
托忒文(TODO)办公套件的开发研究∗
2015-05-16 10:57艾尼宛尔托乎提达瓦伊德木草吾守尔斯拉木哈尔肯别克木哈西买买提哈斯木
新疆大学学报(自然科学版)(中英文) 2015年2期
艾尼宛尔托乎提,达瓦伊德木草,吾守尔斯拉木,哈尔肯别克木哈西,买买提哈斯木
(1.新疆大学新疆维吾尔自治区多语种信息技术重点实验室,新疆乌鲁木齐830046;2.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;3.武汉理工大学计算机科学与技术学院,)
0 引言
居住在新疆地区的蒙古族自从17世纪开始一直沿用一种称作为托忒(TODO)意为易于认读,便于手写的文字)的文字系统.该文字是在蒙古民族从13世纪以来沿用的传统蒙文(Traditional Mongolian TM,又称老蒙文)的基础上做了语言学的改革而创建的一种比较进步的文字系统.目前世界范围内的蒙古民族使用3种不同字母系统的文字语言,如图1所示,即TM,TODO和NM(西里尔蒙文)[1].

图1 蒙文多文字系统
TM文字系统主要在中国内蒙古地区使用,从20世纪80年代初期开始,在新疆教育领域普及使用;TODO文字系统一直在新疆地区和俄国的卡里梅克联邦国使用;而NM文字系统是蒙古国从20世纪40年代开始借用斯拉夫文字拼写蒙古文的一种新文字系统.这三种文字系统除了文字符号不同之外,构词规律、成句以及使用词汇方面均有较大的差别.但是,它们语法规则基本相同,都属于阿勒泰语系语言,在信息处理领域属于少数民族复杂文体.
计算机信息处理技术的日益发展,尤其是各种办公软件的开发利用,大幅度地提高了我们的工作效率.但是,少数民族语言文字的办公软件还处在一个初期研发阶段.以蒙古语TODO文为例,由于国内外开发的办公套件的界面和排版习惯尚缺乏对TODO文的支持,处理技术不完整,电子化办公及通信效率较低.因此,在办公自动化的新趋势下,迫切需要解决TODO文排版问题及现行市场软件相互兼容等实际问题[2].
TODO文是居住在新疆的蒙古族传承本土文化,交流思想的母语.TODO文字结构相比于TM和NM文字系统有独特的符号学、音韵学及语言学特点.毫无疑问,解决TODO文的计算机处理办公套件的开发利用问题,对于发展我国新疆少数民族地区经济、提高该地区的信息化水平和各民族的文化素质等都具有重要意义.因此,自治区科技厅2012年专门在科技支疆项目中设立《研发TODO文办公套件》项目计划,支持促进TODO文办公系统的升级和应用,提高TODO文书籍、报刊、杂志出版印刷效率,更好地服务于新疆经济建设和社会发展.
本文研究在通用办公软件Libreoffice的基础上开发基于OpenType字库技术的TODO文输入法技术.
1 TODO文处理的特点及涉及到的规则
1.1 TODO文基本特征
现行蒙古文是世界上公认的一种最为复杂的文本语言之一.它属于拼音文字,但是由于诸多的历史原因,蒙古文字在发展过程中又借鉴了其它文字的一些特性,因此它又有别于一般的拼音文字.在ISO/I EC 10646编码中,为蒙古文提供了176个码位,Unicode编码区为1800一18AF[3].目前,依据蒙古文编码国际/国家编码标准及用户协定,在Windows Vist/7/8,IOS等平台上,依托其复杂文本布局引擎,开发OpenType字体,再配合一个简单的键盘映射输入法既可以实现蒙古文的录入和名义字符到变形显现字形的转换显示.这给我们在通用Windows版本上开发TODO文办公软件提供了便利的条件.
本文研发的TODO文办公套件是完整的,独立的TODO文国际/国家标准码解决方案,它将使TODO文电子化处理全过程完全数字化,包括信息采集、录入、稿件审批、排版、输出(包括输出纸制报纸和数字报刊)等过程.其中,TODO文字库和输入法是TODO文信息化的基础.
