
行车噪声环境下基于人耳频率选择特性的声学特征提取方法
2015-04-29 00:44:03裴孝中郑铁然韩纪庆
智能计算机与应用 2015年3期
裴孝中 郑铁然 韩纪庆
摘 要:本文提出了一种基于加权Mel滤波器组的声学特征提取方法。该方法通过提取音频信号中的共振峰信息,使用动态自适应方法对中高频部分的Mel滤波器组进行加权,从而模仿人耳覆膜的频率选择映射。相比较于传统的MFCC特征,更适用于行车噪声环境下的快速声学事件检测任务;弥补了传统的Mel滤波器组高频部分分辨率低,从而导致对噪声鲁棒性较差的问题。实验结果表明:在信噪比较低的行车环境中,该特征有助于提高声学事件的检出率。
关键词:声学事件检测;鲁棒性特征提取;行车噪声环境;动态自适应;MFCC
中图分类号:TP391.4 文献标识号:A 文章编号:2095-2163(2014)02-
An acoustic feature extraction approach based on frequency selectivity of human auditory under driving noisy environments
PEI Xiaozhong, ZHENG Tieran, HAN Jiqing
(School of Computer Science and Technology, Harbin Institude of Technology, Harbin 150001,China)
Abstract:This paper presents an acoustic feature extraction approach based on weighting Mel filter banks. By extracting the formant information of audio signal, this method uses dynamic adaptive method for weighting high-frequency part of the Mel filter bank to achieve the purpose of simulating the auditory frequency selection mapping. Compared to the conventional MFCC feature, the proposed feature is more suitable for the fast acoustic event detection under driving noise task and makes up the poor robustness of the traditional methods which is resulting with the low resolution of Mel filter bank at the high-frequency part. The experiments show that the proposed feature helps to improve the detection rate of acoustic events in the low SNR driving environment.
