-means聚类算法是最为经典的基于划分的聚类算法,该算法的最大优势在与简洁和快速,但是该算法聚类效果的好坏取决于初始中心的选择和距离公式。同时,Hierarchical聚类在处理大量数据时,会生成一个高维的矩阵,导致时间效率低。
本算法模型正是针对K-means聚类对大量数据进行降维,以此降低Hierarchical聚类的时间效率,同时利用Hierarchical提高了K-means的聚类效果并实现k值的选取。
1 结合Hierarchical聚类和K-means聚类算法的算法模型
本模型主要分为一下几步:首先对数据进行预估,预设一个合适的k值(大于目标类数,远小于总样本数),使用K-means聚类进行聚类操作;然后对k个类的平均中心点进行Hierarchical聚类操作,生成一棵树;最后通过判断k个类的中心点的拐点,对这个树进行剪枝,从而生成newk个子树,即newk个类。
该模型的算法流程如下:
输入:k,data[m,n];
(1)K-means聚类:
1.选择k个初始中心点,c[k,n];
2.对于data[m,n]中的每一行m,寻找距离其最近的中心点I (i∈k),标记data[m,:]为I;
3.对于所有标记为i的点,重新计算中心点(使用所有标记为i的点的平均数)
4.重复2,3,直至循环10次;
(2)Hierarchical聚类:
5.对4中生成的k个中心点计算两两间的距离,生成距离矩阵
6.选择最近的两个中心点,合并生成新的中心点,使用两个类中的所有点的平均值代表新的中心点
7.重新生成距离矩阵
8.重复6和7,直到合并成一个类为止
(3)剪枝操作:
9.根据8生成的树中每一步合并操作时,两个子节点之间的距离,计算拐点
10.根据计算的拐点进行剪枝,得到newk个子树
2 实验评价
本模型中的K-means聚类和Hierarchical聚类使用Python编程实现,利用了sklearn工具中实现的聚类算法KMeans和hierarchy数据结构。实验机器配置为:Intel Core i7-3537U 2.00GHz CPU,8.00 GB 内存;Python 2.7.5(32 bit)。
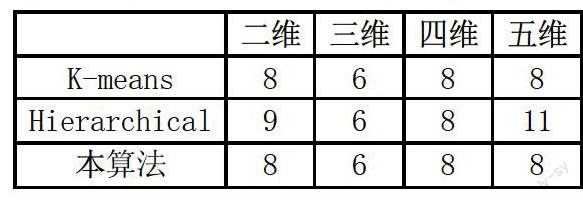
数据样本为900条时:
3 结束语
本模型通过结合Hierarchical聚类和K-means聚类算法,实现了一种新的聚类方式。从实验结果可以看出本方法在处理大量高维数据时效果明显,时间效率低且聚类效果更好。本算法仍存在不足:需要预设一个合适的较大的k值,此k值不宜过大,太大会导致算法效率的降低;另一方面,此值也不能小于聚类效果最好时的类数,否则聚类效果不理想。基于此点,需要在使用前根据数据样本进行预估,然后给出一个较为合适的k值,或者进行几次实验进行探索。本算法已经实现了k值的自动选择,也大大减小了在探索过程中所需的时间和精力。
参考文献
[1]王千,王成,冯振元.叶金凤K-means聚类算法研究综述[J].电子设计工程,2012(7).
[2]胡伟.改进的层次K均值聚类算法[J].计算机工程与应用,2013,49(2).
[3]杨燕,靳蕃.KAMEL Mohamed聚类有效性评价综述[J].计算机应用研究,2008(1).
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
电子测试(2017年15期)2017-12-18 07:19:27
天津诗人(2017年2期)2017-03-16 03:09:39
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
智能系统学报(2015年4期)2015-12-27 09:38:39
大众摄影(2015年9期)2015-09-06 17:05:41
电子设计工程(2015年6期)2015-02-27 12:04:53
