
基于JAVA建立树形结构的算法优化
2015-05-25 03:24:10宋小倩张书茂
大庆师范学院学报 2015年3期
宋小倩,张书茂,康 彦
(安徽城市管理职业学院 信息工程系 安徽 合肥230011)
0 引言
树形结构是指数据元素之间存在着一对多的树形关系的数据结构,是一类非常重要的非线性数据结构。树形结构可用于表示从属关系,层级关系等。本文介绍一种从普通Java 对象中建立树形结构的算法。
1 树形结构的算法设计
1.1 场景介绍
在教师信息系统中,基本信息模块中需要填写各种地址,包含户口所在地地址、家庭详细地址和当前居住地详细地址等。如果这些地址直接由输入框输入,则无法保证信息填写的信息准确性,另外在后续需要根据省、市、县等各类条件生成报表信息时会无法处理。因此,通过以树形形式提供选择框供选择,这样上面的信息准确性、后续条件过滤时出现的问题都可以避免。
而地址的原始数据与页面中树的展示格式相差较远。如何高效地根据原始数据生成树形结构便成为该模块中非常重要的问题。如果处理不好就会在使用树进行选择的时候出现卡顿现象,影响用户体验。下面详细介绍一种高效地在内存中构建完整树形结构的算法,供大家借鉴学习。
数据本身存储在数据库中,需要显示时则从数据库加载数据后进行显示。需要建立树形结构的时候,可以从最顶级节点开始按级查找下级所有子节点来构建树形结构[1]。优点:不需要一次性构建整个树形结构。缺点:每次展开某节点时,都需要去数据库查询该节点的所有子节点。数据库压力非常大,同时会导致界面操作出现卡顿现象。
可以考虑将树形结构需要的数据一次性加载到内存当中,在内存中构建树形结构的所有节点结构然后再显示。这样既可以减轻数据库压力,又可以增强用户体验[2]。
如图1给出省市县镇村的部分数据。其中code 列为身份证识别码,first 列为省,second 为市,third 为县,fourth 为镇,fifth 为村。现在即要在这种数据对象中构建省市县镇村多级树形结构。
因为每级结构都是文本数据,无法直接通过上一级节点直接得到下一级节点数据,更无法直接通过下一级节点得到上一级节点数据。比如通过“镇”列得到“村”列时,必须保证“镇”列所属的“省、市、县”是一致的。这样从省到村上下级关系来构建树形结构,则查询每个节点(除最后一级节点外)的所有子节点都需要遍历整份数据。假设整份数据有N 条,则需要遍历数据N^5 次,即遍历算法复杂度至少O(N^5)。如果数据为100 条则需要100^5=100 亿次。这种算法必然是不可行的。
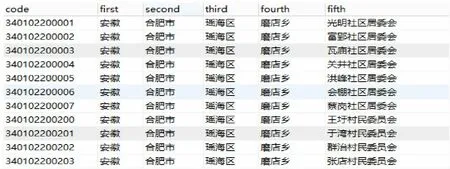
图1 省市县镇村数据(部分)
1.2 算法设计
图1这种数据在日常生活中是非常常见的。如果算法设计不当,则会得到O(N^5)的算法复杂度,在程序设计中必然无法接受。
分析这种方法的不合理的原因,主要有以下几点:
(1)每个节点都是无状态的。即每个节点都不是自说明的,而是由前面几级节点共同控制才能保证唯一性[3]。
(2)每次遍历数据都没有对数据进行缓存。因为没有缓存上一次读取的数据,导致处理任何一个节点的下一级节点时都需要再完整遍历一次整份数据。
为了解决节点的无状态问题,可以对每级节点进行编码,比如first 可以编码为01,second 节点编码为0101,third 节点编码为010101,fourth 节点编码为01010101,fifth 节点编码为0101010101。这种方法的优点是每个节点都是有状态的。缺点是每个节点在构建时需要先编码。
本文设计的算法则是对上述方法进行改进,即对每级节点做到状态自说明。方法即是在每级节点中记录上一级节点文本。比如记录“合肥市”则记录为“安徽@合肥”,“瑶海区”则记录为“安徽@合肥@瑶海区”,之后节点依次类推(假设分隔符号为“@”)。如图2为优化后的记录方式。这些记录只在内存中进行构建,不真正修改数据库。
从图中可以看出,该种处理方式是一种以空间换时间的解决方案。可以解决节点的无状态问题,但仍然无法解决需要多次遍历数据的问题。还需要对节点数据进行缓存。

图2 优化后的记录方式
在读取数据过程中要对层级关系进行存储,因为使用图2的优化后记录方式,再也不用担心节点名称重复的问题了。
如何预处理一遍数据则建立上下级层级关系呢?使用一个关系容器(假设名称为dataMap)记录上下级层级关系,所有层级关系存储在同一个关系容器当中。如first 与second,second 与third 等都存储起来,过滤掉重复的记录[4]。
关系容器记录后效果如下(“=>”或“/”符号只用于说明上下级关系,不代码具体存储方式):
安徽=>安徽@合肥市/ 安徽@芜湖市...