Keyword: Acoustic Event Detection; Robust acoustic feature extraction; driving noisy environments; Dynamic Adaptive; MFCC
0引 言
声学事件检测(Acoustic Event Detection, AED)就是检测当前环境中发生的特定目标声学事件,然后把检测出的声学事件转换为人类或者智能设备可以理解的信号,为人类或者智能设备的决策提供信息。在声学事件检测研究中,研究者们做出了大量的贡献。目前研究主要聚焦在提取适合检测任务要求的声学特征表示和声学事件的分类算法方面。在声学特征方面,研究者们尝试了各种声学特征,如:梅尔倒谱系数(Mel-frequency cepstral coefficients, MFCC)[1]、线性预测倒谱系数(Linear prediction cepstral coefficients, LPCC)[2]、 基频(Pitch)[3]、频谱质心(Spectral centroid)[4]等。在声学事件的分类方法中,研究者们也尝试了各种不同的方法,包括基于支持向量机(Support Vector Machine, SVM) 方法、隐马尔科夫模型(Hidden Markov Model, HMM)方法、人工神经网络(Artificial Neural Network, ANN)方法等。近几年来,SVM方法[5]和HMM方法[6]成为最主流的声学事件分类方法。
在本文的研究工作中,将会尝试在行车噪声环境下,检测车辆周边发生的各种目标声学事件。由于行车中的声学环境较为复杂,当车辆行驶速度较快或者路况较差等情况存在时,噪声频谱污染就较为严重,传统的声学特征,例如:MFCC在中高频部分的滤波器分布较为稀疏且处此滤波环境下,而中高频部分噪声较强时,目标声学事件的检出率即会显著下降。
对强噪问题,研究者们通常采用降噪模式来增强目标声音信号的方法,如:高斯模型假设下的维纳滤波增强算法[7]、基于听觉掩蔽效应的增强算法[8]、谱减法[9]等。综合评析可知,基于高斯模型的滤波方法计算复杂度较高;基于听觉掩蔽效应的语音增强算法则不能充分地模拟人耳对于声音的感知;而在降噪中普遍使用的谱减法却存在“音乐噪声”的问题,导致降噪后声音信号的频谱破坏较为严重,使得提取出的特征不能很好地刻画声音信号的目标声学事件的频谱特性。
耳蜗是人类接收和处理外界声音信号的主要器官,在提取可辨性的声音特征,以及对背景噪声的鲁棒性方面均表现出高强的能力。耳蜗生理学研究成果表明,耳蜗的这种能力主要来自于以下几个方面:基底膜的频率分析功能、外毛细胞/覆膜的主动选择性增益功能等[10]。其中,基底膜的主要功能是将接收到的声音信号分解为各个频率上的振动峰值,并将相应的振动传递给外毛细胞和内毛细胞;外毛细胞/覆膜则主要依据接收到的振动对特定频率处的能量进行选择性增益,影响相应位置处的内毛细胞发放强度。
针对传统声学事件检测方法存在的问题以及人耳中耳蜗的听觉感知特性,本文提出了一种模拟人耳听觉感知的基于共振峰的Mel滤波器组的加权算法,通过模拟人耳的听觉感知特性,加强了Mel滤波器组对中高频的分辨能力,并采用加权后的Mel滤波器组提取FMFCC(Formant-MFCC, FMFCC)系数。实验证明,FMFCC对噪声有更好的鲁棒性,并且在目标声学事件信号较弱时,也不会增加误识率。
1共振峰的提取
