
基于本体的语义信息检索模型研究
2015-05-30 10:48:04赵彦锋周晓红
软件工程 2015年8期
赵彦锋 周晓红


摘 要:为了弥补传统检索模型基于关键词匹配的缺陷,探讨领域本体的语义信息检索模型。阐述了四元组本体内涵,给出了资源映射方案,制定了本体概念扩展策略,描述了本体概念相似度计算算法,并进行了实验对比分析。结果表明:本体语义检索模型查准率及查全率均高于传统检索模型,具有一定的理论及实用价值。
关键词:本体;语义;相似度;信息检索
中图分类号:TP301 文献标识码:A
Abstract:Aimed at the defects of the traditional keyword-based retrieval model,an ontology-based semantic query-oriented information retrieval model was built.Concept of four tuple ontology was defined,the resource mapping scheme was given,ontology concept expansion strategy was formulated, the concept similarity computing algorithm of ontology was described,and the experimental comparison was carried out.The results show that precision and recall rate of ontology semantic retrieval model are higher than the traditional retrieval model,this study has some theoretical and practical value.
Keywords:ontology;semantic;similarity;information retrieval
1 引言(Introduction)
随着互联网技术的快速发展,人类已进入信息时代,尤其是当前大数据背景下网络信息资源的数量越来越庞大,其已成为全球最大的信息库,且网络信息资源随之呈现出更加复杂的特性,暴露出一些亟待解决的问题[1-3]。然而,传统信息检索模式面对文本字符串匹配的语法层面,缺乏针对信息表示及处理和理解的语义层面分析,即信息是丰富的,而知识却是贫乏的,所以依赖传统的信息检索方式已很难满足用户需求,而本体及其相关理论技术的出现为解决这一问题提供了可能。
本文将利用本体建立标签之间的语义关系,并引入语义与Agent技术,实现标注系统的语义检索,通过语义模型丰富的描述能力和强大的逻辑推理能力准确描述信息资源,以Agent组织完成用户交互、信息检索、信息过滤、结果返回,构建一种基于本体学习的能够实现语义层面分析的检索模型,以弥补传统信息检索的不足,进而从信息查全率和查准率方面改善信息检索的效率。
2 基于本体的语义检索模型构建(Construction of semantic retrieval model based on ontology)
基于领域本体的语义检索,可依据领域本体知识库对信息资源或文档进行语义标注,本体概念的语义信息可借助本体概念定义及本体概念之间的关系进行描述,因为特定专业领域的概念可通过领域本体进行描述,这样可使文档或信息资源更具有语义,且可揭示出用户检索词的语义,把从文档和用户查询抽取的关键词转换为具有语义的本体概念,实现基于关键词的语法检索到基于本体概念的语义检索的提升,其中,语义检索与传统基于关键词匹配的检索方式不同,因为语义检索基于信息理解的语义层面对信息资源及用户提交的检索请求进行分析,语义检索方式对检索条件、信息组织以及检索结果均赋予了语义成分,可从语义层面提高检索精度[4-7]。