安徽@合肥市=>安徽@合肥市@瑶海区
安徽@合肥市@瑶海区=>安徽@合肥市@瑶海区@磨店乡
安徽@合肥市@瑶海区@磨店乡=>安徽@合肥市@瑶海区@磨店乡@富郢社区居委会/ 安徽@合肥市@瑶海区@磨店乡@瓦庙社区居委会...
上面仅解决了如何记录数据和存储数据,还没有真正地建立树形结构。
有了上述的数据,再来建立树形结构则非常方便了。假设需要生成的树形结构数据如图3的JSON格式。
在图3中,对于每级节点记录文本数据(text)和子节点数据(children)。如果该层节点没有子节点仅记录text 而不记录children。

图3 需要的树形结构数据
2 算法实现
第1 部分已经非常清晰地将算法设计出来了,下面使用Java 来实现该算法。
2.1 算法的Java 实现
优化数据记录实现如图4所示。其中,srcList 是源数据,可以从数据库中加载或在程序中模拟。nodeList 是需要构建树的节点名称。dataMap 用于记录节点与下级节点的map 数据。rootList 用于记录根节点数据。cnMap 用于记录每个节点所有子节点数量。
询多个节点的子节点数据的实现如图5所示。其中map 为图4中输出的dataMap。keyList 为多个节点的名称。cnMap 为图4中输出的cnMap。
图6为构建树形结构程序的入口。输入参数为srcList,可以从数据库中加载或在程序中模拟。nodeList 是需要构建树的节点名称,传入想要构建树的字段即可[5]。
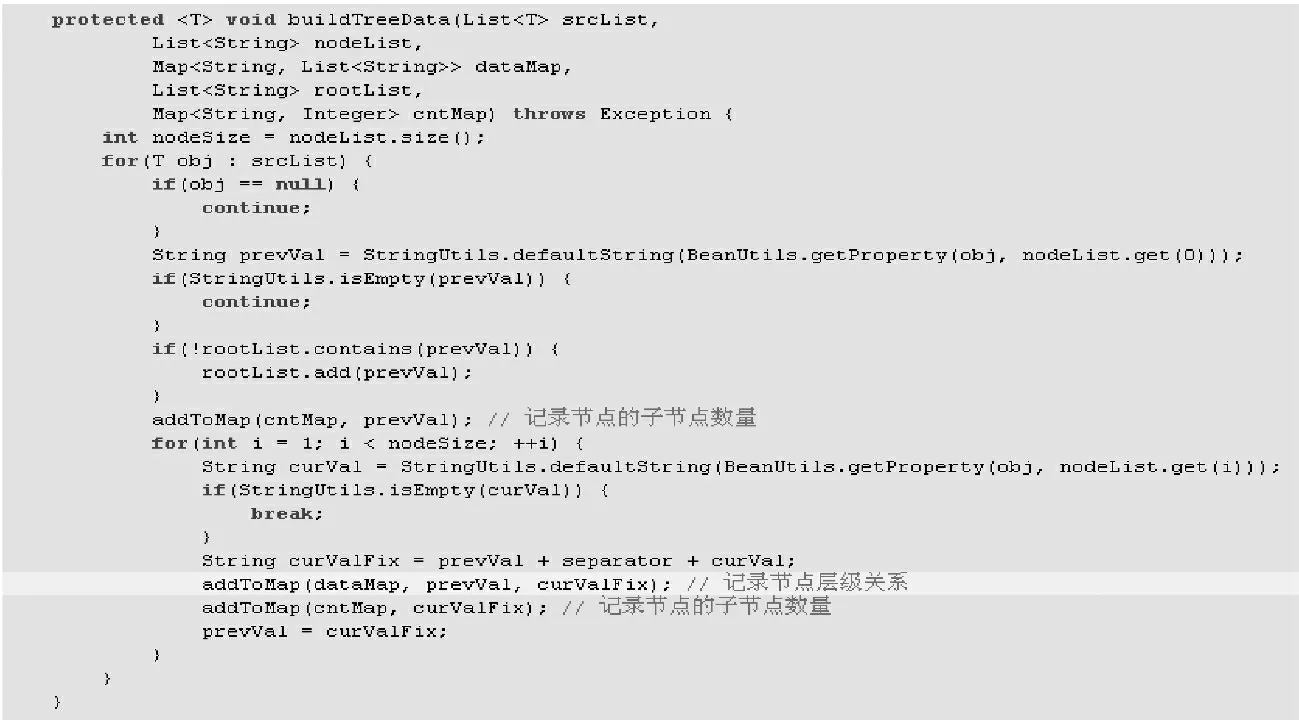
图4 优化数据记录的实现
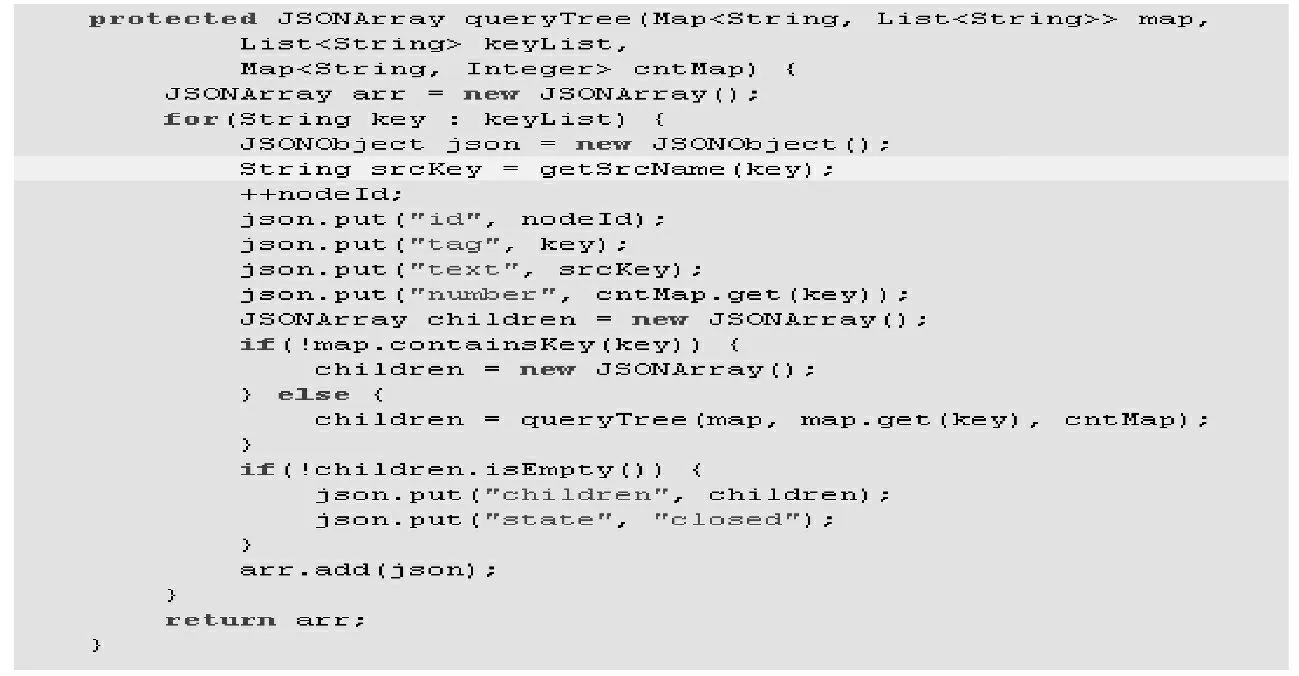
图5 递规查询多个子节点的实现
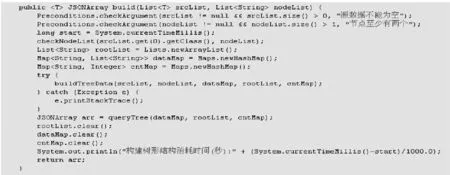
图6 构建树形结构的实现
2.2 实现效率和效果
在Java 中实现该算法是非常高效的,构建树的效率也是非常高的。
使用全国的省市县镇村的数据来构建树,原始数据有70 万条左右。在Windows8 中构建该树的5 级结构只需要5 秒左右。