声音信号的倒谱可以通过先对信号做傅里叶变换、取模,得到信号的频谱密度,然后求频谱密度的对数,最后求反傅里叶变换得到。根据参数模型功率谱估计的思想,可以将声音信号 看作一个输入序列 激励一个全极点的系统 而产生的输出,系统的传递函数为:
……………………………(1)
其中, 为常数, 为实数, 为模型的阶数。
由于频率响应 反映了被分析信号的频谱包络,因此用 来代替频谱密度,对 求对数后,做傅里叶反变换求出的LPC倒谱系数,也被认为包含了信号频谱的包络信息,因此将其看作是对原始信号短时倒谱的一种近似。
的冲击响应为 。欲求 的倒谱 ,根据同态分析法,因为 是最小相位的,所以 一定可以展开成级数的形式,即 的逆变换 是存在的,可得:
……..….(2)
因此,只要计算出线性预测系数 ,就可以求出倒谱 ,通过对倒谱 进行搜索,找到每一个共振峰所在的频率,记为 ,其中 表示共振峰的个数。
2 Mel滤波器组的加权
2.1模拟频率选择性增益功能
人耳的选择性增益功能对人耳耳蜗的听觉感知至关重要,人耳的选择性增益机制主要包括:频率相关的增益区间和增益函数。考虑到人耳覆膜的行波振动范围有限,因此其频率增益区间仅局限于中心频率附近[11];增益函数在频域的对数尺度上近似于高斯函数,在共振峰频率处的增益幅度最大,而在共振峰频率两侧的增益幅度迅速衰减。这即导致共振处的频率振幅能量在急剧增加的同时,两侧的频率振幅能量急剧降低,表现出人耳的频率选择性增益功能。
下面给出一种方法把LPC谱估计法提取出的共振峰的信息应用到Mel滤波器组中,从而弥补Mel滤波器组在中高频分辨率不足的问题。
考虑到在频率的对数尺度上,耳蜗的频率增益曲线类似于高斯密度函数,在共振峰处,耳蜗的频率增益最大,而在共振峰所在频率的两侧,耳蜗的增益幅度迅速衰减,根据以上分析,设计了如下函数来模拟耳蜗基底膜与覆膜之间的频率选择增益函数:
……(3)
其中, 表示第 个子带的频率中心, 表示第 个子带的宽度, 表示Mel滤波器组中包含的Mel子带的个数; 表示检测到的第 个共振峰的频率, 表示第 个共振峰的振幅在 个共振峰的振幅总和中所占的振幅能量的比例,该比例用来表示第 个共振峰的强弱; 是一个指示性函数,如果共振峰 的频率在以 为中心,以 为宽度的第 个Mel子带中,则返回1,否则返回0。
2.2 Mel滤波器组的加权
通过对每一帧中共振峰所处的Mel子带对应的Mel滤波器系数进行加权,突出共振峰所在的Mel子带的频率,从而模仿人耳覆膜的频率选择映射,由此即弥补了Mel滤波器组在中高频分辨率较低的不足,同时也增强了传统MFCC对噪声的鲁棒性。这符合人耳的听觉感知机理,如在众多嘈杂的背景环境噪声中,要想别人听清楚自己说话,必须提高声音的分贝,掩盖其他背景声音。
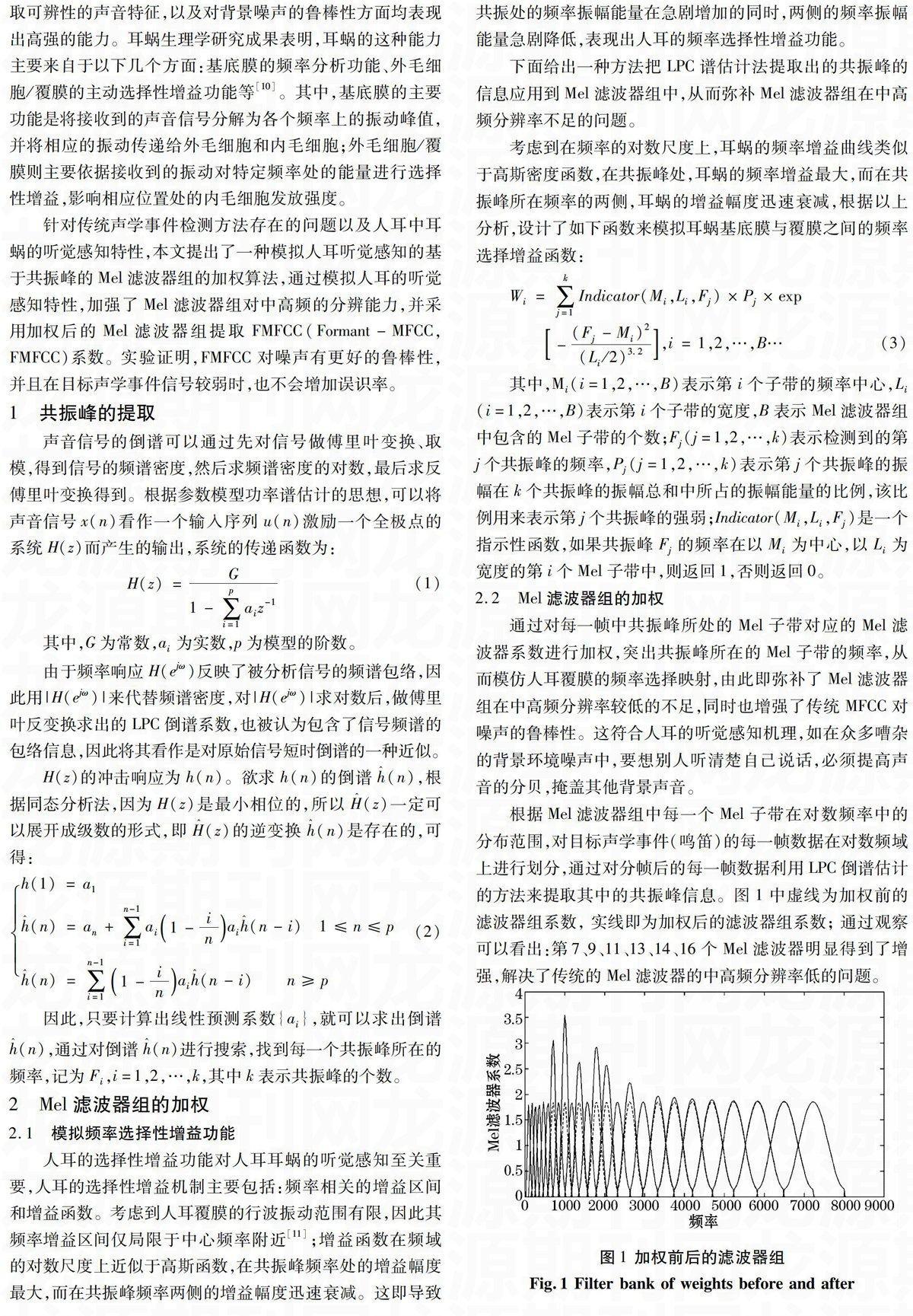
根据Mel滤波器组中每一个Mel子带在对数频率中的分布范围,对目标声学事件(鸣笛)的每一帧数据在对数频域上进行划分,通过对分帧后的每一帧数据利用LPC倒谱估计的方法来提取其中的共振峰信息。图1中虚线为加权前的滤波器组系数,实线即为加权后的滤波器组系数;通过观察可以看出:第7、9、11、13、14、16个Mel滤波器明显得到了增强,解决了传统的Mel滤波器的中高频分辨率低的问题。
图1 加权前后的滤波器组
Fig.1 Filter bank of weights before and after
3 基于加权后的Mel滤波器组的FMFCC特征提取
