
基于DBSCAN算法的城市交通拥堵区域发现
2015-04-29 23:57:57刘畅李治军姜守旭
智能计算机与应用 2015年3期
刘畅 李治军 姜守旭
摘 要:现阶段我国车辆的数目不断增加,这必然会导致现有的交通条件等不再能够满足现在的交通状况。因时空数据蕴含丰富的信息,本文将通过分析车辆的时空轨迹数据,即GPS轨迹数据,并利用DBSCAN算法挖掘出城市中交通最拥堵的城市区域,并将得到的结果映射到城市路网上,使得相关部门能够清楚的了解问题,并制定一系列相应措施,如调整道路规划等,保证该区域的问题能够迅速得到解决。本文的实验结果清晰地标明了城市中具体的拥堵区域,本文下一步将根据城市拥堵区域的发现结果预测区域的下一次拥堵的时间。
关键词 : DBSCAN算法;时空轨迹数据;城市拥堵区域
中图法分类号: TP39 文献标识码: A
Discovery of Heavy Traffic Areas based on DBSCAN Algorithm
LIU Chang, LI Zhijun, JIANG Shouxu
(School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China)
Abstract: At present, the number of vehicles is increasing in our country. This will inevitably cause that the existing road and so on would no longer able to meet the current traffic conditions. Because the spatio-temporal data contain rich information, this paper will analyze the GPS data of the vehicle. This paper will mining the heaviest traffic congestion areas in a city by using the DBSCAN algorithm, and the mining result will be mapped to the city road network so that the relevant departments can clearly understand where the problems are. The departments also can develop a series of measures to solve those problems, such as adjusting the road planning and so on. This will ensure that the problems can be resolved quickly, and the experiment results of this paper clearly indicate the specific congestion areas in a city. The next work is the time prediction of congestion areas.
Key words: DBSCAN Algorithm; Spatio-temporal Data; Heavy Traffic Area
0 引 言
我国现阶段经济迅速发展,私家车、公交车、出租车等的数量正与日激增,这一态势必将导致现有的部分地区交通道路已经难以满足不断增长的运营与运力需求,所以如何做好城市交通道路规划即已归作城市建设中需要重点解决的关键问题之一[1],一个科学、合理的交通道路规划则是建造一座现代智能城市的基础必备技术手段。
时空轨迹数据[2]蕴含非常丰富的地理信息、语义信息,连续的轨迹数据还能反映出其移动规律以及相应变化。通过相同种类大量不同对象的轨迹数据,规划团队还可以迅速了解某一种类对象的特点特性。而当规划者使用城市中的车辆轨迹数据时,这些数据的动态分布则能实时有效地反映城市的交通变化[3],这就为城市交通道路规划提供了极其重要的信息,并使得城市的交通道路能够进一步做出相应的调整。本文的目的即是找出潜在不能满足交通需求的区域,并且因为出租车的交通数据在一定程度上更能代表全市的交通状况,而且比较容易实现采集,由此本文所用的数据即为北京市12 000辆出租车一个月的GPS数据,该数据存储在TXT文件中[4]。
1 本文所采用的GPS数据介绍