现代TODO文是在古代TODO文(1638年)的基础上形成的拼音文字,共有36个字母.TODO文是一个复杂文本语言.TODO文字显现形式与Unicode中的编码字符不是一一对应的,并且字符(character)与字形(glyph)也不是一一对应的.字符是表示语音最小单位的符号,字符在计算机中是以编码形式表现的.字形是字符显示时的表现形式,只有在显示的时候才有字形的概念.TODO文有如下特征:
1.字符在单词的不同位置有着不同的字形(显现形式),即独立形式(Isolated),词首形式(initial),词中形式(medial)以及词尾形式( final)等4种显现形式.图2给出了TODO文一个字符编码uni1820(A)的字符(独立1)以及在单词中的不同显现字形.比如字符“uni1820_A”存在两个词中形式(词中1,词中2)和两个词末形式(词末1和词末2);
2.TODO文的书写形式是从上到下,从左到右,字符不等长且有连接显示的特征;
3.TODO文有名义字符和显现字符之分,一个名义字符有多种显现形式;
4.在TODO文的词中大量存在“一字多形,多字同形”的现象.一个字符更因其在上、中、下位置不同而字形不同(变形).因此,在计算机上输出TODO文时需要频繁地把一个字符的某一种形状替换成另一种形状,用计算机自动实现此过程的方法称为自动选形.在制作TODO文字库时需要定义自动选形脚本,解决“名义字符”与“显现字符”之间“一对多”和“多对一”的显现问题.
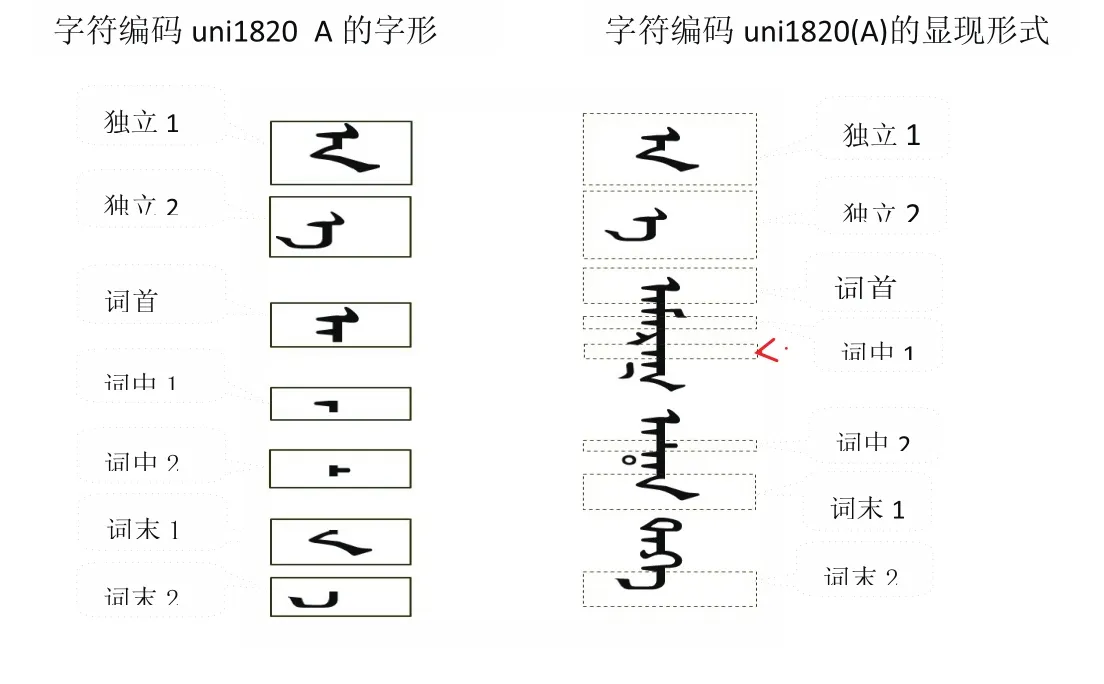
图2 字符编码uni1820显现形式和成词举例
1.2 TODO文涉及到的规则
书写TODO文的时候,从上到下连着显示TODO文的各个字符,但是这些字符的出现情况是有规律的.所以我们考虑名义字符到显现字符映射的时候,必须对这些规律进行分析.涉及到的规律如下:
1.一个字形可以由多个字符组成,如:合体字是字符和构成的;
2.一个字符可以有多个字形,根据词里位置的不同显示不同字形,如图2左边字符;
3.字母受它前面字母的结束选择不同显现形式,如:由字母结束时,选择字符的显现形式,而其他字母由字符结束时,选择的显现形式.