如果使用安徽省的数据来测试,原始数据是2 万条左右。构建该树的5 级结构只需要0.2 秒左右。
显示的效果如图7所示。左边的图即是普通的树形结构显示,右边的图中每级节点显示时加入了其对应的所有子节点个数。

图7 树形结构显示效果
3 结 语
本文描述了从普通对象中建立树形结构的一种算法设计,并使用Java 语言进行了实现。如果需要建立相关树形结构会非常方便。
通过使用文中所述的根据对象集合建立树形结构算法,即可高效地创建页面中需要的树形结构,提升页面展现效果,有效地解决了系统中多处地址选择问题,达到了预期效果。另外,文中对该算法也使用高效的方法进行实现,如果需要建立相关树形结构直接借鉴即可。
[1]严蔚敏等.数据结构:2 版[M].北京:清华大学出版社,2012.
[2]Thomas H.Cormen 等.算法导论:3 版[M].北京:机械工业出版社,2013.
[3]严蔚敏等.数据结构题集(C 语言版)[M].北京:清华大学出版社,2011.
[4]韦斯等.数据结构与算法分析:Java 语言描述[M].北京:机械工业出版社,2009.
[5]王希军.java 程序设计案例教程[M].北京:北京邮电大学出版社,2012.
猜你喜欢
花卉(2024年1期)2024-01-16 11:29:12
红蜻蜓·低年级(2022年3期)2022-03-16 12:33:40
河北果树(2022年1期)2022-02-16 00:41:10
红蜻蜓·低年级(2021年3期)2021-03-18 02:05:36
安徽教育科研(2019年6期)2019-07-03 04:24:32
现代园艺(2017年19期)2018-01-19 02:50:30
现代园艺(2017年13期)2018-01-19 02:28:17
中国卫生(2016年6期)2016-11-23 01:09:20
中国卫生(2016年8期)2016-11-12 13:27:12
中国卫生(2016年8期)2016-11-12 13:27:02