首先对采集的声音信号进行预加重、分帧、加窗等预处理,然后对每一帧的数据使用LPC倒谱法提取共振峰的信息,接下来根据提取的共振峰信息以及Mel频域子带的划分确定当前数据帧的每一个Mel滤波器的加权系数,从而获得加权后的Mel滤波器组,此后对每个滤波器的输出进行指数压缩,再对经过指数压缩的能量谱进行离散余弦变换,并经过升半正弦倒谱提升,最终得到FMFCC特征。
4实验结果与分析
根据本文提出的加权Mel滤波器组进行车载系统的鸣笛声学事件的检出实验。在实验中,搭载声学事件检测系统的车辆分别在不同的速度和不同的路况下对测试数据进行采集,测试数据中长鸣笛(每一个长鸣笛时长大于1.5秒),包括100个,短鸣笛(每一个短鸣笛时长小于1秒),包括为100个,笛语(由不同的长、短鸣笛序列组成)25个。基线系统使用的特征是传统的MFCC,而实验系统使用的是加权后的Mel滤波器组提取的特征,具体的实验结果如表1所示。
通过分析表1可以获知,与传统的MFCC特征相比,加权后的FMFCC特征有着更高的召回率和更低的误识率,因此FMFCC更适应于行车噪声环境下的声学事件检测。
表1 加权前后的检测系统性能对比
Tab.1 Comparison of detection systems performance of weights before and after
AE
指标 长鸣笛 短鸣笛 笛语
基线系统 实验系统 基线系统 实验系统 基线系统 实验系统
R(召回率) 75% 86% 72% 80% 63% 75%
D(误识率) 5.7% 5.9% 9.7% 9.7% 31.3% 31.5%
响应时间(s) 125ms 139ms 125ms 139ms 150ms 169ms
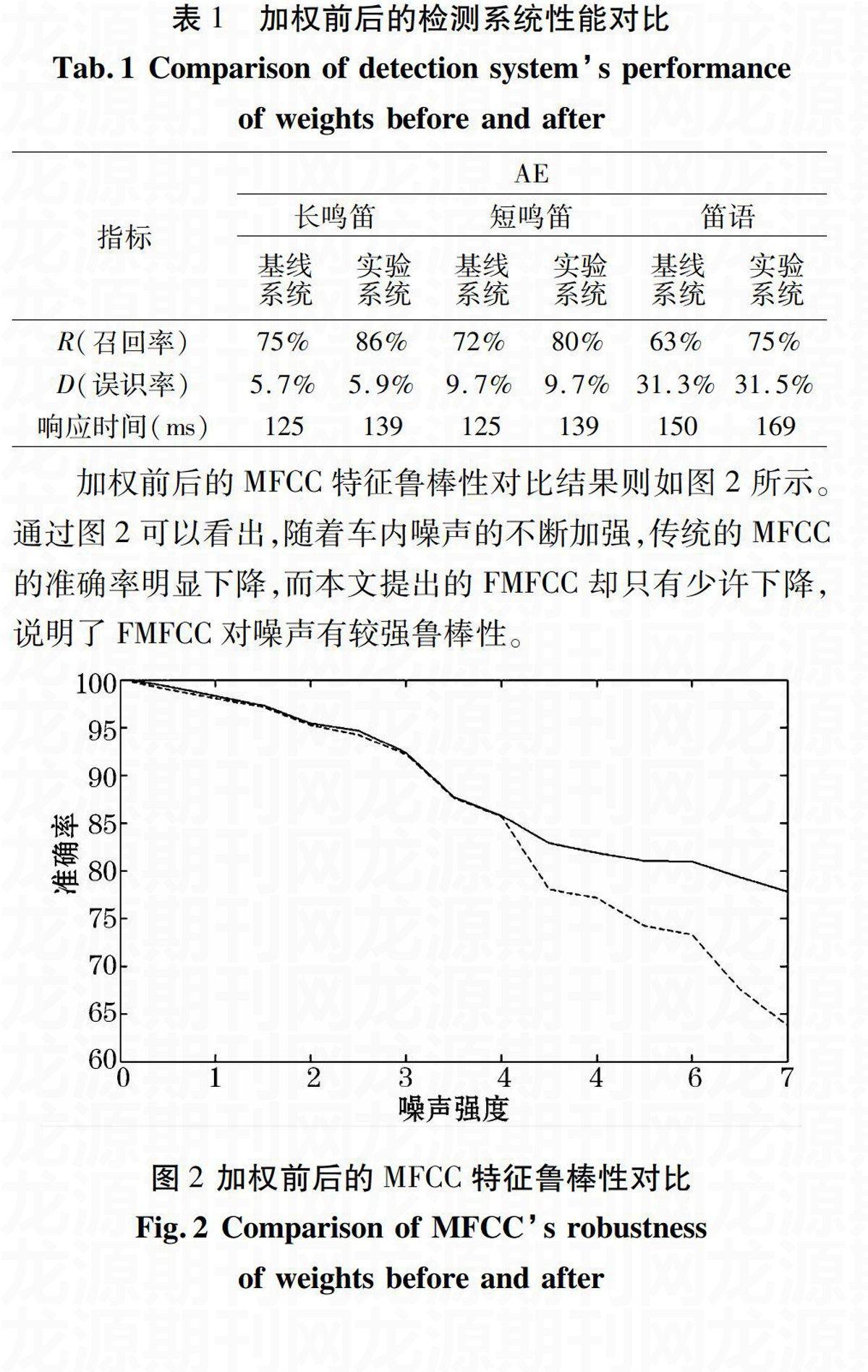
加权前后的MFCC特征鲁棒性对比结果则如图2所示。通过图2可以看出,随着车内噪声的不断加强,传统的MFCC的准确率明显下降,而本文提出的FMFCC却只有少许下降,说明了FMFCC对噪声有较强鲁棒性。
图2 加权前后的MFCC特征鲁棒性对比
Fig.2 Comparison of MFCCs robustness of weights before and after
5结束语
本文提出了一种基于人耳频率选择特性的加权滤波器组的FMFCC特征,使用LPC倒谱法提取共振峰的信息,模拟人耳的频率选择特性对Mel滤波器组进行加权,提取FMFCC系数。加权Mel滤波器组提取的FMFCC系数已经应用到行车噪声环境下的快速声学事件检测系统中。实验表明,在一定程度上提高了系统的准确率,降低了系统的误识率,并有效增强了传统MFCC对噪声的鲁棒性。
参考文献:
[1] MESAROS A, HEITTOLA T, ERONEN A. Acoustic event detection in real life recordings[C]//18th European SignalProcessing Conference, Aalborg: Proc Eusipco (2010),2010:1267-1271.
[2] RUVOLO P, FSSEL I, MOVELLAN J. A learning approach tohierarchical feature selection and aggregation for audio classification[J]. Pattern Recognition Letters, 2010,31(12) :1535-1542.