4.长元音字母受它前面字符的不同选择不同字形,如前字符为时,选择显现形式,而为时,选择显现形式,时,选择显现形式;
5.音节在词里位置的不同显出不同的显现形式,如TODO文元音字母,在词首出现显现形式,词中非第一音节出现显现形式,而词尾出现显现形式.
6.TODO特殊习惯性显现字符,如两个显现字符/i/和/a/在词尾连接时选用的显现形式.
2 相关技术介绍
2.1 OpenType字库技术
OpenType字体格式是TrueType字体的一种扩展,它融合PostScript字体技术,同时,OpenType字库使用Unicode编码,可以处理大的字型集,能更好地支持国际化处理,其有跨平台特性,是一个开放,无版权的字形描述技术.OpenType字库在原有的TrueType字库的基础上增加了OpenType的排版特性使其升级到OpenType字库格式,这些排版特性的加入可以更好地控制字型的替换和排版位置,对复杂文本的处理提供了很好的技术支持.OpenType对复杂文本的支持通过OpenType布局(Layout)来实现.复杂文本处理涉及到的布局表,由字形替换表GSUB(Glyph Substitution)和位置表GPOS(Glyph Positioning)组成.
GSUB表:GSUB表实现了字型ID到字型ID的替换,用它可以解决TODO文根据上下文选择恰当显现字形的问题.GSUB表中定义了如下替换:
①单一替换:以一个字型替换另一个字型;②多替换:以多个字形替换一个字型,如连字的分解;③变体替换:字符的多个变体之一来替换字符对应的字型;④连字替换:以连字字型替换一串字型;⑤上下文替换:是上述几个替换的组合运用,在上下文中替换一个或多个字型;⑥链上下文:在链上下文中替换一个或者多个字型.
GPOS表:该表提供了字型位置和粘着的信息,它支持如下的几种位置和粘着(attachment)类:①单一字型的位置调整,如上标或下标;②相关的两个字型的成对位置调整,如字间距的调整;③粘着点位置信息的粘着点定义了一个字.字型和另一个字型的粘着时粘着点位置的信息[5].在Windows Vista和Windows 7以及Windows 2008之后的服务器产品支持了这种复杂字形转换显示功能的OpenType.在Windows Vista和Windows 7上提供了一种OpenType字体Mongolian Baiti.
2.2 TODO文OpenType字库的实现
Volt是Microsoft提供的用来制造字库的工具.在Volt中可以增加许多OpenType特征.在前面提到的OpenType布局表都在Volt中定义,再把复杂文本的各种替换规则定义在OpenType布局表中.其中GSUB表和GPOS表覆盖了几乎所有复杂文本的处理要求,包含了在字形处理过程中用到的所有有关替换和相关字型位置的信息.OpenType对布局表的访问是通过标签来实现的,OpenType定义的标签有:文字(script)标签、语言(language)标签、特征(feature)标签等.OpenType的高级排版特征是通过特征标签实现的.GSUB表中包含若干个特征表,这些特征表中的lookup子表来完成名义字符的字形到显现字符的映射和各种有关字符的替换.而各特征表之间没有从属关系[6].
TODO文种涉及到的相关特征有:根据上下文的替换(Contextual Alternates¡calt¿),词首形式(init),此种形式(medial),合体形式(Liga),词尾形式( final).每一个特征的具体变化规则定义在对应的Lookups表中.