2.1 领域本体的语义检索理念
基于领域本体的语义信息检索,其理念在于使信息资源或文档进行语义描述,借助领域本体知识库完成对文档和信息资源对象的语义标注,进而揭示出文档和信息资源对象的语义理解,及其用户检索词的语义信息,同时可实现领域本体检索词的语义扩展,最终完成理想检索结果的获取,具体检索过程为:
step1:构建并描述领域本体概念。描述领域本体概念,构建领域本体知识库。
step2:提取文档或信息资源对象特征并进行资源映射。借助领域本体概念描述及知识库构建和管理,对获取的信息资源或文档进行语义标注及资源映射,对信息资源或文档语义内涵进行揭示。
step3:制定本体概念扩展及查询语义扩展策略。在领域本体概念描述的基础上,对用户查询请求的语义信息进行揭示,并对用户检索词进行语义扩展,检索系统完成对生成的备选检索词集的检索工作。
step4:实现领域本体概念相似度算法。依赖本体概念结构图,实现本体概念语义距离计算算法、本体概念节点深度计算算法及语义综合相似度计算算法,以此服务于查询结果排序环节。
step5:对检索系统的检索结果进行排序。基于相关相似度计算算法及规则,完成用户原始检索词及检索系统返回检索结果的相似度比较,基于相似度对检索系统的检索结果进行排序并反馈给用户。
2.2 领域本体语义检索模型
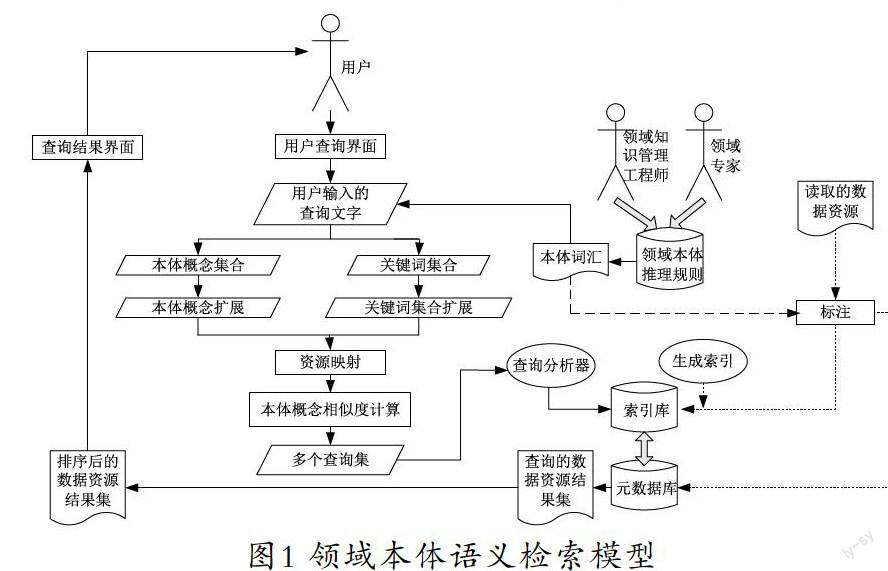
领域本体语义检索模型,如图1所示。
(1)领域本体及其分类体系作为数据资源语义表征的核心,可对文档或数据资源描述给予指导。领域知识也作为查询扩展和查询结果排序的基本依据。因此,领域知识的构建和维护,如领域本体、推理规则的构建和维护,离不开领域知识管理。
(2)数据资源或文档的语义可通过标注进行语义揭示,再借助文档特征提取技术,从领域本体词汇中获取本体概念,建立数据资源或文档的语义特征域,完成数据资源库文档的自动标注,并完成标注和索引信息资源或文档的非语义特征,由此生成文档索引库和元数据库。
(3)基于文档或数据资源标注信息构建索引库,以此为依据,检索出能满足用户需求的文档或数据资源信息。
(4)实现查询扩展及结果排序,就是以领域本体生成的本体词汇库为依据,完成用户查询输入文字的分词工作,将用户查询分成本体概念集合和非本体概念集合。然后,分别对这两个集合按相似度扩展,得到两个查询候选集合,以此为依据,借助相关相似度排序算法获得排序后的查询集,最后,完成查询请求到索引库及检索库的提交环节,将查询结果按查询请求的相似度排序后,将结果推送给用户。
3 关键算法实现(Key algorithm implementation)
3.1 四元组本体内涵及其数学描述
基于四元组的本体概念描述为:,其中,表示用户,描述使用标签管理资源的用户,并且每个用户有唯一的ID号标识。表示标签,描述集合中用户使用过的标签,标签可以是任意的字符串(单词或短语),现定义标签为一组词语序列,,
,公式描述标
签映射成一组术语,术语可以是任意单词。表示资源,描述所有领域相关资源,其内容取决于用户标注集的类型,用户标注集主要由用户、标签、资源三个要素组成,即用进行描述。表示三元关系,其中元素描述用户使用标签标注收藏的资源。函数式描述用户使用一组标签定义一个资源,其中 。
为了理解用户标签含义及标签之间的关系,构建主干本体,用二元组进行描述:,
其中表示概念集,概念,是概念的唯一标识,是同义词集合,包含了概念的同义术语集合,是描述概念的短语,是将概念分类到泛化类中的词类,也可将四个元素分别记为:,,,;
表示概念集之间的关系。现定义为一组同义词集合,资源,定义一组同义词集合及里资源,,每个资源用二元组表示为:,
其中,为资源的频率分配。三元组表示关系集合中的关系,其中,,,是关系的两个关系项。
3.2 资源映射方案设计
一个标签可以映射成一个或多个概念,也有可能只有部分标签可以映射成一个或多个概念,现提供几种资源映射方法。
(1)直接映射
直接映射描述标签到概念的映射,即将每个标签映射到本体中的概念,可表示为:
3.3 本体概念扩展策略制定
(1)本体概念扩展
本体概念扩展步骤如下。
step1:对每个本体概念进行扩展。
为领域本体概念集,为两个本体概念的相似度。如果对本体概念进行语义扩展可形成,
其中集合中每个元素要么为空,要么,且,。
也就是说,可基于相关相似度计算算法扩展单个本体概念,选择相似度大于给定阈值的本体概念,并且被选取的本体概念同其他用户本体概念之间的相似度,比该被选取本体概念同当前单个本体概念之间的相似度小。
step2:构建本体概念查询集。对用户本体概念集的元素进行扩展,其中的每个概念元素都可扩展为一个扩展集,可分别从每个中进行本体概念的选取,构建本体概念查询集,查询本体概念集的组员就是从每个本体概念扩展集中选取的概念,查询本体概念集描述为:
(2)扩展关键词集合
关键词的扩展相对简单,因为关键词不是本体概念,所有扩展的集合所组成的集合为原关键词集的幂集,记为,其中的元素本身也是集合,且与用户输入的原关键词集之间的相似度计算也并不复杂,现令为幂集中的元素,则与之间的相似度计算模型为:
3.4 本体概念相似度算法
领域本体可描述特定领域中的概念及其关系,并可形成本体概念结构图,该本体图可计算本体概念相似度,其实本体概念结构图可看作为带有根节点的有向无环图,本体概念用图中的节点进行表示,概念之间的关系通过有向边进行表示,且该本体概念结构图具有树型结构的层次结构特性,及有向边和多重继承的特性。具体算法步骤如下:
step1:本体概念语义距离的计算。
基于本体概念图,本体概念的语义距离表现为连接两个概念节点的有向边的数量,记为。本体概念语义距离与本体概念语义相似度之间的关系为:两本体概念语义之间的距离越大,则这两个本体概念之间的相似度越小;反之,两本体概念语义之间的距离越小,则其之间的相似度就越大,即两者成反比关系。
step2:本体概念父节点深度的计算。
基于本体概念所体现的层次结构特点,对本体概念节点进行自顶向下的组织,及由大到小的分类,依据本体概念最近共同父节点所在层次,可知其层次越深,本体概念分类越细,从其父节点继承的语义信息就越多,其共同语义信息就越多,即这两个本体概念间的相似度就越大。现用描述两概念的最近共同父节点深度,表示两概念最近共同父节点。
step3:计算语义重合度。
本体概念之间的语义重合度计算可依据两本体概念间所包含的相同父节点个数来完成,但如果同时对本体概念语义距离和本体概念语义重合度加以考虑,则存在重复计算的可能性,因为本体概念语义距离中隐含着本体概念语义重合度信息,所以可基于本体概念语义距离和共同父节点在本体概念结构图中的深度,计算出本体概念相似度,令两本体概念 、,则、的语义相似度可通过、的语义综合距离和、共同父节点的综合深度对相似度影响的加权归一化进行表示,计算如下:
其中,为语义距离加权值,表示共同父节点的加权值,且满足,语义距离决定的相似度可通过调节参数进行调节,表示本体概念树的最大深度。
step4:本体概念综合相似度计算。
如果对用户检索词集中的本体概念进行语义扩展,可生成查询语义扩展集,记为,如果对用户检索词集中的非本体概念的关键词集进行扩展,可生成关键词集的幂集,记为,现从中取一元素,记为,该元素是一个扩展概念集,再从中取一元素,记为,该元素为一个扩展关键词集,便可形成一个提交给检索系统的检索请求,表示为(,),令用户检索词集为(,),每一个扩展的检索请求记为(,),则通过(,)和(,)相似度的计算,可得到用户检索词集和检索结果的相似度。现基于扩展关键词集相似度、扩展本体概念集相似度、分类概念集相似度,可计算出综合相似度,数学描述如下:
其中,、为调节参数,代表本体概念集相似度与综合相似度的比值,代表关键词集相似度与综合相似度的比值,且。
4 实验与结果分析(Experiment and result analysis)