[3] PORTELO J, BUGALHO M, TRANCOSO I. Non-speech audio event detection[C]//IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei:[s.n.],2009:1973-1976.
[4] WICHERN G, XUE J, THORNBURG H. Segmentation,indexing, and retrieval for environmental and natural sounds[J].IEEE Transactions on Audio, Speech, and Language Processing,2010, 18(3):688-707.
[5] YE LAMOS P , RAMIREZ J, GORRIZ J M. Speech event detection using Support Vector Machines[J]. International Conferenceon Computational Science,2006,4:356–363.
[6] LOJKA M, PLEVA M, JUHAR J. Modification of widely used feature vectors for real-time acoustic events detection [C]//55th International Symposium ELMAR. Zadar : IEEE Communications Society,2013: 199 - 202.
[7] CAPPE O. Elimination of the musical noise phenomenon with the Ephraim and Malah noise suppressor[J]. IEEE Trans. Speech Audio Process., 1994, 2(2):345–349.
[8] VIRAG N. Single channel speech enhancement based on masking properties of the huma auditorysystem[J]. IEEE Trans.Speech AudioProcessing, 1999, 7(2):126-137.
[9] BOLL S. Suppression of acoustic noise in speech using spectral subtraction[J].IEEE transaction on acoustic,speech and signal processing,1979,27(2) : 113-120.
[10]游大涛. 基于听觉机理的鲁棒特征提取及在说话人识别中的应用[D]. 哈尔滨:哈尔滨工业大学,2013:36-37.
[11] RUSSELL I J, LEGAN P K, LUKASHKINA V A. Sharpened cochlear tuning in a mouse with a genetically modified tectorial membrane[J]. Nature Neuroscience,2007, 10(2):215–223.