2.3 LibreOffice介绍与本地化
Labreoffice是OpenOffice.org办公套件的衍生版,是一套自由的办公软件,同样免费开源,以GPL许可证分发源代码,但相比Openoffice增加了很多特色功能.Libreoffice拥有强大的数据导入和导出功能,能直接导入PDF文档、微软Works、LotusWord,支持主要的OPenXML格式.软件本身并不局限于Debian和Ubuntu平台,支持Windows、Mac、PRM package Linux等多个系统平台.
Libreoffice包括Writer、Calc、Impress、Draw、Math、Base等六大组件.Libreoffice不仅是这六大组件的组合,他们不是以独立软件模块形式创建的,从一开始,它就被设计成一个完整的办公软件包,可在各种平台上执行.对于一个免费的、全功能的软件套件来说Libreoffice没有微软那样的花样式菜单,但它仍然具有现代性并且容易使用.此外,Libreoffice能够与Microsoft Office系列以及其它开源办公软件深度兼容,且支持的文档格式相当全面[7].
2.4 Libreoffice的本地化框架
由于采用了开源软件许可,Libreoffice对于推动办公套件的使用,发挥了至关重要的作用.Libreoffice软件已经被翻译成多种语言,并运行在所有主流操作系统之上,应用程序的扩展亦为它增添了新的功能.Libre office由本地化框架的结构来组织本地环境(Locale)的信息,本地环境的每组信息都是一个组件.
Libreoffice的本地化框架采用一种利用桩的回退机制(Fallback Mechanism Using Stub)来调用本地化组件.
3 TODO文排版技术的实现
3.1 TODO文竖立排版显示
针对TODO文从上到下、从左到右排版特点,本项目研发了基于以Libreoffice4.0为基础的TODO文竖立排版显示技术.比如字符编码uni1820A在不同位置自动选形显示实现结果如图3所示.图中实线方块中黑体部分表示字符编码uni1820_A在一个行不同词不同位置显现形状.
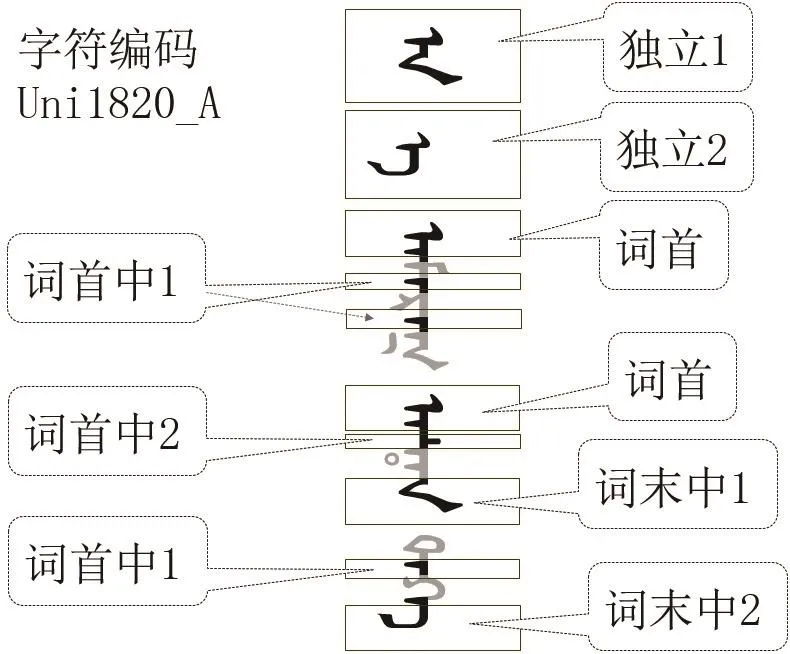
图3 字符编码uni1820_A在一行不同词不同位置的排版效果
3.2 TODO文与多文字系统混合排版编辑技术
不同文字的基线不同,尤其是竖立排版特点的TODO文与英文,中文等多文种在基线对齐排版中比较困难.传统的TrueType字体技术无法满足这一需要,需要支持OpenType字体技术,根据基线来调整不同语言文字的显示位置,使得TODO文、中文以及英文等其它文字混排时左右对齐显示.本系统输入法实现TODO文,英文,中文以及日文混排实例演示如图4所示.(实际上竖立排版).