本文所采用的GPS数据采集频率约为一分钟,解压之前为13.1G,解压之后约为50G[4]。其具体内容主要如下:有车辆标识,由6位数字字符串组成;触发事件,对应为一位整数,共有5种情况,其中“0”代表“空车”,“1” 代表“载客”,“2”代表“设防”,“3”代表“撤防”,“4”代表“其他”;运营状态,共5种情况,其中“0”代表“空车”,“1” 代表“载客”,“2”代表“驻车”,“3”代表“停运”,“4”代表“其他”;GPS时间,是一个数字字符串,代表年月日时分秒;GPS经度,为浮点数,小数点后保留6位有效数字;GPS纬度,也为浮点数,小数点后保留6位有效数字;GPS速度、GPS方向,其对应的单位为角度单位“度”;GPS状态,共2种状态,分别为“有效”、“无效”。各项数据之间以逗号相隔,一组GPS数据以“回车符”与“换行符”结束。
首先,对GPS数据文件中的数据进行时间上的分割,设置时间片为一分钟,将每一分钟采样的出租车数据存放于一个txt文件中,并以采集数据的发生时刻命名该文件,每个文件大小约为1 400KB左右。数据采样的时间约为一分钟,但该频率并不确定,对数据进行时间片处理后,每个文件中均会存在同一辆出租车重复数据采样的问题,此时需对重复数据展开进一步处理,即去掉对同一辆车的重复采样数据,处理完成的数据文件仍储存在txt文件中。
2 基于DBSCAN算法的城市拥堵区域发现
2.1 DBSCAN算法相关定义
针对每个时间片上的数据,本文进行基于密度聚类(DBSCAN),也就是以数据集在空间分布上的稠密程度为依据进行聚类,每个时间片上的群体则可称为快照集群。文中,DBSCAN算法中涉及的一些定义[5]现表述如下:
R区域:以数据对象为圆心、R为半径的圆称为数据对象的R区域,半径R即为数据对象之间距离的最大阈值,本文中计算两数据对象a、b时使用以下公式:
,此处的x、y为纬度和经度的弧度数。通过将两数据对象由经纬度坐标转换到直角坐标系中,求出两数据对象相对地心的弧长,即为对象a、b的距离[6] (本文中地球半径r取为6 378 137.0米);
数量阈值Min:数据对象R领域中包含其他数据对象的数量最小阈值为数量阈值Min;
核心数据对象:若数据对象的R领域中所包含的其他数据对象数量超过阈值Min,则称该数据对象为核心数据对象;
直接密度可达:一个核心数据对象a的R区域中所有其他的数据对象…,数据对象…从该核心数据对象a直接密度可达;
密度可达:在所有数据对象中,若存在一串数据对象为a,…,c,并且有对象从对象a直接密度可达,对于,对象从直接密度可达,对象c从对象直接密度可达,则对象c从对象a密度可达;
密度相连:在同一个密度可达数据集合中的所有数据对象,称作是相互密度相连的;
簇ID:将不同的密度相连的数据集合中的数据对象用簇ID来标记,其中簇ID为-1代表数据对象为噪音点,即该数据对象没有满足密度要求,不属于任何簇。
2.2 DBSCAN算法描述
首先,扫描整个数据集,找到任意一个核心数据对象并针对该核心对象进行扩充。扩充的方法是寻找从该核心数据对象出发的所有密度相连的数据对象。遍历该核心数据对象的R区域内的所有核心数据对象(因为边界数据对象无法扩充,故只遍历所有核心数据对象),寻找与这些数据对象密度相连的数据对象并将密度相连的数据对象标记为相同的簇ID,直到没有可以扩充的数据对象为止,最后聚类成簇的边界点都是非核心数据对象。其次,重新扫描未被访问过的数据集,寻找没有被标记的核心数据对象,并重复第一步的步骤,对该核心数据对象进行扩充。以此类推,直至数据集中所有的GPS数据对象均被访问过,数据集中没有包含在任何簇中的数据点则构成噪音点,将其簇ID置为-1。
该算法流程如下:
算法——各时间片GPS数据文件基于密度聚类
输入:时间片分割后的GPS数据文件,半径R,数量阈值Min;
输出:所有生成的达到密度要求的簇。
(1) 初始化文件中每个数据对象所属的簇ID为-1,即不属于任何簇,数据对象是否被访问的标记参数isVisited设置为false
(2) 初始化半径R以及数量阈值Min
(3) n为文件中数据点个数
(4) For i从1到n
(5) If GPS点i的R区域内的GPS数据点数大于等于阈值Min
(6) 标记点i为核心数据对象
(7) End if
(8) End for
(9) 初始化簇ID=0
(10) For i从1到n
(11) If GPS点i参数isVisited=false && GPS点i是核心数据对象
(12) 设置GPS点i所属簇ID
(13) 设置GPS点i已被访问过,即将 isVisited置为true