本实验环境为:Windows 7操作系统,SQL SERVER 2008数据库平台,模型数据库动态链接查询实现工具为某专业数据库数据及WEB技术。建立领域本体的开发工具为:5.0的PROPERTY BROWSER环境,每个词条类的构建借助Object Property属性实现,因为Object属性可在类与类之间建立不同层次的关系描述,而且两个Object属性之间存在多种关系。如果基本父类建立完成后,还可为每个父类添加不同的子类和属性,同时还具有继承特性,即所有子类都可继承其父类的基本属性。
实验步骤为:
step1:对选取知识本体的专业领域及范围进行确定,基于自顶向下的顺序,构建本体概念和术语清单。
step2:对基础词库进行完善。
step3:依据分类体系层次,对本体实例进行添加,构建整个领域本体。
本体概念语义信息检索模型测试指标通过查准率和查全率进行衡量,分别描述为:
查全率:
查准率:
同时,借助对检索结果进行评价及对比分析,以便于全面衡量其检索效果,的计算公式描述为:
它为检验本体概念语义信息检索模型,将其与传统关键词检索模型进行实验对比分析,对抽取的某领域的标准词条进行测试,从中随机选择四个词条实验样本,分别以相同词条在本文模型和基于关键词模型中检索,实验结果详见表1、表2和图2所示。
由以上实验结果可知,领域本体概念的语义信息检索模型效率高于传统关键词信息检索模型,且语义检索的 也高于传统关键词检索,表明本体概念语义检索模型具有一定的理论及实用价值。
5 结论(Conclusion)
论文构建了面向语义查询的信息检索模型,对资源映射方案、信息概念扩展、相似度计算等进行了改进,实验结果证明该模型具有较高的查全率和查准率。今后的工作中,将继续研究本体结构中,如何查找到更多概念邻居,以减少数据稀少的影响,进而提高检索效率。
参考文献(References)
[1] Zhang Bin,et al.Combining relation and content analysis for social tagging recommendation[J].Journal of Software,2012,23(3):476-488.
[2] 吕刚,王晓峰,胡春玲.基于本体学习的标签推荐方法研究[J].小型微型计算机系统,2015,3(3):424-426.
[3] 何继媛,窦永香,刘东苏.大众标注系统中基于本体的语义检索研究综述[J].现代图书情报技术,2011,203(3):51-56.
[4] 魏桂英,高学东,武森.基于领域本体的个性化文本信息检索[J].辽宁工程技术大学学报,2011(4):316-320.
[5] 张宗仁,杨天奇.基于自然语言理解的SPARQL本体查询[J].计算机应用,2010,30(12):3397-3400.
[6] 何伟,杨小平.基于词间语义关联性的本体扩展[J].计算机应用与软件,2011,28(11):73-76.
[7] 张胜.一种基于领域本体的语义检索模型[J].软件导刊,2014,13(3):18-21.
作者简介:
赵彦锋(1976-),男,硕士,高级工程师.研究领域:软件工程,网络安全.
周晓红(1968-),女,硕士,实习师.研究领域:软件工程,人事管理.
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
中国音乐学(2020年4期)2020-12-25 02:58:06
中国新通信(2016年22期)2017-01-13 08:22:08
计算技术与自动化(2016年4期)2017-01-11 14:04:00
电脑知识与技术(2016年21期)2016-10-18 23:20:17
新闻传播(2016年18期)2016-07-19 10:12:06
科技视界(2016年10期)2016-04-26 11:40:14
现代计算机(2016年11期)2016-02-28 18:35:15
文学教育(2016年27期)2016-02-28 02:35:15
河南科技(2014年11期)2014-02-27 14:10:19