图4 TODO系统实现多文字混合排版显示效果
3.3 研究TODO文竖立排版按词或者按音节断行
现行大多数蒙文处理软件选用传统TrueType字体技术,无法满足竖立排版编辑时行末自动对齐问题.

图5 研发系统按词断行换行效果
本项目采用OpenType字体技术,使得TODO文在排版过程中按词断,行末TODO文断词后,剩余空间由空格,TODO文拉升以补充对齐.图5为研发系统在排版时在行末按词断行处理效果演示.
3.4 单词中任意位置插入或删除字符功能
现行大多数蒙文处理软件选用传统的TrueType字体技术,缺乏词中插入字符自动变形或选形功能,往往采取删除全词重新录入方法,智能化程度较低.本项目采用OpenType字体技术,使得TODO文在排版过程中可以在任意位置插入任意字符并自动选形.图6为现行蒙科立TODO文处理系统与本研发系统录入一个词/harausun/(黑水/乌苏)时的比较结果.
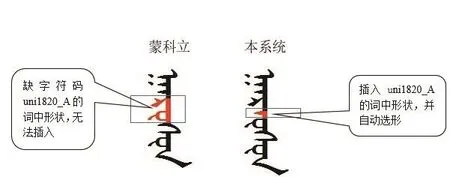
图6 研发系统单词任意位置实现字符的插入删除效果
3.5 TODO文长元音输入法的实现
与其他蒙文类文本相比,实现TODO文长元音词的输入法比较复杂,而且现用Post.TODO文中一个词的长元音形式表现,并不是一个字符形态的选形,而是根据字符形态上下字符的不同选三种特定字符编码录入实现长元音词.
图7显示TODO文词中录入三种长元音字符编码规则.TODO文长元音词的录入主要通过OpenType字形技术的变化属性嵌入到字体文件中,通过字符编码uni1843,uni1845和uni1849的字体描述表实现.本项目实现TODO文长元音输入法实现效果如图8所示.TODO文长元音键盘录入方式为各长元音字符双击方法.即,/aa/,/ee/,/ii/,oo/,/uu/./shift oo/,/vv/.
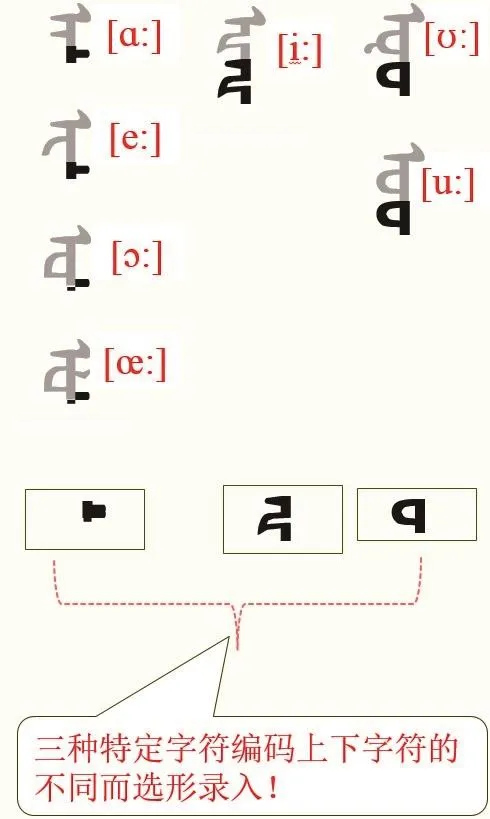
图7 TODO文长元音规则

图8 TODO长元音输入实现效果
4 TODO文输入及键盘布局
4.1 TODO字符出现频率统计
由于现行蒙文处理软件输入法键盘的设计制定主要考虑了传统蒙文字母特点.这种键盘的设计方法既不符合TODO文字符发音规则,又不全对应中文键盘英文26字母位置[8].比如一个英文词/olon/,按现行蒙文键盘录入时要键入/clcn/.这不符合原词发音规则,难以记忆,会误录入.本系统开发中首先研制50K(5万词)的TODO标准语法词典,再次,用名义词拉丁字母形式撰写词典各词,最后统计TODO文名义字符出现频率制定TODO文录入键盘位置.TODO文各字符出现频度结果由图9所示.