(14) While GPS点i的R区域内存在未被访问的数据对象
(15) 设置该数据对象已被访问过, isVisited = true
(16) 设置该对象所属簇ID = GPS点i的簇ID
(17) If 该点为核心数据对象
(18) 递归遍历其R区域中的其他未被访问的GPS点
(19) End if
(20) End while
(21) 簇ID自增1
(22) End if
(23) End for
DBSCAN算法的优点是无需限定其将要生成的簇的个数,并能发现数据集中任意形状的簇。不过DBSCAN算法仍存在一些缺点,其对区域半径R以及数量阈值Min的设定很敏感,对此二参数稍作改动都有可能导致差别较大的结果。
通过DBSCAN算法可以得到每个时间片上的快照集群,得到每个时间片上快照集群所在城市区域,即得到各时间片交通拥挤的区域。记录各时间片拥挤区域ID,若拥挤区域持续一定的时间,即检测到城市交通拥堵区域。若某区域经常出现拥堵情况,则该区域需要进一步作城市交通道路规划调整。
3 实验结果与结论分析
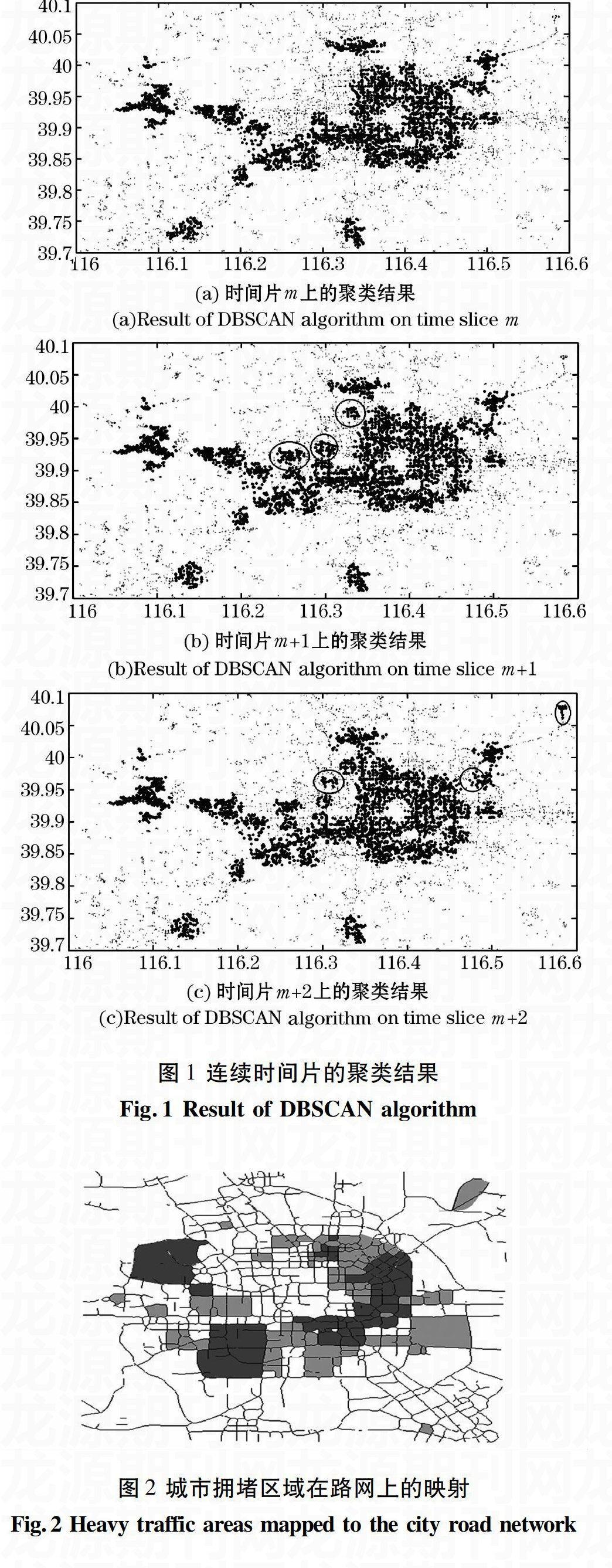
首先,对数据进行时间片分割,得到每个时间片上的车辆GPS轨迹数据。其次,本文针对各个时间片上的GPS数据进行DBSCAN聚类,其中的部分聚类结果效果图如图1所示,设图1的时间片时间为第m个时间片。
(a) 时间片m上的聚类结果
(a)Result of DBSCAN Algorithm on time slice m
(b) 时间片m+1上的聚类结果
(b)Result of DBSCAN Algorithm on time slice m+1
(c) 时间片m+2上的聚类结果
(c)Result of DBSCAN Algorithm on time slice m+2
图1 连续时间片的聚类结果
Fig.1 Result of DBSCAN Algorithm
从图1(a)和图1(b)的圆圈处可看到各个时间片上的聚类结果的变化,各快照集群位置有些细微变化,某一些簇的边界或位置已经发生了改变。
将聚类结果与地图相映射,某一时刻的城市拥堵区域检测结果如图2所示。
图2 城市拥堵区域在路网上的映射
Fig.2 Heavy Traffic Areas Mapped to The City Road Network
图2中深色部分为拥堵程度较重的区域,浅色为拥堵程度次重的区域。
4 结束语
本文将得到城市拥堵区域ID以及其拥堵时间,由于本文所使用的DBSCAN算法对参数比较敏感,本文将进一步找到较为合适的算法参数。其后的下一研究方向则是结合本文所得到的结果,运用概率模型,针对地图区域,推测出区域下一次出现群体的时间。这一研究则可为交通指挥人员提供有利信息,使其能够预先掌握即将出现交通问题的区域,并利于其智能型和前瞻性的工作调度,因而本文研究成果必将具备重大的现实意义及价值。
参考文献:
[1] 周晓昌. 城市交通拥堵问题研究[J]. 价值工程, 2014,(28):86-87.
[2] 单国慧, 程涛, 杨培章,等. 运动目标轨迹的时空数据模型研究[J]. 测绘科学, 2007, 32(3):33-35.
[3] ZHENG V W, ZHENG Y, YANG Q. Joint learning user's activities and profiles from GPS data[C]//Proceedings of the 2009 International Workshop on Location Based Social Networks, [S.l.]:ACM, 2009: 17-20.
[4] 某北方城市12000辆出租车GPS位置数据(2012年11月). http://www.datatang.com/data
/44502,2013-09-16 16:50
[5] BIRANT D, KUT A. ST-DBSCAN: An algorithm for clustering spatial–temporal data[J]. Data & Knowledge Engineering, 2007, 60(1): 208-221.
[6] VENESS C. Calculate distance, bearing and more between Latitude/Longitude points[J]. not dated, http://www. movable-type. co. uk/scripts/latlong. html, 2010.