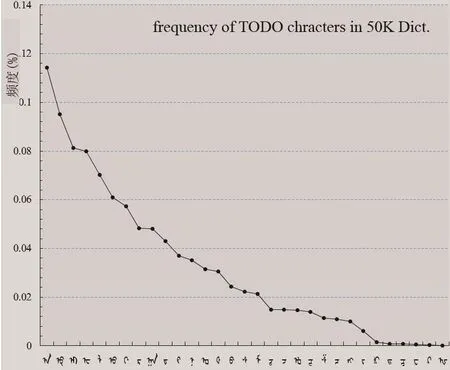
图9 TODO文名义字符出现频度统计
本研究新设立TODO文键盘位置方案与中文键盘26个英文字母相对应,其余字符并用shi fit键配合录入.图10显示本项目研发制定TODO文录入键盘新标准.其中图11为常用英文26个字母对应录入方式,而图10为不对应26个英文字母的TODO文字符,配合用Shift键实现录入.
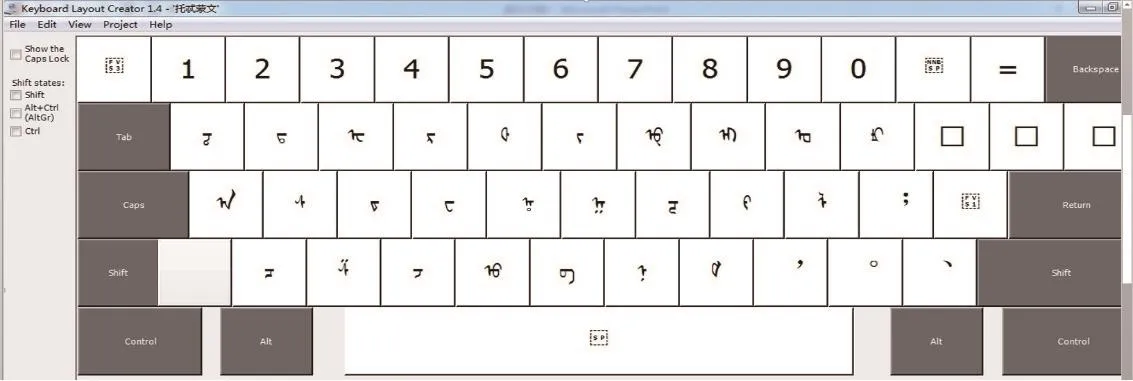
图10 TODO文键盘标准(26个英文字母对应)
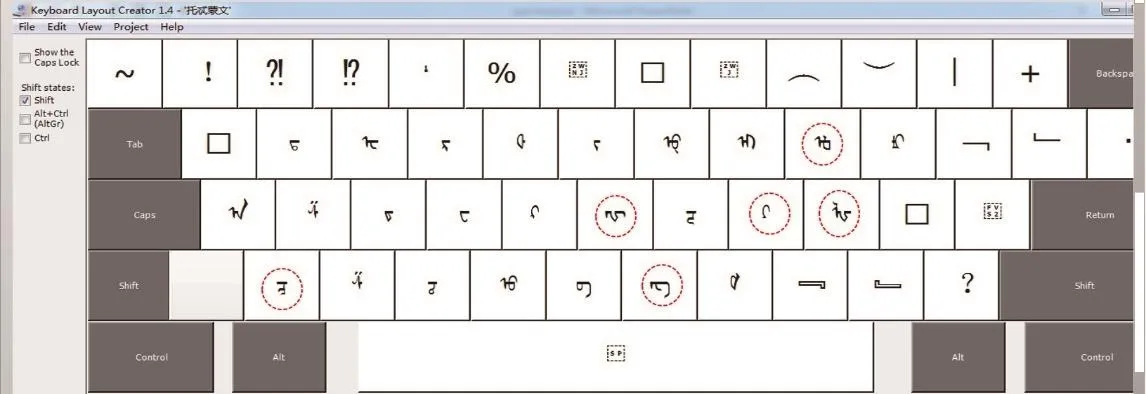
图11 TODO文键盘标准(26个英文字母及shift键合用)
4.2 TODO文字符集及键盘位置设置
目前,TODO字符集(Alphabet)拉丁转写标准不统一.语言学者常用国际音标法标记TODO Alphabet,难以用中文键盘英文26个字母键盘上实现.
另外,现行传统蒙文处理中,蒙文键盘拉丁录入法不适合拼音法,也不适合TODO文拼音法.本项目设置TODO文字符集及键盘录入对应关系如表1所示.其中x(红色标志)表示对应字符与shift键合用实现录入.

表1 TODO文名义字符字符集及中文键盘文拉丁字母对应关系
5 结束语
OpenType技术给复杂文字的处理带来了新的契机,本文在研究OpenType字库技术的基础上,针对TODO文字形变化规则,编写了TODO文OpenType字形处理脚本,最终研发了基于Unicode国际编码标准并符合TODO文特征的TODO文办公套件.
该TODO文软件的实现对新疆地区在用蒙文的信息化、电子政务化以及互联网通信等方面带来极大的推动作用.该软件经在不同地区用户的实际试用情况表明,该办公软件的设计,字符显示以及其他功能基本符合TODO文字的使用习惯.
该系统处理功能的扩展,TODO文字形设计的完善以及扩大字库是我们今后工作的重点.
参考文献:
[1]MONGOLIAN GRAMMAR d,Tserenpil R.Kullmann[M].Ulaabaatar,2005.
[2]加木查.托忒文字研究[M].乌鲁木齐:新疆大学出版社,2014.
[3]确精扎布.蒙古文编码[M].呼和浩特:内蒙古大学,2000.
[4]吾守尔·斯拉木,胡尔西丹,艾尼宛尔·托乎提,等.信息交换用维哈柯文代码标准研究[J].标准化研究,2010,30-36.
[5]http://www.Openoffice.org.
[6]袁保社,袁晓琴.维吾尔文OpenType字库设计与实现[J].软件设计开发,2008,672-677.
[7]肉克艳木·买买提,吾守尔·斯拉木,艾尼宛尔·托乎提,等.基于Labreoffice的维吾尔文断行算法的研究与实现[J].计算机工程与科学,2014,36(10):2014-2017.
[8]白双成,张劲松,呼斯勒.蒙古文输入法输入码方案研究[J].中文信息学报,2013,27(6):167-173.
猜你喜欢
销售与市场(营销版)(2020年9期)2020-11-25
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
制造技术与机床(2018年9期)2018-09-19
——以方正诉宝洁案为例
法制博览(2018年20期)2018-01-22
新疆农垦科技(2016年2期)2016-08-21
新疆农垦科技(2016年2期)2016-08-21
中国机械工程(2015年13期)2015-12-16

- 新疆大学学报(自然科学版)(中英文)的其它文章
- WSNs中基于Chebyshev多项式的可认证密钥协商方案∗
- 新疆双峰驼乳清蛋白组分对人宫颈癌HeLa细胞增殖的抑制作用∗
- 新疆加曼特金矿与斑岩型金矿的对比研究∗
- 具有非倍测度的参数型Marcinkiewicz积分交换子在Hardy空间的估计∗
- Periodic Solution of a Two-species Competitive Model with State-Dependent Impulsive Replenish the Endangered Species∗
- Permanence and Extinction for Nonautonomous SIRS Epidemic Model with Density Dependence∗